前言
相信現在有很多小伙伴都不會寫毛筆字了,今天想用python來寫一幅春聯,不知道有沒有人喜歡,該文用的是田英章老師的楷
書,我在網上總共找到了1600個漢字,因此,春聯用字被限制在這1600個漢字的小字庫中,我個人精力有限,同時受知識產權保
護的限制,不可能制作完整的毛筆字庫,那么,能否借用現有的矢量字庫,滿足朋友們的要求呢?經過一番嘗試,發現作業系統
自帶的某些矢量字庫,是可以作為毛筆字庫使用的,以下是簡單的演示代碼,僅供學習編程技術之用,絕無侵犯字體權利人之權
力的故意,特此宣告,
選擇矢量字庫
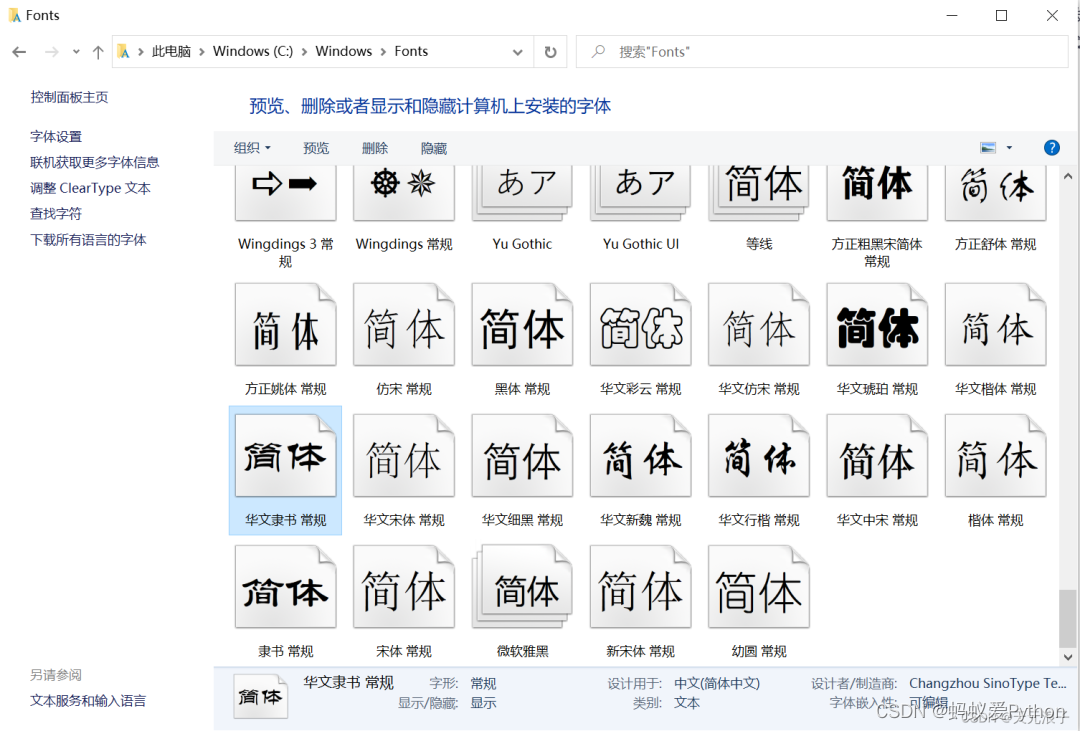
雖然有很多方法可以幫你呈現出系統支持的所有字體檔案,我建議最直接的方式是去查看作業系統的字體目錄,以Windows為例,我直接在C:\Windows\Fonts這個路徑下找到了“華文隸書”這個字庫檔案,查看屬性可知,該檔案名為STLITI.TTF,找到了喜歡的字庫檔案,只需要將其全路徑檔案名替換到代碼中的FONT_FILE常量即可,不需要做其他操作,
選擇一款喜歡的春聯背景圖案
還是以“龍鳳呈祥”這個圖案為例,如果換用其他的圖案,請確保圖案是.png格式(背景透明),且是方形的,同字體檔案一樣,我
們需要將這個背景圖案的全路徑檔案名替換到代碼中的BG_FILE常量即可,

完整代碼
全部代碼總共70余行,使用方法請看注釋,
python學習交流Q群:906715085#### # -*- coding: utf-8 -*- import os import freetype import numpy as np from PIL import Image FONT_FILE = r'C:\Windows\Fonts\STLITI.TTF' BG_FILE = r'D:\temp\bg.png' def text2image(word, font_file, size=128, color=(0,0,0)): """使用指定字庫將單個漢字轉為影像 word - 單個漢字字串 font_file - 矢量字庫檔案名 size - 字號,默認128 color - 顏色,默認黑色 """ face = freetype.Face(font_file) face.set_char_size(size*size) face.load_char(word) btm_obj = face.glyph.bitmap w, h = btm_obj.width, btm_obj.rows pixels = np.array(btm_obj.buffer, dtype=np.uint8).reshape(h, w) dx = int(face.glyph.metrics.horiBearingX/64) if dx > 0: patch = np.zeros((pixels.shape[0], dx), dtype=np.uint8) pixels = np.hstack((patch, pixels)) r = np.ones(pixels.shape) * color[0] * 255 g = np.ones(pixels.shape) * color[1] * 255 b = np.ones(pixels.shape) * color[2] * 255 im = np.dstack((r, g, b, pixels)).astype(np.uint8) return Image.fromarray(im) def write_couplets(text, horv='V', quality='L', out_file=None, bg=BG_FILE): """寫春聯 text - 春聯字串 bg - - 背景圖片路徑 horv - - H-橫排,V-豎排 quality - - 單字解析度,H-640像素,L-320像素 - out_file - 輸出檔案名 - """ - size, tsize = (320, 128) if quality == 'L' else (640, 180) - ow, oh = (size, size*len(text)) if horv == 'V' else (size*len(text), size) - im_out = Image.new('RGBA', (ow, oh), '#f0f0f0') - im_bg = Image.open(BG_FILE) if size < 640: - im_bg = im_bg.resize((size, size)) - for i, w in enumerate(text): - im_w = text2image(w, FONT_FILE, size=tsize, color=(0,0,0)) - w, h = im_w.size - dw, dh = (size - w)//2, (size - h)//2 - if horv == 'V': - im_out.paste(im_bg, (0, i*size)) - im_out.paste(im_w, (dw, i*size+dh), mask=im_w) - else: - im_out.paste(im_bg, (i*size, 0)) - im_out.paste(im_w, (i*size+dw, dh), mask=im_w) - im_out.save('%s.png'%text) os.startfile('%s.png'%text) if __name__ == '__main__': write_couplets('普天同慶', horv='V', quality='H') write_couplets('歡度春節', horv='V', quality='H') write_couplets('國泰民安', horv='H', quality='H')
樣例

最后,祝大家虎年大吉,虎虎生威,身體健康,事事順心,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/492248.html
標籤:Python