一、需求
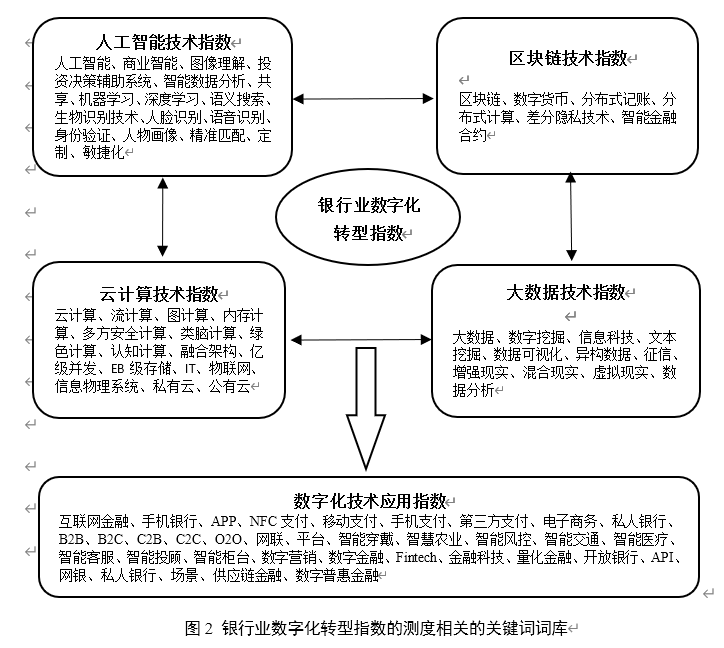
相關研究表明,銀行等企業的數字化轉型相關特征資訊更容易體現在具有總結和指導性質的年度報表中(吳非,2021),因此,通過統計銀行年報中涉及“數字化轉型”的詞頻來刻畫其轉型程度,具有可行性和科學性,具體而言,本文借助Python 爬蟲功能對中國40家上市銀行年度報表進行爬取,并采用Jieba分詞模塊對銀行“數字化轉型”相關的關鍵詞進行分詞與統計,使用Jieba的優勢在于其能夠精準地對中文文本進行識別與分詞,同時支持用戶自定義詞典,可以有效提高分詞的準確性,在詞庫方面,本文借鑒吳非(2021)的研究,將銀行數字化轉型細分為“底層技術”與“實踐應用”兩類,不僅包括了數字化轉型的四種典型底層技術,即“ABCD”技術;同時也包含了這類技術在具體實踐中的運用表現,此外,本文在已有研究的基礎上對關鍵詞詞庫進行有效補充,在此基礎上,根據詞庫對上市銀行年度報表進行匹配與詞頻匯總,同時剔除關鍵詞前存在否定表達的詞頻后進行對數化得到銀行業數字化轉型指數,本文構建的與銀行業數字化相關的關鍵詞詞庫如圖2所示:
二、程序
1、檔案PDF轉換
需要用到的庫:
pip install pdfminer對pdfminer的簡單介紹,官網翻譯成中文的介紹如下:
PDFMiner是一個從PDF檔案中提取資訊的工具,與其他pdf相關的
工具不同,它完全專注于獲取和分析文本資料,PDFMiner允許獲取
頁面中文本的確切位置,以及其他資訊,比如字體或行,它包括一
個PDF轉換器,可以將PDF檔案轉換成其他文本格式(如HTML),
它有一個可擴展的PDF決議器,可以用于其他目的而不是文本分析,
由于PDF檔案有如此大和復雜的結構,完整決議PDF檔案很費時費力,然而在大多數PDF作業中,很多模塊是不需要加進來的,因此 PDFMiner 采用了一個懶惰分析的策略,就是只分析所需要的部分,決議時候,至少需要2個核心類,PDFParser 和 PDFDocument,這兩個模塊配合其他模塊來使用,
PDFParser 從檔案中獲取資料
PDFDocument 存盤檔案資料結構到記憶體中
PDFPageInterpreter 決議page內容
PDFDevice 把決議到的內容轉化為你需要的東西
PDFResourceManager存盤共享資源,例如字體或圖片
源代碼如下:
import pyocr
import importlib
import sys
import time
importlib.reload(sys)
time1 = time.time()
# print("初始時間為:",time1)
import os.path
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
text_paths = r'興業銀行2021 年 年 度 報 告'
def parse():
'''決議PDF文本,并保存到TXT檔案中'''
print("------開始轉換------")
text_path = f'銀行\\興業銀行\\{text_paths}.pdf'
text_path2 = f'銀行\\興業銀行\\TXT\\{text_paths}'
fp = open(text_path, 'rb')
# 用檔案物件創建一個PDF檔案分析器
parser = PDFParser(fp)
# 創建一個PDF檔案
doc = PDFDocument()
# 連接分析器,與檔案物件
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密碼,如果沒有密碼,就創建一個空的字串
doc.initialize()
# 檢測檔案是否提供txt轉換,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 創建PDF,資源管理器,來共享資源
rsrcmgr = PDFResourceManager()
# 創建一個PDF設備物件
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 創建一個PDF解釋其物件
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 回圈遍歷串列,每次處理一個page內容
# doc.get_pages() 獲取page串列
for page in doc.get_pages():
interpreter.process_page(page)
# 接受該頁面的LTPage物件
layout = device.get_result()
# 這里layout是一個LTPage物件 里面存放著 這個page決議出的各種物件
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要獲取文本就獲得物件的text屬性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(f'{text_path2}.txt', 'a',encoding='utf-8') as f:
results = x.get_text()
print(results)
f.write(results + "\n")
f.close()
print("------轉換完成------")
if __name__ == '__main__':
parse()
time2 = time.time()
print("總共消耗時間為:", time2 - time1)2、詞庫分詞統計
Jieba "結巴"中文分詞:做最好的Python中文分詞組件 "Jieba"
支持三種分詞模式:
- 精確模式,試圖將句子最精確地切開,適合文本分析;
- 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
- 搜索引擎模式,在精確模式的基礎上,對長詞再次切分,提高召回率,適合用于搜索引擎分詞,
- 支持繁體分詞
- 支持自定義詞典
這里我使用Jieba對轉換好的txt檔案讀取分詞,在此基礎上,根據詞庫對上市銀行年度報表進行匹配與詞頻匯總,同時剔除關鍵詞前存在否定表達的詞頻后進行對數化得到銀行業數字化轉型指數,
源代碼如下:
# 匯入依賴
import jieba
import numpy as np
text_paths = r'興業銀行2021 年 年 度 報 告'
# text_path = f'銀行\\興業銀行\\{text_paths}.pdf'
text_path2 = f'銀行\\興業銀行\\TXT\\{text_paths}'
def fun():
# 讀取文本
txt = open(f"{text_path2}.txt", "r", encoding='utf-8').read()
# 使用精確模式對文本進行分詞
words = jieba.lcut(txt)
# 通過鍵值對的形式存盤詞語及其出現的次數
counts = {}
for word in words:
# 去掉詞語中的空格
word = word.replace(' ', '')
# 如果詞語長度為1,則忽略統計
if len(word) == 1:
continue
# 進行累計
else:
counts[word] = counts.get(word, 0) + 1
# # 將字典轉為串列
# items = list(counts.items())
# # 根據詞語出現的次數進行從大到小排序
# items.sort(key=lambda x: x[1], reverse=True)
# 查找指數詞(自定義詞庫)
cKu = ["人工智能","網聯","平臺","智能穿戴","智慧農業","智能風控","智能交通","智能醫療","智能客服","智能投顧","智能柜臺","數字營銷","數字金融","Fintech","金融科技","量化金融","開放銀行","API","網銀","私人銀行","場景","供應鏈金融","數字貧訓金融","互聯網金融","手機銀行","APP","NFC支付","移動支付","手機支付","第三方支付","電子商務","私人銀行","B2B","B2C","C2B","C2C","O2O","大資料","數字挖掘","資訊科技","文本挖掘","資料可視化","異構資料","征信","增強現實","混合現實","虛擬現實","資料分析","IT","物聯網","資訊物理系統","私有云","公有云","云計算","流計算","圖計算","記憶體計算","多方安全計算","類腦計算","綠色計算","認知計算","融合架構","億級并發","EB級存盤","區塊鏈","數字貨幣","分布式記賬","分布式計算","差分隱私技術","智能金融合約","商業智能","影像理解","投資決策輔助系統","智能資料分析","共享","機器學習","語意搜索","生物識別技術","人臉識別","語音識別","身份驗證","人物畫像","精準匹配","定制","敏捷化"]
nums = 0
for wd in cKu:
for word,val in counts.items():
# print(f"{word} = {val}")
if wd == word:
nums += val
print(f"詞頻數: {nums}")
print("取對數后: {:.4f}".format(np.log(nums)))
# 結尾保留了4位小數
# 主函式
if __name__ == '__main__':
fun()三、終制版代碼
要實作需求就需要對上述兩種操作分別先后進行,比較不便,為了更加方便大量統計、計算并使用,將上述兩模塊結合在一起,就是終制版
源代碼如下:
import pyocr
import importlib
import sys
import time
import jieba
import numpy as np
importlib.reload(sys)
time1 = time.time()
# print("初始時間為:",time1)
import os.path
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LTTextBoxHorizontal, LAParams
from pdfminer.pdfinterp import PDFTextExtractionNotAllowed
text_paths = r'南京2020 年年度報告'
text_path = f'銀行\\南京銀行\\{text_paths}.pdf'
text_path2 = f'銀行\\南京銀行\\TXT\\{text_paths}'
def parse():
'''決議PDF文本,并保存到TXT檔案中'''
print("------開始轉換------")
fp = open(text_path, 'rb')
# 用檔案物件創建一個PDF檔案分析器
parser = PDFParser(fp)
# 創建一個PDF檔案
doc = PDFDocument()
# 連接分析器,與檔案物件
parser.set_document(doc)
doc.set_parser(parser)
# 提供初始化密碼,如果沒有密碼,就創建一個空的字串
doc.initialize()
# 檢測檔案是否提供txt轉換,不提供就忽略
if not doc.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 創建PDF,資源管理器,來共享資源
rsrcmgr = PDFResourceManager()
# 創建一個PDF設備物件
laparams = LAParams()
device = PDFPageAggregator(rsrcmgr, laparams=laparams)
# 創建一個PDF解釋其物件
interpreter = PDFPageInterpreter(rsrcmgr, device)
# 回圈遍歷串列,每次處理一個page內容
# doc.get_pages() 獲取page串列
for page in doc.get_pages():
interpreter.process_page(page)
# 接受該頁面的LTPage物件
layout = device.get_result()
# 這里layout是一個LTPage物件 里面存放著 這個page決議出的各種物件
# 一般包括LTTextBox, LTFigure, LTImage, LTTextBoxHorizontal 等等
# 想要獲取文本就獲得物件的text屬性,
for x in layout:
if (isinstance(x, LTTextBoxHorizontal)):
with open(f'{text_path2}.txt', 'a',encoding='utf-8') as f:
results = x.get_text()
print(results)
f.write(results + "\n")
f.close()
print("------轉換完成------")
# ------------------二---------------
def fun():
# 讀取文本
txt = open(f"{text_path2}.txt", "r", encoding='utf-8').read()
# 使用精確模式對文本進行分詞
words = jieba.lcut(txt)
# 通過鍵值對的形式存盤詞語及其出現的次數
counts = {}
for word in words:
# 去掉詞語中的空格
word = word.replace(' ', '')
# 如果詞語長度為1,則忽略統計
if len(word) == 1:
continue
# 進行累計
else:
counts[word] = counts.get(word, 0) + 1
# # 將字典轉為串列
# items = list(counts.items())
# # 根據詞語出現的次數進行從大到小排序
# items.sort(key=lambda x: x[1], reverse=True)
# 查找指數詞(自定義詞庫)
cKu = ["人工智能","網聯","平臺","智能穿戴","智慧農業","智能風控","智能交通","智能醫療","智能客服","智能投顧","智能柜臺","數字營銷","數字金融","Fintech","金融科技","量化金融","開放銀行","API","網銀","私人銀行","場景","供應鏈金融","數字貧訓金融","互聯網金融","手機銀行","APP","NFC支付","移動支付","手機支付","第三方支付","電子商務","私人銀行","B2B","B2C","C2B","C2C","O2O","大資料","數字挖掘","資訊科技","文本挖掘","資料可視化","異構資料","征信","增強現實","混合現實","虛擬現實","資料分析","IT","物聯網","資訊物理系統","私有云","公有云","云計算","流計算","圖計算","記憶體計算","多方安全計算","類腦計算","綠色計算","認知計算","融合架構","億級并發","EB級存盤","區塊鏈","數字貨幣","分布式記賬","分布式計算","差分隱私技術","智能金融合約","商業智能","影像理解","投資決策輔助系統","智能資料分析","共享","機器學習","語意搜索","生物識別技術","人臉識別","語音識別","身份驗證","人物畫像","精準匹配","定制","敏捷化"]
nums = 0
for wd in cKu:
for word,val in counts.items():
# print(f"{word} = {val}")
if wd == word:
nums += val
print(f"詞頻數: {nums}")
print("取對數后: {:.4f}".format(np.log(nums)))
if __name__ == '__main__':
parse()
time2 = time.time()
print("總共消耗時間為:", time2 - time1)
fun()當然,在讀取操作目標名字方法main仍有諸多不便,因此可以加上讀取檔案夾下所有檔案名,再使用串列將其回圈遍歷操作便可解決這個問題,后續有時間可以再寫一寫
讀取指定路徑下所有檔案:
import os
filePath = 'D:\\pythonProject\\資料分析\\銀行\\興業銀行'
# 檔案路徑
fileNames = os.listdir(filePath)
# 獲取的路徑下檔案名稱串列形式存到fileNames
print(fileNames)
# 列印
print('---------')
for name in fileNames:
print(name)以上
Love for Ever Day轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/499624.html
標籤:Python
上一篇:python移除串列中的重復元素