
前面我們剖析了Redisson的原始碼,主要分析了Redisson實作Redis分布式鎖的15問,理清了Redisson是如何實作的分布式鎖和一些其它的特性,這篇文章就來接著剖析Zookeeper分布式鎖的實作框架Curator的原始碼,看看Curator是如何實作Zookeeper分布式鎖的,以及它提供的哪些其它的特性,
Curator框架是封裝對于zk操作的api,其中就包括了對分布式鎖的實作,當然Curator框架也包括其它的功能,分布式鎖只是Curator的一部分功能,
本文的目錄跟Redisson文章的目錄比較相似,主要是為了方便大家對比redis和zk分布式鎖的實作,如需要Redisson原始碼剖析的文章,請關注微信公眾號 三友的java日記,回復 Redisson 即可,
一、ZK分布式鎖實作原理
實作Zookeeper分布式鎖,主要是基于Zookeeper的臨時順序節點來實作的,
當客戶端來加鎖的時候,會先在加鎖的節點下建立一個子節點,這個節點就有一個序號,類似 lock-000001 ,創建成功之后會回傳給客戶端所創建的節點,然后客戶端會去獲取這個加鎖節點下的所有客戶端創建的子節點,當然也包括自己創建的子節點,拿到所有節點之后,給這些節點進行排序,然后判斷自己創建的節點在這些節點中是否排在第一位,如果是的話,那么就代表當前客戶端就算加鎖成功了,如果不是的話,那么就代表當前客戶端加鎖失敗,
加鎖失敗的節點并不會不停地回圈去嘗試加鎖,而是在自己創建節點的前一個節點上加一個監聽器,然后就進行等待,當前面一個節點釋放了鎖,就會反過來通知等待的客戶端,然后客戶端就加鎖成功了,
為什么需要在前一個節點加個監聽器?
假設有很多客戶端來加鎖,然后加鎖失敗的都對前一個節點加一個監聽,那么一旦第一個加鎖成功的客戶端執行緒釋放了鎖,那么被喚醒的就是第二個客戶端執行緒,第二個客戶端執行緒就會加鎖成功,執行完任務之后就釋放了鎖,那么就會喚醒第三個客戶端執行緒,第三個客戶端執行緒加鎖成功,執行完任務之后就釋放了鎖,喚醒第四個客戶端執行緒,以此類推,所以每次釋放鎖都會喚醒下一個節點,這樣每個加鎖的執行緒都會加鎖成功,所以監聽器的作用是喚醒加鎖失敗阻塞等待的客戶端,
二、為什么使用臨時順序節點
下面介紹一下臨時節點、持久化節點、順序節點的特性,
1)臨時節點
臨時節點,指的是節點創建后,如果創建節點的客戶端和 Zookeeper 服務端的會話失效(例如斷開連接),那么節點就會被洗掉,
2)持久化節點
持久化節點指的是節點創建后,即使創建節點的客戶端和 Zookeeper 服務端的會話失效(例如斷開連接),節點也不會被洗掉,只有客戶端主動發起洗掉節點的請求,節點才會被洗掉,
3)有序節點
有序節點,這種節點在創建時會有一個序號,這個序號是自增的,有序節點既可以是有序臨時節點,也可以是有序持久化節點,
從上面節點的特性可以知道,臨時節點相比持久節點,最主要的是對會話失效的情況處理不一樣,如果使用臨時節點的話,如果客戶端發生例外的話,沒有來得及主動釋放鎖,就能避免鎖無法釋放導致死鎖的情況,因為一旦客戶端例外,那么客戶端和服務端之間的會話就會失效,然后臨時節點就會被洗掉,這樣就釋放了鎖;而持久化節點在由于會話失效無法被洗掉,那么就不會去釋放鎖,這樣就會產生死鎖的問題,
從這里可以看出redis和zk防止死鎖的實作是不同的,redis是通過過期時間來防止死鎖,而zk是通過臨時節點來防止死鎖的,
為什么使用順序節點?其實為了防止羊群效應,如果沒有使用順序節點,假設很多客戶端都會去加鎖,那么加鎖就會都失敗,都會對加鎖的節點加個監聽器,那么一旦鎖釋放,那么所有的加鎖客戶端都會被喚醒來加鎖,那么一瞬間就會造成很多加鎖的請求,增加服務端的壓力,
所以綜上,臨時順序節點是個比較好的選擇,
三、加鎖的邏輯是如何實作的
前面關于ZK分布式鎖實作原理已經說過了,接下來就來看一下代碼的實作,
加鎖的使用方法如下,接下來幾節會著重講解這段代碼背后的邏輯
acquire方法的實作
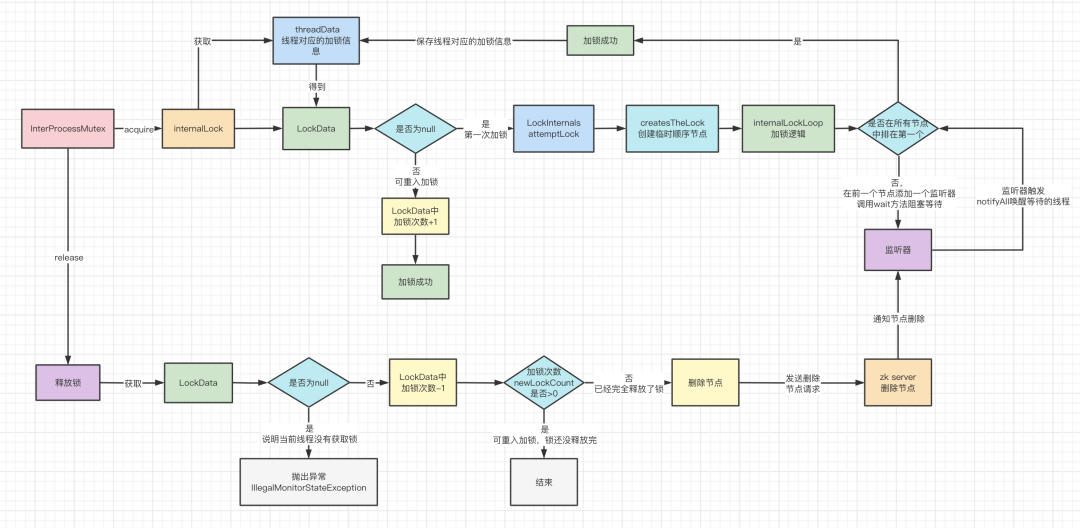
acquire方法會去呼叫internalLock方法,傳入超時時間 -1 和單位 null,也就代表了如果加鎖不成功會一直阻塞直至加鎖成功,不會超時,
internalLock方法會先去獲取當前執行緒,然后從threadData中獲取當前執行緒對應的LockData,這里面封裝了加鎖的資訊和次數,是實作可重入鎖的關鍵,當然第一次加鎖這里肯定是沒有的,會繼續下走 internals.attemptLock 加鎖,
attemptLock方法
先通過driver的createsTheLock去創建節點,
從這里看出,創建的節點型別是臨時順序節點,創建成功之后,就會回傳當前創建的節點,
節點創建成功之后,會呼叫internalLockLoop方法來加鎖,
通過getSortedChildren方法獲取排好序的子節點,然后獲取當前的節點名稱,再通過 driver.getsTheLock判斷當前的節點有沒有加鎖成功,回傳一個PredicateResults判斷的結果,這里面存的就是否加鎖成功的資訊,
第一次加鎖,那么到這里就加鎖成功了,之后就會封裝一個LockData物件,放入threadData 的map中,
加鎖的流程如下圖:
四、如何實作可重入加鎖
上文加鎖的時候提到了,當第一次加鎖成功之后,會往threadData放入該加鎖的執行緒對應的LockData,
LockData主要封裝了當前執行緒、加鎖的次數、加鎖的節點,
此時如果第二次來加鎖,那么就會從threadData中獲取到加鎖的資訊,然后將加鎖次數加1,就代表了加鎖成功,然后直接回傳,
所以可重入加鎖的實作很簡單,就是在客戶端中判斷有沒有加過鎖,加過的話就將加鎖次數累加1,壓根就跟服務端沒有互動,
注意Redisson可重入加鎖的實作跟的Curator是不一樣的,Redisson的加鎖次數是存在Redis的服務端的,而Curator是存在客戶端的,
五、加鎖失敗之后如何實作阻塞等待加鎖
前面加鎖的邏輯主要是說了加鎖成功的情況,這里就來說一下加鎖失敗的情況,
繼續來看internalLockLoop方法,
前面說過,判斷有沒有加鎖成功,會回傳一個PredicateResults,這里面包含了有沒有加鎖成功的資訊,同時如果沒有加鎖成功,就會回傳需要監聽的節點,也就是當前創建的節點的前一個節點,
所以沒有加鎖成功,就會走else的邏輯,對上一個節點加一個監聽器 watcher
然后就會呼叫 wait 方法,進行等待,
當前一個節點被洗掉了,也就是釋放了鎖,那么就會回呼這個監聽器watcher的方法,
所以,這個watcher的作用就是呼叫notifyAll方法喚醒呼叫wait方法的執行緒,這樣執行緒就會繼續嘗試加鎖,因為是在一個while的回圈中,
六、如何實作阻塞等待一定時間還未加鎖成功就放棄加鎖
可通過下面這個方法來實作實作阻塞等待一定時間還未加鎖成功就放棄加鎖,
boolean acquire(long time, TimeUnit unit) throws Exception
這個方法相比不指定等待時間的方法最主要的區別就是加鎖失敗之后,呼叫的阻塞的方法不一樣,當不指定超時時間就會呼叫wait()方法,不會傳入等待時間,不被喚醒就會一直阻塞;指定超時時間的時候,就會呼叫wait(long timeout)指定等待的時間,這樣如果等待時間一到,執行緒就會醒過來,然后再次嘗試加鎖,一旦加鎖失敗,就會放棄加鎖,
七、如何主動釋放鎖和避免其它執行緒釋放鎖
釋放鎖release方法
釋放鎖其實很簡單,就是拿出當前執行緒對應的LockData,如果沒有,就說明當前執行緒沒有加過鎖,就會拋出例外,所以Curator就是通過這個判斷來防止其它執行緒釋放了自己執行緒加的鎖,
如果加鎖了,那么LockData就不會為null,然后將加鎖次數遞減1,得到newLockCount,代表了剩下的加鎖次數,
-
如果newLockCount > 0,說明鎖沒釋放完,有可重入加鎖,然后什么事都不干,直接回傳了,
-
如果newLockCount < 0,就拋例外,但是一般不會出現,
-
剩下的一種情況就是newLockCount == 0 ,說明鎖已經完完全全釋放完了,然后通過internals.releaseLock洗掉加鎖的節點,
服務端洗掉節點之后,就會通知監聽該節點的客戶端,然后客戶端就會回呼watcher監聽器,喚醒阻塞等待的執行緒,執行緒被喚醒后再進行一次判斷就能加鎖成功,
到這里,就講完了加鎖和釋放鎖的程序,整個加鎖和釋放鎖的程序就如下圖所示,
八、如何實作公平鎖
其實使用臨時順序節點實作的分布式鎖就是公平鎖,所謂的公平鎖就是加鎖的順序跟成功加鎖的順序是一樣的,
因為節點的順序就是被喚醒的順序,所以也就是加鎖的順序,所以天生就是公平鎖,
九、如何實作讀寫鎖
讀寫鎖使用如下,
創建節點的時候,節點的內容中會有一個標記來代表當前節點加的是什么型別的鎖,
當需要加寫鎖時,需要判斷自己創建的節點是否排在第一位,如果是就能加鎖成功,所以一旦前面有節點,不論前面加是讀鎖還是寫鎖,那么都是加鎖失敗,實作了讀寫互斥和寫寫互斥,當然寫鎖和讀鎖都是可以重入加鎖的,
當需要加讀鎖的時候,會去判斷自己創建節點的前面有沒有寫鎖,如果沒寫鎖,那么說明前面加的都是讀鎖,那么讀鎖就能加鎖成功,讀讀不互斥,如果前面有寫鎖,那么就加鎖失敗(自己加的寫鎖除外),讀寫互斥,
十、如何實作批量加鎖
批量加鎖的意思就是同時加幾個鎖,只有這些鎖都算加成功了,才是真正的加鎖成功,
Redisson也實作了批量加鎖的功能,Redisson的實作通過RedissonMultiLock類實作的,RedissonMultiLock會去遍歷需要加的鎖,然后每個都加成功之后才算加鎖成功,Curator是封裝了InterProcessMultiLock類來實作的批量加鎖的,那么InterProcessMultiLock如何實作的呢?
使用代碼如下,
InterProcessMultiLock的acquire的方法實作,
從這里可以看出,InterProcessMultiLock也是遍歷傳入的鎖,然后每個鎖都加鎖成功了,InterProcessMultiLock才算加鎖成功,
所以從這里可以看出,跟Redisson實作的批量加鎖的實作思想上基本是一樣的,都是遍歷加鎖,
十一、ZK分布式鎖和Redis分布式鎖到底該選誰
這是一個比較常見的面試題,
redis分布式鎖:
-
優點:性能高,能保證AP,保證其高可用,
-
缺點:正如Redisson的那篇文章所言,主要是如果出現主節點宕機,從節點還未來得及同步主節點的加鎖資訊,可能會導致重復加鎖,雖然Redis官網提供了RedLock演算法來解決這個問題,Redisson也實作了,但是RedLock演算法其實本身是有一定的爭議的,有大佬質疑該演算法的可靠性;同時因為需要的機器過多,也會浪費資源,所以RedLock也不推薦使用,
zk分布式鎖:
-
優點:zk本身其實就是CP的,能夠保證加鎖資料的一致性,每個節點的創建都會同時寫入leader和follwer節點,半數以上寫入成功才回傳,如果leader節點掛了之后選舉的流程會優先選舉zxid(事務Id)最大的節點,就是選資料最全的,又因為半數寫入的機制這樣就不會導致丟資料
-
缺點:性能沒有redis高
所以通過上面的對比可以看出,redis分布式鎖和zk分布式鎖的側重點是不同的,這是redis和zk本身的定位決定的,redis分布式鎖側重高性能,zk分布式鎖側重高可靠性,所以一般專案中redis分布式鎖和zk分布式鎖的選擇,是基于業務來決定的,如果你的業務需要保證加鎖的可靠性,不能出錯,那么zk分布式鎖就比較符合你的要求;如果你的業務對于加鎖的可靠性沒有那么高的要求,那么redis分布式鎖是個不錯的選擇,
最后,希望通過這兩篇文章,讓大家對于zookeeper分布式鎖和redis分布式鎖的實作有個更好的認識,如需要Redisson原始碼剖析的文章,請關注微信公眾號 三友的java日記,回復 Redisson 即可,
往期熱門文章推薦
-
有關回圈依賴和三級快取的這些問題,你都會么?(面試常問)
-
萬字+28張圖帶你探秘小而美的規則引擎框架LiteFlow
-
7000字+24張圖帶你徹底弄懂執行緒池
-
【SpringCloud原理】OpenFeign原來是這么基于Ribbon來實作負載均衡的
-
【SpringCloud原理】Ribbon核心組件以及運行原理原始碼剖析
-
【SpringCloud原理】OpenFeign之FeignClient動態代理生成原理
掃碼或者搜索關注公眾號 三友的java日記 ,及時干貨不錯過,公眾號致力于通過畫圖加上通俗易懂的語言講解技術,讓技術更加容易學習,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/491086.html
標籤:Java