在聊Kafka高可靠之前,先在評論區來波RNG NB好不好!
什么叫可靠性?
大家都知道,系統架構有三高:「高性能、高并發和高可用」,三者的重要性不言而喻,
對于任意系統,想要同時滿足三高都是一件非常困難的事情,大型業務系統或者傳統中間件都會搭建復雜的架構來保證,
除以上三種模式之外,還有一個指標方向也很重要,那就是高可靠,甚至你可能會將它和「高可用」混淆起來,
事實上兩者并不一樣,高可用會更偏向于整體服務的可用性,防止系統宕機等等,而高可靠是指資料的可靠性保證嘛,你可以理解”高可靠“相比于系統三高會是一個更細一點的概念,
那么什么是資料的高可靠呢,總結一下就是系統要提供可靠的資料支撐,不能發生丟失、重復等錯誤現象,
所以每個開源中間件在發布版本時都會通過檔案宣告自己是超可靠的,就像520那天每一位暖男說的那樣,

咱今天的主角kafka就是這么一個例子,
一些重要概念
因為有一段時間沒講訊息佇列了嘛,為了幫助你更好理解文章,我們來先復習一下kafka的基礎概念:
record:訊息,訊息佇列基礎通信單位
topic:主題,目的就是將訊息進行分類,不同業務型別的訊息通常會被分發到不同的主題
partition:磁區,每個主題可以創建多個磁區,每個磁區都由一系列有序和不可變的訊息組成
replica:副本,每個磁區都有一個至多個副本存在,它的主要作用是存盤保存資料,以日志(Log)物件的形式體現,副本又分為leader副本和follower副本
offset:偏移量,每一個訊息在日志檔案中的位置都對應一個按序遞增的偏移量,你可以理解為類似陣列的存盤形式
producer:生產者,生產訊息的那一方
consumer:消費者,通常不同的業務都會有一到多個消費者組成消費者集群
broker:代理,一個Kafka集群由一個或多個Kafka實體構成,每一個Kafka實體就稱為代理
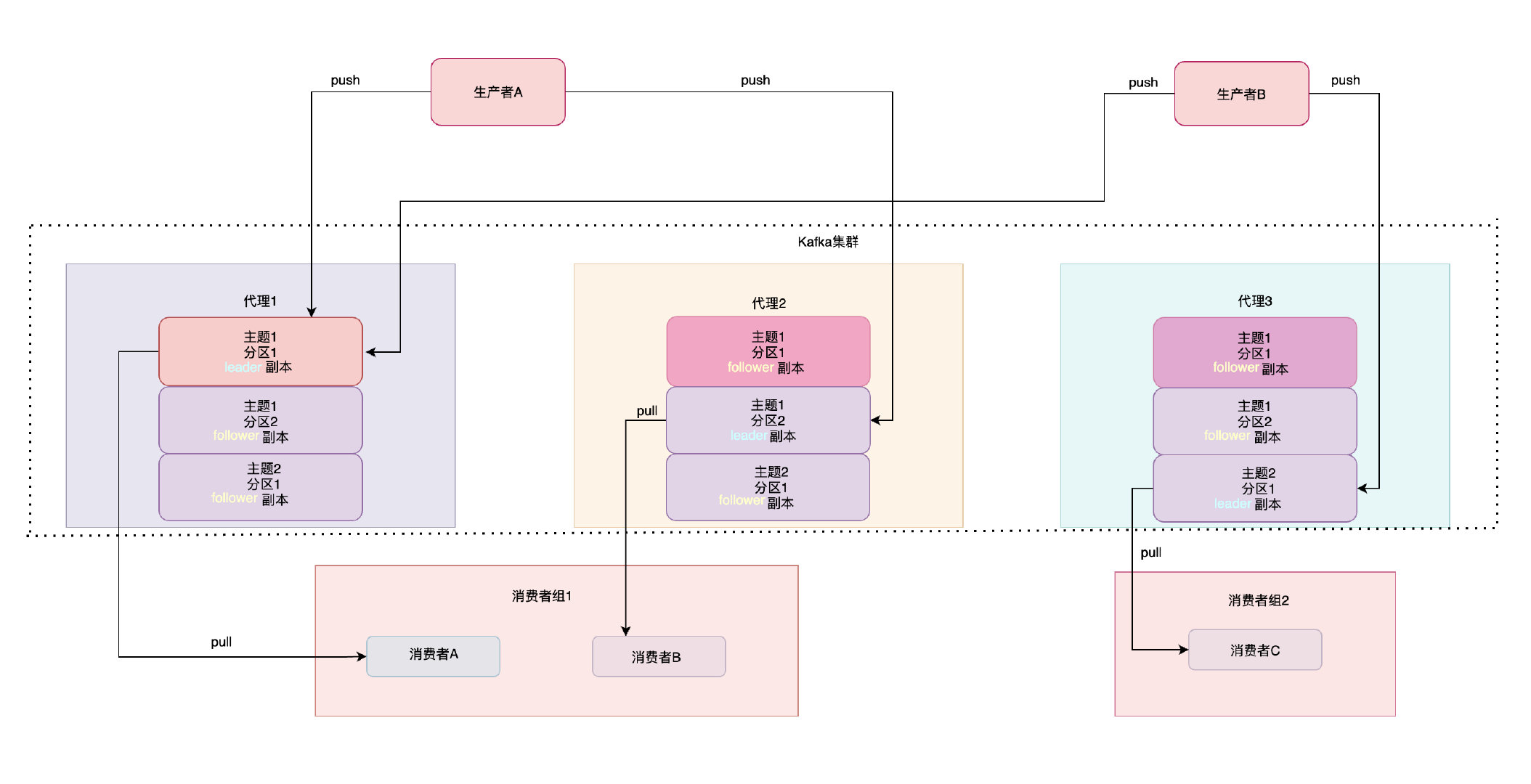
如上圖所示,一共存在主題1和主題2,主題1有兩個磁區,主題2只有一個磁區,并且每個磁區都存在一個leader副本和兩個follower副本,它們分布在每個不同的代理節點上,
partition里只有leader副本負責與生產者、消費者之間資料的互動,follower副本會定期從leader副本拉取資料以保證整個集群資料可用性,
如何保證資料高可靠
Kafka是通過副本機制實作資料的存盤的,所以就需要一些機制保證資料在跨集群的副本之間能夠可靠地傳輸,
1.副本同步集合
業務資料封裝成訊息在系統中流轉,由于各個組件都是分布在不同的服務器上的,所以主題和生產者、消費者之間的資料同步可能存在一定的時間延遲,Kafka通過延遲范圍劃分了幾個不同的集合:
AR(Assigned Replicas)
指的是已經分配資料的磁區副本,通常指的是leader副本 + follower副本,

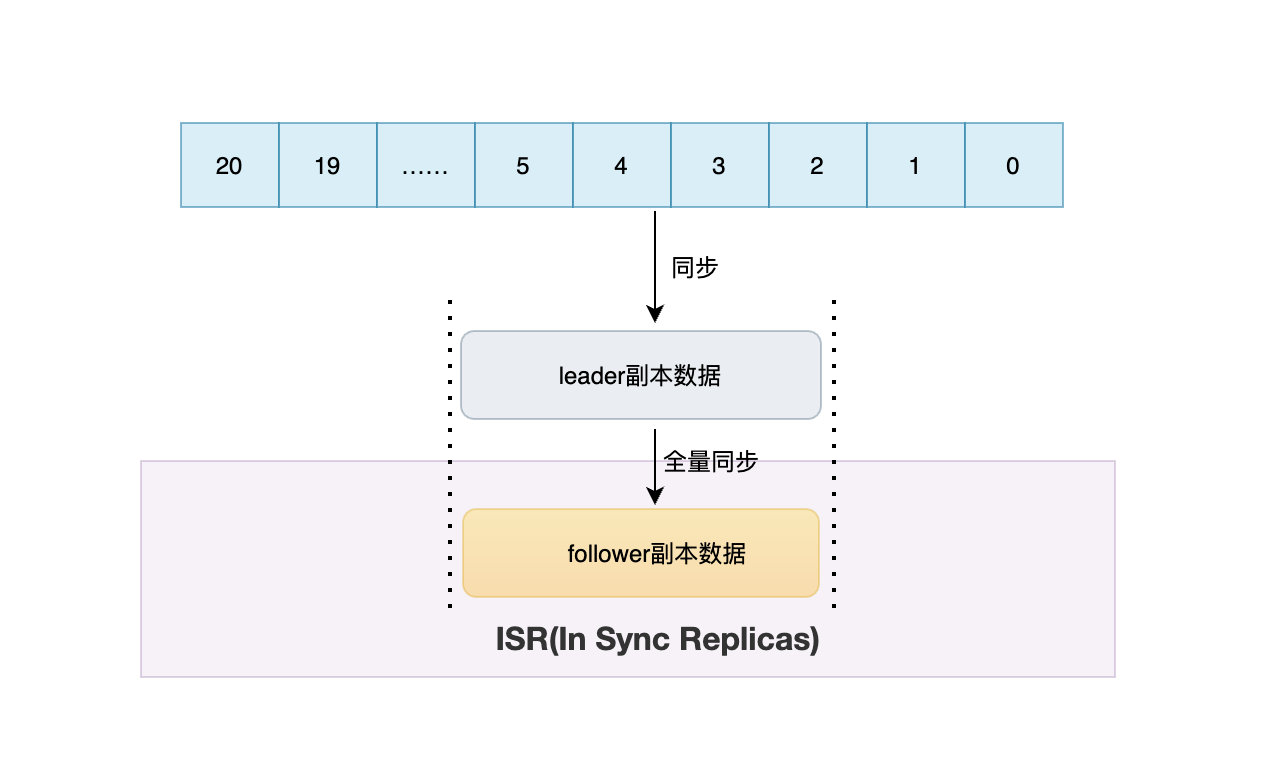
ISR(In Sync Replicas)
指的是和leader副本資料保持同步的副本集合,當follower副本資料和leader副本資料保持同步,那么這些副本就處在ISR里面,ISR集合會根據資料的同步狀態動態變化,
OSR(Out Sync Replicas)
一旦follower副本的資料同步進度跟不上leader了,那么它就會被放進叫做OSR的集合里,也就是這個集合包含的是不處于同步狀態的磁區副本,
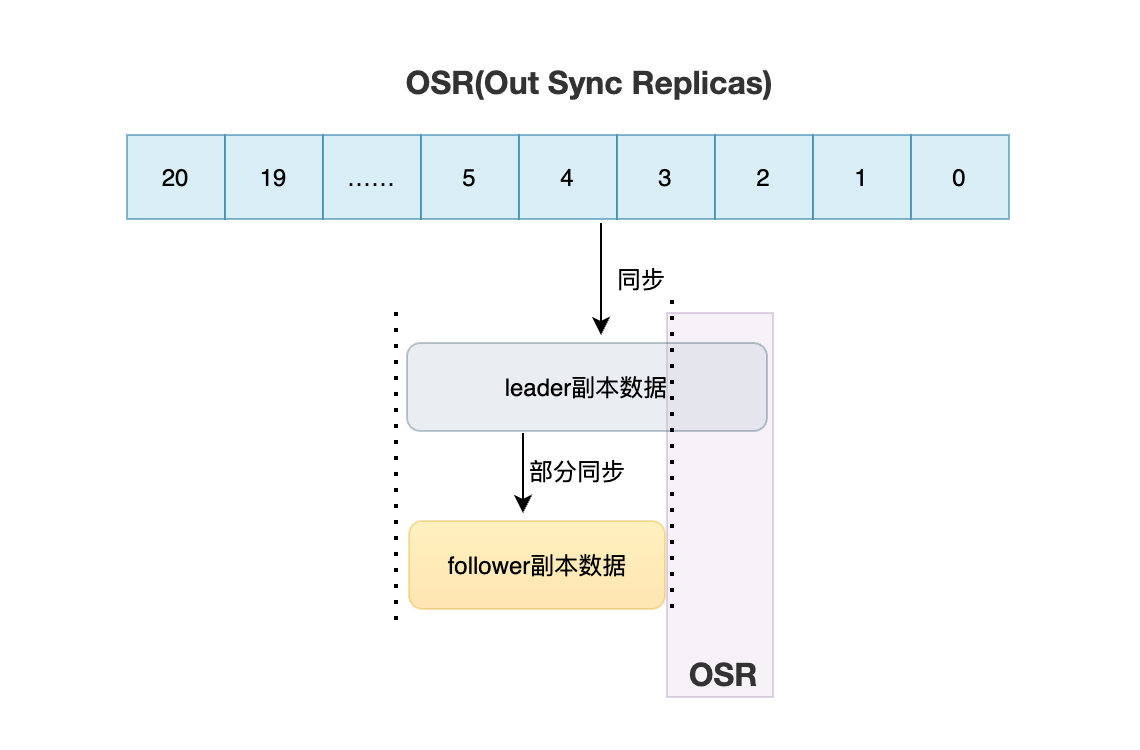
OK,那有什么標準判斷它是同步還是不同步呢?
通過replica.lag.time.max.ms這個引數來設定資料同步時間差,它的默認值是10s,
一旦從磁區副本和主磁區副本的訊息相差10s以上,那么就認為訊息處于OSR不同步的狀態,若follower處于OSR集合里,那么在選取新的leader的時候就不會選舉它作為新leader,
2.ACK應答機制
我們剛剛說了kafka是通過ack來發送資料同步信號的,那信號發送頻率又有幾種設定呢?
ack = 0
生產者發送一次訊息就不再發送,不管是否發送成功,若發出去的訊息處于通信的路上就丟失,或者還未做磁盤持久化操作,那么訊息就可能丟失,
它的好處就是性能很高,你想呀你發送訊息都不需要等待對方回復就持續發送下一批,那么訊息等待的時間就節省出來了,同一時間范圍內能比別人處理更多資料,缺點就是它的可靠性真的很低,資料真的是說丟就丟,
ack = 1
leader接收到訊息并且寫入到本地磁盤后就認為訊息處理成功,這種方式可靠性會比上一種好一些,當leader接收到訊息并且寫入到本地磁盤后就認為訊息處理成功,不論follower是否同步完這條訊息就會回傳給producer,
但是假如此刻partition leader所在的broker宕機了,如果那么資料也可能會丟失,所以follower副本的資料同步就很重要,
Kafka默認就采用這種方式,
ack = -1
producer只有收到磁區內所有副本的回應ACK才會認為訊息已經push成功,
這種方式雖然對于資料的可靠保障做得很好,但是就是性能很差,影響吞吐量,所以一般也不會采取,
那么它就絕對可靠嗎?也不一定,最重要的還是取決于副本資料是否同步完成,若producer收到回應訊息前leader副本掛掉,那么producer會因未收到訊息重復發送訊息,那就可能造成資料重復,怎么解決呢?只要保證業務冪等就行,
我們可以通過request.required.acks這個引數控制訊息的發送頻率,
如果覺得文章不錯,可以微信搜一搜「 敖丙 」第一時間閱讀,關注后回復【資料】有我準備的一線大廠面試資料和簡歷模板
3.訊息語意
訊息集群整體是一個復雜的系統,所以程序中可能會因為各種原因導致訊息傳遞出錯,Kafka對于這些可能遇到的場景定義了對應的的訊息語意,
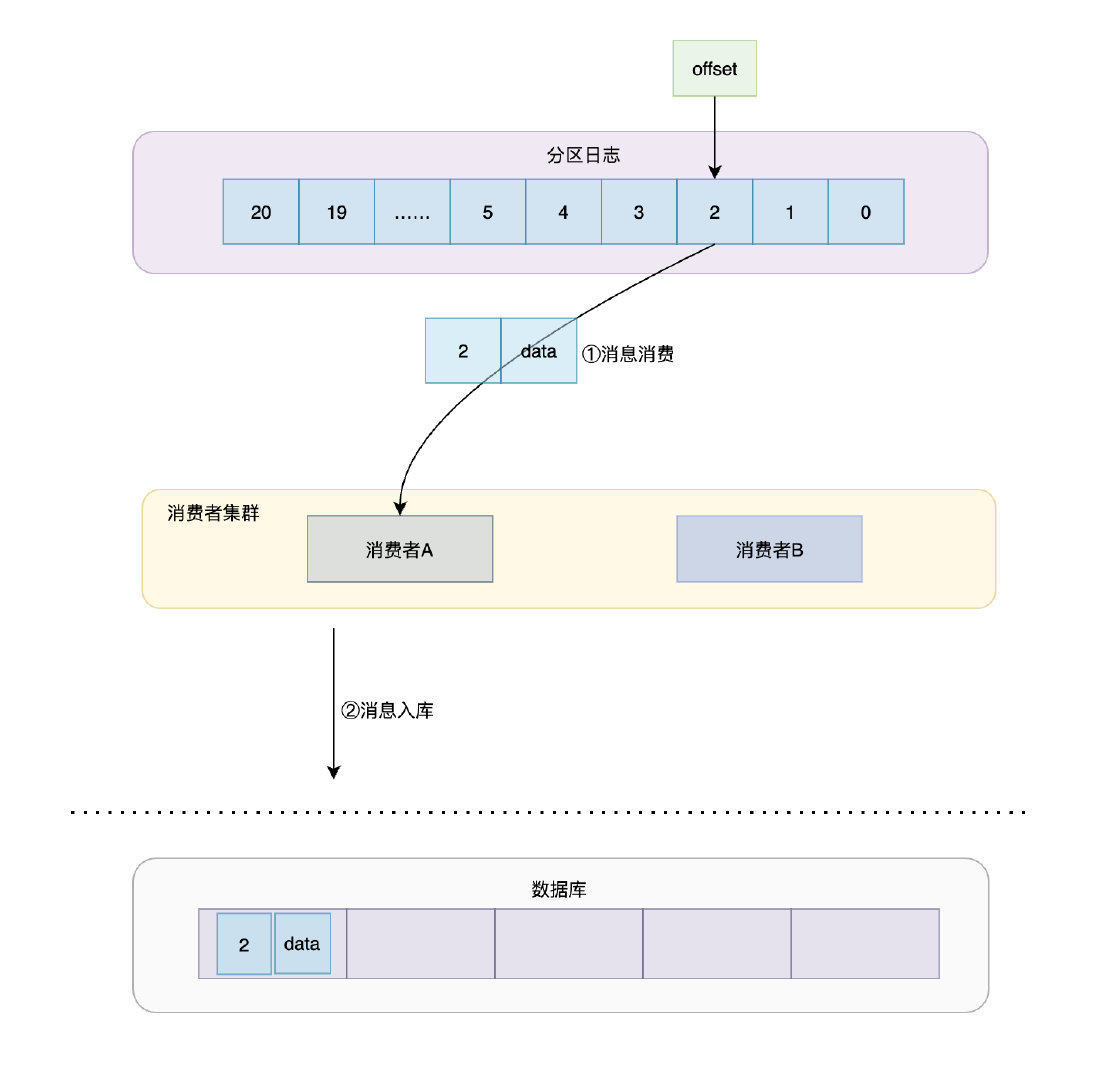
at most once
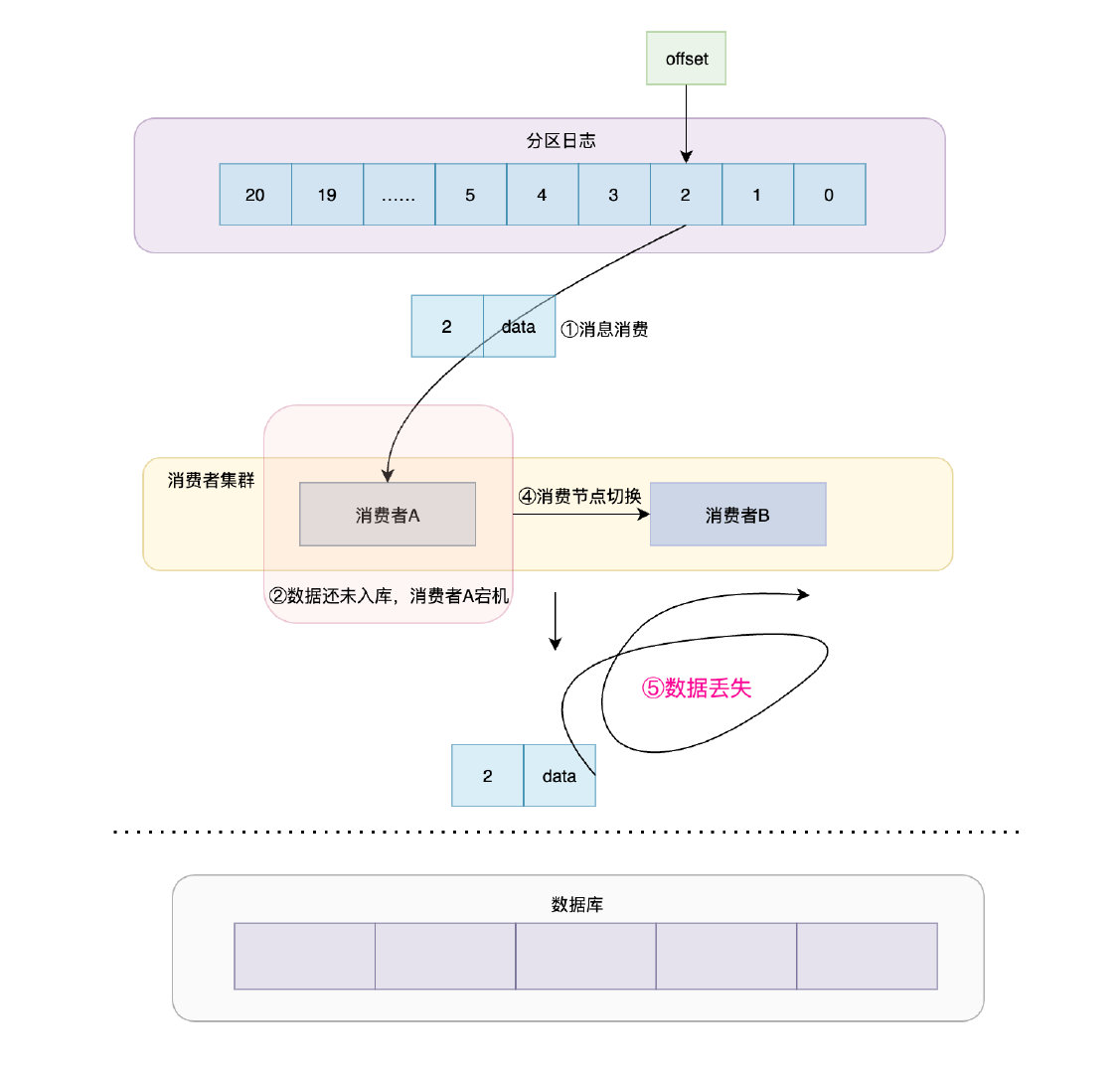
它代表訊息可能被消費者消費0次或者1次,若場景如下:
訊息從partition分發給消費者集群
消費者把自己收到的訊息告訴集群,集群收到之后offset就會往后移動
消費者將資料入庫做持久化
你一定想到了,在第三步消費者將訊息入庫時若因任何原因消費者A掛了,那么在將消費者切換到集群的消費者B后,資料還沒入庫呢,此時partition是渾然不知的呀,那么這就會造成一個問題:資料丟失,
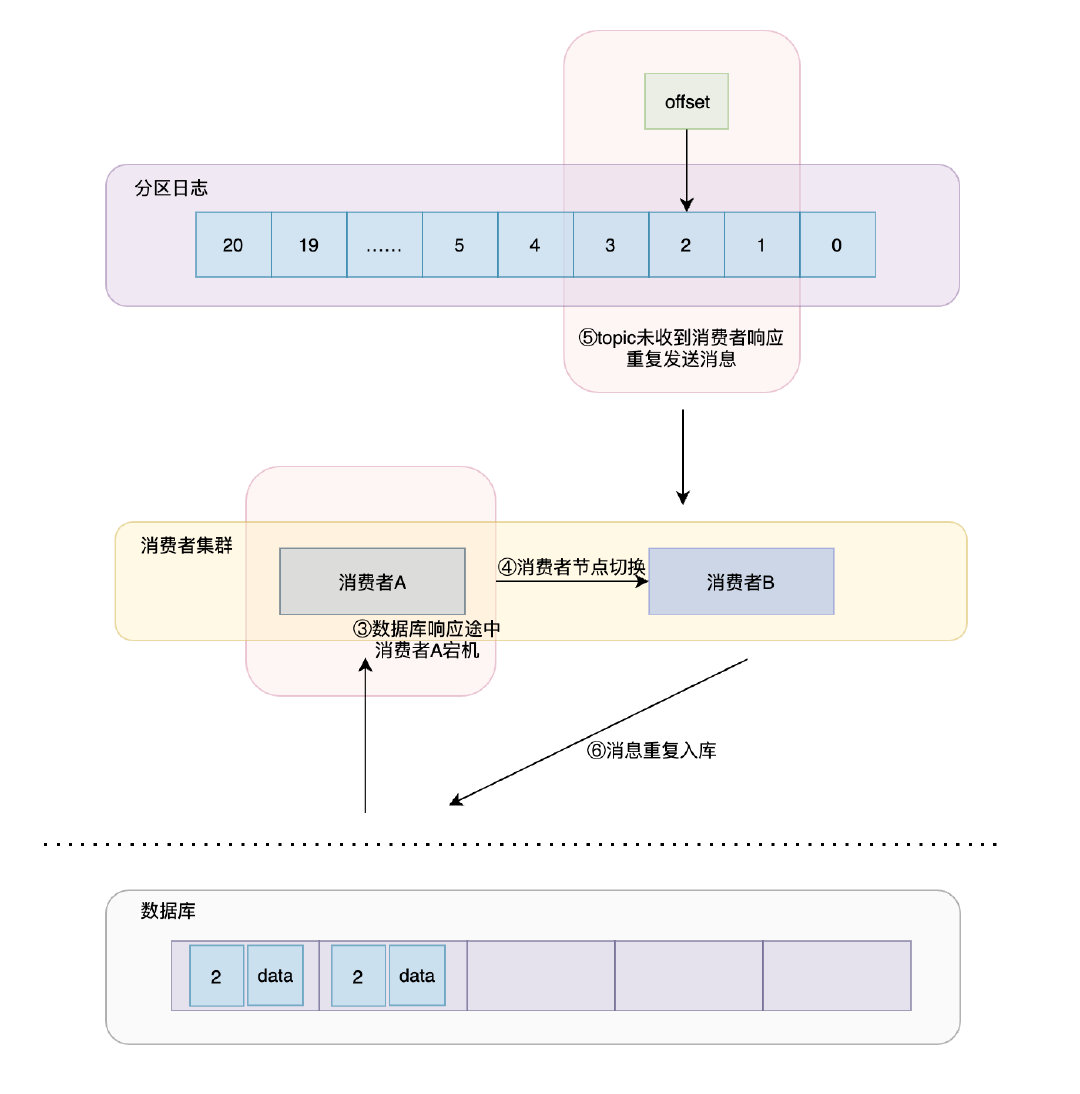
at least once
它代表partition分發的訊息至少被消費一次,其通信程序如下:
訊息從partition分發給消費者集群
消費者將資料入庫做持久化
消費者把自己收到的訊息告訴集群,集群收到之后offset就會往后移動
假設consumer group在資料入庫之后,在將資料回傳給partition的程序中消費者A掛了,那么partition會因為接收不到回應ACK而重新發送資料,此時消費者B可能再次將原先的訊息入庫,這就造成了資料重復了,
在沒有做任何冪等性保護的情況下,像重復轉賬,重付疊加積分這種業務,那么結果可能是致命的,
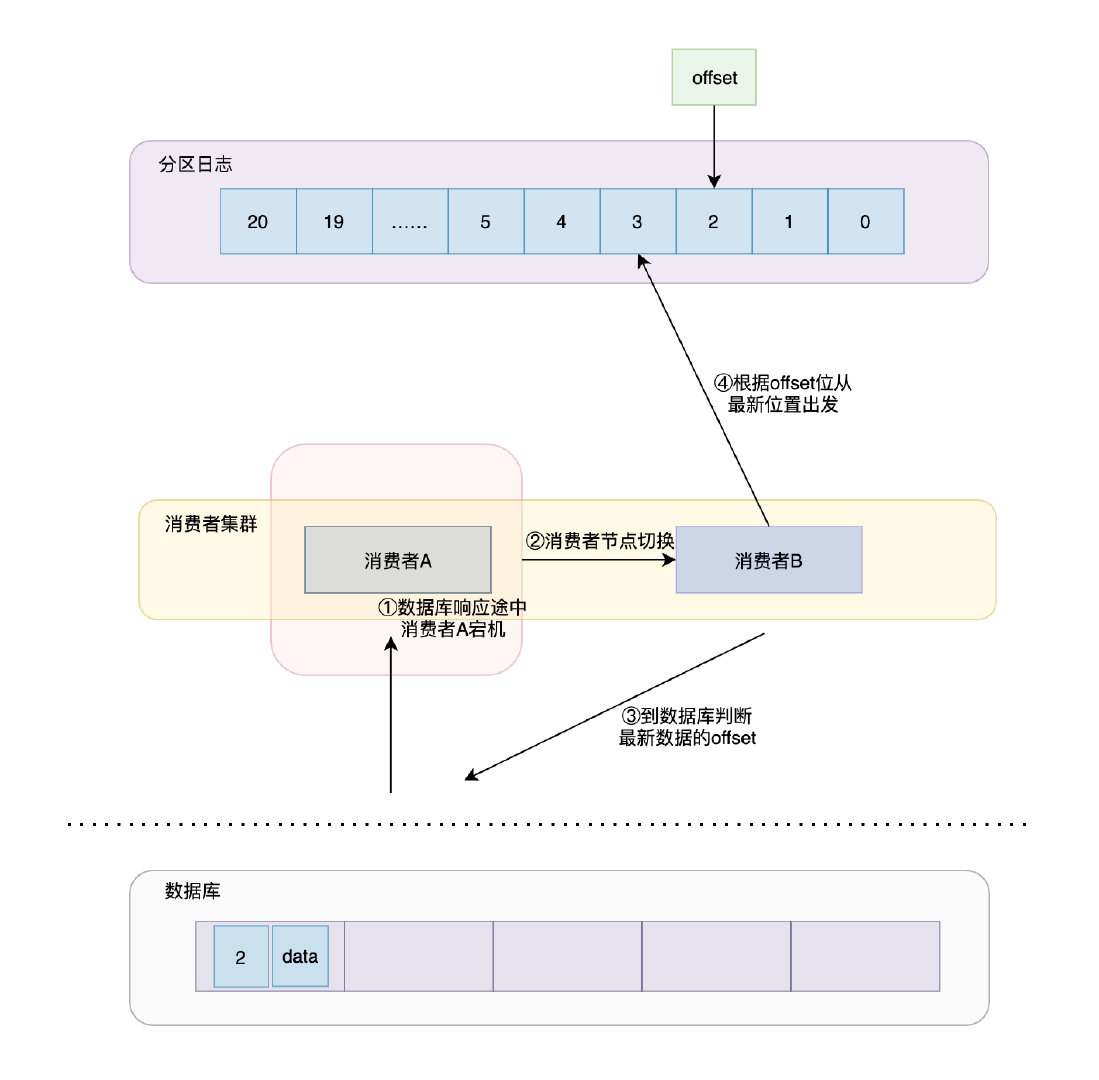
exactly once
代表訊息正好能被消費一次,不丟失,不重復,
在at least once的情況基礎上,假設consumerA在回傳ack給partition的程序中宕機了,那么consumerB不會跟著partition的offset走,它會先去資料庫里面查看最新訊息對應的偏移位,再根據這個偏移位回傳Kafka集群從對應的偏移位置出發,這就可以避免訊息重復和訊息丟失,
不知道有多少小伙伴看到這里的,如果覺得目前為止寫的還不錯的,可以幫忙點個贊讓,讓我看看有多少好學的寶寶,
4.資料截斷機制
我們開頭說了真正處理資料的是leader副本,follower副本只負責資料的同步和保存,那如果因為leader宕機了二者資料不一致會怎么樣呢?
在講一致性保證程序之前還需了解兩個Kafka用于表示副本資料同步的概念:
HW(High Watermark):中文翻譯為高水位,用來體現副本間資料同步的相對位置,consumer最多只能消費到HW所在的位置,通過HW我們可以判斷資料對副本是否可見,
LEO(Log End Offset):下一條待寫入訊息的記錄位置,
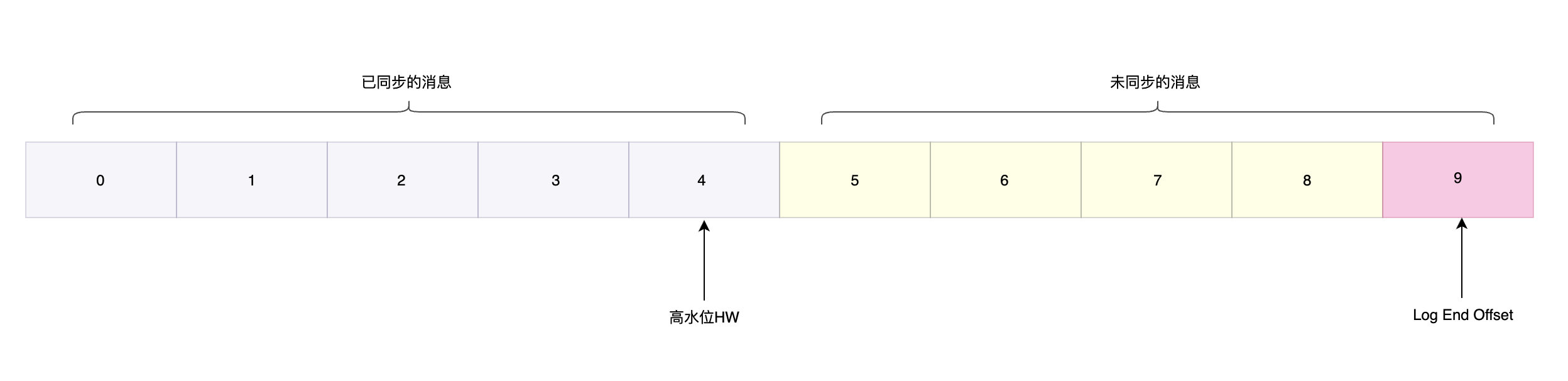
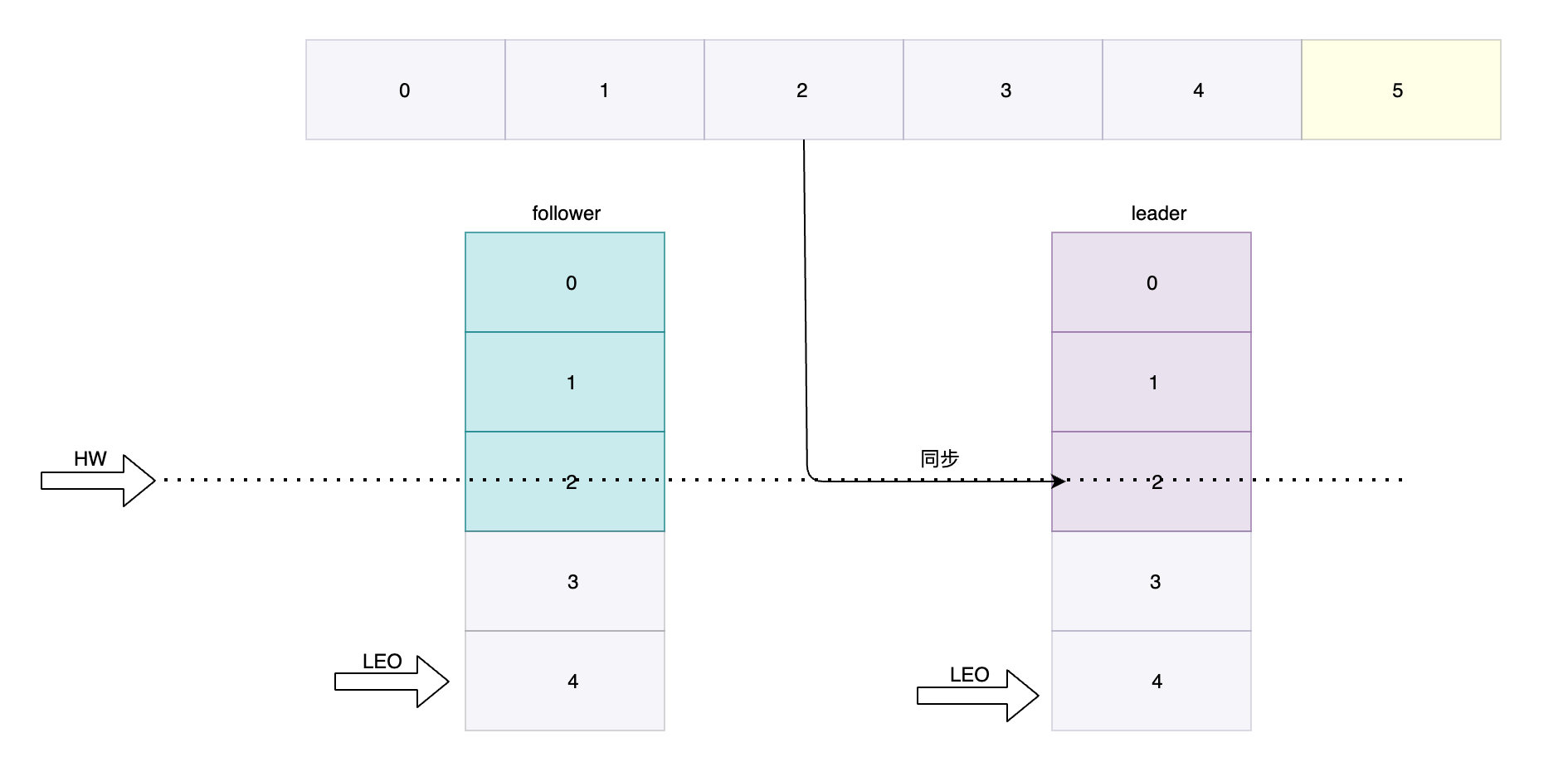
leader副本從生產者獲取訊息,follower副本實時從leder同步資料,此時它們的同步資料是一致的都同步到2這個位置,并且下一個寫入的訊息都是偏移位4:
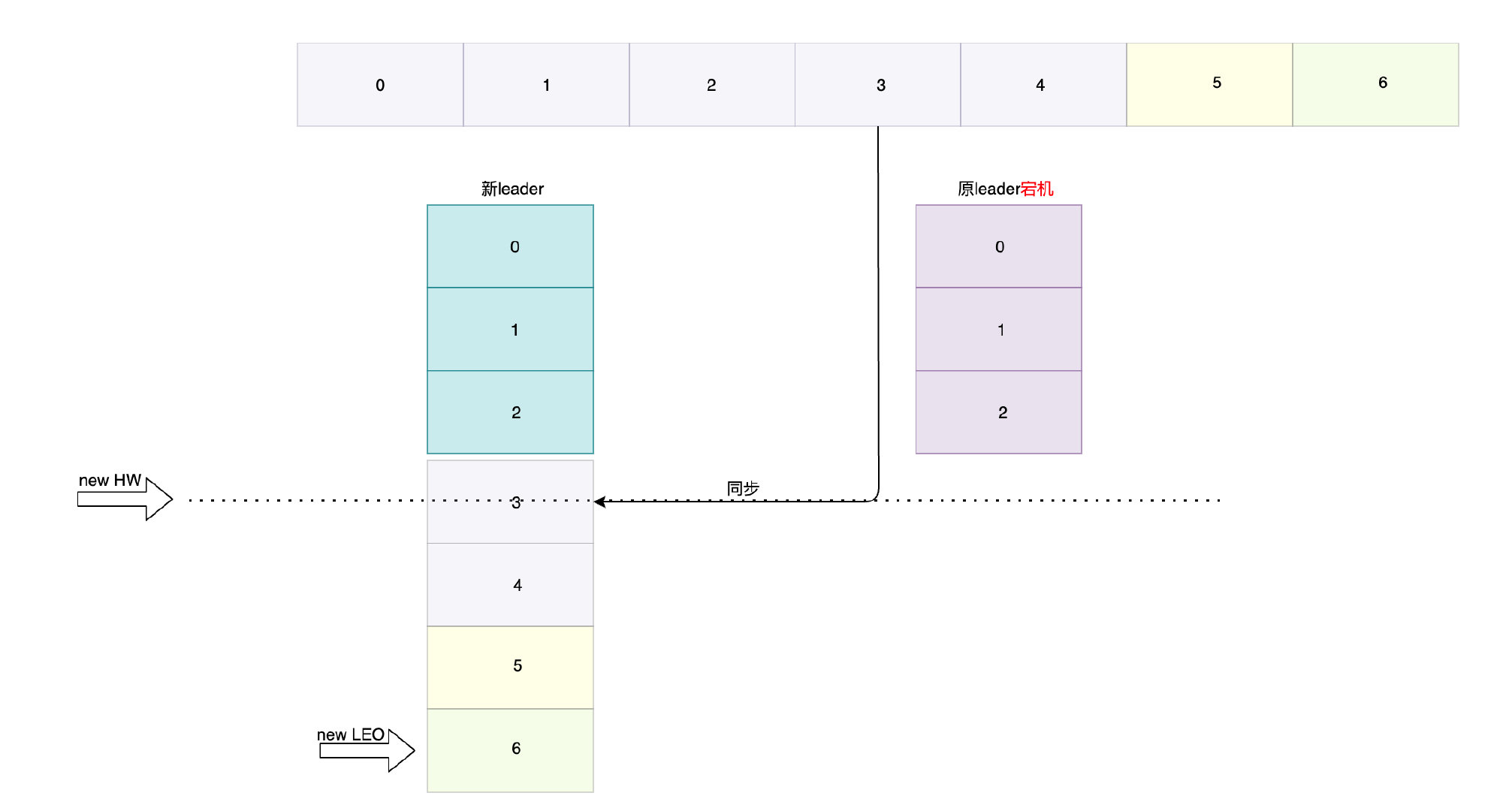
假設因為意外leader發生宕機,follower即被選為新leader,此后從生產者寫入最新的偏移位4和5:
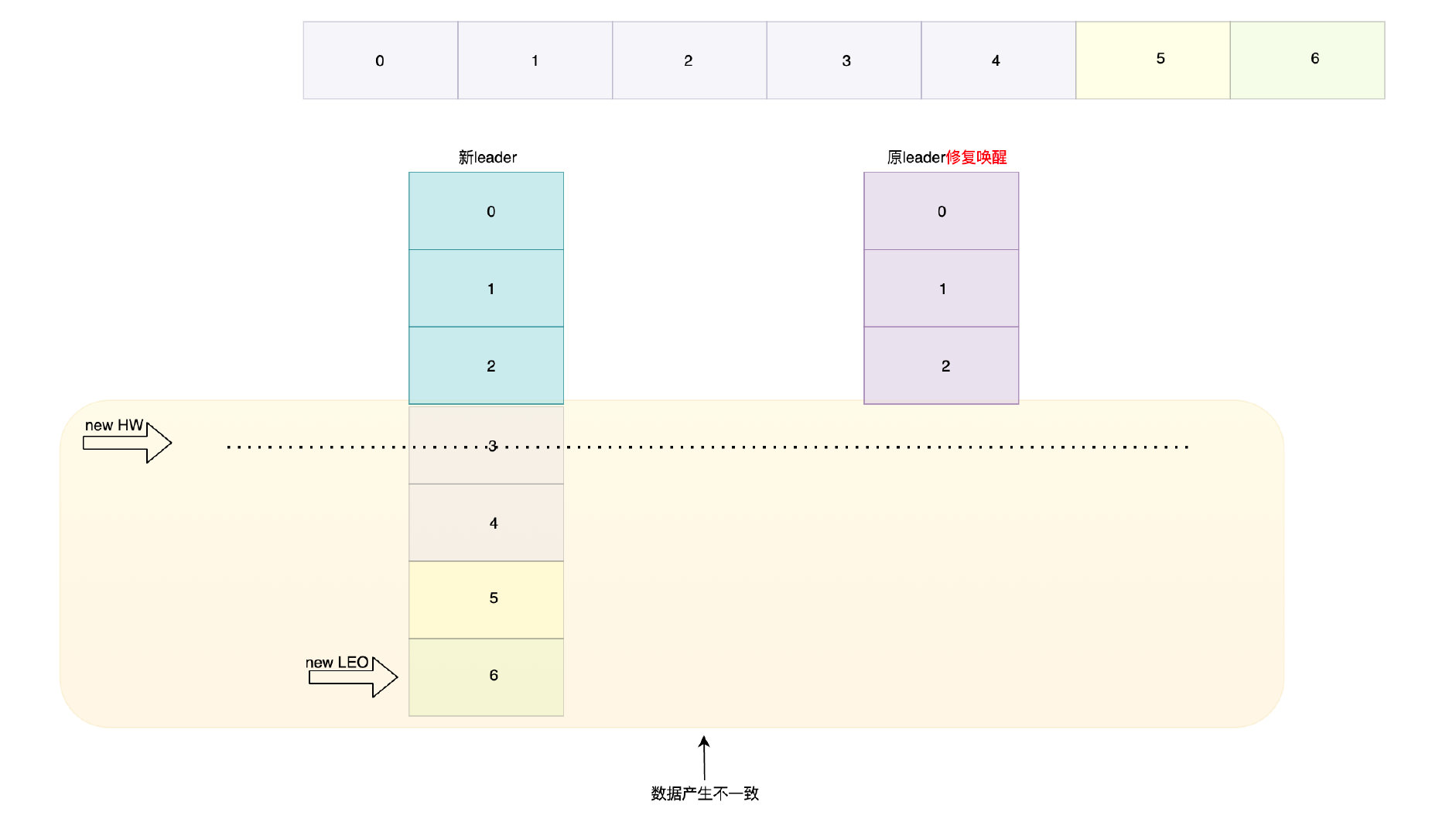
過了一段時間原leader通過修復恢復服務,它就會發現自己和新leader的資料是不一致的:
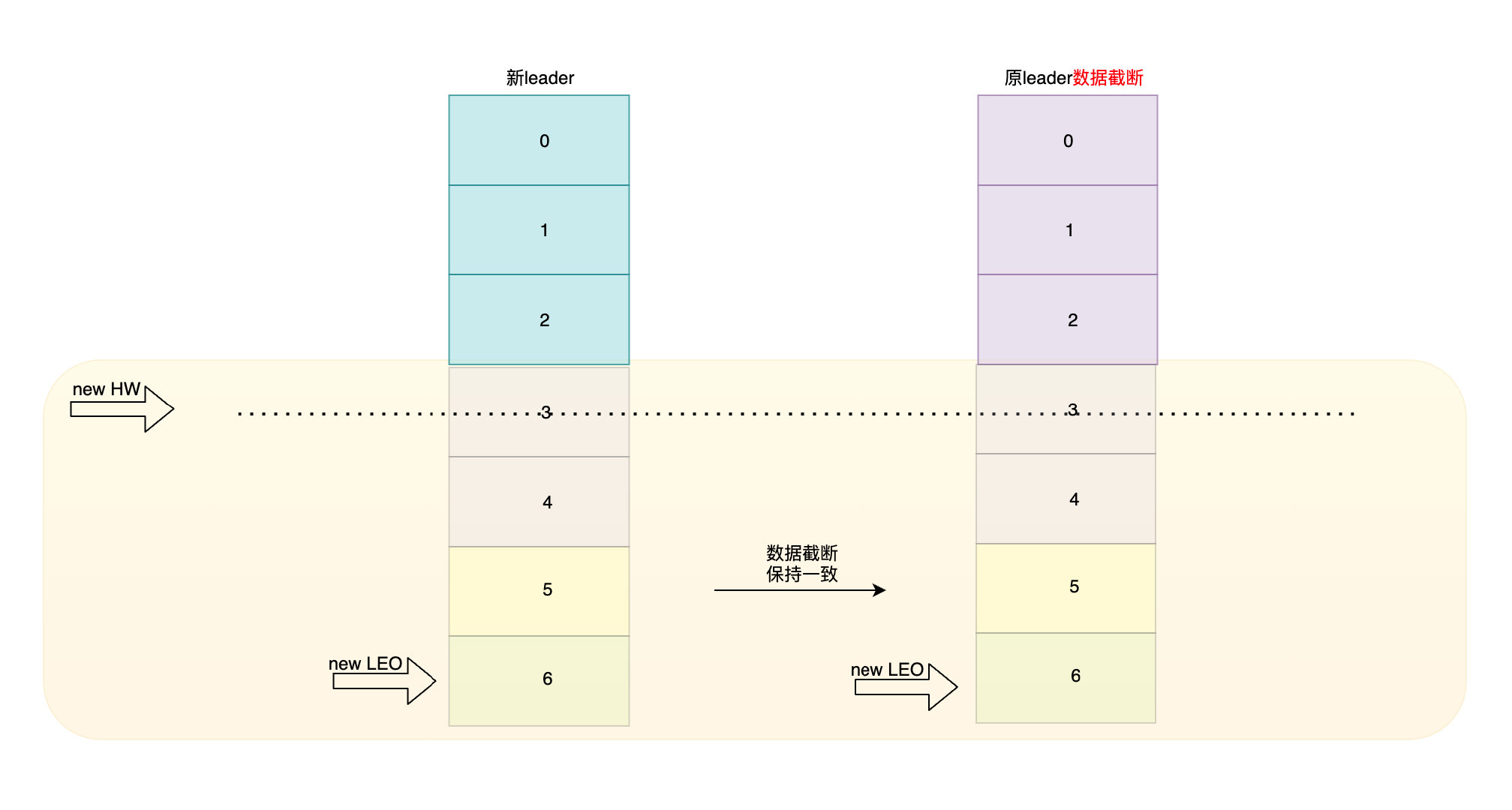
為了保證資料一致性就必須強行讓一方妥協,因為資料是不斷在重繪的,所以舊leader此時的優先級會小于新leader,因此它會將自己的資料截斷到與新leader相同的HW和LEO位置,確保和新leader的資料一定相同,這就是Kafka資料截斷機制,
5.資料清理機制
同其它中間件一樣,Kafka的主要作用是通信,所以即使是將資料保存在磁盤上它還是會占用一定空間,為了節約存盤空間它會通過一些機制對過期資料進行清理,
日志洗掉
日志洗掉會直接洗掉日志分段,kafka會維護一個定時任務來周期性檢查和洗掉「過期資料」,
基于時間的日志洗掉
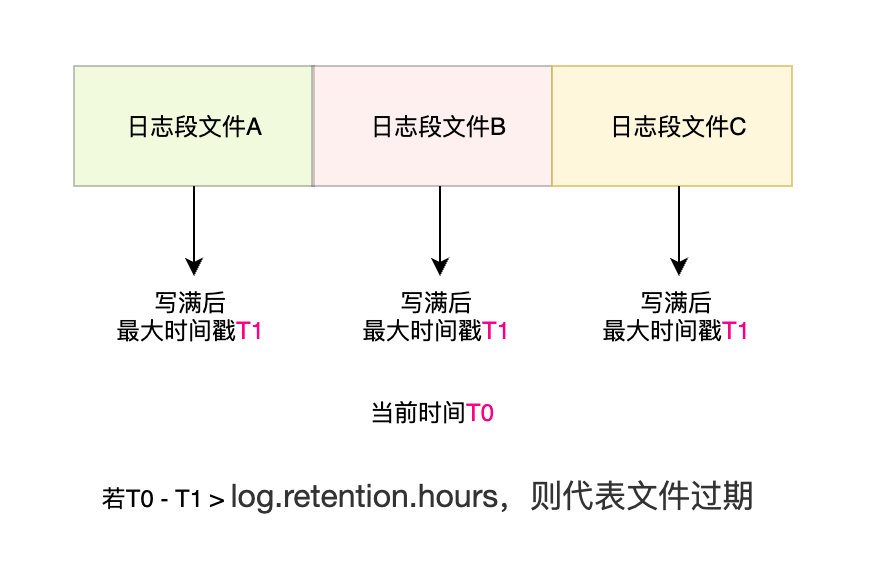
它在每一個日志段檔案里面都維護一個最大時間戳來確認當前配置的洗掉時間,只要日志段寫入新訊息該欄位都會被更新,一個日志段被寫滿了之后就不會再接收新的訊息,它會去創建一個新的日志段檔案往里面寫資料,
每一個日志段檔案被寫滿之后它的最大的時間戳都是保持不變的,Kafka只要通過當前時間與最大時間戳進行比較就可以判斷該日志段檔案是否過期,
Kafka默認配置log.retention.hours = 168,也就是7天的日志保留時間,
基于容量大小的日志洗掉
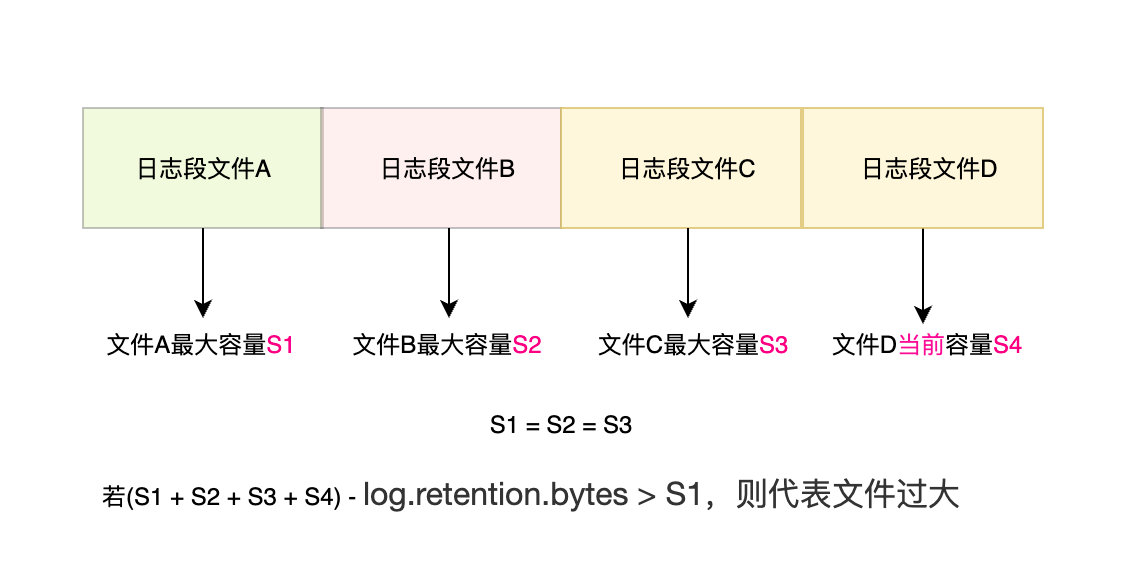
這和以上是異曲同工的方式, 只不過這次從時間換成了空間,
Kafka會通過每個日志段空間的大小計算一個總容量閾值,然后計算出當前的實際空間大小和總容量閾值的差值,如果這個差值大于單個日志段檔案的大小那么就會洗掉掉最舊的那個日志段檔案,反之則不做任何處理,
同理,這個閾值也可以通過log.retention.bytes引數來設定,
日志壓縮
Kafka的訊息是由鍵值組成的,如果日志段里存在多條相同key但是不同value的資料,那么它會選擇性地清除舊資料,保留最近一條記錄,
具體的壓縮方式就是創建一個檢查點檔案,從日志起始位置開始遍歷到最大結束位置,然后把每個訊息的key和key對應的offset保存在一個固定容量的SkimpyOffsetMap中,
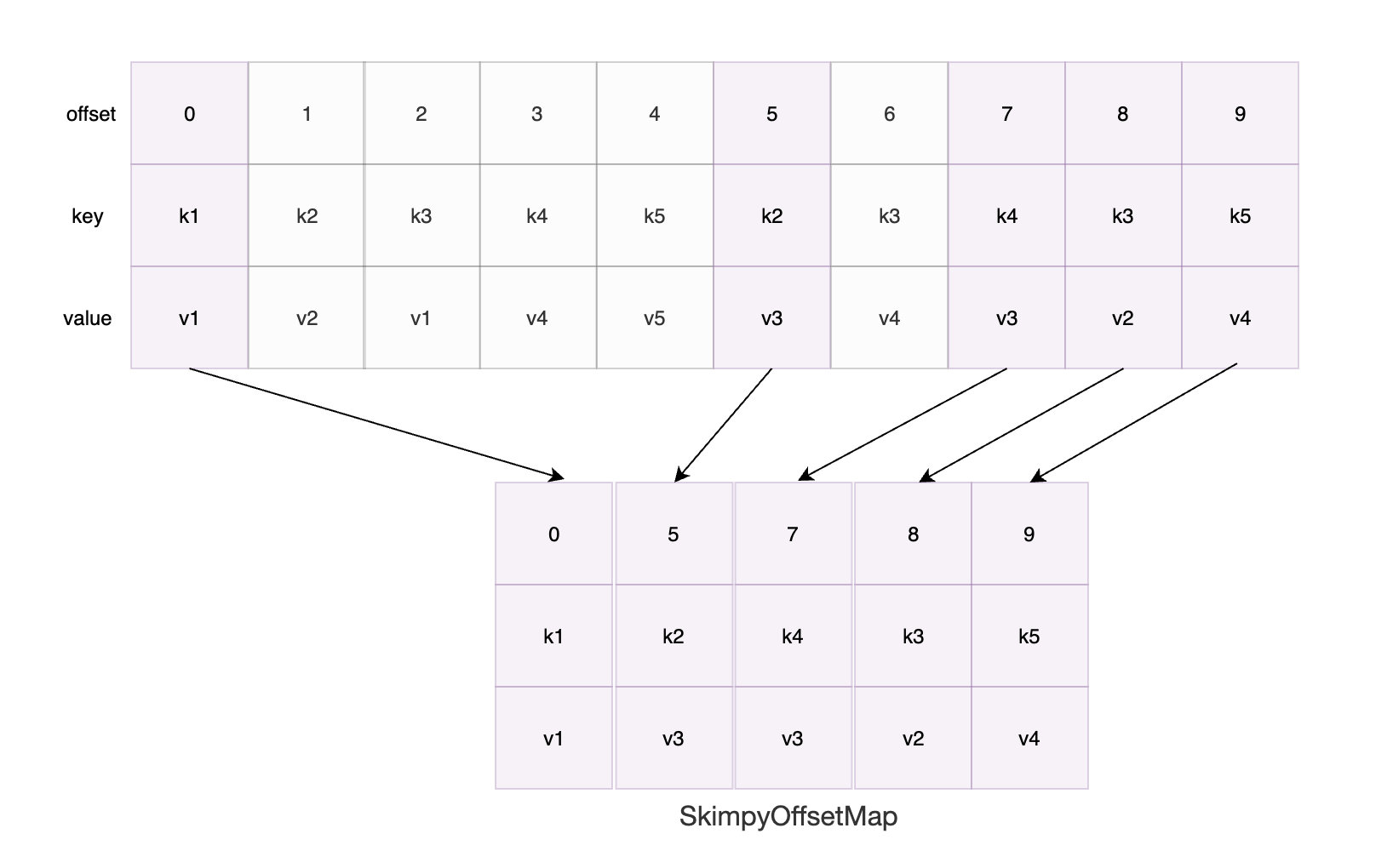 這樣前面的值就會被后面的覆寫掉,如果日志檔案里存在相同的key只有最新的那個會被保留,
這樣前面的值就會被后面的覆寫掉,如果日志檔案里存在相同的key只有最新的那個會被保留,
總結
Kafka通過ACK應答機制保證了不同組件之間的通信效率,通過副本同步機制、資料截斷和資料清理機制實作了對于資料的管理策略,保證整個系統運行效率,
作為一款高性能又同時兼顧高可靠性的訊息中間件來說,Kafka能吹的點實在太多,如果本篇文章對你有所幫助,點擊一下右下角的大拇指,下一次我們來詳細講解Kafka是如何實作副本間資料傳遞的,
你知道的越多,不知道的越多,各位的點贊評論都對我很重要,如果這篇文章有幫助你多一點點了解Kafka的話,可以在評論區來一波“變得更強”,
也希望你的bug和下面這張圖一樣,?? 退 ??退 ??退!我們下次見,

文章持續更新,可以微信搜一搜「 敖丙 」第一時間閱讀,關注后回復【資料】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/482829.html
標籤:其他
上一篇:java如何使用多個分隔符