一個美女面試官坐到我的對面,發光logo的MacBook也擋不住她那圓潤可愛的臉龐,
程式媛本就稀有,美女面試官更是難尋,具體長什么樣呢?就像下面這樣:

這么溫柔可愛的面試官,應該不會為難我吧,嗯,應該是的,畢竟我這么帥氣,面試可能就是走個過場,美女面試官是不是單身?畢竟程式員都不善交流,因為我也是單身,難道我的姻緣就在此注定,孩子的名字我都想好了,一冰!好名字,
面試官: 小伙子,你低著頭笑什么吶,開始面試了,你知道訂單ID是怎么生成的嗎?
啥?訂單ID怎么生成?美女怎么不按套路出牌!HashMap實作原理,我已經倒背如流,你不問,瞎問什么訂單ID,
我: 還能咋生成?用資料庫主鍵自增唄,
面試官: 這樣不行啊,資料庫主鍵順序自增,每天有多少訂單量被競爭對手看的一清二楚,商業機密都暴露了,
況且單機MySQL只能支持幾百量級的并發,我們公司每天千萬訂單量,hold不住啊,
我: 嗯,那就用用資料庫集群,自增ID起始值按機器編號,步長等于機器數量,
比如有兩臺機器,第一臺機器生成的ID是1、3、5、7,第二臺機器生成的ID是2、4、6、8,性能不行就加機器,這并發量der一下就上去了,
面試官: 小伙子,你想得倒是挺好,你有沒有想過實作百萬級的并發,大概就需要2000臺機器,你這還只是用來生成訂單ID,公司再有錢也經不起這么造,
我: 既然MySQL的并發量不行,我們是不是可以提前從MySQL獲取一批自增ID,加載到本地記憶體中,然后從記憶體中并發取,這并發性能豈不是杠杠滴,
面試官: 你還挺上道,這種叫號段模式,并發量是上去了,但是自增ID還是不能作為訂單ID的,
我: 用Java自帶UUID怎么樣?
import java.util.UUID;
/**
* @author yideng
* @apiNote UUID示例
*/
public class UUIDTest {
public static void main(String[] args) {
String orderId = UUID.randomUUID().toString().replace("-", "");
System.out.println(orderId);
}
}
輸出結果:
58e93ecab9c64295b15f7f4661edcbc1
面試官: 也不行,32位字串會占用更大的空間,無序的字串作資料庫主鍵,每次插入資料庫的時候,MySQL為了維護B+樹結構,需要頻繁調整節點順序,影響性能,況且字串太長,也沒有任何業務含義,pass,
小伙子,你可能是沒參與過電商系統,我先跟說一下生成訂單ID要滿足哪些條件:
全域唯一:如果訂單ID重復了,肯定要完蛋,
高性能:要做到高并發、低延遲,生成訂單ID都成為瓶頸了,那還得了,
高可用:至少要做到4個9,別動不動就宕機了,
易用性:如果為了滿足上述要求,搞了幾百臺服務器,復雜且難以維護,也不行,
數值且有序遞增:數值占用的空間更小,有序遞增能保證插入MySQL的時候更高性能,
嵌入業務含義:如果訂單ID里面能嵌入業務含義,就能通過訂單ID知道是哪個業務線生成的,便于排查問題,
我擦,生成一個小小的訂單ID,搞出這么多規則,還能玩下去嗎?難道今天的面試要跪,怎么可能,一燈的文章我一直訂閱,這個還能難得住我,陪美女程式員玩玩還當真了,
我: 我聽說圈內有一種流傳已久的分布式、高性能、高可用的訂單ID生成演算法—雪花演算法,完全能滿足你的上述要求,雪花演算法生成ID是Long型別,長度64位,
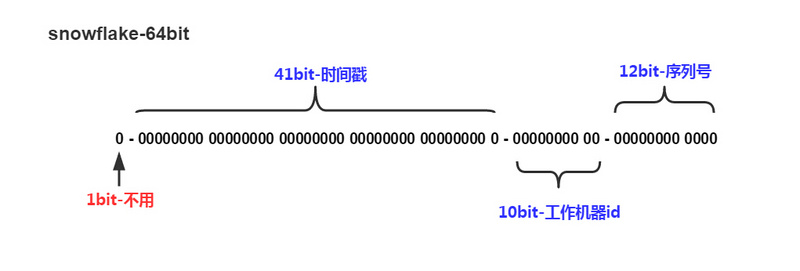
第 1 位: 符號位,暫時不用,
第 2~42 位: 共41位,時間戳,單位是毫秒,可以支撐大約69年
第 43~52 位: 共10位,機器ID,最多可容納1024臺機器
第 53~64 位: 共12位,序列號,是自增值,表示同一毫秒內產生的ID,單臺機器每毫秒最多可生成4096個訂單ID
代碼實作:
/**
* @author 一燈架構
* @apiNote 雪花演算法
**/
public class SnowFlake {
/**
* 起始時間戳,從2021-12-01開始生成
*/
private final static long START_STAMP = 1638288000000L;
/**
* 序列號占用的位數 12
*/
private final static long SEQUENCE_BIT = 12;
/**
* 機器標識占用的位數
*/
private final static long MACHINE_BIT = 10;
/**
* 機器數量最大值
*/
private final static long MAX_MACHINE_NUM = ~(-1L << MACHINE_BIT);
/**
* 序列號最大值
*/
private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long TIMESTAMP_LEFT = SEQUENCE_BIT + MACHINE_BIT;
/**
* 機器標識
*/
private long machineId;
/**
* 序列號
*/
private long sequence = 0L;
/**
* 上一次時間戳
*/
private long lastStamp = -1L;
/**
* 構造方法
* @param machineId 機器ID
*/
public SnowFlake(long machineId) {
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new RuntimeException("機器超過最大數量");
}
this.machineId = machineId;
}
/**
* 產生下一個ID
*/
public synchronized long nextId() {
long currStamp = getNewStamp();
if (currStamp < lastStamp) {
throw new RuntimeException("時鐘后移,拒絕生成ID!");
}
if (currStamp == lastStamp) {
// 相同毫秒內,序列號自增
sequence = (sequence + 1) & MAX_SEQUENCE;
// 同一毫秒的序列數已經達到最大
if (sequence == 0L) {
currStamp = getNextMill();
}
} else {
// 不同毫秒內,序列號置為0
sequence = 0L;
}
lastStamp = currStamp;
return (currStamp - START_STAMP) << TIMESTAMP_LEFT // 時間戳部分
| machineId << MACHINE_LEFT // 機器標識部分
| sequence; // 序列號部分
}
private long getNextMill() {
long mill = getNewStamp();
while (mill <= lastStamp) {
mill = getNewStamp();
}
return mill;
}
private long getNewStamp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
// 訂單ID生成測驗,機器ID指定第0臺
SnowFlake snowFlake = new SnowFlake(0);
System.out.println(snowFlake.nextId());
}
}
輸出結果:
6836348333850624
接入非常簡單,不需要搭建服務集群,,代碼邏輯非常簡單,,同一毫秒內,訂單ID的序列號自增,同步鎖只作用于本機,機器之間互不影響,每毫秒可以生成四百萬個訂單ID,非常強悍,
生成規則不是固定的,可以根據自身的業務需求調整,如果你不需要那么大的并發量,可以把機器標識位拆出一部分,當作業務標識位,標識是哪個業務線生成的訂單ID,
面試官: 小伙子,有點東西,深藏不漏啊,再問個更難的問題,你覺得雪花演算法還有改進的空間嗎?
你真是打破砂鍋問到底,不把我問趴下不結束,幸虧來之前我瞥了一眼一燈的文章,
我: 有的,雪花演算法嚴重依賴系統時鐘,如果時鐘回撥,就會生成重復ID,
面試官: 有什么解決辦法嗎?
我: 有問題就會有答案,比如美團的Leaf(美團自研一種分布式ID生成系統),為了解決時鐘回撥,引入了zookeeper,原理也很簡單,就是比較當前系統時間跟生成節點的時間,
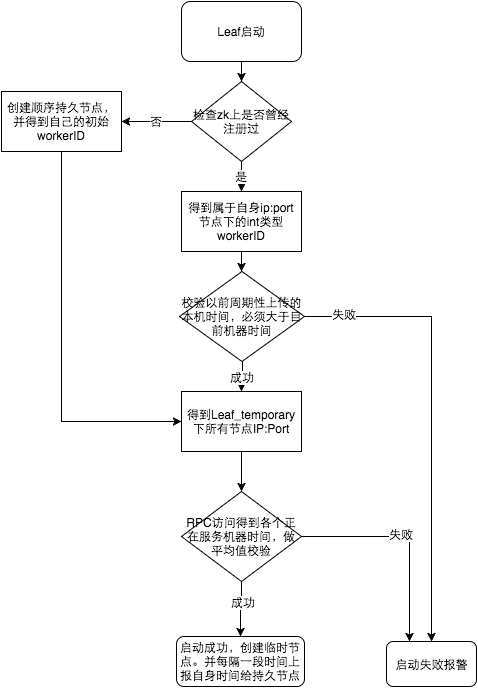
有的對并發要求更高的系統,比如雙十一秒殺,每毫秒4百萬并發還不能滿足要求,就可以使用雪花演算法和號段模式相結合,比如百度的UidGenerator、滴滴的TinyId,想想也是,號段模式的預先生成ID肯定是高性能分布式訂單ID的最終解決方案,
面試官: 小伙子,我看你簡歷上寫著已經離職了,明天就來上班吧,薪資double,就這樣了,
文章持續更新,可以微信搜一搜「 一燈架構 」第一時間閱讀更多技術干貨,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/494279.html
標籤:其他