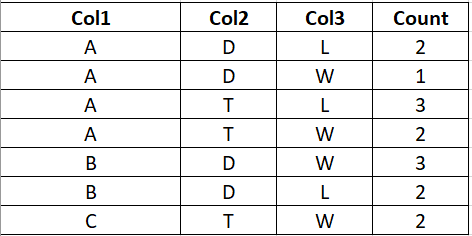
我有以下格式的df。這里的“計數”列是“Col3”的計數。考慮到前兩行,它有 2 個 L 計數和 1 個 W 計數。
input_data = {
'Col1' : ['A','A','A','A','B','B','C'],
'Col2' : ['D','D','T','T','D','D','T'],
'Col3' : ['L','W','L','W','W','L','W'],
'Count': [2,1,3,2,3,2,2]
}
input_df = pd.DataFrame(input_data)
print(input_df)
我想將此df轉換為以下格式-required_df
output_data = {
'Col1' : ['A','A','B','C'],
'Col2' : ['D','T','D','T'],
'New_Col3' : ['L/W','L/W','L/W','W'],
'W_Count' : [1,3,3,2],
'L_Count' : [2,2,2,0]
}
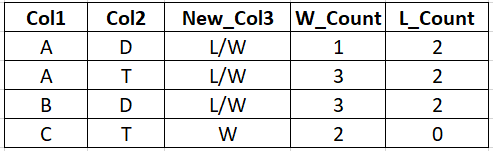
即,將第一個df的前2行轉換為required_df的第一行。對于 ['Col1','Col2'] 的每個唯一集合,'Col3' 的值與 '/' 連接,并且計數添加為 2 個新列 W-Count 和 L_Count。最后一行的變化,其中只有 W 值。
我知道我們需要做 groupby(['Col1','Col2']) 但在此之后無法獲得其他兩列的值,如 required_df 中所反映的那樣。實作這一目標的最佳方法是什么?
由于真實資料很敏感,我不能在這里分享。但是原始資料很大,有數十萬行。
uj5u.com熱心網友回復:
您可以結合 agroupby.agg和pivot_table:
(df
.groupby(['col1', 'col2'])
.agg(**{'New_col3': ('col3', lambda x: '/'.join(sorted(x)))})
.join(df.pivot_table(index=['col1', 'col2'],
columns='col3',
values='col4',
fill_value=0)
.add_suffix('_count')
)
.reset_index()
)
輸出:
col1 col2 New_col3 L_count W_count
0 A D L/W 2 1
1 A T L/W 3 2
2 B D L/W 2 3
3 C T W 0 2
使用的輸入:
df = pd.DataFrame({'col1': list('AAAABBC'),
'col2': list('DDTTDDT'),
'col3': list('LWLWWLW'),
'col4': (2,1,3,2,3,2,2)})
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/488943.html