一個作業8年的粉絲私信了我一個問題,
他說這個問題是去阿里面試的時候被問到的,自己查了很多資料也沒搞明白,希望我幫他解答,
問題是: “Mysql為什么使用B+Tree作為索引結構”
關于這個問題,看看普通人和高手的回答,
普通人:
B+數它的特征就是相對B數來說他的這個非葉子節點不存資料,所有的資料都存在葉子節點
相對于B數來說他的查詢次數IO次數會更穩,
高手:
關于這個問題 ,我從幾個方面來回答,
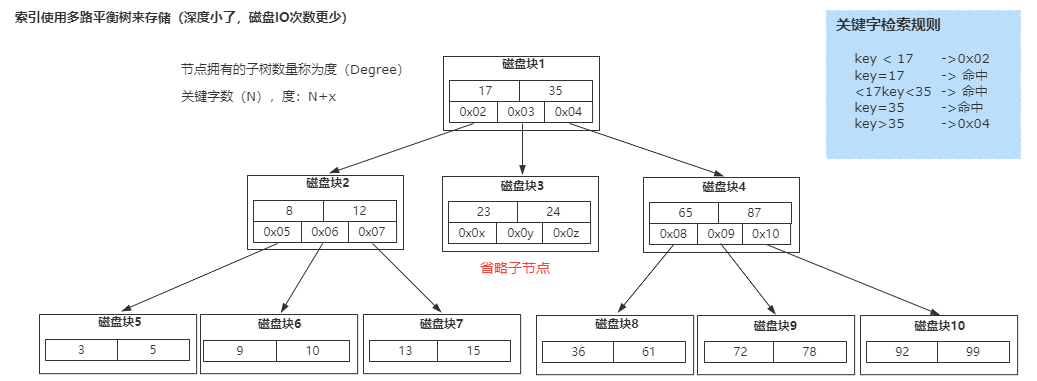
首先,常規的資料庫存盤引擎,一般都是采用B樹或者B+樹來實作索引的存盤,
因為B樹是一種多路平衡樹,用這種存盤結構來存盤大量資料,它的整個高度會相比二叉樹來說,會矮很多,
而對于資料庫來說,所有的資料必然都是存盤在磁盤上的,而磁盤IO的效率實際上是很低的,特別是在隨機磁盤IO的情況下效率更低,
所以樹的高度能夠決定磁盤IO的次數,磁盤IO次數越少,對于性能的提升就越大,這也是為什么采用B樹作為索引存盤結構的原因,
但是在Mysql的InnoDB存盤引擎里面,它用了一種增強的B樹結構,也就是B+樹來作為索引和資料的存盤結構,
相比較于B樹結構,B+樹做了幾個方面的優化,
- B+樹的所有資料都存盤在葉子節點,非葉子節點只存盤索引,
- 葉子節點中的資料使用雙向鏈表的方式進行關聯,
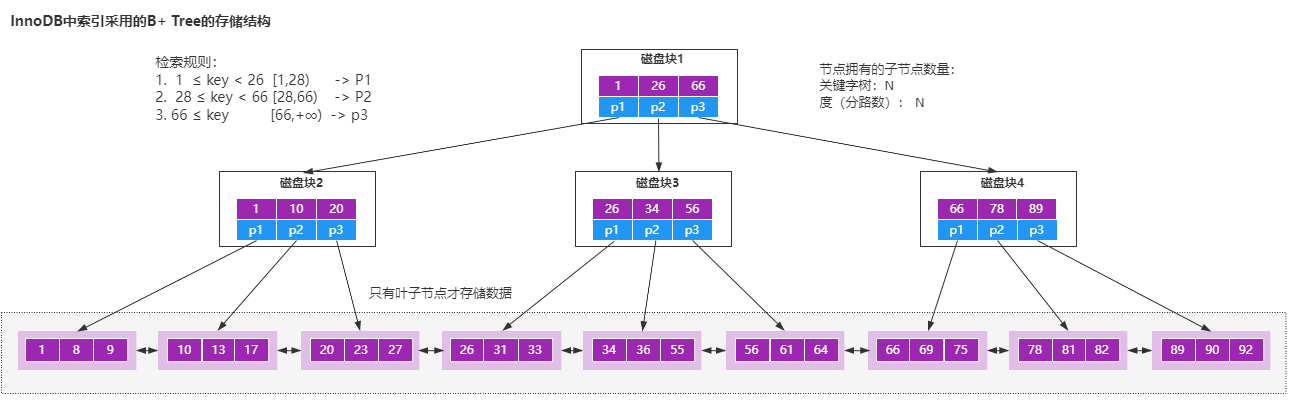
使用B+樹來實作索引的原因,我認為有幾個方面,
- B+樹非葉子節點不存盤資料,所以每一層能夠存盤的索引數量會增加,意味著B+樹在層高相同的情況下存盤的資料量要比B樹要多,使得磁盤IO次數更少,
- 在Mysql里面,范圍查詢是一個比較常用的操作,而B+樹的所有存盤在葉子節點的資料使用了雙向鏈表來關聯,所以在查詢的時候只需查兩個節點進行遍歷就行,而B樹需要獲取所有節點,所以B+樹在范圍查詢上效率更高,
- 在資料檢索方面,由于所有的資料都存盤在葉子節點,所以B+樹的IO次數會更加穩定一些,
- 因為葉子節點存盤所有資料,所以B+樹的全域掃描能力更強一些,因為它只需要掃描葉子節點,但是B樹需要遍歷整個樹,
另外,基于B+樹這樣一種結構,如果采用自增的整型資料作為主鍵,還能更好的避免增加資料的時候,帶來葉子節點分裂導致的大量運算的問題,
總的來說,我認為技術方案的選型,更多的是去解決當前場景下的特定問題,并不一定是說B+樹就是最好的選擇,就像MongoDB里面采用B樹結構,本質上來說,其實是關系型資料庫和非關系型資料庫的差異,
以上就是我對這個問題的理解,
總結
對于“為什么要選擇xx技術”的問題,其實很好回答,
只要你對這個技術本身的特性足夠了解,那么自然就知道為什么要這么設計,
就像,我們在業務開發中,知道什么時候使用List,什么時候使用Map,道理是一樣的,
如果有任何面試問題、職業發展問題、學習問題,都可以私信我,
著作權宣告:本博客所有文章除特別宣告外,均采用 CC BY-NC-SA 4.0 許可協議,轉載請注明來自
Mic帶你學架構!
如果本篇文章對您有幫助,還請幫忙點個關注和贊,您的堅持是我不斷創作的動力,歡迎關注「跟著Mic學架構」公眾號公眾號獲取更多技術干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/491429.html
標籤:Java