我正在嘗試使用 opencv 裁剪影像,然后讓 tesseract 讀取它,但即使影像非常清晰,它也無法識別該影像中的數字,以下是該操作的代碼行:
screen_img = cv2.imread(f'data\\screenshot\\{e_name}.png')
crop_img = screen_img[350:385,185:270]
crop_img = cv2.cvtColor(crop_img,cv2.COLOR_BGR2GRAY)
cv2.imwrite(f'data\\screenshot{e_name}.png',crop_img)
cv2.imshow('ad',crop_img)
cv2.waitKey(0)
text = pytesseract.image_to_string(crop_img)
print(text)
cv2.imshow('ad',crop_img)看起來像這樣的輸出:
但是控制臺的輸出print(text)只是一個新的空白行。
我真的很感謝你的幫助(我可能會犯愚蠢的錯誤,因為我不是專業的程式員,所以我很抱歉)。
EDIT1:感謝評論,我添加了幾行:
screen_img = cv2.imread(f'data\\screenshot\\{e_name}.png')
crop_img = screen_img[350:385,185:270]
crop_img = cv2.cvtColor(crop_img,cv2.COLOR_BGR2GRAY)
crop_img = cv2.bitwise_not(crop_img)
ret, thresh1 = cv2.threshold(crop_img, 120, 255, cv2.THRESH_BINARY cv2.THRESH_OTSU)
cv2.imshow('ad',thresh1)
cv2.waitKey(0)
text = pytesseract.image_to_string(thresh1)
現在的輸出看起來更有希望: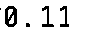
但結果似乎保持不變,我從互聯網上檢查了一些隨機文本影像,其中大多數都可以正常作業。
uj5u.com熱心網友回復:
添加時會發生魔術config='--psm 6'。
根據Tesseract OCR 選項頁面:
6 假設一個統一的文本塊。
代碼示例:
crop_img = cv2.imread('crop_img.png')
text = pytesseract.image_to_string(crop_img, config='--psm 6')
print(text)
結果:
73.9
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/479047.html
標籤:Python opencv 计算机视觉 正方体 python-正方体