應用 levenshtein 距離演算法后,我得到這樣的資料幀:
| 元素串列 | Item_ID | 分數 | 編號 | ITEM_ID_巧合 |
|---|---|---|---|---|
| 4 | 691776 | 100 | 5 | 691777 |
| 4 | 691776 | 100 | 6 | 691789 |
| 4 | 691776 | 100 | 7 | 691791 |
| 5 | 691777 | 100 | 4 | 691776 |
| 5 | 691777 | 100 | 6 | 691789 |
| 5 | 691777 | 100 | 7 | 691791 |
| 6 | 691789 | 100 | 4 | 691776 |
| 6 | 691789 | 100 | 5 | 691777 |
| 6 | 691789 | 100 | 7 | 691791 |
| 7 | 691791 | 100 | 4 | 691776 |
| 7 | 691791 | 100 | 5 | 691777 |
| 7 | 691791 | 100 | 6 | 691789 |
| 9 | 1407402 | 100 | 10 | 1407424 |
| 10 | 1407424 | 100 | 9 | 1407402 |
Elemento_lista 列是與其他元素進行比較的元素的索引,Item_ID 是元素的 id,Score 是演算法生成的分數,idx 是找到相似的元素的索引(與 Elemento_lista 相同,但對于元素發現相似),ITEM_ID_Coincidencia 是發現相似的元素的 id
這是真實 DF 的小樣本(超過 300000 行),我需要洗掉相同的行,例如...如果 Elemento_lista 4,等于 idx 5,6 和 7...它們都是一樣的,所以我不需要 5 等于 4、6 和 7/6 等于 4、5、7 和 7 等于 4、5、6 的行。每個 Elemento_Lista 都相同: value=9 等于 idx 10,所以...我不需要 Elemento_Lista 10 等于 idx 9 這行...我怎樣才能洗掉這些行以減少 DF len ? ?
最終的 DF 應該是:
| 元素串列 | Item_ID | 分數 | 編號 | ITEM_ID_巧合 |
|---|---|---|---|---|
| 4 | 691776 | 100 | 5 | 691777 |
| 4 | 691776 | 100 | 6 | 691789 |
| 4 | 691776 | 100 | 7 | 691791 |
| 9 | 1407402 | 100 | 10 | 1407424 |
我不知道該怎么做……這可能嗎?
提前致謝
uj5u.com熱心網友回復:
準備資料,例如:
a = [
[4,691776,100,5,691777],
[4,691776,100,6,691789],
[4,691776,100,7,691791],
[5,691777,100,4,691776],
[5,691777,100,6,691789],
[5,691777,100,7,691791],
[6,691789,100,4,691776],
[6,691789,100,5,691777],
[6,691789,100,7,691791],
[7,691791,100,4,691776],
[7,691791,100,5,691777],
[7,691791,100,6,691789],
[9,1407402,100,10,1407424],
[10,1407424,100,9,1407402]
]
c = ['Elemento_lista', 'Item_ID', 'Score', 'idx', 'ITEM_ID_Coincidencia']
df = pd.DataFrame(data = a, columns = c)
df
現在,您插入一列:它將包含一個由 2 個排序索引組成的陣列。
tuples_of_indexes = [sorted([x[0], x[3]]) for x in df.values]
df.insert(5, 'tuple_of_indexes', (tuples_of_indexes))
然后所有資料框按插入的列排序:
df = df.sort_values(by=['tuple_of_indexes'])
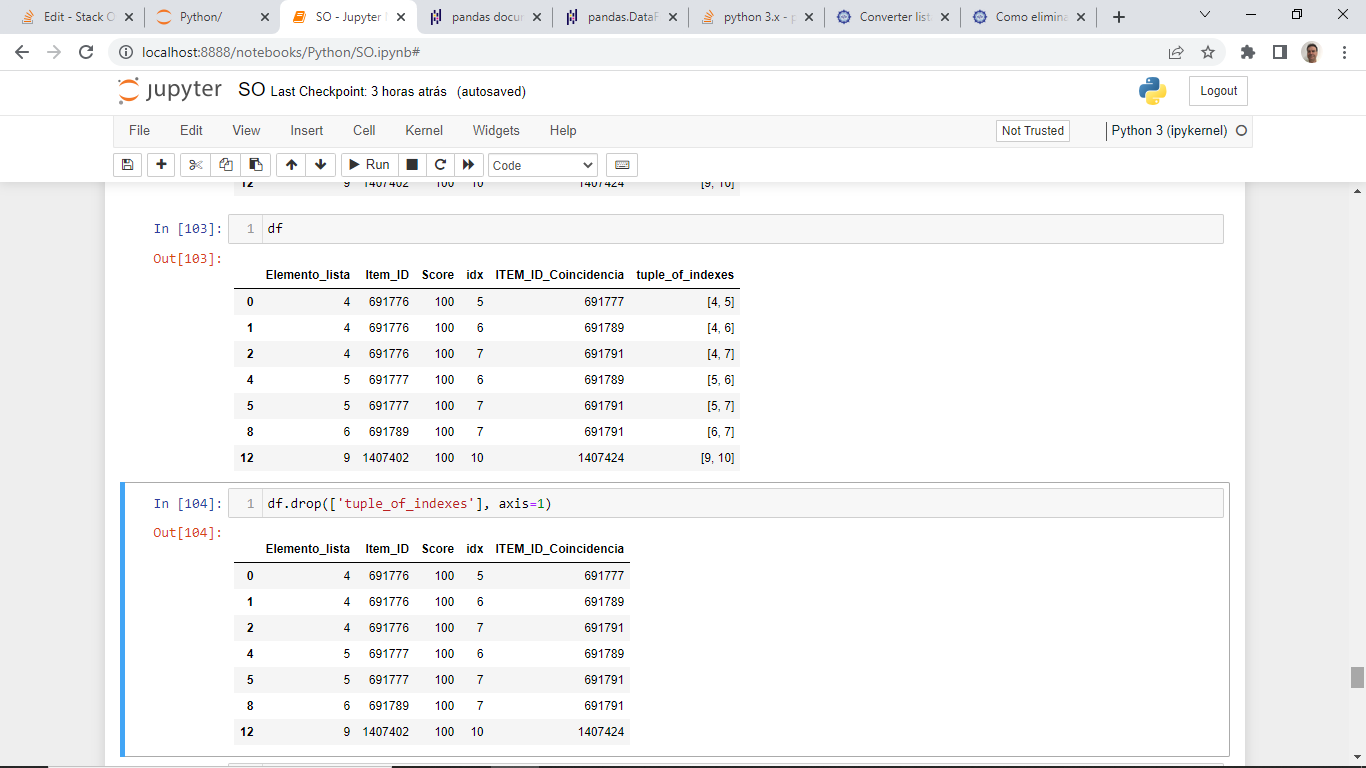
然后你消除重復插入列的行:
df = df[~df['tuple_of_indexes'].apply(tuple).duplicated()]
最后,您消除了插入的列:'tuple_of_indexes':
df.drop(['tuple_of_indexes'], axis=1)
輸出是:
Elemento_lista Item_ID Score idx ITEM_ID_Coincidencia
0 4 691776 100 5 691777
1 4 691776 100 6 691789
2 4 691776 100 7 691791
4 5 691777 100 6 691789
5 5 691777 100 7 691791
8 6 691789 100 7 691791
12 9 1407402 100 10 1407424
uj5u.com熱心網友回復:
這可以使用圖論來解決。
您的 ID 之間存在以下關系:
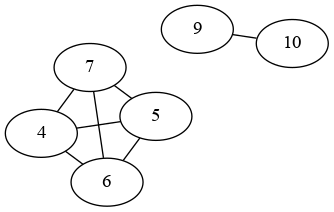
所以你需要做的是找到子圖。
為此,我們可以使用
您可以在此處更改策略并使用有向圖和
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/474505.html