面試的時候,總會遇到這么一個場景,
1. 場景分析
面試官:你們的服務的QPS是多少?
我:我們的服務高峰期訪問量還挺大的,大約是3萬吧,
面試官:這么大的訪問量,你們的服務器能撐住嗎?有加快取嗎?
我:有的,我們使用了Redis做快取,介面優先查詢快取,快取不存在,才訪問資料庫,這樣可以減少資料庫訪問壓力,加快查詢效率,
面試官:一份資料存盤在兩個地方,更新資料的時候,你們是怎么保證資料的一致性的?
看到了吧,好的面試官一般不直接問你資料一致性的解決方案,而是循循善誘,結合具體的使用場景,再問你解決方法,如果你沒做過這方面,沒有線上的實戰經驗,一般很難回答的有條理性、有思考性,
保證資料一致性,一般有這4種方法:
- 先更新快取,再更新資料庫,
- 先更新資料庫,再更新快取,
- 先洗掉快取,再更新資料庫,
- 先更新資料庫,再洗掉快取,
每種方案都詳細的討論一下:
2. 解決方案
2.1 先更新快取,再更新資料庫
如果同時來了兩個并發寫請求,執行程序是這樣的:
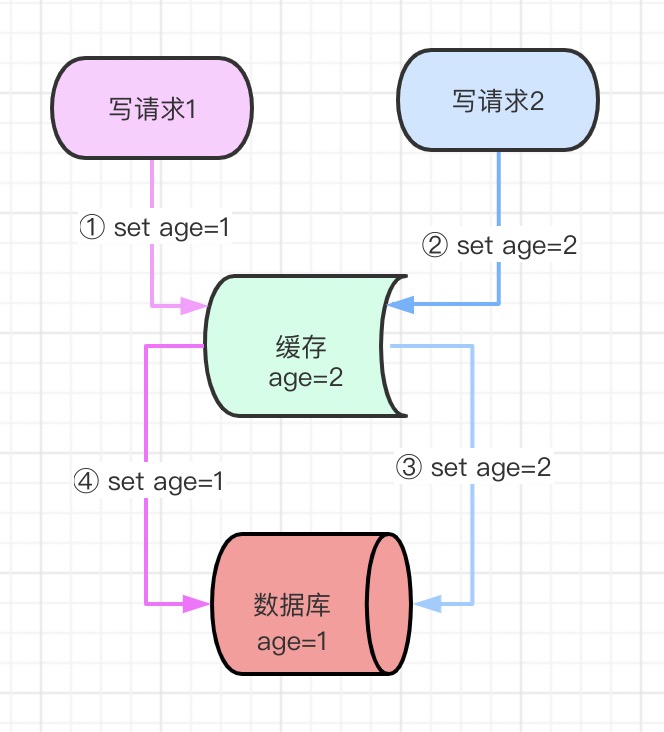
- 寫請求1更新快取,設定age為1
- 寫請求2更新快取,設定age為2
- 寫請求2更新資料庫,設定age為2
- 寫請求1更新資料庫,設定age為1
執行結果就是,快取里age被設定2,資料庫里的age被設定成1,導致資料不一致,此方案不可行,
2.2 先更新資料庫,再更新快取
如果同時來了兩個并發寫請求,執行程序是這樣的:
- 寫請求1更新資料庫,設定age為1
- 寫請求2更新資料庫,設定age為2
- 寫請求2更新快取,設定age為2
- 寫請求1更新快取,設定age為1
執行結果就是,資料庫里age被設定2,快取里的age被設定成1,導致資料不一致,此方案不可行,
2.3 先洗掉快取,再更新資料庫
如果同時來了兩個并發讀寫請求,執行程序是這樣的:
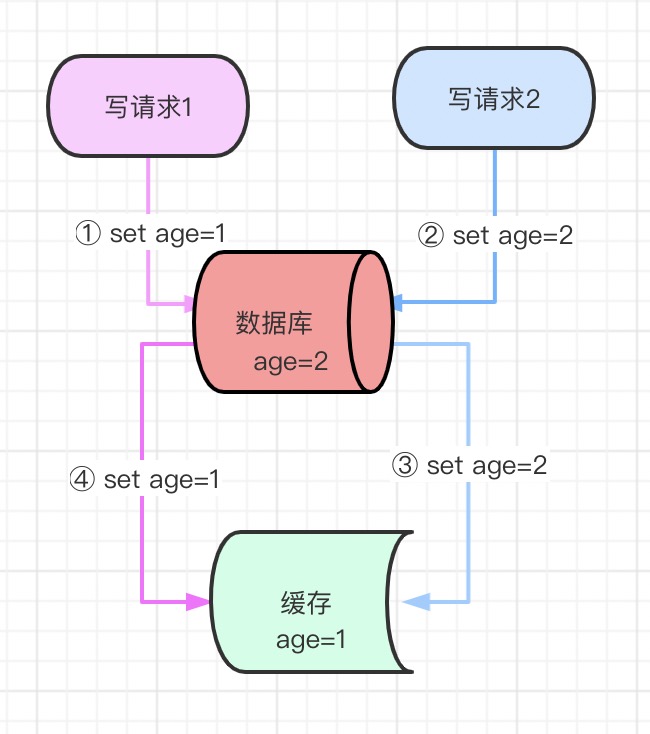
- 寫請求洗掉了快取
- 讀請求查詢快取沒資料,然后查詢資料庫,再把資料寫到快取中
- 寫請求更新資料庫
執行結果是,快取中是舊資料,而資料庫里是新資料,導致資料不一致,此方案不可行,
2.4 先更新資料庫,再洗掉快取
這種方案,在并發寫的時候,不會出問題,因為都是先更新資料庫再洗掉快取,不會出現不一致的情況,
但是在并發讀寫的時候,還是有可能出現資料不一致,
- 讀請求查詢快取沒資料,然后查詢資料庫
- 寫請求更新資料庫,洗掉快取
- 讀請求回寫快取
執行結果是,快取中是舊資料,而資料庫里是新資料,導致資料不一致,
其實這種情況出現的概率很低,寫快取比寫資料庫快出幾個量級,讀寫快取都是記憶體操作,速度非常快,
遇到了這種極端場景,我們也需要做一下兜底方案,快取都要設定過期時間,這種方案屬于資料的弱一致性和最終一致性,而不是強一致性,
3. 總結與思考
有讀者可能會好奇,為什么不在更新快取和資料庫方法上加上事務注解,實作強一致性,這么哪種方案都不會有問題,
是的,當我們的服務只在一臺機器上,加本地事務是可行的,但是作業中,我們會把一個服務部署到幾十臺、上百臺機器上,有時候為了應對更極端的查詢請求,又在Redis快取加一層本地快取,這時候我們再用本地事務是不起作用的,
一份資料在多臺機器上,存在多個副本,為了實作強一致性,我們也可以使用分布式事務,這樣一來更新快取操作將會變得非常復雜,得不償失,
但是在另外的一些場景,比如更新訂單狀態、更新用戶資產,這種場景,我們無論付出多大代價也要實作資料的強一致性,具體實作方案一般有以下幾種:
- 二階段提交
- TCC
- 本地訊息表
- MQ事務訊息
- 分布式事務中間件
下篇文章咱們再一起詳細的分析這幾種方案優缺點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/491317.html
標籤:Java
上一篇:【Java面試】Mybatis中#{}和${}的區別是什么?
下一篇:Eureka多節點資料不同步問題