在使用SQL提數的時候,常會遇到表內有重復值的時候,比如我們想得到 uv (獨立訪客),就需要做去重,
在 MySQL 中通常是使用 distinct 或 group by子句,但在支持視窗函式的 sql(如Hive SQL、Oracle等等) 中還可以使用 row_number 視窗函式進行去重,
舉個栗子,現有這樣一張表 task:
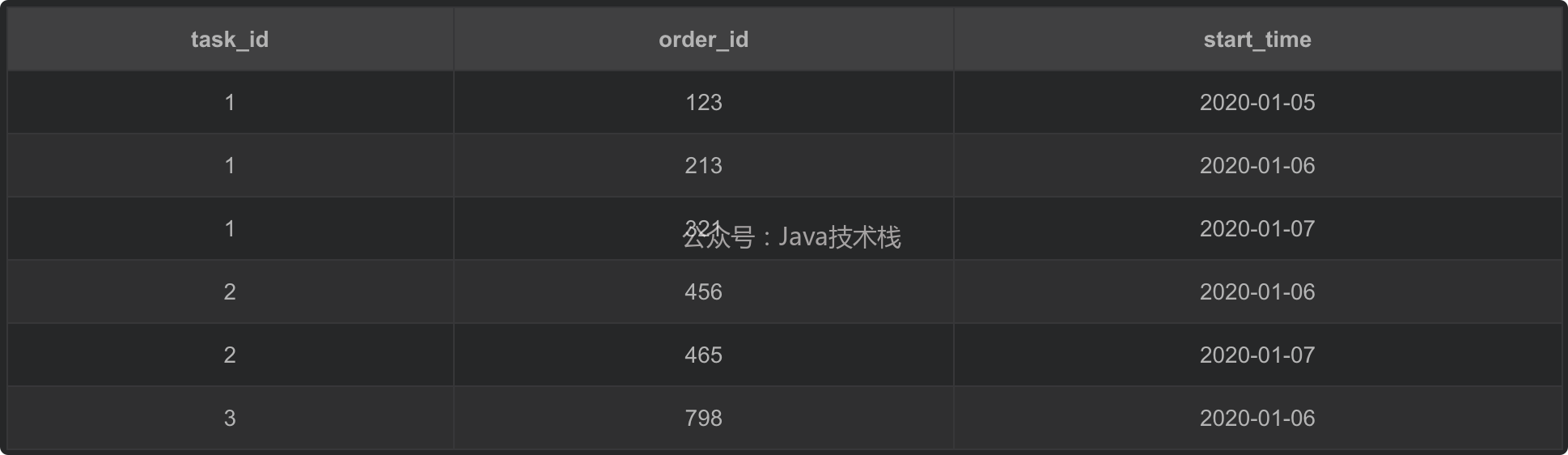
備注:
task_id: 任務id;order_id: 訂單id;start_time: 開始時間
注意:一個任務對應多條訂單
我們需要求出任務的總數量,因為 task_id 并非唯一的,所以需要去重:
distinct
-- 列出 task_id 的所有唯一值(去重后的記錄)
-- select distinct task_id
-- from Task;
-- 任務總數
select count(distinct task_id) task_num
from Task;
distinct 通常效率較低,它不適合用來展示去重后具體的值,一般與 count 配合用來計算條數,
distinct 使用中,放在 select 后邊,對后面所有的欄位的值統一進行去重,比如distinct后面有兩個欄位,那么 1,1 和 1,2 這兩條記錄不是重復值 ,
group by
-- 列出 task_id 的所有唯一值(去重后的記錄,null也是值)
-- select task_id
-- from Task
-- group by task_id;
-- 任務總數
select count(task_id) task_num
from (select task_id
from Task
group by task_id) tmp;
row_number
row_number 是視窗函式,語法如下:
row_number() over (partition by <用于分組的欄位名> order by <用于組內排序的欄位名>)
其中 partition by 部分可省略,
-- 在支持視窗函式的 sql 中使用
select count(case when rn=1 then task_id else null end) task_num
from (select task_id
, row_number() over (partition by task_id order by start_time) rn
from Task) tmp;
此外,再借助一個表 test 來理理 distinct 和 group by 在去重中的使用:

-- 下方的分號;用來分隔行
select distinct user_id
from Test; -- 回傳 1; 2
select distinct user_id, user_type
from Test; -- 回傳1, 1; 1, 2; 2, 1
select user_id
from Test
group by user_id; -- 回傳1; 2
select user_id, user_type
from Test
group by user_id, user_type; -- 回傳1, 1; 1, 2; 2, 1
select user_id, user_type
from Test
group by user_id;
-- Hive、Oracle等會報錯,mysql可以這樣寫,
-- 回傳1, 1 或 1, 2 ; 2, 1(共兩行),只會對group by后面的欄位去重,就是說最后回傳的記錄數等于上一段sql的記錄數,即2條
-- 沒有放在group by 后面但是在select中放了的欄位,只會回傳一條記錄(好像通常是第一條,應該是沒有規律的)
原文鏈接:https://blog.csdn.net/xienan_ds_zj/article/details/103869048
著作權宣告:本文為CSDN博主「米竹」的原創文章,遵循CC 4.0 BY-SA著作權協議,轉載請附上原文出處鏈接及本宣告,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/486447.html
標籤:Java
上一篇:延時佇列我在專案里是怎么實作的?