一、字串
1、字串編碼發展:
1)ASCII碼: 一個位元組去表示
(8個位元(bit)作為一個位元組(byte),因此,一個位元組能表示的最大的整數就是255(二進制11111111 = 十進制255))
2)Unicode:兩個位元組表示(將各國的語言(中文編到GB2312,日文編到Shift_JIS,韓文編到Eur-kr......) 統一到一個編碼里)
3) UTF-8:為了節省空間,可變長編碼應運而生;(英文1個位元組;中文3個位元組)
----Python3默認使用的是utf-8編碼方式
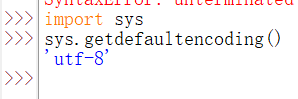
2、網路傳輸使用的編碼解碼方式:
encode()--使用指定編碼方式將字串編碼為bytes(位元組),便于網路傳輸;(編碼)
decode()--從網路或磁盤上讀取位元組流【讀到的資料(data)就是bytes】,再轉換為字串(解碼)
3、字串常用方法:
1)len(str):回傳字符個數或位元組個數
len('Hellow world!')

2) chr(整數編碼):回傳Unicode編碼x對應的字符(即ASCII碼值)(x可以是10進制, 也可以是16進制的形式的數字)

3)ord(字符):回傳單個字符表示的Unicode編碼;(與chr()函式相對應)

列印十二星座:

4) find(str, beg=0, end=len(string))---檢測字串中是否包含子字串str,回傳索引值;
----------------若在索引范圍內找不到子字串,則回傳-1
引數:str:指定檢索的字串;
beg:指定字串索引的起始位置;
end:指定字串索引的結束位置;

5)index(str, beg=0, end=len(string))-- 與find()函式差不多;
區別-----若在索引范圍內找不到子字串,則回傳例外值;

6)in/not in 判斷一個字串是否包含另一個字串中

7)upper() 將原字符的所有字母轉換為大寫
lower() 將原字符的所有字母轉換為小寫

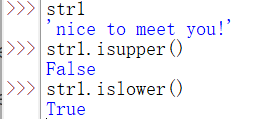
8)isupper() 所有字母都是大寫 ,回傳布林值True,否則,回傳False
islower() 所有字母都是小寫 ,回傳布林值True,否則,回傳False
4、 格式化輸出:
1)基本格式:<字串>.format(<逗號分隔的引數>)

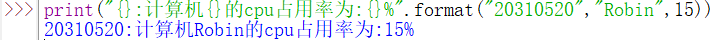
2)格式控制:
- 填充、對齊、寬度一般搭配使用
s = "python"
print("格式化:{0:10}".format(s)) #默認使用空格填充,默認左對齊,寬度為10
print("格式化:{0:*>10}".format(s)) #填充字符為*,右對齊,寬度為10
print("格式化:{0:*<10}".format(s)) #填充字符為*,左對齊,寬度為10
print("格式化:{0:-^20}".format(s)) #填充字符為-,居中對齊,寬度為20

5、字串拼接
1)str1+str2
2) str1str2
3) str1*3

6、索引和切片:
1)索引:獲取某一個字符s[下標];
從左往右數:0
從右往左數:-1
2)切片:獲取片段 name[起始,結束,步長];
獲取順序:步長>0,從左往右;
步長<0,從右往左

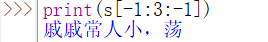
2022-07-15
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/499415.html
標籤:Python