1 背景與挑戰
1.1 背景介紹
1.1.1 課程概述
- 了解雙11 的歷程
- 學習當前主流的電商系統架構體系
- 了解大促對電商系統的一些挑戰
- 面對大促活動,站在架構師角度思考,可能有哪些問題,如何應對
1.1.2 雙11歷程
(最早接觸雙11的年份?)
? 起于2009年,剛開始的雙十一還并不出名,電商開展促銷月都是以各自的店慶月作為基礎的,國美在線是4月份,京東6月份,易購8月份,而淘寶商城選擇了雙十一作為促銷月,促銷的初衷是光棍節(11月11日)大家沒事干,就該買點啥東西去當禮物送人,于是乎,雙11就這樣誕生了,
- 2009年 銷售額0.52億,27家品牌參與;
- 2010年 銷售額9.36億,711家品牌參與;
- 2011年 銷售額33.6億,2200家品牌參與;
- 2012年 銷售額132億,10000家品牌參與;
- 2013年 銷售額352億,20000家品牌參與;
- 2014年 銷售額571億,27000家品牌參與;
- 2015年 銷售額912億,40000家品牌參與;
- 2016年 銷售額1207億,98000家品牌參與;
- 2017年 銷售額1682億,140000家品牌參與;
- 2018年 銷售額2135億,180000家品牌參與;
- 截止到2019年11日23時59分59秒 銷售額2684億,
了解雙11背景下電商公司的應對措施,有助于提升高訪問量背景下的系統架構知識,
1.2 電商整體架構
1.2.1 概述
? 從組織架構到技術架構,當前各大電商系統基本趨于中臺化,中臺在2015由阿里提出,其實是一種企業架構而不是單純的技術層面,目前幾乎各大電商都進行著中臺化的建設,
? 中臺沒有什么神秘的,說到底,中臺就是對 ”共享“ 理念系統化的歸納和總結,
- 重復功能建設和維護帶來的重復投資
- 煙囪式建設造成系統壁壘,資料孤島
- 業務沉淀促進可持續發展
- 大中臺小前臺快速回應市場的需要
?
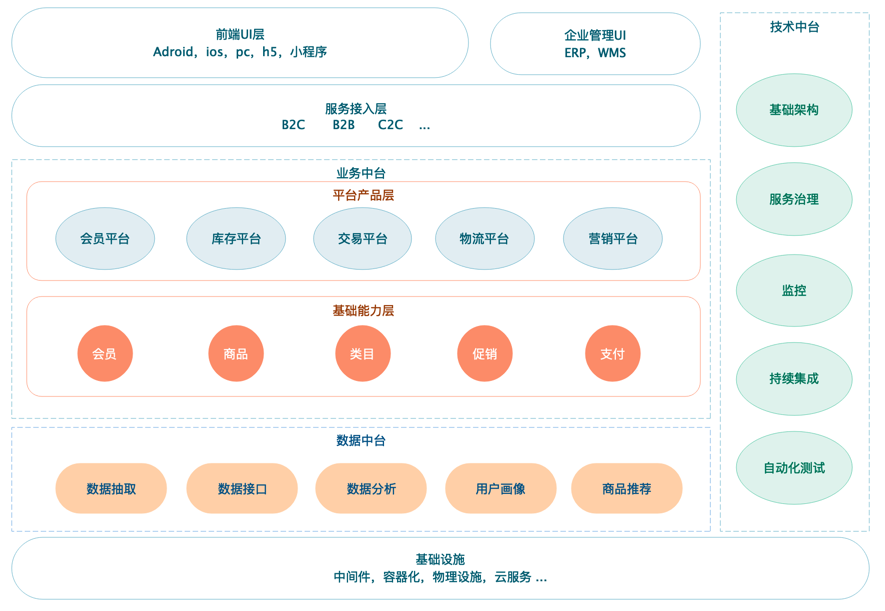
1.2.2 上層業務
? 即大中臺,小前臺的前臺,電商中直面用戶的B2B,B2C等各個業務線,
1.2.3 業務中臺
? 業務中臺基于公共服務的沉淀,需要收斂一些基礎的業務服務,如商品、訂單、會員、庫存、財務、結算等等,
1.2.4 資料中臺
? 資料中臺不是一個平臺,也不是一個系統,資料倉庫、資料平臺和資料中臺是有區別的,簡單的舉例:資料平臺可以理解為資料庫,資料倉庫類比為報表,而資料中臺更貼近上層業務,帶著業務屬性,
1.2.5 技術中臺
? 與業務無關的基礎沉淀,中間件,系統框架,監控,日志,集成部署等等
1.2.6 運維中臺
? 不一定存在,系統運維相關的內容,硬體,機房,包括企業云平臺的建設等可以劃分為單獨的運維中臺
1.3 面臨挑戰
1.3.1 考量維度
(根據專案情況有所偏重,例如分布式與一致性是一對矛盾)
- 高性能:提供快速的訪問體驗,
- 高可用:網站服務7*24正常訪問,
- 可伸縮:硬體彈性增加/減少能力(快速擴容與釋放),
- 擴展性:方便地增加/減少新的功能/模塊(迭代與服務降級),
- 安全性:安全訪問和資料加密、安全存盤等策略,
- 敏捷性:快速應對突發情況的能力(災備等),
1.3.2 內部瓶頸
-
木桶效應:水管最細的地方決定流量,水桶最低的地方決定容量(QPS壓測調優為例)
-
CPU:序列化和反序列化、復雜運算、大量反射、大量執行緒的應用
-
記憶體:使用記憶體的中間件或服務,如redis,memcache,jvm大量物件堆積記憶體的應用等
-
網路帶寬:大流量高并發環境下,雙11用戶訪問量激增,造成網路擁堵
-
磁盤IO:檔案上傳下載,資料庫頻繁讀寫,不合理或大批量的日志輸出
-
資料庫連接數:應對雙11,應用服務器連接池大批擴容,警惕底層資料庫、Redis等連接數瓶頸
1.3.3 外部服務
-
短信:外部短信延遲與送達率問題,可以搭建短信平臺,多家渠道做路由和切換分流(讓你設計短信平臺,會考慮哪些問題?如何做架構?)
-
支付:銀行支付與回呼延遲,搭建支付中心,對接多支付渠道
-
快遞對接:快遞服務對接(快遞100)
-
外部云存盤:云存盤檔案訪問,流量擴容(大家所使用的存盤?nfs的架構與事故)
-
CDN:外部靜態檔案訪問提速服務(使用過的專案?)
2 應對措施
? 該小節從中臺的各個團隊角度,介紹雙11期間的一些應對措施和遇到的問題,
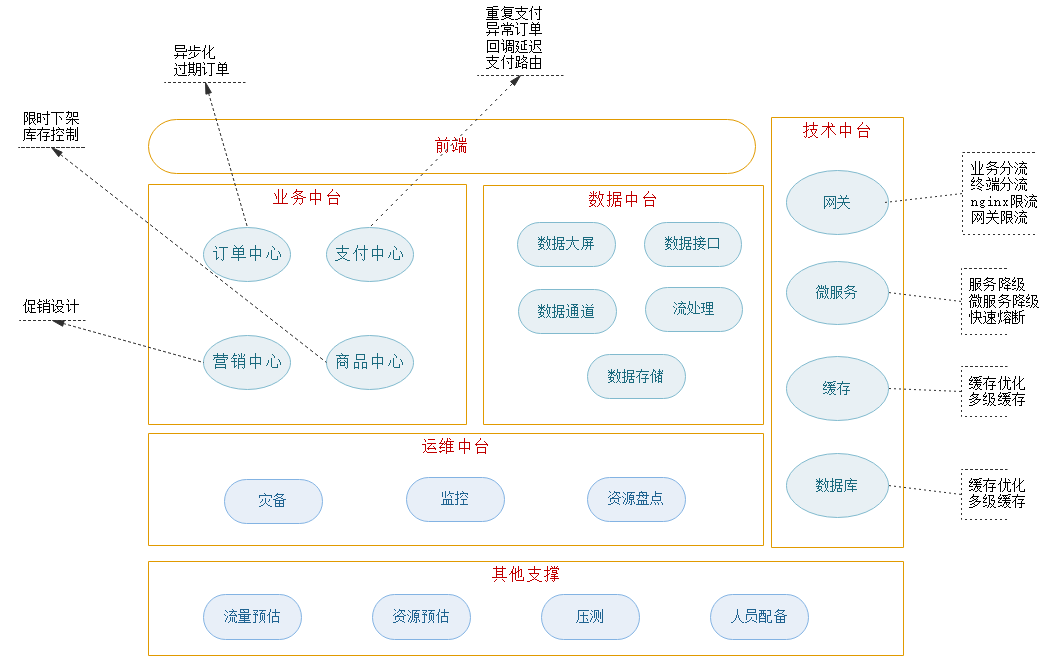
2.1 業務中臺
2.1.1 訂單中心
1)異步化
(異步化的目的是什么?大家使用過的mq?遇到的問題?)
場景:
? 大促期間新增許多需要獲取訂單狀態的服務,比如應對雙11而臨時增加的資料中臺訂單大屏展示等
解決:
? 異步化,并對訊息佇列調優,多佇列分流
問題:
? 注意異步化引發的亂序問題,一是傳輸階段,二是消費階段
? 區域有序與絕對有序
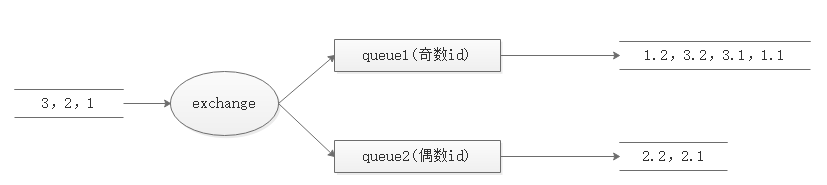
圖解:
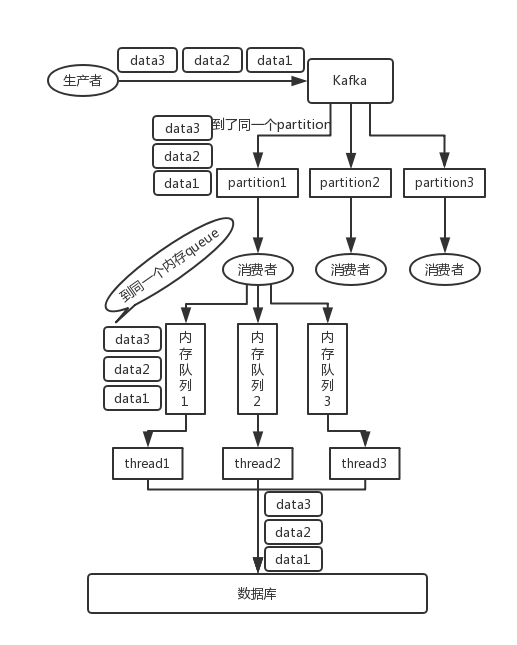
rabbitmq傳輸:佇列級別順序保障,單消費者消費一個佇列可以嚴格保障順序性,需要擴充佇列數提升性能
kafka傳輸:磁區級別順序保障,只能保障投放和傳輸階段的順序性
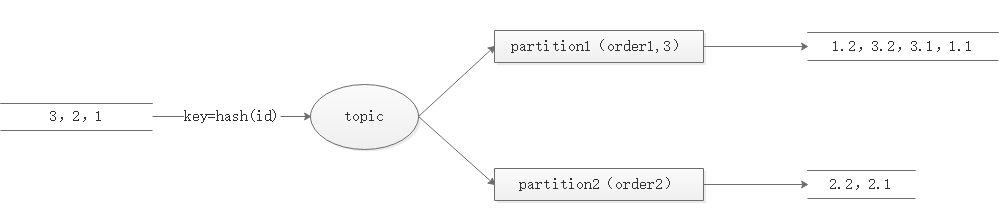
消費階段:1對1消費存在性能問題,接收訊息后對key做二次分發,放入多個記憶體佇列,開啟多執行緒消費
2)過期訂單
(場景及思考,如果讓你做架構設計有什么方案?這些方案有什么優缺點)
? 雙11搶單是最常見的場景,搶單不支付會占據大批量資源,如商品庫存,如何取消過期訂單是架構師必須面對的問題,主要有以下幾種方案:
掃表實作
原理:
? 通過定時任務輪詢掃描訂單表,超時的批量修改狀態
優點:
- 實作非常簡單
缺點:
-
大量資料集,對服務器記憶體消耗大,
-
資料庫頻繁查詢,訂單量大的情況下,IO是瓶頸,
-
存在延遲,間隔短則耗資源,間隔長則時效性差,兩者是一對矛盾,
-
不易控制,隨著定時業務的增多和細化,每個業務都要對訂單重復掃描,引發查詢浪費
java延遲佇列實作
原理:
? 通過DelayQueue,每下一單,放入一個訂單元素并實作getDelay()方法,方法回傳該元素距離失效還剩余的時間,當<=0時元素就失效,就可以從佇列中獲取到,啟用執行緒池對資料監聽,一旦捕獲失效訂單,取出之后,呼叫取消邏輯進行處理,(多執行緒課題案例)
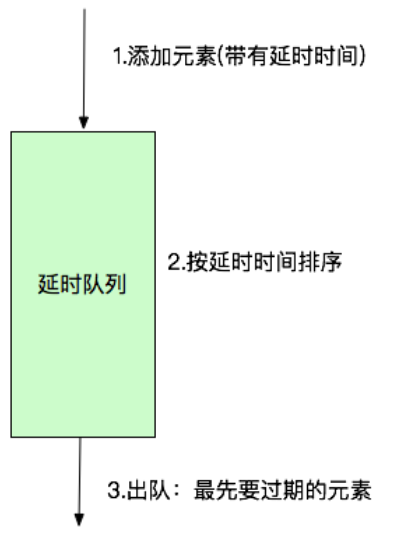
優點:
- 基于jvm記憶體,效率高,任務觸發時間延遲低,
缺點:
- 存在jvm記憶體中,服務器重啟后,資料全部丟失,
- 依賴代碼硬編碼,集群擴展麻煩
- 依賴jvm記憶體,如果訂單量過大,無界佇列內容擴充,容易出現OOM
- 需要代碼實作,多執行緒處理業務,復雜度較高
- 多執行緒處理時,資料頻繁觸發等待和喚醒,多了無謂的競爭
訊息佇列實作
原理:
? 設定兩個隊列,每下一單放一條進延遲佇列,設定過期時間,訊息一旦過期,獲取并放入作業佇列,由consumer獲取,喚起超時處理邏輯
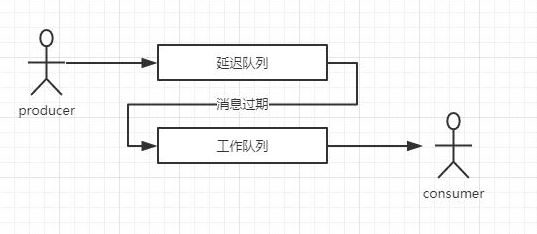
? 如果采用的是RabbitMQ,其本身沒有直接支持延遲佇列功能,可以針對Queue和Message設定 x-message-ttl,用訊息的生存時間,和死信佇列來實作,具體有兩種手段, A: 通過佇列屬性設定,佇列中所有訊息都有相同的過期時間,粗粒度,編碼簡單 B: 對訊息進行單獨設定,每條訊息TTL可以不同,細粒度,但編碼稍微復雜,
優點:
-
訊息存盤在mq中,不占用應用服務器資源
-
異步化處理,一旦處理能力不足,consumer集群可以很方便的擴容
缺點:
- 可能會導致訊息大量堆積
- mq服務器一旦故障重啟后,持久化的佇列過期時間會被重新計算,造成精度不足
- 死信訊息可能會導致監控系統頻繁預警
redis實作
原理:
? 利用redis的notify-keyspace-events,該選項默認為空,改為Ex開啟過期事件,配置訊息監聽,每下一單在redis中放置一個key(如訂單id),并設定過期時間,
優點:
- 訊息都存盤在Redis中,不占用應用記憶體,
- 外部redis存盤,應用down機不會丟失資料,
- 做集群擴展相當方便
- 依賴redis超時,時間準確度高
缺點:
- 訂單量大時,每一單都要存盤redis記憶體,需要大量redis服務器資源
被動取消
原理:
? 在每次用戶查詢訂單的時候,判斷訂單時間,超時則同時完成訂單取消業務,
優點:
- 實作極其簡單
- 不會有額外的性能付出
- 不依賴任何外部中間件,只是應用邏輯的處理
缺點:
- 延遲度不可控,如果用戶一直沒觸發查詢,則訂單一直掛著,既不支付也未取消,庫存也就被占著
2.1.2 支付中心
支付互動流程,支付系統設計偏重,關于做過的那些支付系統2014與2018的架構變化,政策的變動經歷,
1)重復支付
(2018重復支付事故)
原因:
? 在第一步發起的時候,用戶進入支付方式選擇頁,選第一個支付方式并支付完后因為通知延遲,以為支付失敗,在支付又選了第二種,再次支付,
應對方案:
? 程式屏蔽,前端js觸發按鈕置灰或者遮罩提示(支付成功?遇到問題?),或者在支付方式選擇頁直接跳轉,
? 后端處理,發現不同通道下的支付成功回呼,拋訊息佇列或記錄日志,
資料修復:
? 首先查支付日志,確認針對同一筆訂單收到了不同支付渠道的回呼,
? 其次,在支付平臺管理后端可以查到入賬記錄,人工介入,
? 最后對賬階段會發現對方多帳,我方補單時出現重復訂單,
問題處理:
? 調取退款介面或者在支付渠道的管理后臺操作退款(一定要多次確認無誤),
2)例外訂單
支付但未開單
場景:
? 用戶明明支付成功,但未開通訂單
問題分析:
? 一般支付渠道會間隔性多次回呼開單鏈接,如果支付未開單,銀行未回呼的可能性比較小,著重排查開單介面是否可用,如果可用追查日志是否出現例外記錄,
應對措施:
-
對賬階段可以查漏,程式自動完成補單,但是處理相對延遲,取決于支付渠道的對賬檔案下發周期(2011-2013年,支付測驗資料與財務人工對賬的歷程)
-
人工補單,人工查詢支付渠道后臺資料,確認已支付的情況下,介入補單流程人工處理
未支付但已開單
場景:
? 用戶未支付,或者財務中心未收到這筆款項,訂單狀態已開通,這種就問題比較嚴重了
應對措施:
? 首先排除人為操作因素,其次排查系統是否存在漏洞或者級聯開單的情況(支付中心測驗環境資料回呼造成線上意外開單經歷)
3)回呼延遲
場景:
? 用戶是期望支付完成的同時立馬看到結果,但是中間多層遠程的呼叫,可能發生訂單狀態更新延遲問題,
解決:
? 主動查詢,在用戶查看訂單的時候,如果是類似“支付中”的中間態時,觸發遠程訂單狀態查詢介面,(大家看到的點擊“支付完成”跳轉的程序,觸發遠程支付結果查詢)
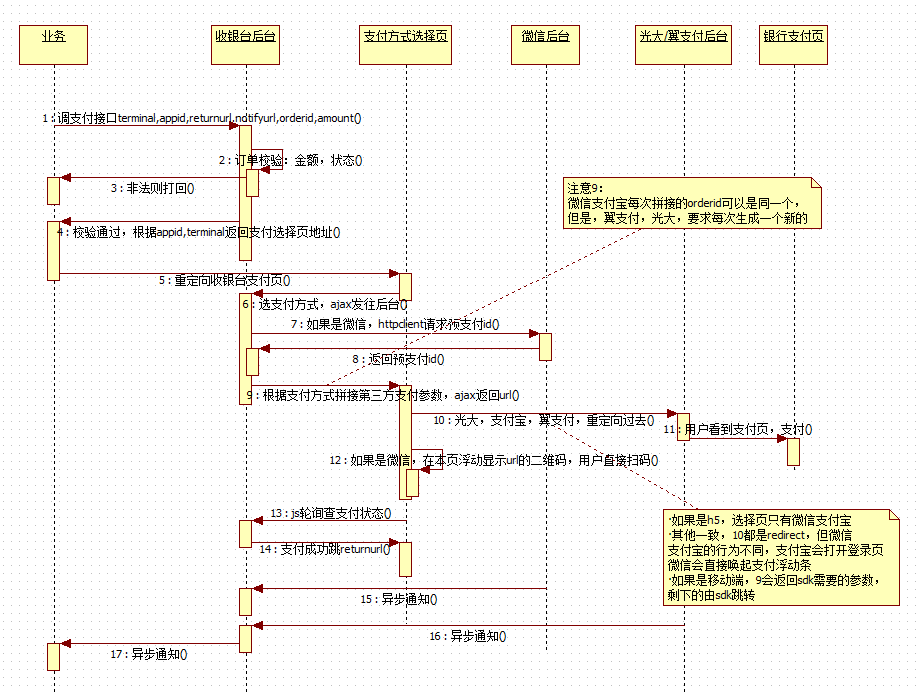
4)支付路由
(你所看到的收銀臺圖示內情...)
背景:
? 保障支付可用性及支付分流,支付中心對接多家渠道
方案:
- 支付中心對接多個支付渠道,支付寶,微信,各銀行或第三方支付供應商,
- 對不同用戶,進入支付方式選擇頁時,做支付分流,
- 做好監控統計,一旦某個支付渠道不可用或者延遲較大,切掉,下線,或者降權,
2.1.3 營銷中心
1)概述
? 大促和活動不分家,一般營銷中心所面對的主要是促銷策略、優惠方式等業務上的架構問題,
? 從促銷活動的范圍來看,分為單品促銷活動、套裝促銷活動、店鋪促銷活動,平臺促銷活動,
? 從促銷型別來看,分為滿減、折扣、贈品等,
? 業務復雜度高,一般遵循 “同類營銷僅可選其一,不同類營銷可疊加” 的規則,同類疊加意義不大且會造成系統復雜度上升,引發用戶困惑,
2)前端設計
? 用戶體驗上的設計,比如購物車里商品的排序,按商鋪分門別類,優惠總價格及時調整,這些依賴于前端的ui設計和互動體驗,
3)贈品設計
(SPU , SKU 基礎概念,如何設計表結構?京東怎么做的)
? 贈品有兩種設計方案,一種是不做單獨的SKU,只有一個空的描述,設計簡單,缺點是沒有商品詳情頁,無法給用戶直觀的查看和估值,
? 另一種是單獨做SKU,贈品也會作為一個商品存在,與主商品關聯,下單的時候將會自動加到商品串列,價格降為0,這種更為常見,整個商品有完善的詳情頁,用戶可以直接看到價格甚至單獨下單購買,
4)排他與優先級
? 檢查同類別促銷,將最大優惠力度的規則應用到訂單,并且滿足排他性,同類只享受其一,比如滿10減3,滿20減5,那么用戶購買大于20時,只減5即可,
? 不同類別不做排斥,如購物車整體滿減后,不影響單個商品的折扣,在記錄資料時,優惠要細化到每個單獨的訂單明細上,退款也做到明細級別的單獨退,
5)價格分攤
(有沒有遇到精度問題?價格欄位如何設計?)
? 滿級訓平臺券等優惠,在多個商品下單時,涉及到金額的分攤,即 優惠總額度/購物車總額 ,得到比例后再按比例均分到每個商品,只有分攤才能在發生部分退款時退回真實金額,
? 但是這會涉及到一個精度問題,舉例如下:滿99減9活動,假設用戶購買了 30+40+50=120,3件商品應付111元,按比例折算的話,9/99取4位小數是0.9090,那么分攤后為 30x0.9090+40x0.9090+50x0.9090=109.08與實際支付金額出現偏差,這會造成財務無法平賬,
? 解決方案:記賬時在訂單明細記錄,將誤差 111-109.08=1.92計入金額最大的明細,也就是50元商品上,那么最終記賬為:30x0.9090 + 40x0.9090 +(50*0.909+1.92)= 111
6)退單處理
? 退單后要同時恢復用戶的權益,比如優惠券的再次使用,限購次數等,確保用戶體驗,
2.1.4 商品中心
1)限時商品的下架控制
? 這個和超時訂單設計方案類似,前面已經提到不再贅述,
2)庫存管理
? 普通商品可以直接借助資料庫鎖實作,一般分樂觀鎖和悲觀鎖兩種方案,如果采用悲觀鎖(如select陳述句帶forupdate),會帶來很大的性能阻塞,所以更多的采用樂觀鎖設計,(冪等性課題的鎖機制有詳細講解)
? 樂觀鎖就是在最后執行庫存扣減操作時,將事務開始前獲取的庫存數量帶入到SQL陳述句中作為更新的where條件,如果數量相等,則該條更新庫存的陳述句成功執行回傳update條數為1;如果不相等,則表示該商品的庫存資訊已經被其他事務修改,需要放棄該條update的執行,采用重試處理,
? 庫存秒殺商品因為大批量的訪問在一瞬間涌入,資料庫扛不住,可以采用 redis快取做decr處理,正常下單后,再使用mq異步更新到db,(秒殺不超賣課題的庫存控制)
2.2 技術中臺
2.2.1 資料庫優化
? 資料庫層的調優,一般發生在大促前的預備階段,一旦大促開始,對資料庫的優化已經來不及了,
-
在大促開始前梳理耗時查詢業務,對關鍵業務壓測,
-
開啟mysql的慢查詢日志(兩種方式)
#組態檔方式,需要重啟mysql #日志檔案位置 log-slow-queries=/opt/data/slowquery.log #超時時間,默認10s long_query_time=2 #臨時開啟,不需要重啟 set global slow_query_log=on; set global long_query_time=10; set global slow_query_log_file=‘/opt/data/slow_query.log’ -
使用mysqldumpslow命令決議mysql慢查詢日志
-- 慢查詢日志以文本打開,可讀性很高 -- 查詢次數,耗時,鎖時間,回傳結果集條數(掃描行數),執行者 Count: 1 Time=10.91s (10s) Lock=0.00s (0s) Rows=1000.0 (1000), mysql[mysql]@[10.1.1.1] SELECT * FROM order_history -
借助explain查看sql執行計劃,對sql調優,或其他優化工具,
2.2.2 快取優化
(業務篇紅包雨課題里有快取結構的深度應用)
1) 策略
熱點資料預熱:
(常規加載機制畫圖展示)
? 常規快取設計趨向于懶加載,大促期間的熱點資料盡量做到預熱加載,比如某個促銷專題,不要等待活動開始的一瞬間再讀庫加快取,搞不好引發擊穿,
細粒度設計:
(細粒度快取結構畫圖展示)
? 集合與單體分開存盤,快取結構細粒度化,如某個櫥窗的推薦商品串列,常規存盤一個key,value為整個商品集合,優化為串列與每個商品詳細資訊設定兩個獨立快取值,在查詢環節組裝,可以降低發生修改時對快取的沖擊,新增一個推薦則失效串列,修改商品則僅僅失效當前商品快取,
可用性:
(回顧三種快取問題)
-
只要快取失效時間設定分散,雪崩的可能性不大
-
防范惡意攻擊引發穿透,前端做到防刷,業務層面要注意合法性校驗,非法key的失效時間需要評估,
-
擊穿可能性升高,大促高并發下,修改時,如果采用key洗掉策略很可能觸發擊穿,修改少可以優化為雙寫,
2)多級快取
? 優化快取體系,對關鍵業務請求,如商品詳情頁,采用多級快取處理
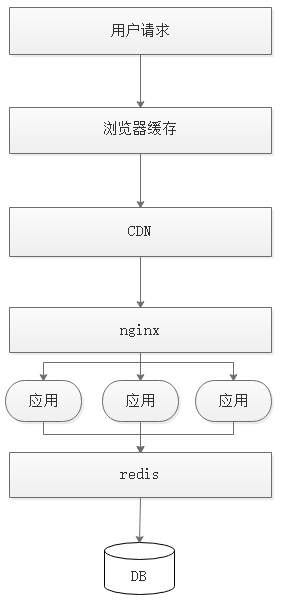
? 首先看瀏覽器快取,一般瀏覽器快取可分為兩種手段,分別交給瀏覽器和服務端執行
-
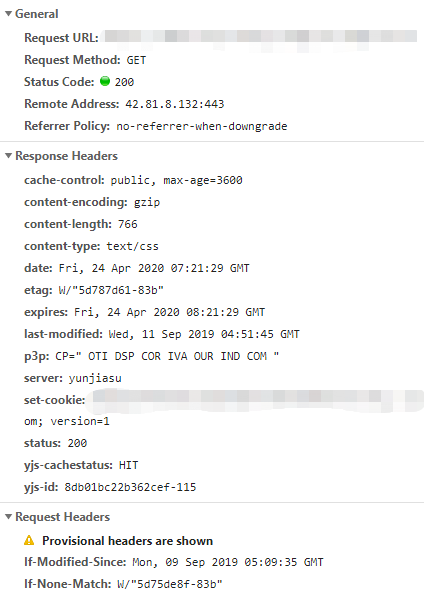
客戶端判決:為請求Header設定Expires(http1.0) 和 Cache-Control(http1.1),客戶端本地比較決定是否使用快取
-
服務端判決:借助Last-Modified/If-Modified-Since(http1.0)或ETag/If-None-Match,服務器端比較決定回傳200帶body還是304僅有head頭 (畫圖展示)
-
Last-Modified < ETag < Expires < Cache-Control
? CDN:借助CDN的dns決議,對用戶做ip分流,CDN作為應用服務器的代理,抵擋前端的流量洪峰,同樣,前面提到的http快取策略對CDN依然有效,
? nginx快取:nginx除了作為負載均衡,也可以作為請求級別的快取,一段典型配置如下:
proxy_cache_path 快取檔案路徑
levels 設定快取檔案目錄層次;levels=2:2:2 表示三級目錄,每級用2位16進制數命名
keys_zone 設定快取名字和共享記憶體大小
inactive 在指定時間內沒人訪問則被洗掉
max_size 最大快取空間,如果快取空間滿,默認覆寫掉快取時間最長的資源,
# 定義快取路徑、過期時間、空間大小等
proxy_cache_path /tmp/nginx/cache levels=2:2:2 use_temp_path=off keys_zone=my_cache:10m inactive=1h max_size=1g;
server {
listen 80;
server_name xxx.xxx.com;
# 添加header頭,快取狀態資訊
add_header X-Cache-Status $upstream_cache_status;
location / {
# 定義快取名
proxy_cache my_cache;
# 定義快取key
proxy_cache_key $host$uri$is_args$args;
# 針對回傳狀態碼單獨定義快取時間
proxy_cache_valid 200 304 10m;
# url 上設定請求 nocache=true 時不走快取,
proxy_cache_bypass $arg_nocache $http_nocahe;
proxy_pass http://localhost:8080;
}
}
? 分布式快取:redis做應用層快取,不多解釋,但是要注意做好擴容預案和業務層優化
- 依據預估量做相應的擴容或資源申請,純做快取時可以關閉持久化,記憶體超出60%將變得不穩定,
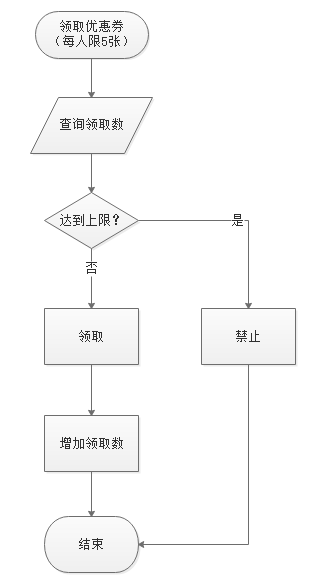
- 頻繁互動業務從java端下移到lua腳本實作,一方面可以實作原子性,另一方面有效減少網路延時和資料的冗余傳輸,以平臺優惠券領取為例:(搶紅包介面課題有涉及)
2.2.3 分流與限流
(演算法與資料結構應用 - 限流演算法有詳細實作)
? CDN的引入本身起到了按ip分流的作用,但是我們可以在下層做到更細粒度化的控制,根據業務情況將不同的請求分流到各自的服務器,
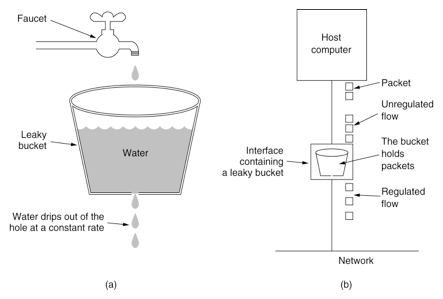
? 限流不同與分流,是對下層的保護,當系統超過一定流量后,超過的流量做直接拒絕處理,以便保護后端的服務,原則就是要么不進來,進來的都正常服務,常見的限流演算法有三種:計數器(滑動視窗)、漏桶、令牌桶,
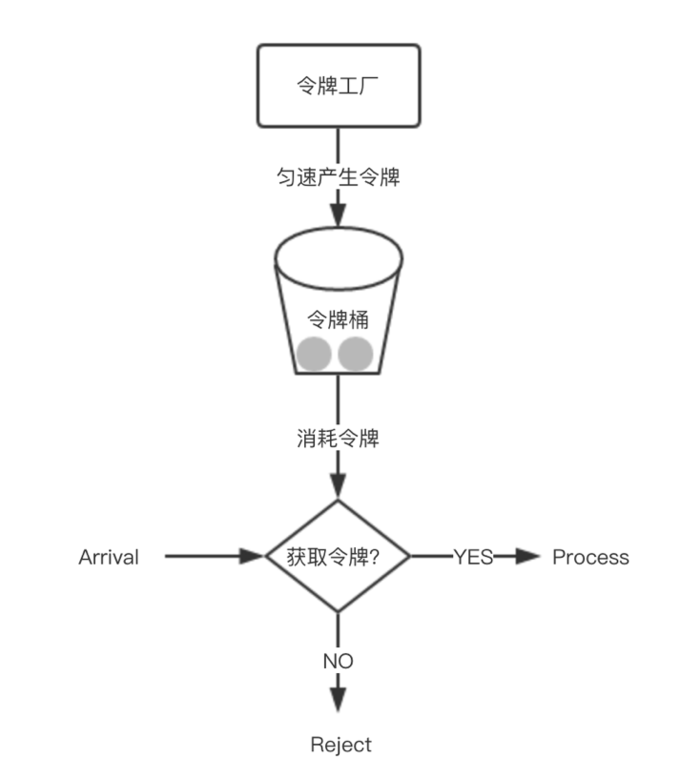
1) 業務分流
? 根據不同的業務線分發請求,配備二級域名如b2b.xxx.com,b2c.xxx.com,或者在nginx軟負載層針對不同虛擬主機名做upstream分發
? 新上的雙11活動頁,或者促銷專題頁面,采用新訪問入口和機器部署,與主站分離,活動結束后也利于機器資源的快速釋放(有沒有遇到臨時性需求的場景?上線就用1天)
2) 終端分流
? 按不同的請求終端分流,在header頭的user-agent中可以捕獲用戶的訪問終端,android,ios,pc,根據不同終端設備,做流量分發,到不同的應用機器,同時方便對用戶終端流量的監控和統計,
3)nginx限流
? 評估雙11可能的流量,結合具體業務模塊,配備對應限流措施,主要有流量限制和連接數限制兩個維度,
? 流量限制:限制訪問頻率,其目的是基于漏桶演算法實作ip級別的防刷,Nginx中使用 ngx_http_limit_req_module 模塊來限制請求的訪問頻率,基于漏桶演算法原理實作,
#$binary_remote_addr 表示通過remote_addr這個標識來做限制
#binary_的目的是縮寫記憶體占用量,是限制同一客戶端ip地址
#zone=one:10m表示生成一個大小為10M,名字為one的記憶體區域,用來存盤訪問的頻次資訊
#rate=1r/s表示允許相同標識的客戶端的訪問頻次
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
server {
location /b2b/ {
#zone=one 設定使用哪個配置區域來做限制,與上面limit_req_zone 里的name對應
#burst=5,設定一個大小為5的緩沖區,當有大量請求時,超過了訪問頻次限制的請求可以先放到這個緩沖區內
#nodelay,如果設定,超過訪問頻次而且緩沖區也滿了的時候就會直接回傳503,如果沒有設定,則所有請求會等待排隊
limit_req zone=one burst=5 nodelay;
}
}
? 連接數限制:Nginx 的 ngx_http_limit_conn_module模塊提供了對資源連接數進行限制的功能,(同一個出口ip,如公司內部共享一個出口ip,可能會被整體限制)
#$binary_remote_addr同上
limit_conn_zone $binary_remote_addr zone=addr:10m;
server {
location /b2b/ {
# 限制每個ip下最大只能有一個連接
limit_conn addr 1;
}
}
4)網關限流
? 從代理服務器放進來的流量,會進入應用服務器,第一道關卡是微服務的網關,應對大促,針對各個微服務具體業務具體分析,配備對應限流措施,zuul和gateway是團隊中最常遇到的網關組件,
zuul.routes.userinfo.path=/user/**
zuul.routes.userinfo.serviceId=user-service
zuul.ratelimit.enabled=true
zuul.ratelimit.policies.userinfo.limit=3
zuul.ratelimit.policies.userinfo.refresh-interval=60
zuul.ratelimit.policies.userinfo.type=origin
routes:
- id: user_route
uri: http://localhost:8080
predicates:
- Path=/*
filters:
- name: RequestRateLimiter
args:
redis-rate-limiter.replenishRate: 1
redis-rate-limiter.burstCapacity: 1
key-resolver: "#{@ipKeyResolver}
2.2.4 服務降級
? 當服務器壓力劇增的情況下,根據實際業務情況及流量,對一些服務和頁面有策略的不處理或換種簡單的方式處理,從而釋放服務器資源以保證核心交易正常運作或高效運作,是一種舍車保帥的策略,
? 比如平時客戶來我的店鋪購買衣服,平時可以試穿,給出建議,幫助搭配,最后下單支付,送用戶祝福卡片等,雙11大促則簡單粗暴回應下單支付收錢發貨,其他不太重要的服務關閉開關,騰出資源讓位主交易流程,
? 服務降級可以從前端頁面,后端微服務兩個點著手,
1)頁面降級
? 很好理解,針對頁面元素處理,將不重要的操作入口置灰或屏蔽,平時呼叫后端介面實時呈現資料的地方替換為靜態頁也可以理解為一種降級操作,
2)微服務降級
? 配置介面開關,并通過配置中心可以靈活開閉,必要時關閉開關,屏蔽介面的實際查詢,直接回傳mock資料,例如,購買了本商品的用戶還購買過哪些商品介面,在業務上需要呼叫資料中臺訂單統計服務,訪問量大時,關閉對外呼叫,直接回傳設定好的一批相關商品,起到降級保護作用,
3)快速熔斷
? 快速熔斷可以認為是在應對突發情況時,對服務請求結果準確性的一種妥協,避免因單一服務垮臺導致整個呼叫鏈路崩潰,常用手段如下:
-
拋例外:這種處理需要上層配備例外處理機制,在捕獲例外時,導向錯誤頁、等待頁或稍后重試等,
-
回傳NULL:簡單粗暴,可能會出現空白結果,并不友好,
-
呼叫Fallback處理邏輯:更人性化的手段,也最常用,為每個業務配備一個備選方案,
? 舉個例子:商品頁或訂單詳情頁面,一般都會有猜你喜歡這個模塊,通過對用戶的購買行為、瀏覽記錄、收藏記錄等等進行大資料分析,然后給每一個用戶推送自己可能喜歡的商品,在雙11大促背景下,如果推薦服務壓力過大,出現服務出錯、網路延遲等等之類突發情況,導致最后呼叫服務失敗,則可以配備一個fallback,直接回傳當前商品同類別下的幾款商品,作為備選方案,這比拋例外或者回傳null空白頁面體驗要更優,
2.2.5 安全性
? 大促前做好安全防范,常見的DDos,Arp,腳本等攻擊平時也會存在,日常防范已經配備,大促期間需要注意的可能更多的是業務層面的入侵,比如搶購或秒殺時的惡意刷介面,
- 實名制,限制單用戶,單ip等維度下的頻次
- 必要的地方添加驗證碼(圖片復雜度升級,或滑塊等新型方式)
- 黑名單機制,一旦發現惡意行為,列入黑名單,并自動維護
2.3 運維中臺
2.3.1 做好災備
(2018從一次斷電看災備的背景與經歷,30分鐘以內)
? 災備是應對大型故障的保底措施,最好的結局是永遠不要觸發,但是大促前需要做好災備切換演練,可以選擇大促前用戶量少的時間段進行:
1)前期準備:兩地災備程式同步維護,大促相關的迭代和活動專題上線確保兩地測驗ok,鏡像版本統一
2)資料庫配置兩地主從,或雙主單寫,切換前做好資料同步性檢查
3)啟用腳本,切換代理服務器,代理流量轉入災備機房,正式環境還需要處理dns指向
4)分布式檔案災備日常采用rsync等實時同步,采用云存盤的可以忽略
5)es索引等其他資料確保日常同步
6)注意掛好維護頁,友好提示
7)配備自動化測驗腳本以便快速驗證切換結果
2.3.2 配備監控
1)基礎設施監控
? 包括物理機、Docker 容器、以及對交換機、IP 進行監控 (容器課題)
? 借助zabbix等開源軟體對機器資源配置監控,如果采用云化部署,各大云供應商都會配備完善的監控機制
2)應用級監控
? 主動監控,日志或訊息佇列形式打點輸出,定時匯報 (日志平臺追蹤課題)
? 被動監控,添加監控介面,監控系統定時請求確認可用性
3)業務監控
? 對具體業務點做監控處理,如訂單量、登錄量、注冊量、某些頁面的訪問量等關鍵點采用異步訊息方式推送到監控中心,監控中心針對特定佇列的資料做統計和展示,
4)客服一線反饋
? 主動監控依然無法察覺的情況下,來自客服的一線反饋成為最后關卡,優先級也最高,開發故障快速回應平臺,做到實時性保障,做到客服 - 業務線 - 產品 - 技術排查的及時回應,快速排查,
2.3.3 資源盤點
1)網路設施擴容
? 網路帶寬是影響訪問流量的重要因素,做好各個機房網路帶寬預估,資料在兩地機房間傳輸并且要求低延遲的場景,如資料庫主從,可以考慮機房專線,使用公有云的服務,可以購買臨時流量,
2)硬體資源盤點
? 對容量做預估和硬體資源盤點,配合大促期間不同服務的架構設計,以及專案本身的特性,對cpu,記憶體做評估,偏運算的專案,重度使用多執行緒的專案偏cpu,需要大量物件或集合處理的專案偏記憶體,
3)容器盤點
? 所有專案容器化部署,基于鏡像即版本理念,打好各個服務的鏡像是docker快速復制擴容的基礎,大促前對各個中心微服務做統計和盤點,
? 借助swarm和k8s等編排工具,快速實作容器的伸縮, (運維篇會講到)
2.4 資料中臺
? 資料中臺多為大資料相關架構體系,大促期間,同樣可能面臨大批資料洪峰,比如訂單量激增、用戶行為資料暴漲等場景,簡單看一下可能需要做的一些應對,(大屏實時計算課題)
2.4.1 資料通道
? 對資料傳輸通道擴容,比如kafka擴大磁區數,rabbitmq增加細分佇列,一方面實作了擴容,另一方面在傳輸的起始階段就對資料做了一定的分類,
? 資料降級,關閉某些非核心資料的通道采集,讓位網路帶寬給核心業務資料,
2.4.2 資料展示
? 資料大屏開發,對實時性有一定要求,多采用流式運算,
2.5 其他準備
2.5.1 流量預估
? 對關鍵業務的體量做好預估,如用戶的注冊、下單量、首頁,商品詳情頁等關鍵頁面的qps,為壓測提供參考指標,
2.5.2 資源預估
? 架構師統計各中心服務關系,對各個服務擴容做預估,匯總,
2.5.3 壓測準備
(全鏈路壓測課題)
1)線下壓測
(大家當前使用的環境都有哪些?上線模式是什么樣的)
? 當前成熟系統都具備各種環境,開發環境、測驗環境、準生產環境等,對線下可以選擇準生產環境做為壓測,模擬線上,
? 線下壓測資料安全,不必擔心對線上造成干擾,所壓測的值可以用于相對性比較,比如其中全鏈路的某個環境哪個是瓶頸,但是無法精準反饋線上的真實場景,
2)線上壓測(謹慎!)
? 重點看線上壓測,線上壓測壓出的資料是最真實有效的,但是因為使用的是生產環境,操作不當可能引發災難性后果,
? 1)在全鏈路壓測環境下,服務呼叫關系錯綜復雜,最重要的是實作壓測流量的標識,以及標識在服務背景關系間如何有效傳遞不丟失,服務內借助threadlocal,但是要注意多執行緒下失效,服務間通過改寫遠程呼叫框架或借助框架提供的Context設定,(分布式日志平臺,訪問鏈路追蹤課題)
? 2)資料隔離,資料庫可以創建影子表,redis等快取可以設定shadow_等前綴,從開發框架層面封裝處理,對資料層持久化框架做二次開發,使其自動發現壓測資料,
? 3)外部服務可以借助服務降級功能,添加開關判斷屬于壓測流量時開關進入降級或mock,比如收銀程式添加擋板,直接回傳成功,短信應用直接默認一個短信號碼,
? 4)日志列印需要隔離,可以借助分布式日志平臺收集時采用不同的輸出通道和佇列,
? 5)壓測資料最好的方式是流量克隆(TCPCopy工具等),將線上的實際訪問請求克隆放大幾倍加壓到壓測入口,如果實作不了,盡量模擬線上的真實資料結構和體量,
? 5)做好全壓流量規劃,按預估2~3倍加壓,確定流量比例,打壓,
2.5.4 人員配備
? 人員互備,防止故障,及時回應,應對雙11不是什么神秘事,
任務
- 梳理課題中自己不太熟的知識點
- 在日常專案中多換位思考,換成我如何設計,有什么問題,
- 多歸納總結,在設計中參考下架構思想
本文由傳智教育博學谷 - 狂野架構師教研團隊發布
轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/488685.html
標籤:Java