我正在嘗試分離從 PDF 表復制的資訊 - id 通常使用文本到列,但唯一的分層是空格,然后將資料拆分為多個不可用的列
資料是這樣的:
| 原始資料 |
|---|
| A1 公司 0 |
| 公司2 40000 |
| 命名一個 1 |
| 名字 b 15 |
| 名稱 c 184 |
| 17 大公司 1887 |
我需要輸出為:
| 公司 | 單位 |
|---|---|
| A1公司 | 0 |
| 公司2 | 40000 |
| 命名一個 | 1 |
| 名字 b | 15 |
| 名字 c | 184 |
| 17 大公司 | 1887年 |
因此,公司名稱(可能包含數字)與單位編號(可能是 1-5 位長)分開。
我一直無法找出使用 =len() 的方法,因為字串長度不是常數,最后一個數字不是一致的位數。
我目前正在使用:
=SUMPRODUCT(MID(0&A2, LARGE(INDEX(ISNUMBER(--MID(A2, ROW(INDIRECT("1:"&LEN(A2))), 1)) * ROW(INDIRECT("1:"&LEN(A2))), 0), ROW(INDIRECT("1:"&LEN(A2)))) 1, 1) * 10^ROW(INDIRECT("1:"&LEN(A2)))/10)
這給了我單元格中的所有數字 - 這適用于 90% 的資料,因為大多數公司的名稱中沒有數字。但是對于像“A1 Company 0”這樣的東西,它會給出 10 作為輸出,而不僅僅是 0。然后我去手動編輯少數也會發生這種情況的公司。
然后,我根據需要混合使用=LEN() =LEFT和=RIGHT來拆分資訊,以進行進一步的自動化分析。
我更喜歡公式而不是 VBA/宏
我無法提供實際資料,但我希望我在上表中提供了足夠的示例來顯示主要問題(不同的公司名稱長度、名稱中帶有數字的公司、代表單位的不同數字數量)
uj5u.com熱心網友回復:
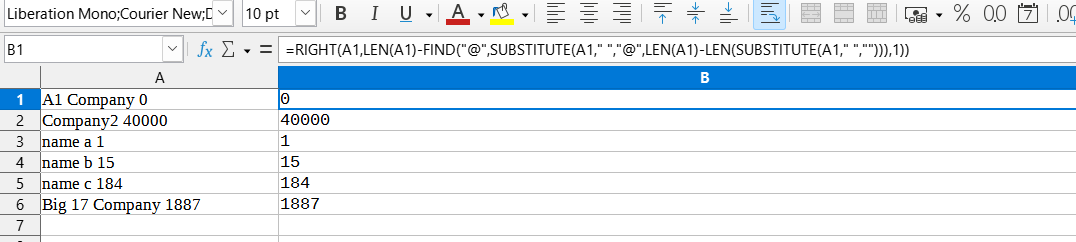
使用 Libre Office,但此公式檢查單元格中的最后一個空格
=RIGHT(A1,LEN(A1)-FIND("@",SUBSTITUTE(A1," ","@",LEN(A1)-LEN(SUBSTITUTE(A1," ",""))),1))
取自: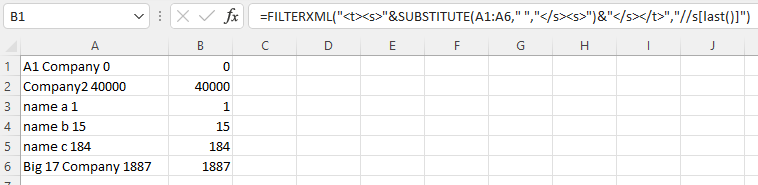
uj5u.com熱心網友回復:
看看以下是否適合您:
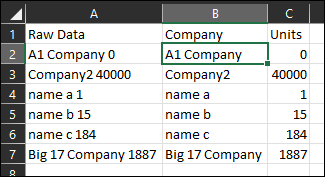
中的公式B2:
=LEFT(A2,LEN(A2)-1-LEN(C2))
在C2:
=-LOOKUP(1,-RIGHT(A2,ROW($1:$5)))
對于使用 ms365 最新功能的用戶:
=HSTACK(TEXTBEFORE(A2," ",-1),TEXTAFTER(A2," ",-1))
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/487447.html