我想讀取一個 Excel 檔案,對來自同一區域(區域 B)的位置的 2021、2020 和 2019 年的值求和,然后創建一個包含兩條線的圖形(對于區域 A 和 B),它將顯示如何多年來,這兩個地區的價值都發生了變化。
我試過這段代碼:
import numpy
import pandas as pd
import matplotlib.pyplot as plt
excel_file_path = "Testfile.xlsx"
df = pd.read_excel(excel_file_path)
df_region = df.groupby(['Region']).sum()
x = ["2021", "2020", "2019"]
y1 = df_region["Values2021"]
y2 = df_region["Values2020"]
y3 = df_region["Values2019"]
fig = plt.figure(figsize=(20,5))
plt.plot(x, y1, color = 'red', label = "A")
plt.plot(x, y2, color = 'blue', label = "B")
plt.legend(loc='best')
plt.show()
但這對我不起作用-我收到以下錯誤:
“發生例外:ValueError x 和 y 必須具有相同的第一維,但具有形狀 (3,) 和 (2,)”
這是我的 Excel 檔案:
Location Region Values2021 Values2020 Values2019
Location1 A 720,00 680,00 554,00
Location2 B 340,00 360,00 389,00
Location3 B 320,00 230,00 287,00
我需要做什么才能得到我想要的結果?任何幫助將不勝感激。
uj5u.com熱心網友回復:
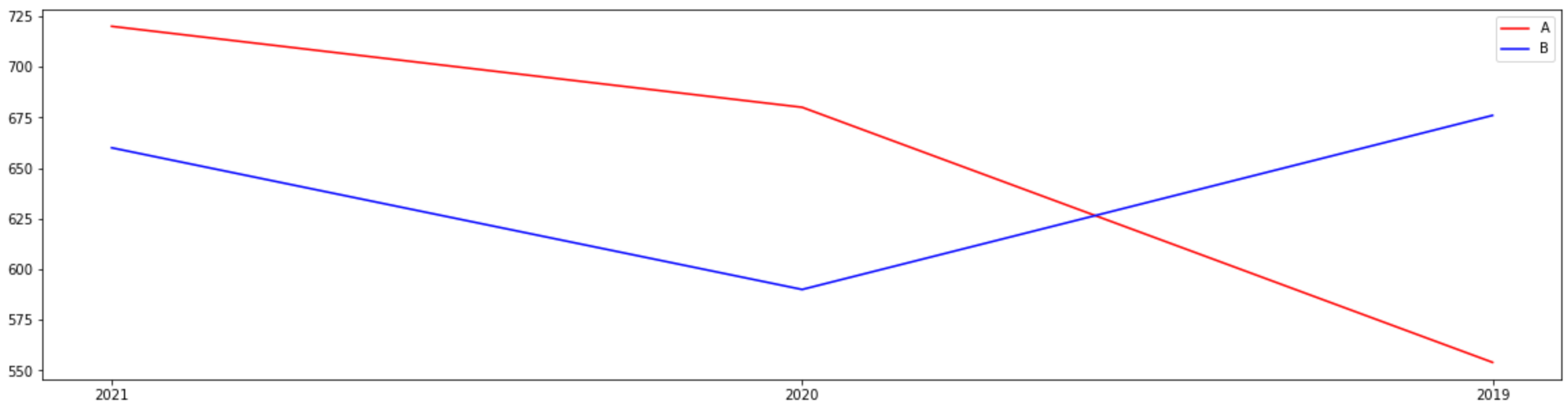
我認為你的意思是定義你的y1和y2有點不同。
x = ["2021", "2020", "2019"]
fig = plt.figure(figsize=(20,5))
colors = ['red', 'blue']
for i, region in enumerate(df_region.index):
y = df_region.loc[region, :]
plt.plot(x, y, color = colors[i], label = region)
plt.legend(loc='best')
plt.show()
它繪制并從 DataFrame 中讀取區域名稱。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/495123.html
標籤:Python 擅长 熊猫 matplotlib
上一篇:如何保存FITS檔案的jpeg?
下一篇:向分組條形圖添加線