對于 Java 部分的面試來說,突然想到并發這一塊的內容是不太完整的,這篇文章會通篇把多執行緒和并發都大致闡述一遍,至少能夠達到了解原理和使用的目的,內容會比較多,從最基本的執行緒到我們常用的類會統一說一遍,慢慢看,
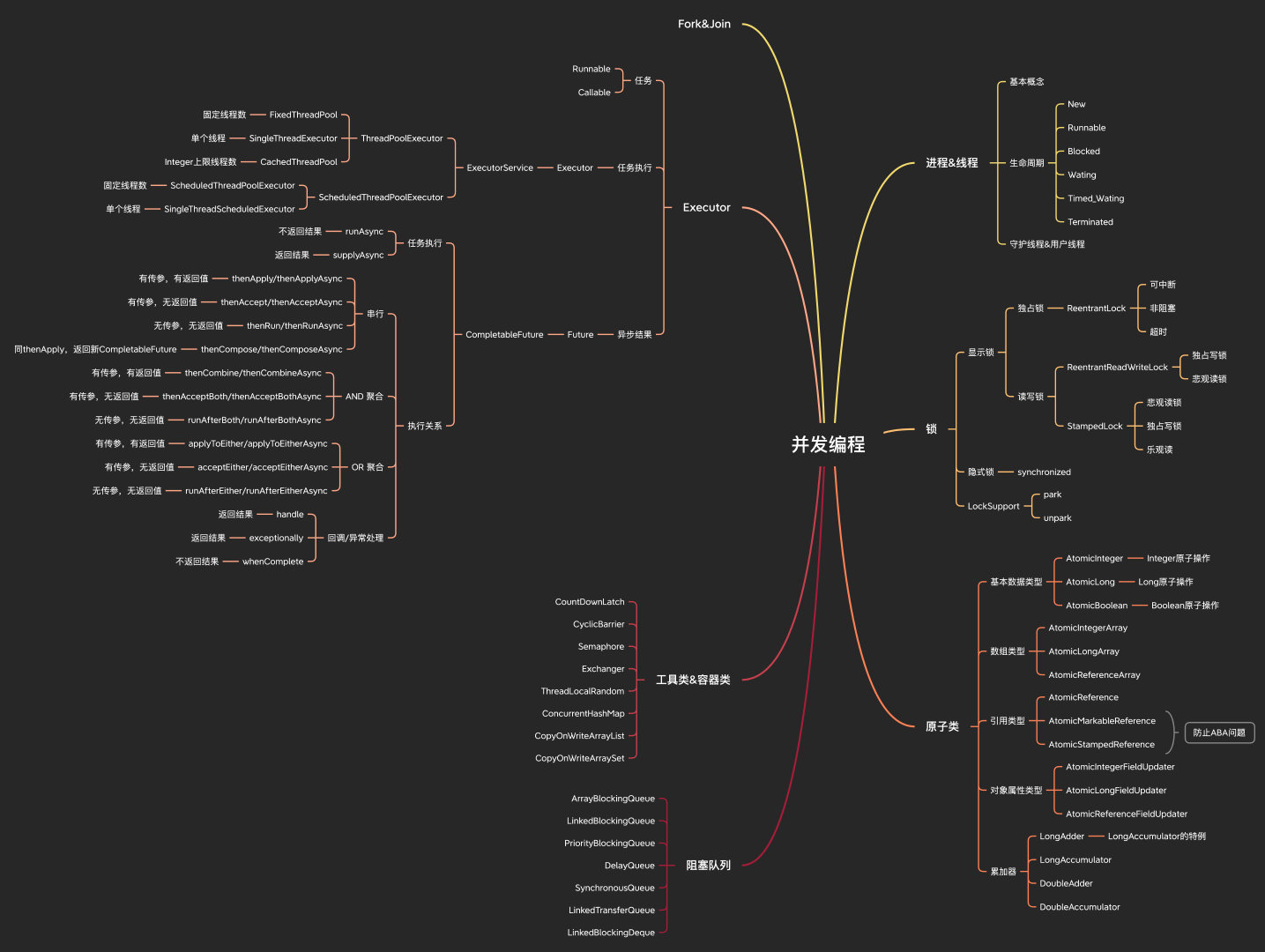
行程&執行緒
對于基本的概念,大家應該都很熟悉了,行程是資源分配的單位,執行緒是CPU調度的單位,執行緒是行程中的一個物體,
對于我們的Java程式來說,天生就是多執行緒的,我們通過main方法啟動,就是啟動了一個JVM的行程,同時創建一個名為main的執行緒,main就是JVM行程中的一個物體執行緒,
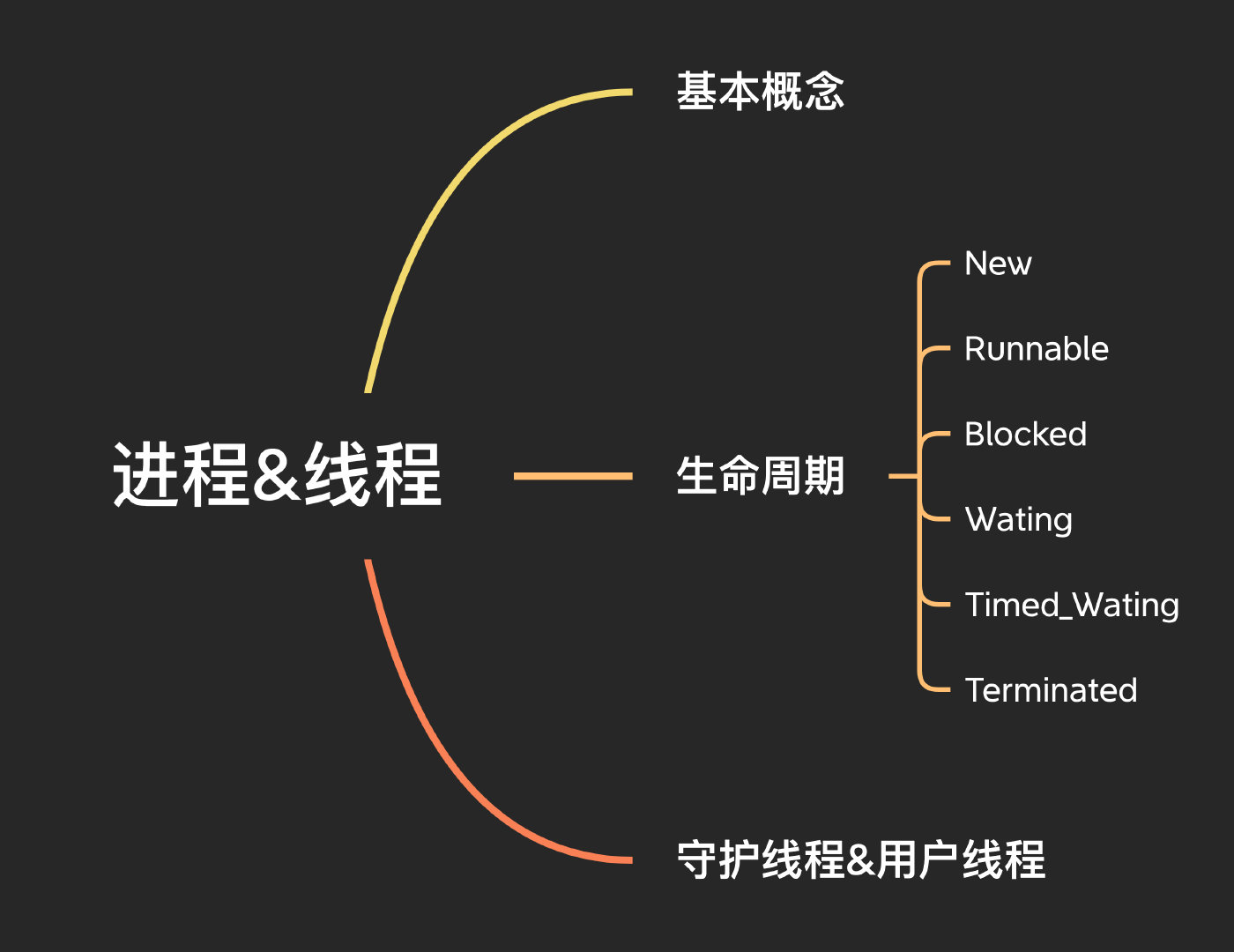
執行緒生命周期
執行緒幾種基本狀態:
- New,初始狀態,就是New了一個執行緒,但是還沒有呼叫start方法
- Runnable,可運行Ready或者運行Running狀態,執行緒的就緒和運行中狀態我們統稱為Runnable運行狀態
- Blocked/Wating/Timed_Wating,這些狀態統一就叫做休眠狀態
- Terminated,終止狀態
幾個狀態之間的轉換我們分別來說,
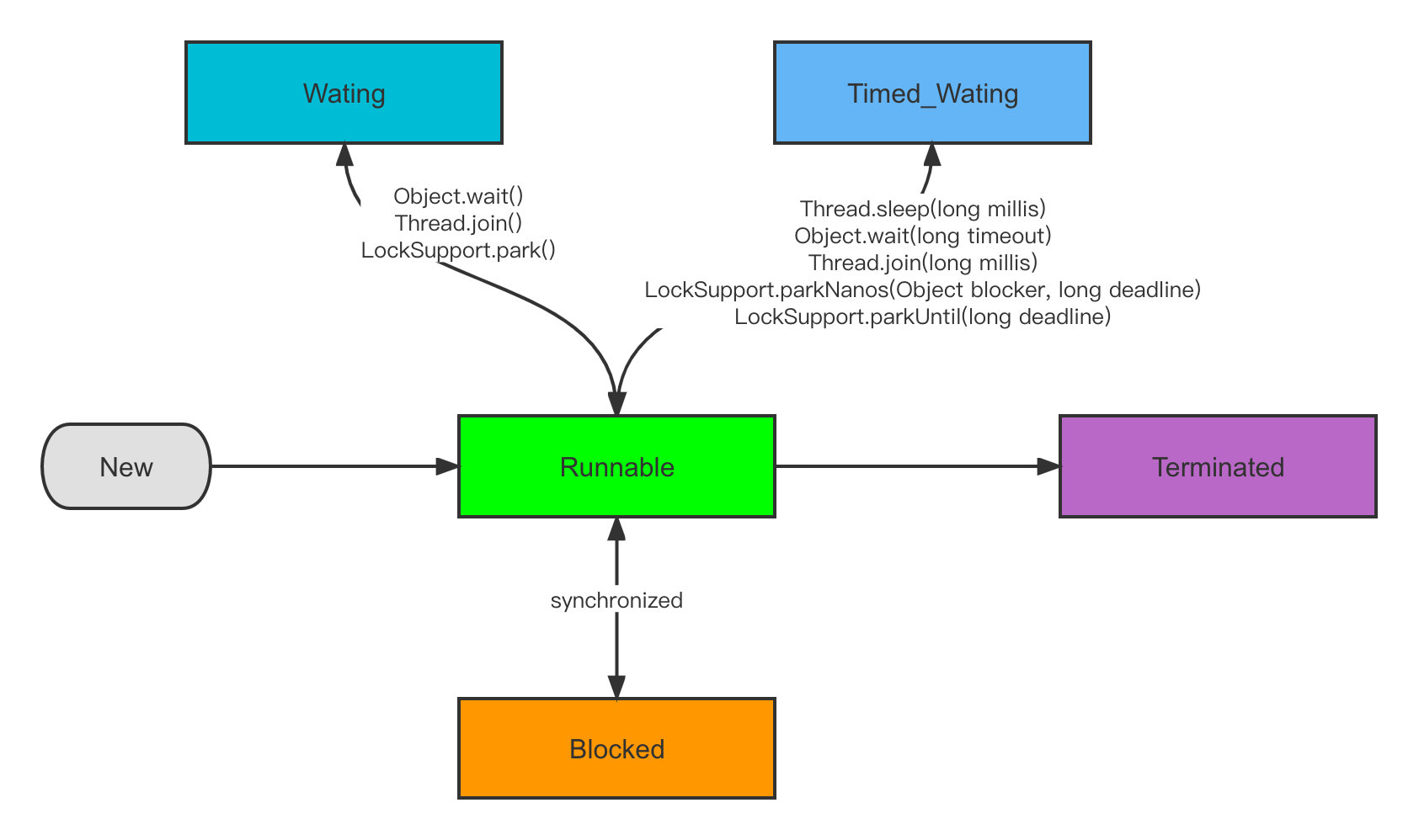
New:我們創建一個執行緒,但是執行緒沒有呼叫start方法,就是初始化狀態,
Runnable:呼叫start()啟動執行緒進入Ready可運行狀態,等待CPU調度之后進入到Running狀態,
Blocked:阻塞狀態,當執行緒在等待進入synchronized鎖的時候,進入阻塞狀態,
Waiting:等待狀態需要被顯示的喚醒,進入該狀態分為三種情況,在synchonized中呼叫Object.wait(),呼叫Thread.join(),呼叫LockSupport.park(),
Timed_Waiting:和Waiting的區別就是多了超時時間,不需要顯示喚醒,達到超時時間之后自動喚醒,呼叫圖中的一些帶有超時引數的方法則會進入該狀態,
Terminated:終止狀態,執行緒執行完畢,
守護執行緒&用戶執行緒
Java中的執行緒分為守護執行緒和用戶執行緒,上面我們提到的main執行緒其實就是一個用戶執行緒,
他們最主要的區別就在于,只要有非守護執行緒沒有結束,JVM就不會正常退出,而守護執行緒則不會影響JVM的退出,
可以通過簡單的方法設定一個執行緒為守護執行緒,
Thread t = new Thread();
t.setDaemon(true);
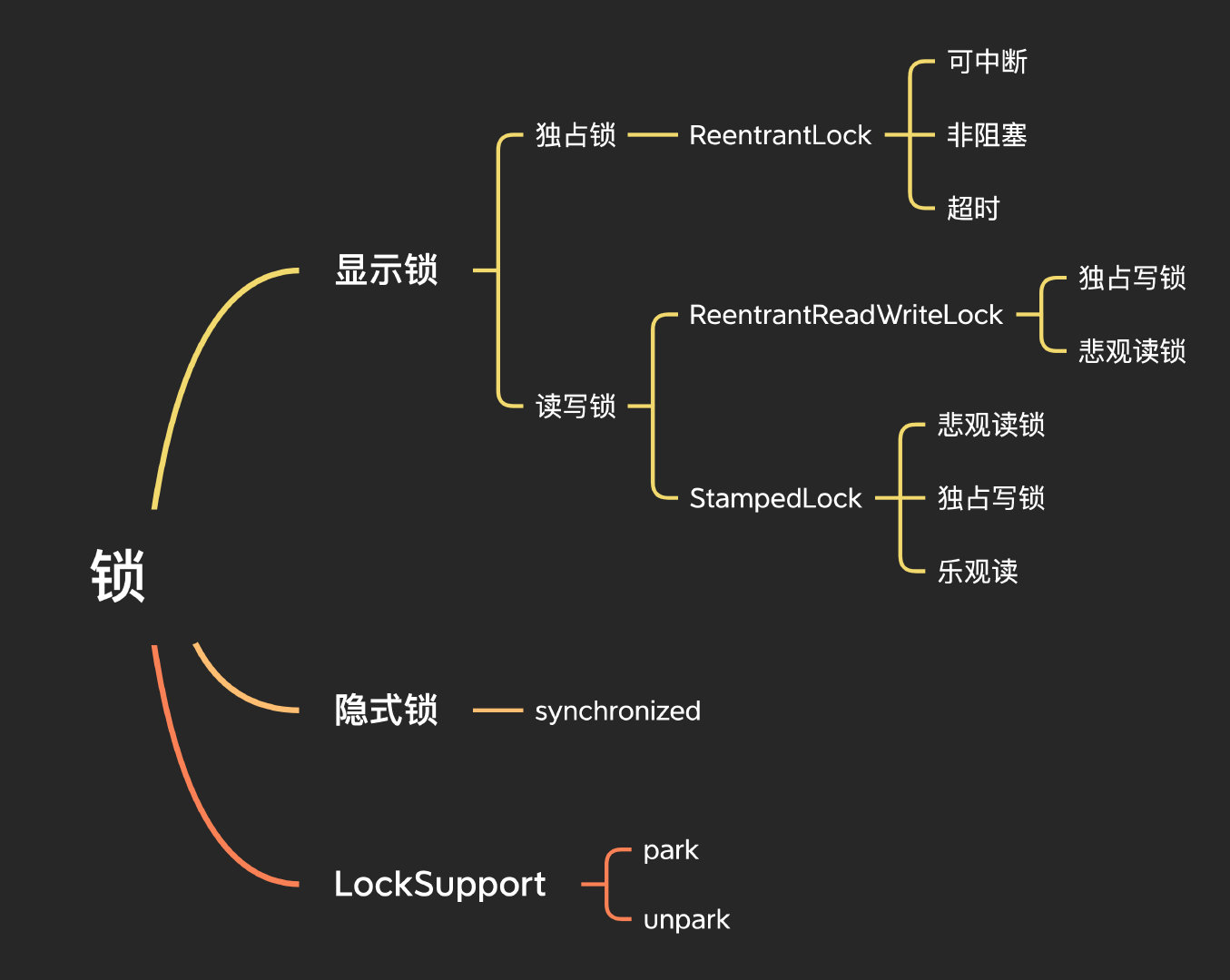
鎖
鎖是控制多執行緒并發訪問共享資源的方式,為了更簡單快速的了解Java中的鎖,我們可以按照顯示鎖和隱式鎖來做一個大致的區分,
隱式鎖
在沒有Lock介面之前,加鎖通過synchronzied實作,在之前的Java基礎系列中我已經說過了,就不在這里過多的闡述,此處參考之前寫過的,更多詳細可以看《我想進大廠》之Java基礎奪命連環16問,
synchronized是java提供的原子性內置鎖,這種內置的并且使用者看不到的鎖也被稱為監視器鎖,使用synchronized之后,會在編譯之后在同步的代碼塊前后加上monitorenter和monitorexit位元組碼指令,他依賴作業系統底層互斥鎖實作,主要作用就是實作原子性操作和解決共享變數的記憶體可見性問題,
執行monitorenter指令時會嘗試獲取物件鎖,如果物件沒有被鎖定或者已經獲得了鎖,鎖的計數器+1,此時其他競爭鎖的執行緒則會進入等待佇列中,
執行monitorexit指令時則會把計數器-1,當計數器值為0時,則鎖釋放,處于等待佇列中的執行緒再繼續競爭鎖,
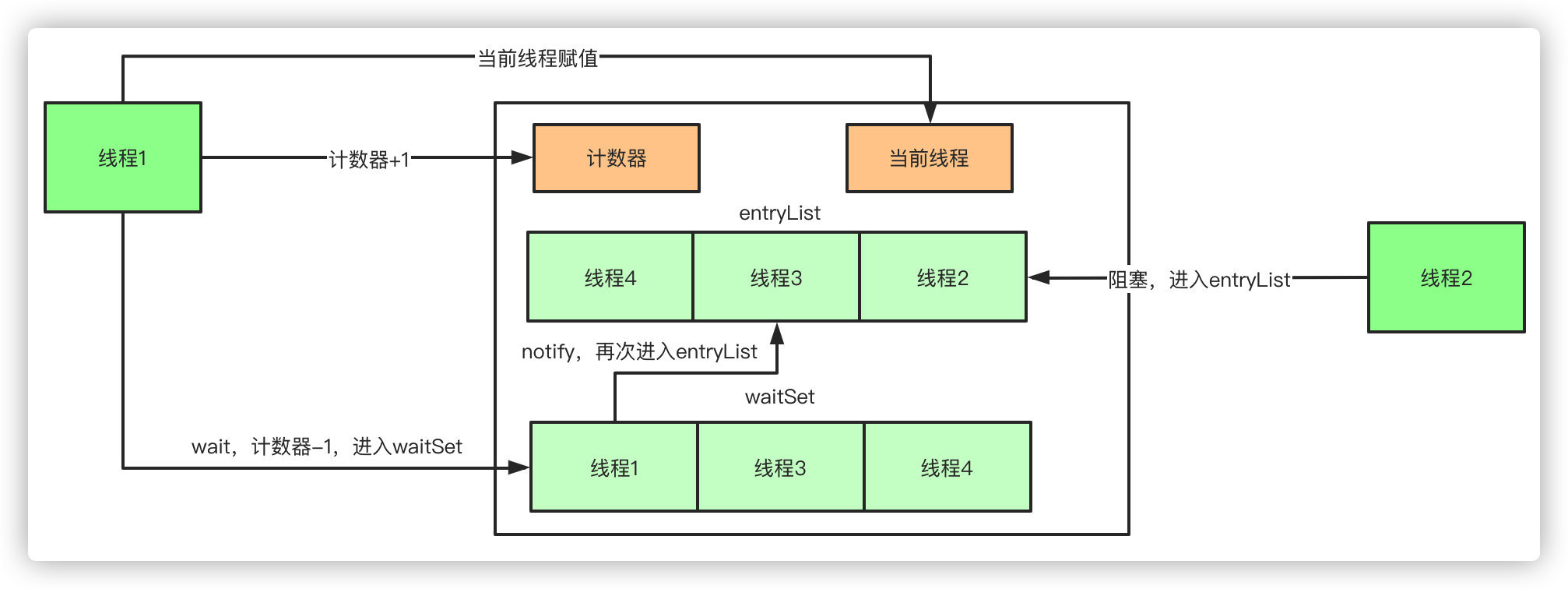
如果再深入到原始碼來說,synchronized實際上有兩個佇列waitSet和entryList,
- 當多個執行緒進入同步代碼塊時,首先進入entryList
- 有一個執行緒獲取到monitor鎖后,就賦值給當前執行緒,并且計數器+1
- 如果執行緒呼叫wait方法,將釋放鎖,當前執行緒置為null,計數器-1,同時進入waitSet等待被喚醒,呼叫notify或者notifyAll之后又會進入entryList競爭鎖
- 如果執行緒執行完畢,同樣釋放鎖,計數器-1,當前執行緒置為null
顯示鎖
雖然synchronized使用簡單,但是也使得加鎖的流程固化了,顯示鎖在Java1.5版本之后加入了Lock介面,可以通過宣告式顯示的加鎖和解鎖,
Lock lock = new ReentrantLock();
lock.lock(); //加鎖
lock.unlock(); //解鎖
獨占鎖
在上述的偽代碼中,我們使用到了ReentrantLock,它其實就是獨占鎖,獨占鎖保證任何時候都只有一個執行緒能獲得鎖,當然了,synchronized也是獨占鎖,
這里我們看ReentrantLock的幾個加鎖介面,
void lock(); //阻塞加鎖
void lockInterruptibly() throws InterruptedException; //可中斷
boolean tryLock(); //非阻塞
boolean tryLock(long time, TimeUnit unit) throws InterruptedException; //超時加鎖
這幾個加鎖介面,向我們明白地展示了他和synchronized的區別,
- 可中斷加鎖
lockInterruptibly,synchronized可能會有死鎖的問題,那么解決方案就是能回應中斷,當前執行緒加鎖時,如果其他執行緒呼叫當前執行緒的中斷方法,則會拋出例外, - 非阻塞加鎖
tryLock,呼叫后立刻回傳,獲取鎖則回傳true,否則回傳false - 支持超時加鎖
tryLock(long time, TimeUnit unit),超時時間內獲取鎖回傳true,否則回傳false - 支持公平和非公平鎖,公平指的是獲取鎖按照請求鎖的時間順序決定,先到先得,非公平則是直接競爭鎖,先到不一定先得
- 支持Condition
如果你看過阻塞佇列的原始碼,那么你對 Condition 應該挺了解了,我們舉個栗子來看看,我們需要實作:
- 如果佇列滿了,那么寫入阻塞
- 如果佇列空了,那么洗掉(取元素)阻塞
我們給阻塞佇列提供一個 put 寫入元素和 take 洗掉元素的方法,
put 時候加鎖且回應中斷,如果佇列滿了,notFull.await 釋放鎖,進入阻塞狀態,反之,則把元素添加到佇列中,notEmpty.signal 喚醒阻塞在洗掉元素的執行緒,
take 的時候一樣加鎖且回應中斷,如果佇列空了,notEmpty.await 進入釋放鎖,進入阻塞狀態,反之,則洗掉元素,notFull.signal 喚醒阻塞在添加元素的執行緒,
public class ConditionTest {
public static void main(String[] args) throws Exception {
ArrayBlockingQueue arrayBlockingQueue = new ArrayBlockingQueue(10);
}
static class ArrayBlockingQueue<E> {
private Object[] items;
int takeIndex;
int putIndex;
int count;
private ReentrantLock lock;
private Condition notEmpty;
private Condition notFull;
public ArrayBlockingQueue(int capacity) {
this.items = new Object[capacity];
lock = new ReentrantLock();
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public void put(E e) throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length) {
notFull.await();
}
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length){
putIndex = 0;
}
count++;
notEmpty.signal();
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
notEmpty.await();
}
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
final Object[] items = this.items;
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length){
takeIndex = 0;
}
count--;
notFull.signal();
return x;
}
}
}
讀寫鎖
讀寫鎖,也可以稱作共享鎖,區別于獨占鎖,共享鎖則可以允許多個執行緒同時持有,如ReentrantReadWriteLock允許多執行緒并發讀,要簡單概括就是:讀讀不互斥,讀寫互斥,寫寫互斥,
ReentrantReadWriteLock
通過閱讀原始碼發現它內部維護了兩個鎖:讀鎖和寫鎖,
private final ReentrantReadWriteLock.ReadLock readerLock;
private final ReentrantReadWriteLock.WriteLock writerLock;
本質上,不管是ReentrantLock還是ReentrantReadWriteLock都是基于AQS,AQS只有一個狀態位state,對于ReentrantReadWriteLock實作讀鎖和寫鎖則是對state做出了區分,高16位表示的是讀鎖的狀態,低16表示的是寫鎖的狀態,
我們可以看一個原始碼中給出的使用例子,
class CacheData {
Object data;
volatile boolean cacheValid;
final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock();
void processCachedData() {
rwl.readLock().lock();
if (!cacheValid) {
// 必須先釋放讀鎖,再加寫鎖
rwl.readLock().unlock();
rwl.writeLock().lock();
try {
// 重新校驗狀態,防止并發問題
if (!cacheValid) {
data = https://www.cnblogs.com/ilovejaney/p/...
cacheValid = true;
}
// 寫鎖降級為讀鎖
rwl.readLock().lock();
} finally {
rwl.writeLock().unlock(); // 寫鎖釋放,仍然持有讀鎖
}
} try {
use(data);
} finally {
rwl.readLock().unlock();
}
}
}
這個例子嵌套寫的其實不太好理解,因為他包含了一個寫鎖降級的概念,實際上我們自己寫最簡單的例子就是這樣,例子中給到的示例其實是一個意思,只是在寫鎖釋放前先降級為讀鎖,明白意思就好,
rwl.readLock().lock();
doSomething();
rwl.readLock().unlock();
rwl.writeLock().lock();
doSomething();
rwl.writeLock().unlock();
額外需要注意的是,寫鎖可以降級為讀鎖,但是讀鎖不能升級為寫鎖,比如下面這種寫法是不支持的,
rwl.readLock().lock();
doSomething();
rwl.writeLock().lock();
doSomething();
rwl.writeLock().unlock();
rwl.readLock().unlock();
StampedLock
這是JDK1.8之后新增的一個鎖,相比ReentrantReadWriteLock他的性能更好,在讀鎖和寫鎖的基礎上增加了一個樂觀讀鎖,
寫鎖:他的寫鎖基本上和ReentrantReadWriteLock一樣,但是不可重入,
讀鎖:也和ReentrantReadWriteLock一樣,但是不可重入,
樂觀讀鎖:普通的讀鎖通過CAS去修改當前state狀態,樂觀鎖實作原理則是加鎖的時候回傳一個stamp(鎖狀態),然后還需要呼叫一次validate(stamp)判斷當前是否有其他執行緒持有了寫鎖,通過的話則可以直接操作資料,反之升級到普通的讀鎖,之前我們說到讀寫鎖也是互斥的,那么樂觀讀和寫就不是這樣的了,他能支持一個執行緒去寫,所以,他性能更高的原因就來自于沒有CAS的操作,只是簡單的位運算拿到當前的鎖狀態stamp,并且能支持另外的一個執行緒去寫,
總結下來可以理解為:讀讀不互斥,讀寫不互斥,寫寫互斥,另外通過tryConvertToReadLock()和tryConvertToWriteLock()等方法支持鎖的升降級,
還是按照官方的檔案舉個栗子,方便理解,兩個方法分別表示樂觀鎖的使用和鎖升級的使用,
public class StampedLockTest {
private double x, y;
private final StampedLock sl = new StampedLock();
double distanceFromOrigin() {
// 樂觀鎖
long stamp = sl.tryOptimisticRead();
double currentX = x, currentY = y;
if (!sl.validate(stamp)) {
//狀態已經改變,升級到讀鎖,重新讀取一次最新的資料
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
void moveIfAtOrigin(double newX, double newY) {
// 可以使用樂觀鎖替代
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
// 嘗試升級到寫鎖
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
//升級成功,替換當前stamp標記
stamp = ws;
x = newX;
y = newY;
break;
} else {
//升級失敗,再次獲取寫鎖
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
}
LockSupport
LockSupport是一個比較基礎的工具類,基于Unsafe實作,主要就是提供執行緒阻塞和喚醒的能力,上面我們提到對執行緒生命周期狀態的時候也說過了,LockSupport的幾個park功能將會把執行緒阻塞,直到被喚醒,
看看他的幾個核心方法:
public static void park(); //阻塞當前執行緒
public static void parkNanos(long nanos); //阻塞當前執行緒加上了超時時間,達到超時時間之后回傳
public static void parkUntil(long deadline); //和上面類似,引數deadline代表的是從1970到現在時間的毫秒數
public static void unpark(Thread thread);// 喚醒執行緒
舉個栗子:
public class Test {
public static void main(String[] args) throws Exception {
int sleepTime = 3000;
Thread t = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + "掛起");
LockSupport.park();
System.out.println(Thread.currentThread().getName() + "繼續作業");
});
t.start();
System.out.println("主執行緒sleep" + sleepTime);
Thread.sleep(sleepTime);
System.out.println("主執行緒喚醒阻塞執行緒");
LockSupport.unpark(t);
}
}
//輸出如下
主執行緒sleep3000
Thread-0掛起
主執行緒喚醒阻塞執行緒
Thread-0繼續作業
原子類
多執行緒環境下操作變數,除了可以用我們上面一直說的加鎖的方式,還有其他更簡單快捷的辦法嗎?
JDK1.5之后引入的原子操作包下面的一些類提供給了我們一種無鎖操作變數的方式,這種通過CAS操作的方式更高效并且執行緒安全,
基本資料型別
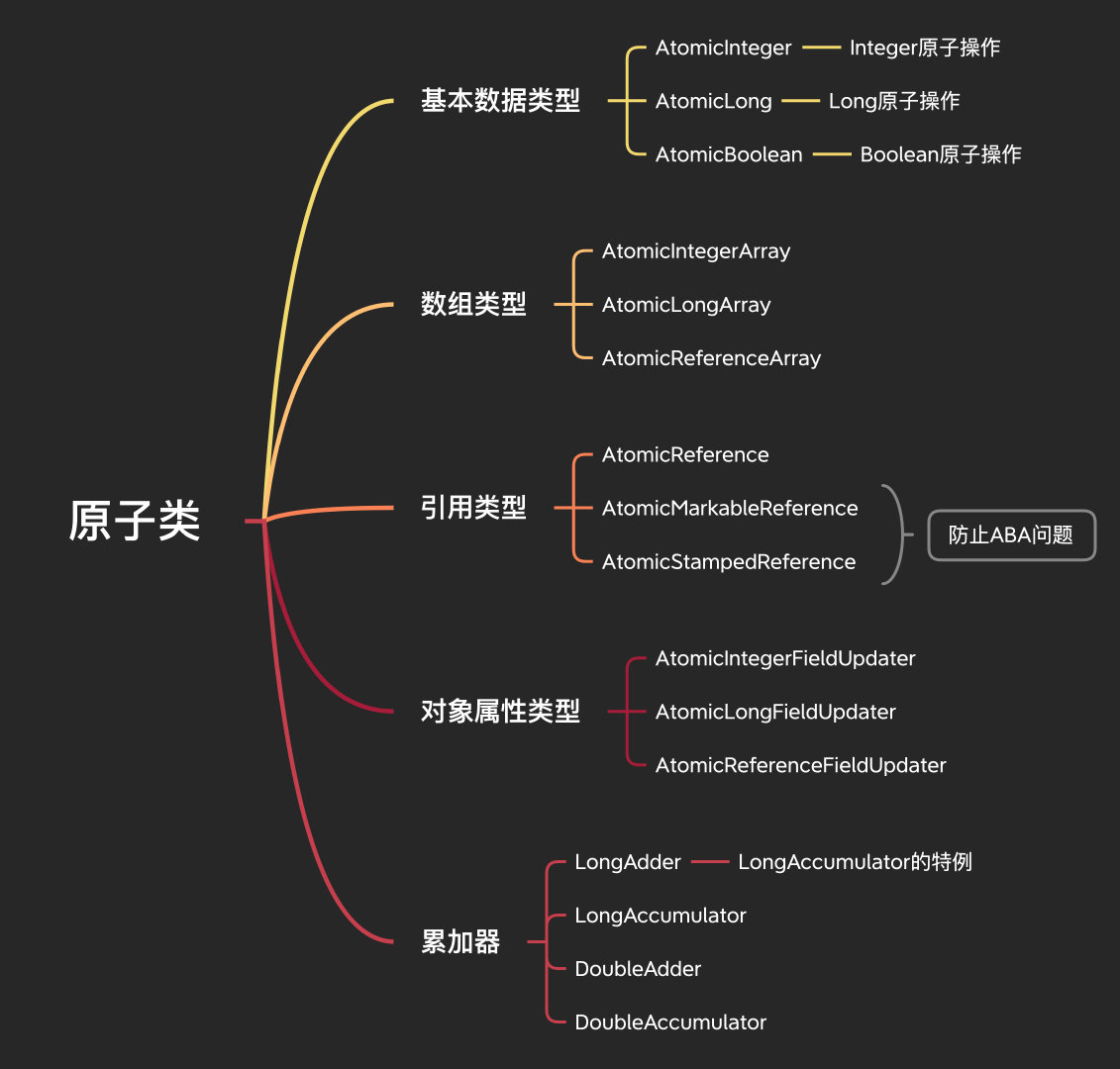
我們先說針對基本資料型別提供的AtomicInteger、AtomicLong、AtomicBoolean,看名字都知道是干嘛的,由于基本上沒什么區別,以AtomicInteger的方法舉例來說明,
public final int getAndIncrement(); //舊值+1,回傳舊值
public final int getAndDecrement(); //舊值-1,回傳舊值
public final int getAndAdd(int delta); //舊值+delta,回傳舊值
public final int getAndSet(int newValue); //舊值設定為newValue,回傳舊值
public final int getAndAccumulate(int x,IntBinaryOperator accumulatorFunction); //舊值根據傳入方法進行計算,回傳舊值
public final int getAndUpdate(IntUnaryOperator updateFunction)//舊值根據傳入進行計算,回傳舊值
與之相對應的還有一套方法比如incrementAndGet()等等,規則完全一樣,只是回傳的是新值,
我們看看下面的例子,針對自定義規則傳參,比如我們可以把計算規則改成乘法,
public class AtomicIntegerTest {
public static void main(String[] args) {
AtomicInteger atomic = new AtomicInteger(10);
System.out.println(atomic.getAndIncrement()); //10
System.out.println(atomic.getAndDecrement()); //11
System.out.println(atomic.getAndAdd(2));//10
System.out.println(atomic.getAndSet(10)); //12
System.out.println(atomic.get()); //10
System.out.println("=====================");
System.out.println(atomic.getAndAccumulate(3, (left, right) -> left * right)); // 10
System.out.println(atomic.get()); //30
System.out.println(atomic.getAndSet(10)); //30
System.out.println("=====================");
System.out.println(atomic.getAndUpdate(operand -> operand * 20)); // 10
System.out.println(atomic.get()); //200
}
}
另外提到一嘴,基本資料型別只給了Integer、Long、Boolean,那其他的基本資料型別呢?其實看下AtomicBoolean的原始碼我們發現其實他本質上是轉成了Integer處理的,那么針對其他的型別也可以參考這個思路來實作,
陣列
針對陣列型別的原子操作提供了3個,可以方便的更新陣列中的某個元素,
AtomicIntegerArray:針對Integer陣列的原子操作,
AtomicLongArray:針對Long陣列的原子操作,
AtomicReferenceArray:針對參考型別陣列的原子操作,
和上面說的Atomic其實也沒有太大的區別,還是以AtomicIntegerArray舉例說明,主要方法也基本一樣,
public final int getAndIncrement(int i);
public final int getAndDecrement(int i);
public final int getAndAdd(int i, int delta);
public final int getAndSet(int i, int newValue);
public final int getAndAccumulate(int i, int x,IntBinaryOperator accumulatorFunction);
public final int getAndUpdate(int i, IntUnaryOperator updateFunction);
操作一模一樣,只是多了一個引數表示當前索引的位置,同樣有incrementAndGet等一套方法,回傳最新值,沒有區別,對于參考型別AtomicReferenceArray來說只是沒有了increment和decrement這些方法,其他的也都大同小異,不再贅述,
說實話,這個都沒有舉栗子的必要,
public class AtomicIntegerArrayTest {
public static void main(String[] args) {
int[] array = {10};
AtomicIntegerArray atomic = new AtomicIntegerArray(array);
System.out.println(atomic.getAndIncrement(0)); //10
System.out.println(atomic.get(0));//11
System.out.println(atomic.getAndDecrement(0)); //11
System.out.println(atomic.getAndAdd(0, 2));//10
System.out.println(atomic.getAndSet(0, 10)); //12
System.out.println(atomic.get(0)); //10
System.out.println("=====================");
System.out.println(atomic.getAndAccumulate(0, 3, (left, right) -> left * right)); // 10
System.out.println(atomic.get(0)); //30
System.out.println(atomic.getAndSet(0, 10)); //30
System.out.println("=====================");
System.out.println(atomic.getAndUpdate(0, operand -> operand * 20)); // 10
System.out.println(atomic.get(0)); //200
}
}
參考型別
像AtomicInteger那種,只能原子更新一個變數,如果需要同時更新多個變數,就需要使用我們的參考型別的原子類,針對參考型別的原子操作提供了3個,
AtomicReference:針對參考型別的原子操作,
AtomicMarkableReference:針對帶有標記位的參考型別的原子操作,
AtomicStampedReference:針對帶有標記位的參考型別的原子操作,
AtomicMarkableReference和AtomicStampedReference非常類似,他們是為了解決CAS中的ABA的問題(別說你不知道啥是ABA問題),只不過這個標記的型別不同,我們看下原始碼,
AtomicMarkableReference標記型別是布爾型別,所以其實他版本就倆,true和false,
AtomicMarkableReference標記型別是整型,那可不就是正常的版本號嘛,
public class AtomicMarkableReference<V> {
private static class Pair<T> {
final T reference;
final boolean mark; //標記
}
}
public class AtomicStampedReference<V> {
private static class Pair<T> {
final T reference;
final int stamp; // 標記
}
}
方法還是那幾個,老樣子,
public final V getAndSet(V newValue);
public final V getAndUpdate(UnaryOperator<V> updateFunction);
public final V getAndAccumulate(V x, BinaryOperator<V> accumulatorFunction);
public final boolean compareAndSet(V expect, V update);
簡單舉個栗子:
public class AtomicReferenceTest {
public static void main(String[] args) {
User user = new User(1L, "test", "test");
AtomicReference<User> atomic = new AtomicReference<>(user);
User pwdUpdateUser = new User(1L,"test","newPwd");
System.out.println(atomic.getAndSet(pwdUpdateUser));
System.out.println(atomic.get());
}
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
static class User {
private Long id;
private String username;
private String password;
}
}
//輸出
AtomicReferenceTest.User(id=1, username=test, password=test)
AtomicReferenceTest.User(id=1, username=test, password=newPwd)
物件屬性
針對物件屬性的原子操作也還是提供了3個,
AtomicIntegerFieldUpdater:針對參考型別里的整型屬性的原子操作,
AtomicLongFieldUpdater:針對參考型別里的長整型屬性的原子操作,
AtomicReferenceFieldUpdater:針對參考型別里的屬性的原子操作,
需要注意的是,需要更新的屬性欄位不能是private,并且必須用volatile修飾,否則會報錯,
舉個栗子:
public class AtomicReferenceFieldTest {
public static void main(String[] args) {
AtomicReferenceFieldUpdater<User, String> atomic = AtomicReferenceFieldUpdater.newUpdater(User.class, String.class, "password");
User user = new User(1L, "test", "test");
System.out.println(atomic.getAndSet(user, "newPwd"));
System.out.println(atomic.get(user));
}
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
static class User {
private Long id;
private String username;
volatile String password;
}
}
//輸出
test
newPwd
累加器
累加器有4個,都來自JDK1.8新增的,為啥新增呢?因為Doug大佬覺得AtomicLong還不夠快,雖然說通過CAS操作已經很快了,但是眾所知周,高并發同時操作一個共享變數只有一個成功,那其他的執行緒都在無限自旋,大量的浪費了CPU的資源,所以累加器Accumulator的思路就是把一個變數拆成多個變數,這樣多執行緒去操作競爭多個變數資源,性能不就提升了嘛,
也就是說,在高并發的場景下,可以盡量的使用下面這些類來替換基礎型別操作的那些AtomicLong之類的,可以提高性能,
LongAdder:Long型別的累加,LongAccumulator的特例,
LongAccumulator:Long型別的累加,
DoubleAdder:Double型別的累加,DoubleAccumulator的特例,
DoubleAccumulator:Double型別的累加,
由于LongAdder和DoubleAdder都是一樣的,我們以LongAdder和LongAccumulator舉例來說明它的一些簡單的原理,
LongAdder
它繼承自Striped64,內部維護了一個Cell陣列,核心思想就是把單個變數的競爭拆分,多執行緒下如果一個Cell競爭失敗,轉而去其他Cell再次CAS重試,
transient volatile Cell[] cells;
transient volatile long base;
在計算當前值的時候,則是累加所有cell的value再加上base,
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
這里還涉及到一個偽共享的概念,至于啥是偽共享,看看之前我寫的真實位元組二面:什么是偽共享?,
解決偽共享的真正的核心就在Cell陣列,可以看到,Cell陣列使用了Contented注解,
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = https://www.cnblogs.com/ilovejaney/p/x; }
}
在上面我們提到陣列的記憶體地址都是連續的,所以陣列內的元素經常會被放入一個快取行,這樣的話就會帶來偽共享的問題,影響性能,這里使用Contented進行填充,就避免了偽共享的問題,使得陣列中的元素不再共享一個快取行,
LongAccumulator
上面說到,LongAdder其實就是LongAccumulator的一個特例,相比LongAdder他的功能會更加強大,可以自定義累加的規則,在上面演示AtomicInteger功能的時候其實我們也使用過了,
*** ***,實際上就是實作了一個LongAdder的功能,初始值我們傳入0,而LongAdder的初始值就是0并且只能是0,
public class LongAdderTest {
public static void main(String[] args) {
LongAdder longAdder = new LongAdder();
LongAccumulator accumulator = new LongAccumulator((left, right) -> 0, 0);
}
}
工具類&容器類
這里要說到一些我們在平時開發中經常使用到的一些類以及他們的實作原理,
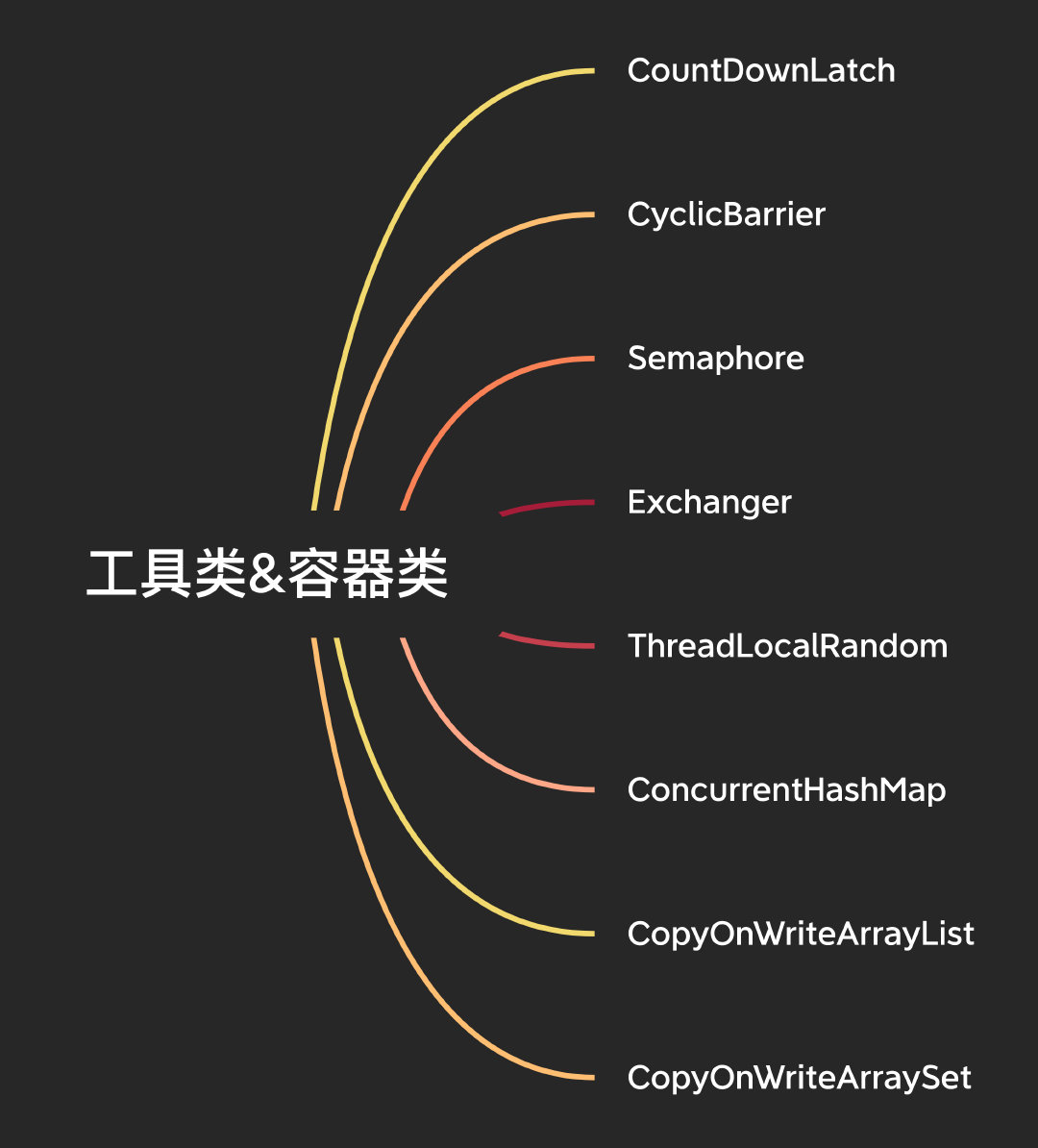
CountDownLatch
CountDownLatch適用于在多執行緒的場景需要等待所有子執行緒全部執行完畢之后再做操作的場景,
假設現在我們有一個業務場景,我們需要呼叫多個RPC介面去查詢資料并且寫入excel,最后把所有excel打包壓縮發送郵件出去,
public class CountDownLatchTest {
public static void main(String[] args) throws Exception{
ExecutorService executorService = Executors.newFixedThreadPool(10);
CountDownLatch countDownLatch = new CountDownLatch(2);
executorService.submit(()->{
try {
Thread.sleep(1000);
System.out.println("寫excelA完成");
countDownLatch.countDown();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
executorService.submit(()->{
try {
Thread.sleep(3000);
System.out.println("寫excelB完成");
countDownLatch.countDown();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
System.out.println("等待excel寫入完成");
countDownLatch.await();
System.out.println("開始打包發送資料..");
executorService.shutdown();
}
}
//輸出
等待excel寫入完成
寫excelA完成
寫excelB完成
開始打包發送資料..
整個程序如下:
初始化一個CountDownLatch實體傳參2,因為我們有2個子執行緒,每次子執行緒執行完畢之后呼叫countDown()方法給計數器-1,主執行緒呼叫await()方法后會被阻塞,直到最后計數器變為0,await()方法回傳,執行完畢,
他和join有個區別,像我們這里用的是ExecutorService創建執行緒池,是沒法使用join的,相比起來,CountDownLatch的使用會顯得更加靈活,
CountDownLatch基于AQS實作,用volatile修飾state變數維持倒數狀態,多執行緒共享變數可見,
- CountDownLatch通過建構式初始化傳入引數實際為AQS的state變數賦值,維持計數器倒數狀態
- 當主執行緒呼叫await()方法時,當前執行緒會被阻塞,當state不為0時進入AQS阻塞佇列等待,
- 其他執行緒呼叫countDown()時,通過CAS修改state值-1,當state值為0的時候,喚醒所有呼叫await()方法阻塞的執行緒
CyclicBarrier
CyclicBarrier叫做回環屏障,它的作用是讓一組執行緒全部達到一個狀態之后再全部同時執行,他和CountDownLatch主要區別在于,CountDownLatch的計數器只能用一次,而CyclicBarrier的計數器狀態則是可以一直重用的,
我們可以使用CyclicBarrier一樣實作上面的需求,
public class CyclicBarrierTest {
public static void main(String[] args) throws Exception{
ExecutorService executorService = Executors.newFixedThreadPool(10);
CyclicBarrier cyclicBarrier = new CyclicBarrier(2, () -> {
System.out.println("開始打包發送資料..");
});
executorService.submit(()->{
try {
Thread.sleep(1000);
System.out.println("寫excelA完成");
cyclicBarrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
});
executorService.submit(()->{
try {
Thread.sleep(3000);
System.out.println("寫excelB完成");
cyclicBarrier.await();
} catch (Exception e) {
throw new RuntimeException(e);
}
});
System.out.println("等待excel寫入完成");
executorService.shutdown();
}
}
//輸出
等待excel寫入完成
寫excelA完成
寫excelB完成
開始打包發送資料..
初始化的時候我們傳入2個執行緒和一個回呼方法,執行緒呼叫await()之后進入阻塞狀態并且計數器-1,這個阻塞點被稱作為屏障點或者同步點,只有最后一個執行緒到達屏障點的時候,所有被屏障攔截的執行緒才能繼續運行,這也是叫做回環屏障的名稱原因,
而當計數器為0時,就去執行CyclicBarrier建構式中的回呼方法,回呼方法執行完成之后,就會退出屏障點,喚醒其他阻塞中的執行緒,
CyclicBarrier基于ReentrantLock實作,本質上還是基于AQS實作的,內部維護parties記錄總執行緒數,count用于計數,最開始count=parties,呼叫await()之后count原子遞減,當count為0之后,再次將parties賦值給count,這就是復用的原理,
- 當子執行緒呼叫await()方法時,獲取獨占鎖ReentrantLock,同時對count遞減,進入阻塞佇列,然后釋放鎖
- 當第一個執行緒被阻塞同時釋放鎖之后,其他子執行緒競爭獲取鎖,操作同1
- 直到最后count為0,執行CyclicBarrier建構式中的任務,執行完畢之后子執行緒繼續向下執行,計數重置,開始下一輪回圈
Semaphore
Semaphore叫做信號量,和前面兩個不同的是,他的計數器是遞增的,信號量這玩意兒在限流中就經常使用到,
public class SemaphoreTest {
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Semaphore semaphore = new Semaphore(0);
executorService.submit(() -> {
try {
Thread.sleep(1000);
System.out.println("寫excelA完成");
semaphore.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
executorService.submit(() -> {
try {
Thread.sleep(3000);
System.out.println("寫excelB完成");
semaphore.release();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
System.out.println("等待excel寫入完成");
semaphore.acquire(2);
System.out.println("開始打包發送資料..");
executorService.shutdown();
}
}
//輸出
等待excel寫入完成
寫excelA完成
寫excelB完成
開始打包發送資料..
稍微和前兩個有點區別,建構式接受引數表示可用的許可證的數量,acquire方法表示獲取一個許可證,使用完之后release歸還許可證,
當子執行緒呼叫release()方法時,計數器遞增,主執行緒acquire()傳參為2則說明主執行緒一直阻塞,直到計數器為2才會回傳,
Semaphore還還還是基于AQS實作的,同時獲取信號量有公平和非公平兩種策略,通過建構式的傳參可以修改,默認則是非公平的策略,
- 先說非公平的策略,主執行緒呼叫acquire()方法時,用當前信號量值-需要獲取的值,如果小于0,說明還沒有達到信號量的要求值,則會進入AQS的阻塞佇列,大于0則通過CAS設定當前信號量為剩余值,同時回傳剩余值,而對于公平策略來說,如果當前有其他執行緒在等待獲取資源,那么自己就會進入AQS阻塞佇列排隊,
- 子執行緒呼叫release()給當前信號量值計數器+1(增加的值數量由傳參決定),同時不停的嘗試喚醒因為呼叫acquire()進入阻塞的執行緒
Exchanger
Exchanger用于兩個執行緒之間交換資料,如果兩個執行緒都到達同步點,這兩個執行緒可以互相交換他們的資料,
舉個栗子,A和B兩個執行緒需要交換他們自己寫的資料以便核對資料是否一致,
public class ExchangerTest {
public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(10);
Exchanger<String> exchanger = new Exchanger<>();
executorService.submit(() -> {
try {
Thread.sleep(1000);
System.out.println("寫excelA完成");
System.out.println("A獲取到資料=" + exchanger.exchange("excelA"));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
executorService.submit(() -> {
try {
Thread.sleep(3000);
System.out.println("寫excelB完成");
System.out.println("B獲取到資料=" + exchanger.exchange("excelB"));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
executorService.shutdown();
}
}
//輸出
寫excelA完成
寫excelB完成
B獲取到資料=excelA
A獲取到資料=excelB
A寫完之后exchange會一直阻塞等待,直到另外一個執行緒也exchange之后,才會繼續執行,
ThreadLocalRandom
通常我們都會用 Random 去生成亂數,但是 Random 有點小問題,在多執行緒并發的情況下為了保證生成的隨機性,通過 CAS 的方式保證生成新種子的原子性,但是這樣帶來了性能的問題,多執行緒并發去生成亂數,但是只有一個執行緒能成功,其他的執行緒會一直自旋,性能不高,所以 ThreadLocalRandom 就是為了解決這個問題而誕生,
//多執行緒下通過CAS保證新種子生成的原子性
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
ThreadLocalRandom 我們從名字就能看出來,肯定使用了 ThreadLocal,作用就是用 ThreadLocal 保存每個種子的變數,防止在高并發下對同一個種子的爭奪,
使用也非常簡單:
ThreadLocalRandom.current().nextInt(100);
看下原始碼實作,current 方法獲取當前的 ThreadLocalRandom 實體,
public static ThreadLocalRandom current() {
if (UNSAFE.getInt(Thread.currentThread(), PROBE) == 0)
localInit();
return instance;
}
nextInt 方法和 Random 看起來差不多,上面是生成新的種子,下面是固定的基于新種子計算亂數,主要看 nextSeed,
public int nextInt(int bound) {
if (bound <= 0)
throw new IllegalArgumentException(BadBound);
int r = mix32(nextSeed()); //生成新種子
int m = bound - 1;
if ((bound & m) == 0) // power of two
r &= m;
else { // reject over-represented candidates
for (int u = r >>> 1;
u + m - (r = u % bound) < 0;
u = mix32(nextSeed()) >>> 1)
;
}
return r;
}
r = UNSAFE.getLong(t, SEED) + GAMMA 計算出新的種子,然后使用 UNSAFE 的方法放入當前執行緒中,
final long nextSeed() {
Thread t; long r; // read and update per-thread seed
UNSAFE.putLong(t = Thread.currentThread(), SEED,
r = UNSAFE.getLong(t, SEED) + GAMMA);
return r;
}
ConcurrentHashMap
這個我們就不說了,說的太多了,之前的文章也寫過了,可以參考之前寫過的,
CopyOnWriteArrayList&CopyOnWriteArraySet
這是執行緒安全的 ArrayList ,從名字我們就能看出來,寫的時候復制,這叫做寫時復制,也就是寫的操作是對拷貝的陣列的操作,
先看建構式,有3個,分別是無參,傳參為集合和傳引陣列,其實都差不多,無參建構式創建一個新的陣列,集合則是把集合類的元素拷貝到新的陣列,陣列也是一樣,
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements;
if (c.getClass() == CopyOnWriteArrayList.class)
elements = ((CopyOnWriteArrayList<?>)c).getArray();
else {
elements = c.toArray();
if (c.getClass() != ArrayList.class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
}
setArray(elements);
}
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
我們看 add 方法,你一眼就能看出來非常簡單的實作,通過 ReentrantLock 加鎖,然后拷貝出一個新的陣列,陣列長度+1,再把新陣列賦值,所以這就是名字的由來,寫入的時候操作的是陣列的拷貝,其他的洗掉修改就不看了,基本上是一樣的,
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
再看看 get 方法,也非常簡單,直接獲取陣列當前索引的值,這里需要注意的是,讀資料是沒有加鎖的,所以會有一致性的問題,它并不能保證讀到的一定是最新的資料,
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
final Object[] getArray() {
return array;
}
至于 CopyOnWriteArraySet ,他就是基于 CopyOnWriteArrayList 實作的,這里我們不再贅述,
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
public boolean add(E e) {
return al.addIfAbsent(e);
}
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
Fork/Join
Fork/Join 是一個并行執行任務的框架,利用的分而治之的思想,
Fork 是把一個大的任務拆分成若干個小任務并行執行,Join 則是合并拆分的子任務的結果集,最終計算出大任務的結果,
所以整個 Fork/Join 的流程可以認為就是兩步:
- Fork 拆分任務,直到拆分到最小粒度不可拆分為止
- Join 計算結果,把每個子任務的結果進行合并
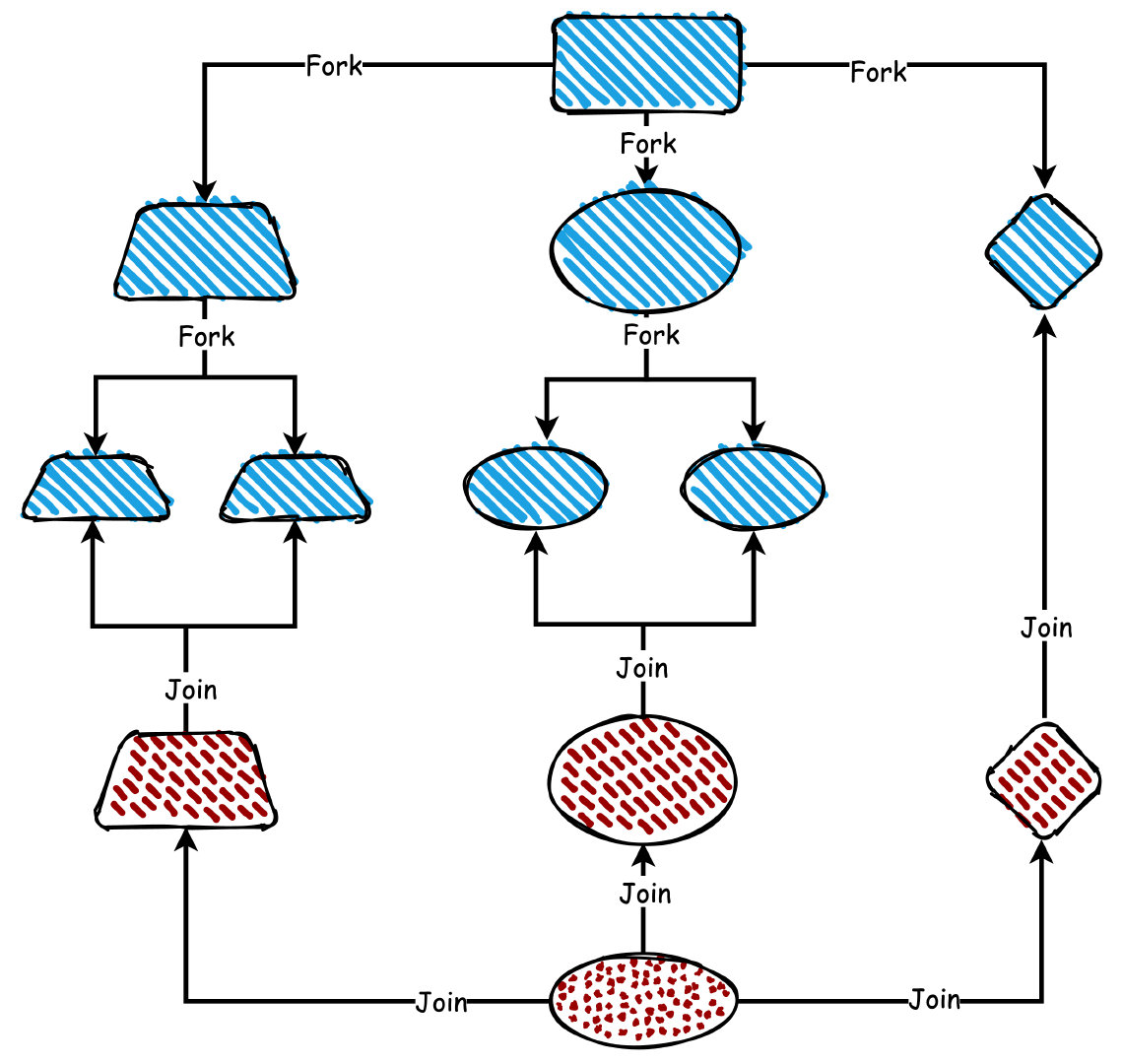
這里我們需要介紹一下主要的幾個類:
ForkJoinTask:就是我們的分治任務的抽象類
RecursiveTask:繼承于 ForkJoinTask,用于計算有回傳結果的任務
RecursiveAction: 繼承于 ForkJoinTask,用于計算沒有回傳結果的任務
ForkJoinPool:用于執行 ForkJoinTask 任務的執行緒池,通常我們可以用 ForkJoinPool.commonPool() 去創建一個 Fork/Join 的執行緒池,然后用 submit 或者 invoke 去提交執行任務,
這里我們寫一個測驗程式,用于計算[0,999]的求和結果,所以我們寫一個類繼承 RecursiveTask ,并且實作他的 compute 方法,
invokeAll() 相當于每個任務都執行 fork,fork 之后會再次執行 compute 判斷是否要繼續拆分,如果無需拆分那么則使用 join 方法計算匯總結果,
public class ForkJoinTest {
public static void main(String[] args) throws Exception {
List<Integer> list = new LinkedList<>();
Integer sum = 0;
for (int i = 0; i < 1000; i++) {
list.add(i);
sum += i;
}
CalculateTask task = new CalculateTask(0, list.size(), list);
Future<Integer> future = ForkJoinPool.commonPool().submit(task);
System.out.println("sum=" + sum + ",Fork/Join result=" + future.get());
}
@Data
static class CalculateTask extends RecursiveTask<Integer> {
private Integer start;
private Integer end;
private List<Integer> list;
public CalculateTask(Integer start, Integer end, List<Integer> list) {
this.start = start;
this.end = end;
this.list = list;
}
@Override
protected Integer compute() {
Integer sum = 0;
if (end - start < 200) {
for (int i = start; i < end; i++) {
sum += list.get(i);
}
} else {
int middle = (start + end) / 2;
System.out.println(String.format("從[%d,%d]拆分為:[%d,%d],[%d,%d]", start, end, start, middle, middle, end));
CalculateTask task1 = new CalculateTask(start, middle, list);
CalculateTask task2 = new CalculateTask(middle, end, list);
invokeAll(task1, task2);
sum = task1.join() + task2.join();
}
return sum;
}
}
}
//輸出
從[0,1000]拆分為:[0,500],[500,1000]
從[0,500]拆分為:[0,250],[250,500]
從[500,1000]拆分為:[500,750],[750,1000]
從[0,250]拆分為:[0,125],[125,250]
從[250,500]拆分為:[250,375],[375,500]
從[500,750]拆分為:[500,625],[625,750]
從[750,1000]拆分為:[750,875],[875,1000]
sum=499500,Fork/Join result=499500
使用完成之后,我們再來談一下 Fork/Join 的原理,
先看 fork 的代碼,呼叫 fork 之后,使用workQueue.push() 把任務添加到佇列中,注意 push 之后呼叫 signalWork 喚醒一個執行緒去執行任務,
public final ForkJoinTask<V> fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
final ForkJoinPool.WorkQueue workQueue; // 作業竊取
final void push(ForkJoinTask<?> task) {
ForkJoinTask<?>[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
}
else if (n >= m)
growArray();
}
}
上面我們看到了 workQueue,這個其實就是我們說的作業佇列,它是一個雙端佇列,并且有一個作業執行緒和他對應,
@sun.misc.Contended
static final class WorkQueue {
volatile int base; // 下一個出佇列索引
int top; // 下一個入佇列索引
ForkJoinTask<?>[] array; // 佇列中的 task
final ForkJoinPool pool;
final ForkJoinWorkerThread owner; // 作業佇列中的作業執行緒
volatile Thread parker; // == owner during call to park; else null
volatile ForkJoinTask<?> currentJoin; // 當前join的任務
volatile ForkJoinTask<?> currentSteal; // 當前偷到的任務
}
那如果作業執行緒自己佇列的做完了怎么辦?只能傻傻地等待嗎?并不是,這時候有一個叫做作業竊取的機制,所以他就會去其他執行緒的佇列里偷一個任務來執行,
為了避免偷任務執行緒和自己的執行緒產生競爭,所以自己的作業執行緒是從佇列頭部獲取任務執行,而偷任務執行緒則從佇列尾部偷任務,
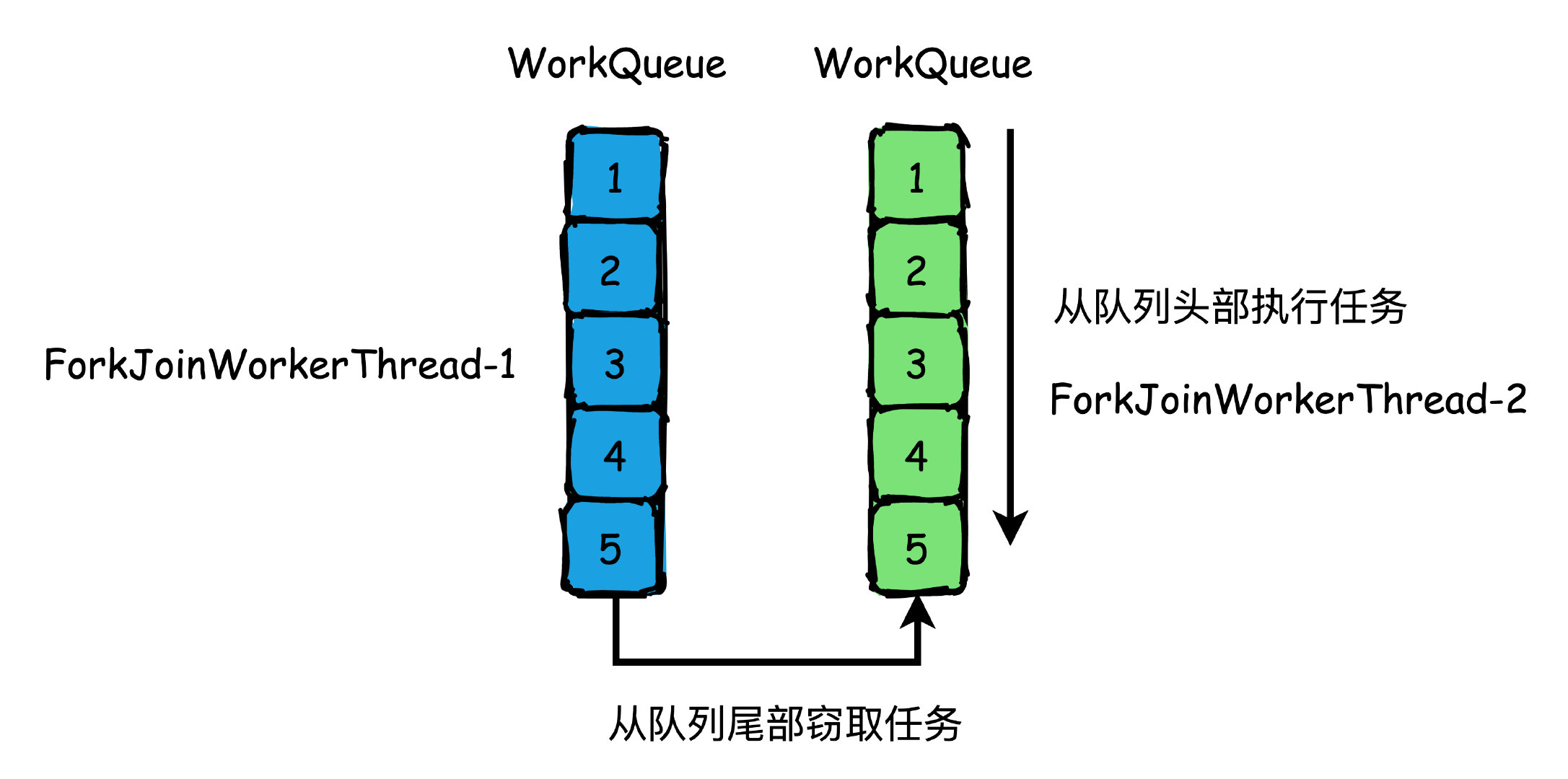
Executor
Executor是并發編程中重要的一環,任務創建后提交到Executor執行并最侄訓傳結果,
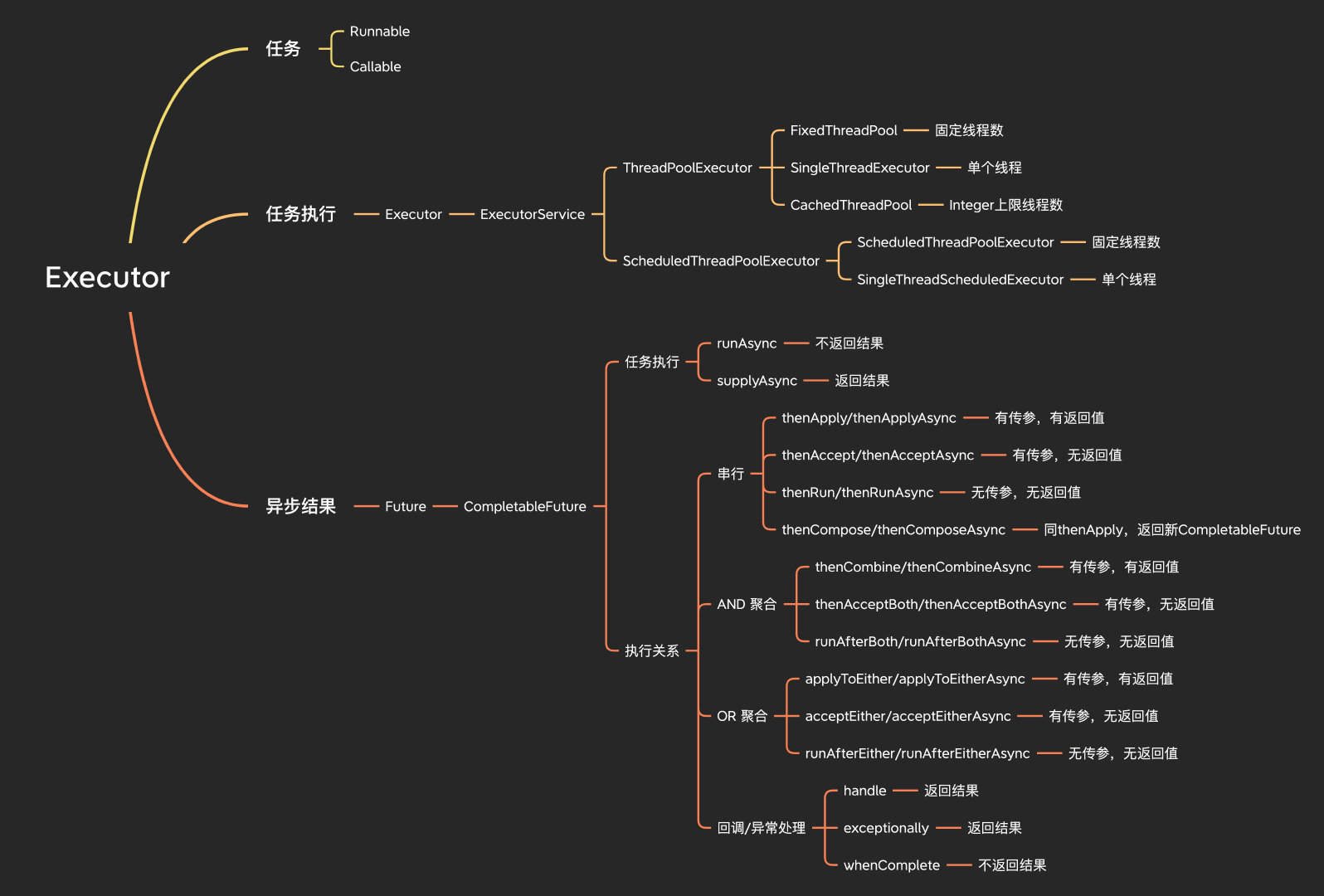
任務
執行緒兩種創建方式:Runnable和Callable,
Runnable是最初創建執行緒的方式,在JDK1.1的版本就已經存在,Callable則在JDK1.5版本之后加入,他們的主要區別在于Callable可以回傳任務的執行結果,
任務執行
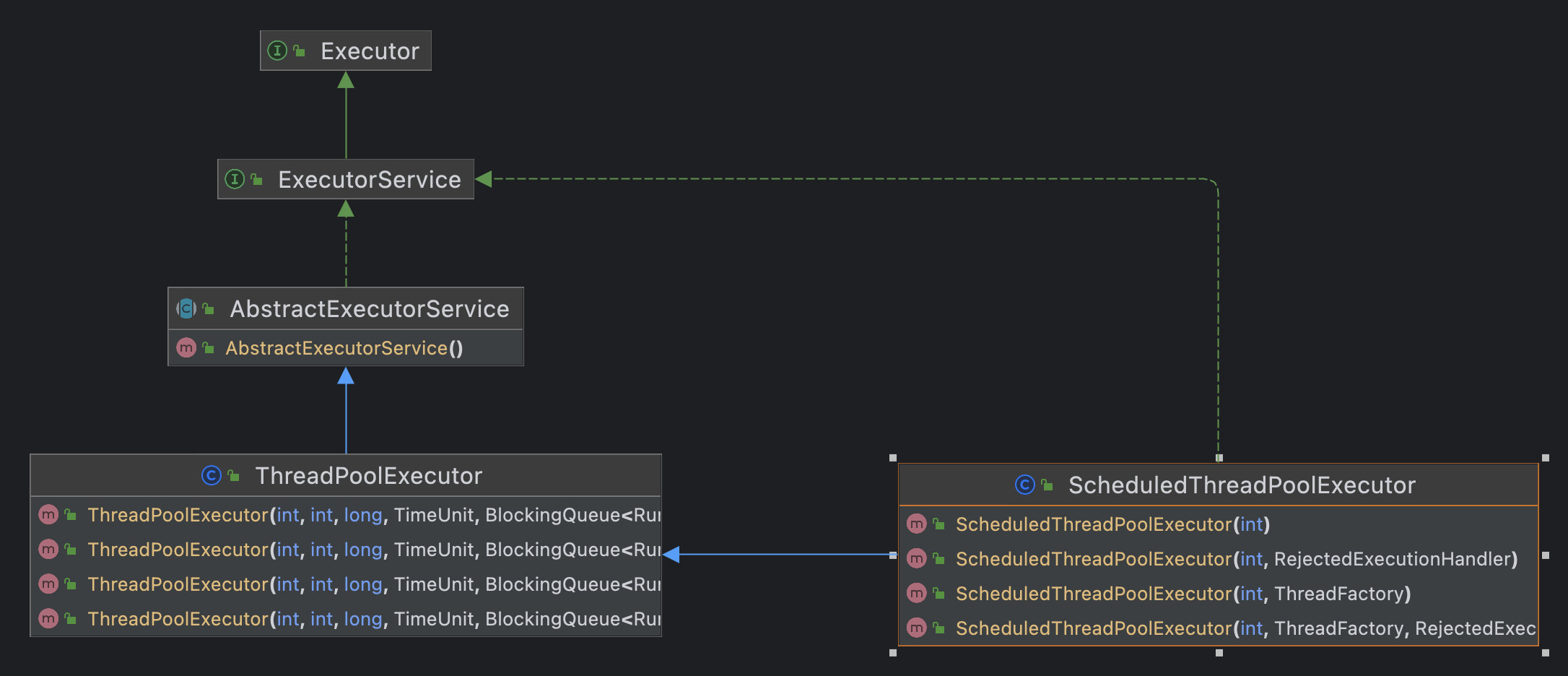
任務的執行主要靠Executor,ExecutorService繼承自Executor,ThreadPoolExecutor和ScheduledThreadPoolExecutor分別實作了ExecutorService,
那說到執行緒池之前,我們肯定要提及到執行緒池的幾個核心引數和原理,這個之前的文章也寫到過,屬于基礎中的基礎部分,
首先執行緒池有幾個核心的引數概念:
-
最大執行緒數maximumPoolSize
-
核心執行緒數corePoolSize
-
活躍時間keepAliveTime
-
阻塞佇列workQueue
-
拒絕策略RejectedExecutionHandler
當提交一個新任務到執行緒池時,具體的執行流程如下:
- 當我們提交任務,執行緒池會根據corePoolSize大小創建若干任務數量執行緒執行任務
- 當任務的數量超過corePoolSize數量,后續的任務將會進入阻塞佇列阻塞排隊
- 當阻塞佇列也滿了之后,那么將會繼續創建(maximumPoolSize-corePoolSize)個數量的執行緒來執行任務,如果任務處理完成,maximumPoolSize-corePoolSize額外創建的執行緒等待keepAliveTime之后被自動銷毀
- 如果達到maximumPoolSize,阻塞佇列還是滿的狀態,那么將根據不同的拒絕策略對應處理
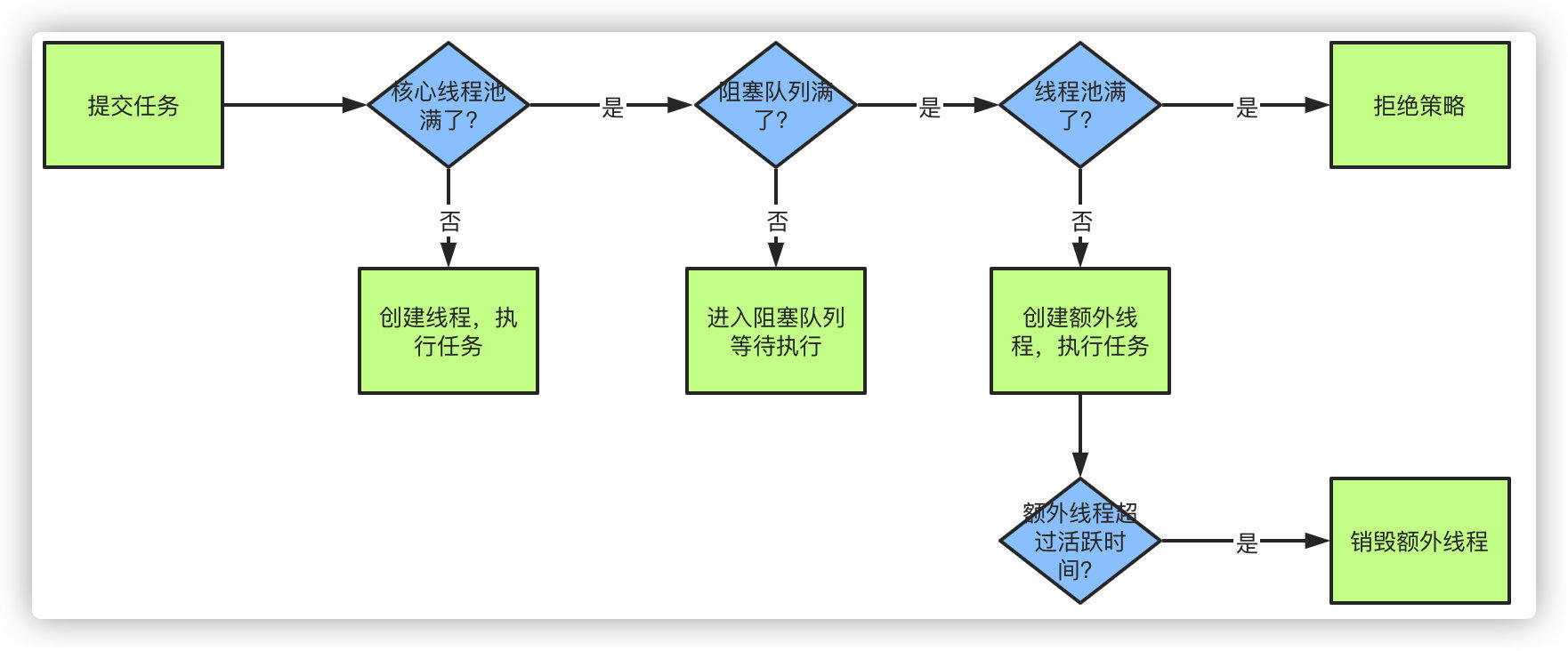
拒絕策略主要有四種:
- AbortPolicy:直接丟棄任務,拋出例外,這是默認策略
- CallerRunsPolicy:使用呼叫者所在的執行緒來處理任務
- DiscardOldestPolicy:丟棄等待佇列中最老的任務,并執行當前任務
- DiscardPolicy:直接丟棄任務,也不拋出例外
ThreadPoolExecutor
通常為了快捷我們會用Executors工具類提供的創建執行緒池的方法快速地創建一個執行緒池出來,主要有幾個方法,但是一般我們不推薦這樣使用,非常容易導致出現問題,生產環境中我們一般推薦自己實作,引數自己定義,而不要使用這些方法,
創建
//創建固定執行緒數大小的執行緒池,核心執行緒數=最大執行緒數,阻塞佇列長度=Integer.MAX_VALUE
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//創建只有一個執行緒的執行緒池,阻塞佇列長度=Integer.MAX_VALUE
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
//創建核心執行緒數為0,最大執行緒數=Integer.MAX_VALUE的執行緒池,阻塞佇列為同步佇列
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
最好的辦法就是自己創建,并且指定執行緒名稱:
new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
Runtime.getRuntime().availableProcessors()*2,
1000L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(100),
new ThreadFactoryBuilder().setNameFormat("thread-name").build());
提交任務
重點說一下幾個方法:
submit(Runnable task, T result):可以用于主執行緒和子執行緒之間的通信,資料共享,
submit(Runnable task):回傳null,相當于呼叫submit(Runnable task, null),
invokeAll(Collection<? extends Callable
invokeAny(Collection<? extends Callable
public void execute(Runnable command); //提交runnable任務,無回傳
public <T> Future<T> submit(Callable<T> task); //提交callable任務,有回傳
public Future<?> submit(Runnable task); //提交runnable,有回傳
public <T> Future<T> submit(Runnable task, T result); //提交runnable,有回傳
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks); //批量提交任務
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit);
public <T> T invokeAny(Collection<? extends Callable<T>> tasks);
public <T> T invokeAny(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit);
關閉
shutdown:執行緒池狀態設定為SHUTDOWN,不再接受新任務,直接回傳,執行緒池中任務會執行完成,遍歷執行緒池中的執行緒,逐個呼叫interrupt方法去中斷執行緒,
shutdownNow:執行緒池狀態設定為STOP,不再接受新任務,直接回傳,執行緒池中任務會被中斷,回傳值為被丟棄的任務串列,
isShutdown:只要呼叫了shutdown或者shutdownNow,都會回傳true
isTerminating:所有任務都關閉后,才回傳true
public void shutdown();
public List<Runnable> shutdownNow();
public boolean isShutdown();
public boolean isTerminating();
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor 繼承于 ThreadPoolExecutor,從名字我們也知道,他是用于定時執行任務的執行緒池,
內部實作了一個DelayedWorkQueue作為任務的阻塞佇列,ScheduledFutureTask 作為調度的任務,保存到佇列中,
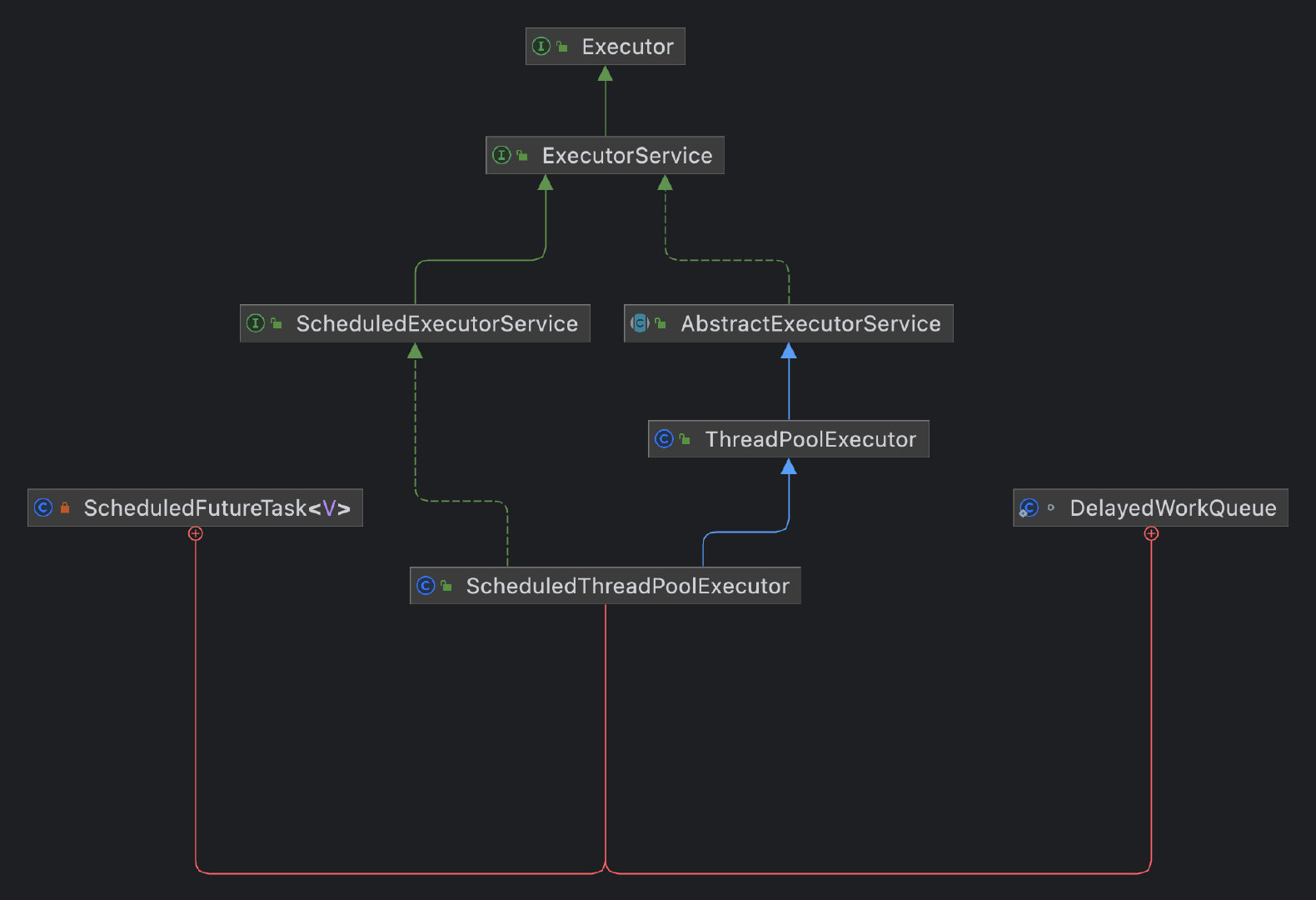
我們先看下他的建構式,4個建構式都不支持傳佇列進來,所以默認的就是使用他的內部類 DelayedWorkQueue,由于 DelayedWorkQueue 是一個無界佇列,所以這里最大執行緒數都是設定的為 Integer.MAX,因為沒有意義,
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), handler);
}
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
執行定時任務的方法主要有4個,前面兩個 schedule 傳參區分 Runnable 和 Callable 其實并沒有區別,最終 Runnable 會通過 Executors.callable(runnable, result) 轉換為 Callable,本質上我們可以當做只有3個執行方法來看,
public <V> ScheduledFuture<V> schedule(Callable<V> callable,
long delay,
TimeUnit unit);
public ScheduledFuture<?> schedule(Runnable command,
long delay,
TimeUnit unit);
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit);
schedule:提交一個延時任務,從時間單位為 unit 的 delay 時間開始執行,并且任務只會執行一次,
scheduleWithFixedDelay:以固定的延遲時間重復執行任務,initialDelay 表示提交任務后多長時間開始執行,delay 表示任務執行時間間隔,
scheduleAtFixedRate:以固定的時間頻率重復執行任務,指的是以起始時間開始,然后以固定的時間間隔重復執行任務,initialDelay 表示提交任務后多長時間開始執行,然后從 initialDelay + N * period執行,
這兩個特別容易搞混,很難理解到底是個啥意思,記住了,
scheduleAtFixedRate 是上次執行完成之后立刻執行,scheduleWithFixedDelay 則是上次執行完成+delay 后執行,
看個例子,兩個任務都會延遲1秒,然后以2秒的間隔開始重復執行,任務睡眠1秒的時間,
scheduleAtFixedRate 由于任務執行的耗時比時間間隔小,所以始終是以2秒的間隔在執行,
scheduleWithFixedDelay 因為任務耗時用了1秒,導致后面的時間間隔都成了3秒,
public class ScheduledThreadPoolTest {
public static void main(String[] args) throws Exception {
ScheduledExecutorService executorService = new ScheduledThreadPoolExecutor(10);
executorService.scheduleAtFixedRate(() -> {
try {
System.out.println("scheduleAtFixedRate=" + new SimpleDateFormat("HH:mm:ss").format(new Date()));
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, 1000, 2000, TimeUnit.MILLISECONDS);
executorService.scheduleWithFixedDelay(() -> {
try {
System.err.println("scheduleWithFixedDelay=" + new SimpleDateFormat("HH:mm:ss").format(new Date()));
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}, 1000, 2000, TimeUnit.MILLISECONDS);
// executorService.shutdown();
}
}
//輸出
scheduleAtFixedRate=01:17:05
scheduleWithFixedDelay=01:17:05
scheduleAtFixedRate=01:17:07
scheduleWithFixedDelay=01:17:08
scheduleAtFixedRate=01:17:09
scheduleAtFixedRate=01:17:11
scheduleWithFixedDelay=01:17:11
scheduleAtFixedRate=01:17:13
scheduleWithFixedDelay=01:17:14
scheduleAtFixedRate=01:17:15
scheduleAtFixedRate=01:17:17
scheduleWithFixedDelay=01:17:17
scheduleAtFixedRate=01:17:19
scheduleWithFixedDelay=01:17:20
scheduleAtFixedRate=01:17:21
我們把任務耗時調整到超過時間間隔,比如改成睡眠3秒,觀察輸出結果,
scheduleAtFixedRate 由于任務執行的耗時比時間間隔長,按照規定上次任務執行結束之后立刻執行,所以變成以3秒的時間間隔執行,
scheduleWithFixedDelay 因為任務耗時用了3秒,導致后面的時間間隔都成了5秒,
scheduleWithFixedDelay=01:46:21
scheduleAtFixedRate=01:46:21
scheduleAtFixedRate=01:46:24
scheduleWithFixedDelay=01:46:26
scheduleAtFixedRate=01:46:27
scheduleAtFixedRate=01:46:30
scheduleWithFixedDelay=01:46:31
scheduleAtFixedRate=01:46:33
scheduleWithFixedDelay=01:46:36
scheduleAtFixedRate=01:46:36
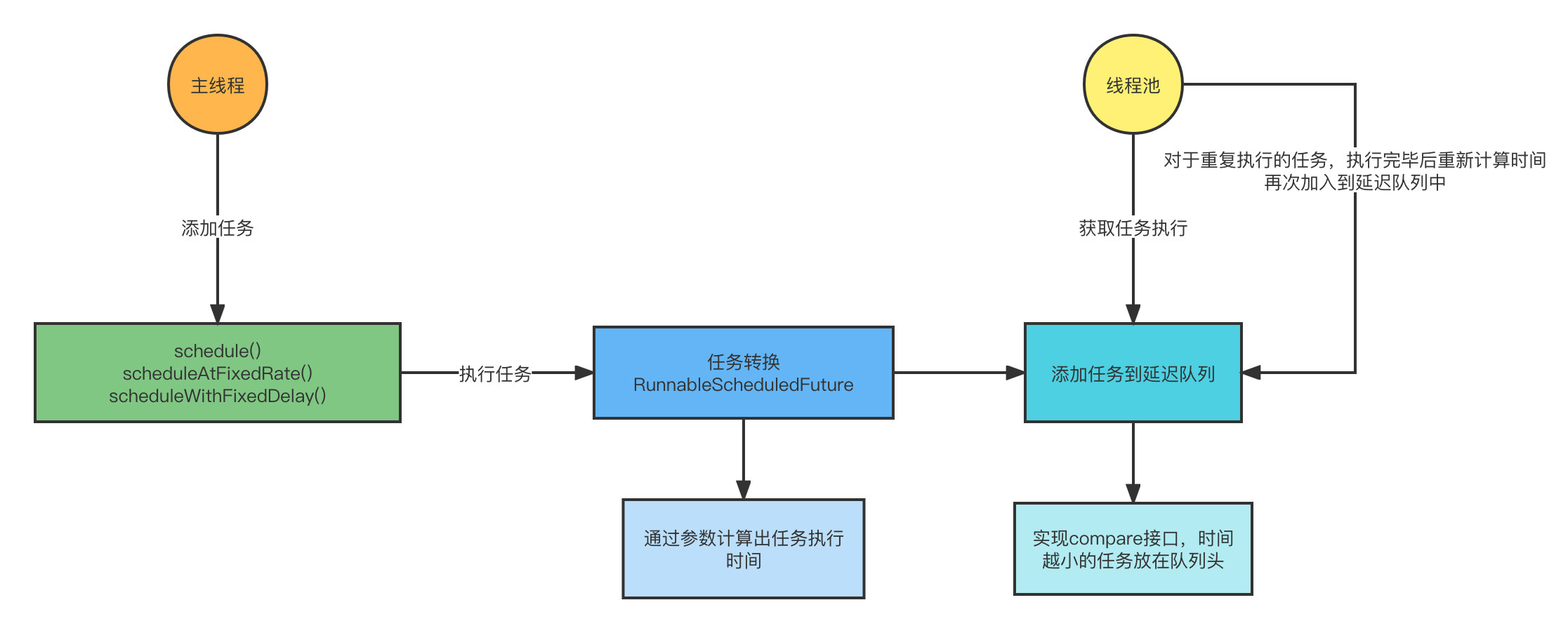
OK,最后來說說實作原理:
- 首先我們通過呼叫 schedule 的幾個方法,把任務添加到 ScheduledThreadPoolExecutor 去執行
- 接收到任務之后,會通過請求引數的延遲時間計算出真正需要執行任務的時間,然后把任務封裝成 RunnableScheduledFuture
- 然后把封裝之后的任務添加到延遲佇列中,任務 ScheduledFutureTask 實作了 comparable 介面,把時間越小的任務放在佇列頭,如果時間一樣,則會通過 sequenceNumber 去比較,也就是執行時間相同,先提交的先執行
- 最后執行緒池會從延遲佇列中去獲取任務執行,如果是一次性的任務,執行之后洗掉佇列中的任務,如果是重復執行的,則再次計算時間,然后把任務添加到延遲佇列中
CompletionService
記得上面我將 ThreadPoolExecutor 的方法嗎,其中有一個 invokeAny 的方法,批量提交任務,只要有一個完成了,就直接回傳,而不用一直傻傻地等,他的實作就是使用了 CompletionService ,我給你看一段原始碼,
private <T> T doInvokeAny(Collection<? extends Callable<T>> tasks,
boolean timed, long nanos)
throws InterruptedException, ExecutionException, TimeoutException {
if (tasks == null)
throw new NullPointerException();
int ntasks = tasks.size();
if (ntasks == 0)
throw new IllegalArgumentException();
ArrayList<Future<T>> futures = new ArrayList<Future<T>>(ntasks);
ExecutorCompletionService<T> ecs = new ExecutorCompletionService<T>(this);
}
看到了吧,OK,在我們想試試使用這個類之前,我們先試試 invokeAny 好使不,
public class CompletionServiceTest {
private static final int TOTAL = 10;
private static ExecutorService executorService = Executors.newFixedThreadPool(TOTAL);
public static void main(String[] args) throws Exception {
testInvokeAny();
}
private static void testInvokeAny() throws Exception {
List<TestTask> taskList = new LinkedList<>();
for (int i = 0; i < TOTAL; i++) {
taskList.add(new TestTask(i));
}
String value = https://www.cnblogs.com/ilovejaney/p/executorService.invokeAny(taskList, 60, TimeUnit.SECONDS);
System.out.println("get value = "https://www.cnblogs.com/ilovejaney/p/+ value);
executorService.shutdown();
}
static class TestTask implements Callable {
private Integer index;
public TestTask(Integer index) {
this.index = index;
}
@Override
public String call() throws Exception {
long sleepTime = ThreadLocalRandom.current().nextInt(1000, 10000);
System.out.println("task-" + index + " sleep " + sleepTime + " Ms");
Thread.sleep(sleepTime);
return "task-" + index;
}
}
}
//輸出
task-7 sleep 3072 Ms
task-4 sleep 1186 Ms
task-3 sleep 6182 Ms
task-9 sleep 7411 Ms
task-0 sleep 1882 Ms
task-1 sleep 8274 Ms
task-2 sleep 4789 Ms
task-5 sleep 8894 Ms
task-8 sleep 7211 Ms
task-6 sleep 5959 Ms
get value = https://www.cnblogs.com/ilovejaney/p/task-4
看到效果了吧,耗時最短的任務回傳,整個流程就結束了,那我們試試自己用 CompletionService 來實作這個效果看看,
public static void main(String[] args) throws Exception {
// testInvokeAny();
testCompletionService();
}
private static void testCompletionService() {
CompletionService<String> completionService = new ExecutorCompletionService(executorService);
List<Future> taskList = new LinkedList<>();
for (int i = 0; i < TOTAL; i++) {
taskList.add(completionService.submit(new TestTask(i)));
}
String value = https://www.cnblogs.com/ilovejaney/p/null;
try {
for (int i = 0; i < TOTAL; i++) {
value = completionService.take().get();
if (value != null) {
System.out.println("get value = "https://www.cnblogs.com/ilovejaney/p/+ value);
break;
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
taskList.forEach(task -> {
task.cancel(true);
});
}
executorService.shutdown();
}
//輸出
task-4 sleep 5006 Ms
task-1 sleep 4114 Ms
task-2 sleep 4865 Ms
task-5 sleep 1592 Ms
task-3 sleep 6190 Ms
task-7 sleep 2482 Ms
task-8 sleep 9405 Ms
task-9 sleep 8798 Ms
task-6 sleep 2040 Ms
task-0 sleep 2111 Ms
get value = task-5
效果是一樣的,我們只是實作了一個簡化版的 invokeAny 功能,使用起來也挺簡單的,
實作原理也挺簡單的,哪個任務先完成,就把他丟到阻塞佇列里,這樣取任務結果的時候直接從佇列里拿,肯定是拿到最新的那一個,
異步結果
通常,我們都會用 FutureTask 來獲取執行緒異步執行的結果,基于 AQS 實作,
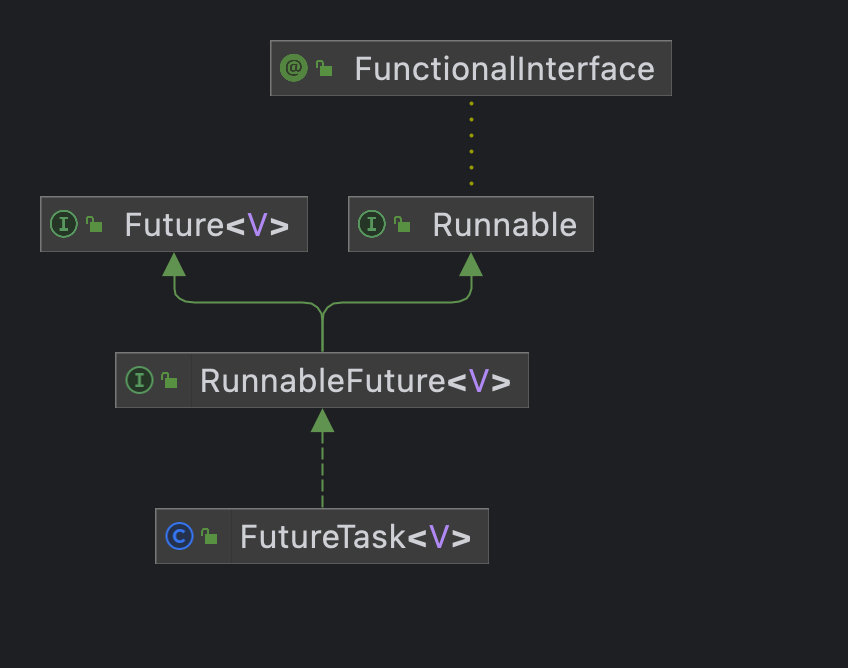
這個沒有說太多的必要,看看幾個方法就行了,
public V get();
public V get(long timeout, TimeUnit unit);
public boolean cancel(boolean mayInterruptIfRunning);
get 會阻塞的獲取執行緒異步執行的結果,一般不建議直接使用,最好是使用帶超時時間的 get 方法,
我們可以通過 cancel 方法去嘗試取消任務的執行,引數代表是否支持中斷,如果任務未執行,那么可以直接取消,如果任務執行中,使用 cancel(true) 會嘗試中斷任務,
CompletableFuture
之前我們都在使用 Future,要么只能用 get 方法阻塞,要么就用 isDone 來判斷,JDK1.8 之后新增了 CompletableFuture 用于異步編程,它針對 Future 的功能增加了回呼能力,可以幫助我們簡化異步編程,
CompletableFuture 主要包含四個靜態方法去創建物件,主要區別在于 supplyAsync 回傳計算結果,runAsync 不回傳,另外兩個方法則是可以指定執行緒池,如果不指定執行緒池則默認使用 ForkJoinPool,默認執行緒數為CPU核數,
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier);
public static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor);
public static CompletableFuture<Void> runAsync(Runnable runnable);
public static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor);
下面看看他的那些惡心人的幾十個方法,我估計能瘋,
串行
串行就不用解釋了,A->B->C 按照順序執行,下一個任務必須等上一個任務執行完成才可以,
主要包含 thenApply、thenAccept、thenRun 和 thenCompose,以及他們對應的帶 async 的異步方法,
為了方便記憶我們要記住,有 apply 的有傳參有回傳值,帶 accept 的有傳參但是沒有回傳值,帶 run 的啥也沒有,帶 compose 的會回傳一個新的 CompletableFuture 實體,
public static void main(String[] args) throws Exception {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread() + "作業完成");
return "supplyAsync";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
CompletableFuture newFuture = future.thenApply((ret) -> {
System.out.println(Thread.currentThread() + "thenApply=>" + ret);
return "thenApply";
}).thenAccept((ret) -> {
System.out.println(Thread.currentThread() + "thenAccept=>" + ret);
}).thenRun(() -> {
System.out.println(Thread.currentThread() + "thenRun");
});
CompletableFuture<String> composeFuture = future.thenCompose((ret) -> {
System.out.println(Thread.currentThread() + "thenCompose=>" + ret);
return CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread() + "thenCompose作業完成");
return "thenCompose";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
});
System.out.println(future.get());
System.out.println(newFuture.get());
System.out.println(composeFuture.get());
}
//輸出
Thread[ForkJoinPool.commonPool-worker-9,5,main]作業完成
Thread[ForkJoinPool.commonPool-worker-9,5,main]thenCompose=>supplyAsync
Thread[main,5,main]thenApply=>supplyAsync
Thread[main,5,main]thenAccept=>thenApply
Thread[main,5,main]thenRun
supplyAsync
null
Thread[ForkJoinPool.commonPool-worker-2,5,main]thenCompose作業完成
thenCompose
AND 聚合
這個意思是下一個任務執行必須等前兩個任務完成可以,
主要包含 thenCombine、thenAcceptBoth、runAfterBoth ,以及他們對應的帶 async 的異步方法,區別和上面一樣,
public static void main(String[] args) throws Exception {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
System.out.println(Thread.currentThread() + "A作業完成");
return "A";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
CompletableFuture<String> future2 = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2000);
System.out.println(Thread.currentThread() + "B作業完成");
return "B";
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
CompletableFuture newFuture = future.thenCombine(future2, (ret1, ret2) -> {
System.out.println(Thread.currentThread() + "thenCombine=>" + ret1 + "," + ret2);
return "thenCombine";
}).thenAcceptBoth(future2, (ret1, ret2) -> {
System.out.println(Thread.currentThread() + "thenAcceptBoth=>" + ret1 + "," + ret2);
}).runAfterBoth(future2, () -> {
System.out.println(Thread.currentThread() + "runAfterBoth");
});
System.out.println(future.get());
System.out.println(future2.get());
System.out.println(newFuture.get());
}
//輸出
Thread[ForkJoinPool.commonPool-worker-9,5,main]A作業完成
A
Thread[ForkJoinPool.commonPool-worker-2,5,main]B作業完成
B
Thread[ForkJoinPool.commonPool-worker-2,5,main]thenCombine=>A,B
Thread[ForkJoinPool.commonPool-worker-2,5,main]thenAcceptBoth=>thenCombine,B
Thread[ForkJoinPool.commonPool-worker-2,5,main]runAfterBoth
null
Or 聚合
Or 聚合代表只要多個任務中有一個完成了,就可以繼續下面的任務,
主要包含 applyToEither、acceptEither、runAfterEither ,以及他們對應的帶 async 的異步方法,區別和上面一樣,不再舉例了,
回呼/例外處理
whenComplete、handle 代表執行完成的回呼,一定會執行,exceptionally 則是任務執行發生例外的回呼,
public static void main(String[] args) throws Exception {
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
int a = 1 / 0;
return "success";
} catch (Exception e) {
throw new RuntimeException(e);
}
});
CompletableFuture newFuture = future.handle((ret, exception) -> {
System.out.println(Thread.currentThread() + "handle exception=>" + exception.getMessage());
return "handle";
});
future.whenComplete((ret, exception) -> {
System.out.println(Thread.currentThread() + "whenComplete exception=>" + exception.getMessage());
});
CompletableFuture exceptionFuture = future.exceptionally((e) -> {
System.out.println(Thread.currentThread() + "exceptionally exception=>" + e.getMessage());
return "exception";
});
System.out.println("task future = " + future.get());
System.out.println("handle future = " + newFuture.get());
System.out.println("exception future = " + exceptionFuture.get());
}
//輸出
Thread[ForkJoinPool.commonPool-worker-9,5,main]exceptionally exception=>java.lang.RuntimeException: java.lang.ArithmeticException: / by zero
Thread[main,5,main]whenComplete exception=>java.lang.RuntimeException: java.lang.ArithmeticException: / by zero
Thread[ForkJoinPool.commonPool-worker-9,5,main]handle exception=>java.lang.RuntimeException: java.lang.ArithmeticException: / by zero
Exception in thread "main" java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.ArithmeticException: / by zero
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at com.example.demo.CompletableFutureTest3.main(CompletableFutureTest3.java:31)
Caused by: java.lang.RuntimeException: java.lang.ArithmeticException: / by zero
at com.example.demo.CompletableFutureTest3.lambda$main$0(CompletableFutureTest3.java:13)
at java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1604)
at java.util.concurrent.CompletableFuture$AsyncSupply.exec(CompletableFuture.java:1596)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1067)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1703)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:172)
Caused by: java.lang.ArithmeticException: / by zero
at com.example.demo.CompletableFutureTest3.lambda$main$0(CompletableFutureTest3.java:10)
... 6 more
阻塞佇列
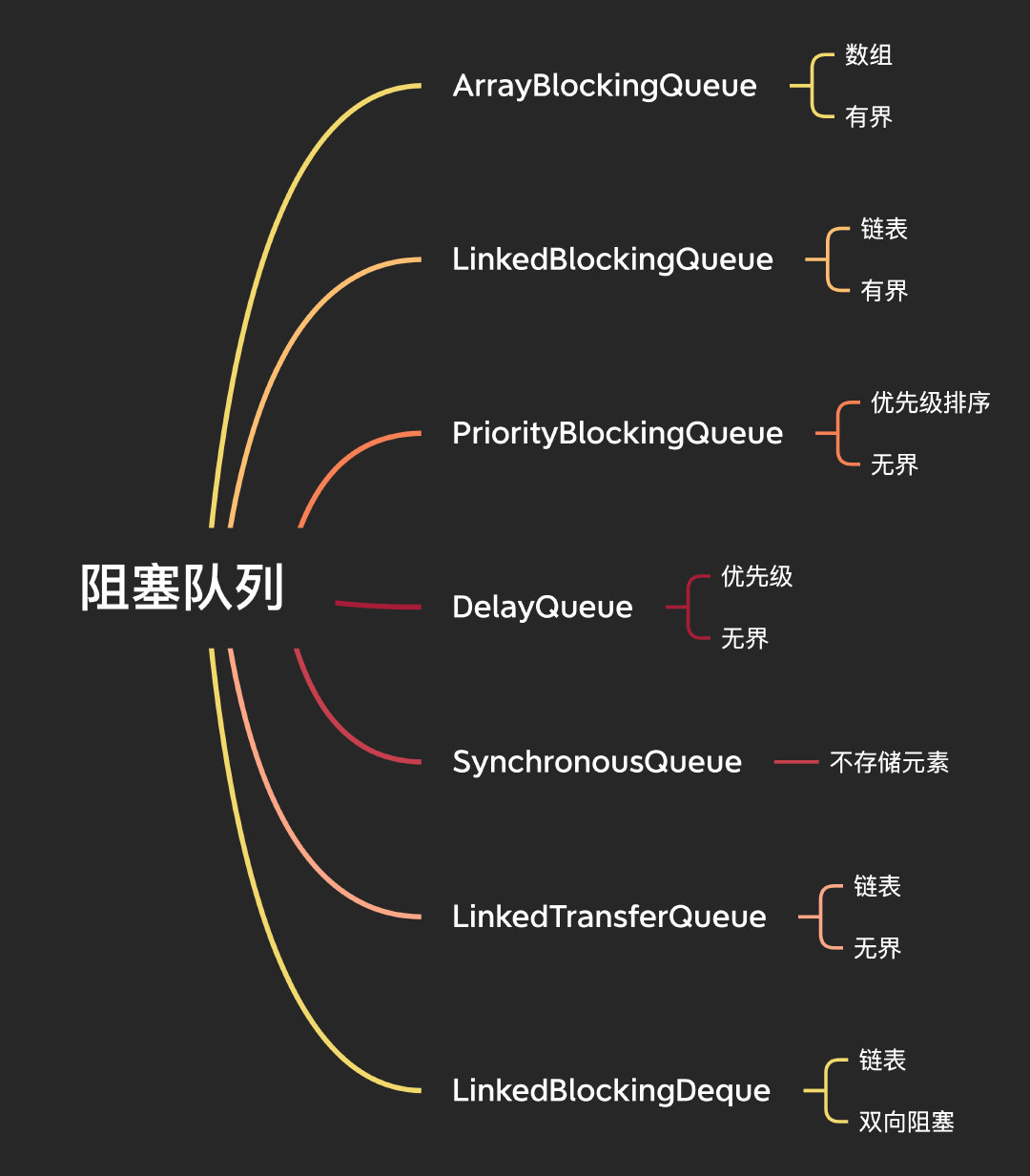
并發編程中,佇列是其中不可缺少的一環,其實前面在說到執行緒池的時候,就已經提及到了阻塞佇列了,這里我們要一起看看 JUC 包下提供的這些佇列,
阻塞佇列中的阻塞包含兩層意思:
- 插入的時候,如果阻塞佇列滿,插入元素阻塞
- 洗掉/查詢的時候,如果阻塞佇列空,洗掉/查詢元素阻塞
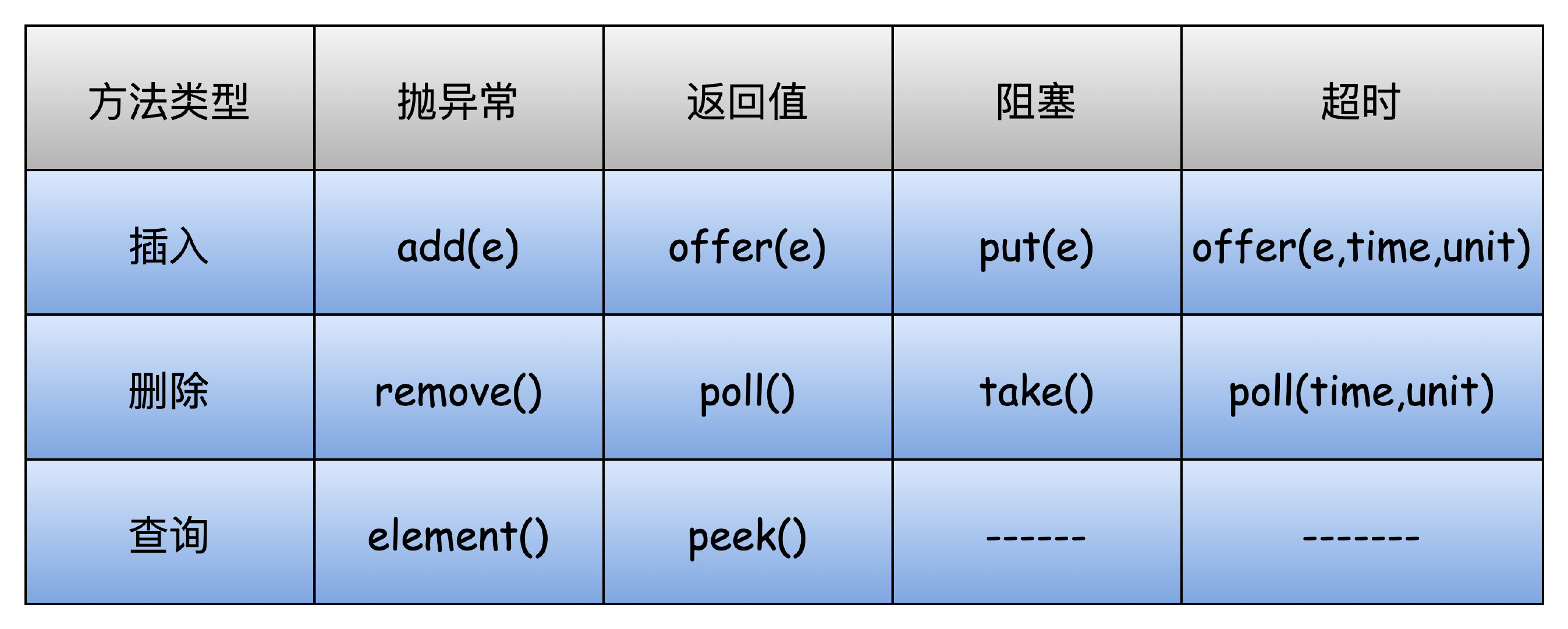
下面列出佇列的一些插入和洗掉元素的方法,一個個來說:
add:向佇列尾部插入元素,插入成功回傳 true,佇列滿則拋出IllegalStateException("Queue full")例外
offer:向佇列尾部插入元素,佇列滿回傳 false,否則回傳 true,帶超時的則是會阻塞,達到超時時間后回傳
put:向佇列尾部插入元素,佇列滿會一直阻塞
remove:洗掉佇列頭部元素,洗掉成功回傳 true,佇列空則拋出NoSuchElementException例外
poll:洗掉佇列頭部元素,洗掉成功回傳佇列頭部元素,佇列慷訓傳null,帶超時的則是會阻塞,達到超時時間后回傳
take:洗掉佇列頭部元素,佇列慷訓一直阻塞
element:查詢佇列頭部元素,并且回傳,佇列空則拋出NoSuchElementException例外
peek:查詢佇列頭部元素,并且回傳
ArrayBlockingQueue
ArrayBlockingQueue 從名字就知道,基于陣列實作的有界阻塞佇列,基于AQS支持公平和非公平策略,
還是看建構式吧,可以傳入初始陣列大小,一旦設定之后大小就不能改變了,傳參可以支持公平和非公平,最后一個建構式可以支持傳入集合進行初始化,但是長度不能超過 capacity,否則拋出ArrayIndexOutOfBoundsException例外,
public ArrayBlockingQueue(int capacity);
public ArrayBlockingQueue(int capacity, boolean fair);
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c);
這個其實在上面介紹 Condition 的時候我們就已經實作過他了,這里就不再說了,可以參考上面 Condition 的部分,
LinkedBlockingQueue
LinkedBlockingQueue 基于鏈表實作的有界阻塞佇列,
使用無參建構式則鏈表長度為 Integer.MAX_VALUE,另外兩個建構式和 ArrayBlockingQueue 差不多,
public LinkedBlockingQueue();
public LinkedBlockingQueue(int capacity);
public LinkedBlockingQueue(Collection<? extends E> c);
我們可以看看 put 和 take 的原始碼,
- 首先加鎖中斷
- 然后判斷如果達到了佇列的最大長度,那么就阻塞等待,否則就把元素插入到佇列的尾部
- 注意這里和 ArrayBlockingQueue 有個區別,這里再次做了一次判斷,如果佇列沒滿,喚醒因為 put 阻塞的執行緒,為什么要做判斷,因為他們不是一把鎖
- 最后的邏輯是一樣的,notEmpty 喚醒
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
notFull.await();
}
enqueue(node);
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
private void enqueue(Node<E> node) {
// assert putLock.isHeldByCurrentThread();
// assert last.next == null;
last = last.next = node;
}
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
take的邏輯也是非常類似啊,
- 加鎖中斷
- 判斷佇列是不是空了,空了的話就阻塞等待,否則就從佇列移除一個元素
- 然后再次做一次判斷,佇列要是不空,就喚醒阻塞的執行緒
- 最后喚醒 notFull 的執行緒
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await();
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal();
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull();
return x;
}
private E dequeue() {
// assert takeLock.isHeldByCurrentThread();
// assert head.item == null;
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
private void signalNotFull() {
final ReentrantLock putLock = this.putLock;
putLock.lock();
try {
notFull.signal();
} finally {
putLock.unlock();
}
}
PriorityBlockingQueue
PriorityBlockingQueue 是支持優先級的無界阻塞佇列,默認排序按照自然排序升序排列,
幾個建構式,無參建構式初始容量為11,可以自定義,也可以在創建的時候傳入 comparator 自定義排序規則,
public PriorityBlockingQueue();
public PriorityBlockingQueue(int initialCapacity);
public PriorityBlockingQueue(int initialCapacity, Comparator<? super E> comparator);
public PriorityBlockingQueue(Collection<? extends E> c);
直接看 put 和 take 方法吧,后面都這樣,其他的就忽略好了,找到 put 之后,發現直接就是呼叫的 offer,那我們就直接看 offer 的實作,
- 首先還是加鎖,然后看當前元素個數是否達到了陣列的上限,到了就呼叫 tryGrow 去擴容,
- 看是否實作了 Comparator 介面,是的話就用 Comparator 去排序,否則就用 Comparable 去比較,如果兩個都沒有,會報錯
- notEmpty 喚醒,最后解鎖
public void put(E e) {
offer(e); // never need to block
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
這里,我們要繼續關注一下這個擴容的邏輯,到底是怎么處理的?代碼不長,但是看著很方的樣子,
- 首先,先釋放鎖,因為下面用 CAS 處理,估計怕擴容時間太長阻塞的執行緒太多
- 然后 CAS 修改 allocationSpinLock 為1
- CAS 成功的話,進行擴容的邏輯,如果長度小于64就擴容一倍,否則擴容一半
- 之前我們說他無界,其實不太對,這里就判斷是否超過了最大長度,MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8,判斷一下有可能會拋出記憶體溢位例外
- 然后創建一個新的物件陣列,并且 allocationSpinLock 重新恢復為0
- 執行了一次 Thread.yield(),讓出 CPU,因為有可能其他執行緒正在擴容,讓大家爭搶一下
- 最后確保新的物件陣列創建成功了,也就是擴容是沒有問題的,再次加鎖,陣列拷貝,結束
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
if (newArray == null) // back off if another thread is allocating
Thread.yield();
lock.lock();
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
take 的邏輯基本一樣,最多有個排序的邏輯在里面,就不再多說了,
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
DelayQueue
DelayQueue 是支持延時的無界阻塞佇列,這個在我們聊 ScheduledThreadPoolExecutor 也談到過,里面也使用了延遲佇列,只不過是它自己的一個內部類,DelayQueue 內部其實使用 PriorityQueue 來實作,
DelayQueue 的用法是添加元素的時候可以設定一個延遲時間,當時間到了之后才能從佇列中取出來,使用 DelayQueue 中的物件必須實作 Delayed 介面,重寫 getDelay 和 compareTo 方法,就像這樣,那實作其實可以看 ScheduledThreadPoolExecutor 里面是怎么做的,這里我就不管那么多,示意一下就好了,
public class Test {
public static void main(String[] args) throws Exception {
DelayQueue<User> delayQueue = new DelayQueue<>();
delayQueue.put(new User(1, "a"));
}
@Data
@NoArgsConstructor
@AllArgsConstructor
static class User implements Delayed {
private Integer id;
private String username;
@Override
public long getDelay(TimeUnit unit) {
return 0;
}
@Override
public int compareTo(Delayed o) {
return 0;
}
}
}
我們可以看看他的屬性和建構式,吶看到了吧,使用的 PriorityQueue,另外建構式比較簡單了,不說了,
private final transient ReentrantLock lock = new ReentrantLock();
private final PriorityQueue<E> q = new PriorityQueue<E>();
private Thread leader = null;
private final Condition available = lock.newCondition();
public DelayQueue();
public DelayQueue(Collection<? extends E> c);
OK,沒啥毛病,這里我們要先看 take 方法,不能先看 put,否則我覺得鬧不明白,
- 來第一步加鎖,如果頭結點是空的,也就是佇列是空的話,阻塞,沒啥好說的
- 反之佇列有東西,我們就要去取了嘛,但是這里要看物件自己實作的 getDelay 方法獲得延遲的時間,如果延遲的時間小于0,那說明到時間了,可以執行了,poll 回傳
- 第一次,leader 執行緒肯定是空的,執行緒阻塞 delay 的時間之后才開始執行,完全沒毛病,然后 leader 重新 置為 null
- 當 leader 不是 null 的時候,說明其他執行緒在操作了,所以阻塞等待喚醒
- 最后,leader 為 null,喚醒阻塞中的執行緒,解鎖
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
return q.poll();
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
然后再來看 put 就會簡單多了,put 還是直接呼叫的 offer,看 offer 方法,
這里使用的是 PriorityQueue 的 offer 方法,其實和我們上面說到的 PriorityBlockingQueue 差不多,不再多說了,添加到佇列頭部之后,leader 置為 null,喚醒,結束了,
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {
leader = null;
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
SynchronousQueue&LinkedTransferQueue
為什么這兩個放一起說呢,,,因為這原始碼真的不想在這里說一遍,這倆原始碼可以單獨出一個專題來寫,長篇精悍文章不適合他他們,就簡單先了解下,
SynchronousQueue 是一個不存盤元素的阻塞佇列,每個 put 必須等待 take,否則不能繼續添加元素,
如果你還記得我們上面說到執行緒池的地方,newCachedThreadPool 默認就是使用的 SynchronousQueue,
他就兩個構造方法,你一看就知道,對吧,支持公平和非公平,當然你也別問默認是啥,問就是非公平,
public SynchronousQueue();
public SynchronousQueue(boolean fair);
主要靠內部抽象類 Transferer,他的實作主要有兩個,TransferQueue 和 TransferStack,
注意:如果是公平模式,使用的是 TransferQueue 佇列,非公平則使用 TransferStack 堆疊,
abstract static class Transferer<E> {
abstract E transfer(E e, boolean timed, long nanos);
}
LinkedTransferQueue 是鏈表組成的無界阻塞佇列,看他內部類就知道了,這是個鏈表實作,
static final class Node {
final boolean isData; // 標記生產者或者消費者
volatile Object item; // 值
volatile Node next; // 下一個節點
volatile Thread waiter;
}
LinkedBlockingDeque
LinkedBlockingDeque 是鏈表組成的雙向阻塞佇列,它支持從佇列的頭尾進行進行插入和洗掉元素,
建構式有3個,不傳初始容量就是 Integer 最大值,
public LinkedBlockingDeque() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingDeque(int capacity);
public LinkedBlockingDeque(Collection<? extends E> c);
看下雙向鏈表的結構:
static final class Node<E> {
E item;
Node<E> prev;
Node<E> next;
Node(E x) {
item = x;
}
}
因為是雙向鏈表,所以比其他的佇列多了一些方法,比如 add、addFirst、addLast,add 其實就是 addLast,offer、put 也是類似,
我們可以區分看一下 putFirst 和 putLast ,主要區別就是 linkFirst 和 linkLast,分別去佇列頭部和尾部添加新節點,其他基本一致,
public void putFirst(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
while (!linkFirst(node))
notFull.await();
} finally {
lock.unlock();
}
}
public void putLast(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
final ReentrantLock lock = this.lock;
lock.lock();
try {
while (!linkLast(node))
notFull.await();
} finally {
lock.unlock();
}
}
結尾
本次長篇內容參考書籍和檔案
- Java 并發編程的藝術
- Java 并發編程之美
- Java 并發編程實戰
- Java 8實戰
- 極客時間:Java 并發編程實戰
OK,本期內容到此結束,我是艾小仙,我們過兩個月再見,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/484543.html
標籤:Java
下一篇:識別符號中的有效字符是什么?