我有一個資料框的子集,如下所示。我想在“疾病年齡”欄中填寫 NA,以便一個患有疾病的人的年齡與沒有疾病的兄弟姐妹(從 familyID 識別)相同。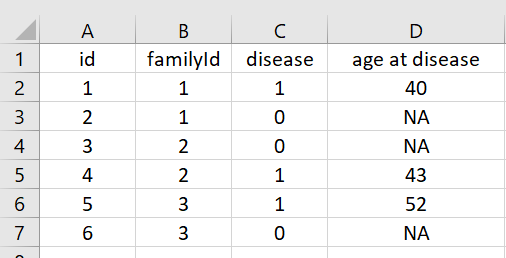
structure(list(id = c(1, 2, 3, 4, 5, 6),
familyId = c(1, 1, 2, 2, 3, 3),
disease = c(1, 0, 0, 1, 1, 0),
`age at disease` = c("40","NA", "NA", "43", "52", "NA")),
class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA, -6L))
這意味著最后一列“患病年齡”應該是:c(40,40,43,43,52,52)。
uj5u.com熱心網友回復:
您可以使用以下代碼:
library(dplyr)
library(tidyr)
df %>%
na_if("NA") %>%
group_by(familyId) %>%
fill(`age at disease`) %>%
fill(`age at disease`, .direction = "up")
輸出:
# A tibble: 6 × 4
# Groups: familyId [3]
id familyId disease `age at disease`
<dbl> <dbl> <dbl> <chr>
1 1 1 1 40
2 2 1 0 40
3 3 2 0 43
4 4 2 1 43
5 5 3 1 52
6 6 3 0 52
uj5u.com熱心網友回復:
如果每組只有一個非 NA 元素,我們也可以這樣做
library(dplyr)
df1 %>%
type.convert(as.is = TRUE) %>%
group_by(familyId) %>%
mutate(`age at disease` = `age at disease`[complete.cases(`age at disease`)][1]) %>%
ungroup
-輸出
# A tibble: 6 × 4
id familyId disease `age at disease`
<dbl> <dbl> <dbl> <chr>
1 1 1 1 40
2 2 1 0 40
3 3 2 0 43
4 4 2 1 43
5 5 3 1 52
6 6 3 0 52
uj5u.com熱心網友回復:
這是另一種dplyr方法:
df %>%
group_by(familyId) %>%
arrange(`age at disease`,.by_group = TRUE) %>%
mutate(`age at disease` = first(`age at disease`))
id familyId disease `age at disease`
<dbl> <dbl> <dbl> <chr>
1 1 1 1 40
2 2 1 0 40
3 4 2 1 43
4 3 2 0 43
5 5 3 1 52
6 6 3 0 52
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/474490.html
上一篇:Pandas資料框-洗掉重疊區間