前言
演算法是什么?演算法就是數學規律.怎么去總結和發現這個規律,就是理解演算法的程序.
KMP演算法的本質是窮舉法,而并不是去創造新的匹配邏輯.
以下將搜尋的字串稱為子串(part),以P表示.被搜尋的字串稱為總串(total),以T表示.
start代表P串在T串中開始匹配的位置,end代表P串與T串對比字符時的位置
String total = "ababcd";
String part = "abc";
total.contains(part);
部分匹配表
部分匹配表是KMP演算法的核心,只要理解了部分匹配表,就基本理解了KMP演算法,
普通匹配模式
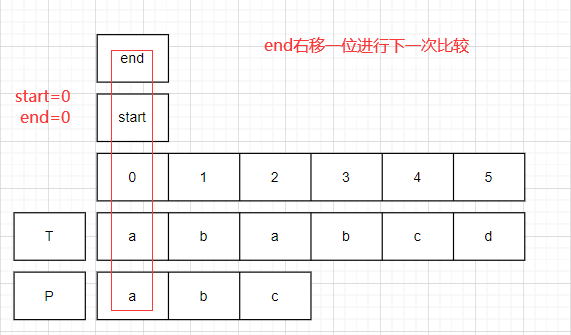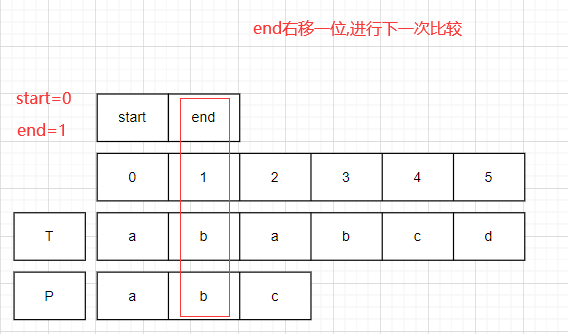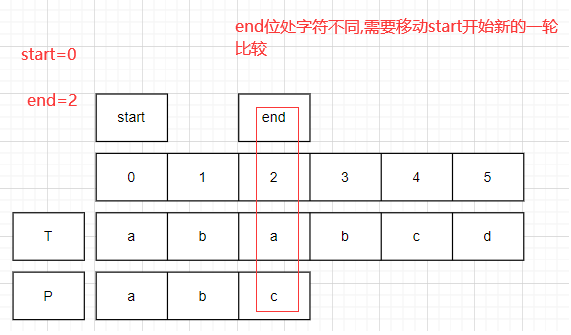
對比開始.
start=0,end=0;比較T.charAt(0)==P.charAt(0).均為a,此時end右移一位.
start=0,end=1;比較T.charAt(1)==P.charAt(1).均為b,此時end右移一位.
start=0,end=2;比較T.charAt(2)!=P.charAt(2).此時,start右移一位.
start=1,end=0;比較T.charAt(start+end)!=P.charAt(end).此時,start右移一位.
start=2,end=0;比較T.charAt(start+end)==P.charAt(end).此時,此時end右移一位.以此類推.
最終發現T.contains(P)為true,T.indexOf(P)為start,即為2.
public static int getIndex(String total, String part) {
char[] totalChars = total.toCharArray();
char[] partChars = part.toCharArray();
int start = 0;
int end = 0;
while (start < total.length()) {
if (totalChars[start + end] == partChars[end]) {
end++;
} else {
start = start + 1;
end = 0;
}
if (end == part.length()) {
return start;
}
}
return -1;
}
尋找規律
規律是什么?就是在匹配程序中,遇到某一位不匹配時.start與end下一次的起點位置選擇.
對于普通匹配而言,start的變化永遠是右移一位,end永遠是從0開始,并且每次右移一位.
這里先介紹兩個規律,當發現end位不匹配時
第一條規律,,新起點位置只與重合部分有關
T.charAt(start+end)!=P.charAt(end)
T.substring(start,start+end)==P.substring(0,end)
因為它不相等,所以它相等,這句話前后順序不能顛倒.這雖然很像廢話,但是確實KMP演算法的核心.

第二條規律,未知無法跳過
這次的end位一定是下次比較的起點
這里有個特殊的地方,就是首位不同時的邏輯,代碼中也是一樣,先按下不表.
部分匹配表
有個比較關鍵的地方,確定start與end新起點的規則是什么?
新的起點是什么,是可能性,是T串的某一段與P串完全相同的可能性.
只有end=0時相同,才會有end=1時的比較
只有end=1時相同,才會有end=2時的比較
...
那么至少,T.charAt(start)==P.charAt(0),才可以進行后面的比較
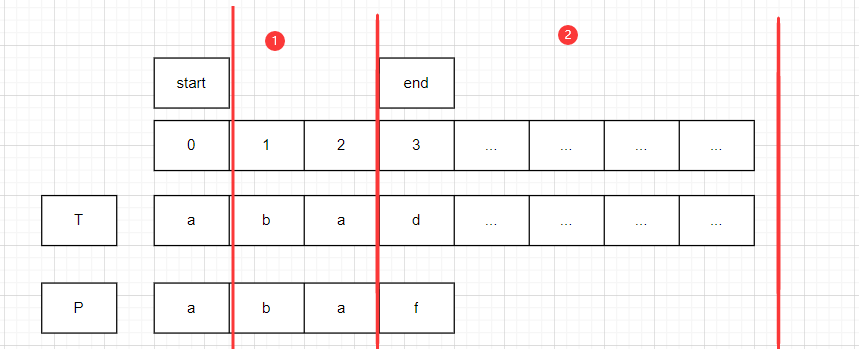
當遇到end位不匹配時,我們將start可能移動的軌跡分為兩部分
① (start,start+end)
② [start+end,...]
T.indexOf(P)的位置只可能出現在這兩個區域(因為之前的位置都被排除了).這兩個區域的差別是什么呢?
結合上面兩條規律,途經區域①的比較的字符物件是完全已知的,而區域②則不是.
即下一次start的起點在 (start,start+end] 中
因為即要么在(start,start+end)中,要么就是end,因為end是未知的,必須要用首位去對比,所以start最遠會位移到end位
由于第一條規律,T.substring(start,start+end)==P.substring(0,end)
那么start在T.substring(start,start+end)中位移的程序就是start在P.substring(0,end)中位移的程序
去尋找start在(start,start+end)中作為新起點的可能性,就是尋P.substring(0,end)這個字串本身與其子串的重合度,什么是重合度?
兩個相同的字串,一個不動,一個整體向右移動一格,查看兩者相交部分,如果相交部分完全相等,那么相交字串的首位,就是新的起點,這個相交部分的長度就是重合度.
假設 P = abcde
| 不匹配時end位置 | P.substring(0,end) | 重合度 |
|---|---|---|
| 0 | "" | 0 |
| 1 | a | 0 |
| 2 | ab | 0 |
| 3 | abc | 0 |
| 4 | abcd | 0 |
獲取重合度
public static int getPublicPart(String part) {
int start = 1;
int end = 0;
char[] chars = part.toCharArray();
while (start < part.length()) {
if (chars[start + end] == chars[end]) {
if (end + start == part.length() - 1) {
return part.substring(start).length();
}
end++;
} else {
start++;
end = 0;
}
}
return 0;
}
我們將start移動軌跡的研究,變成了P.substring(0,end)的研究,那么假設T串很長,那么end值可能會出現在任意一個地方,并且相同情況會有多次,所以我們只要事先將所有可能的情況列出,以后遇到相同情況就可以直接套用結果.
為什么可以復用呢?因為P.charAt(end)我們一定知道什么,但是T.charAt(start+end)卻有很多種可能,因為它只需要與P.charAt(end)不相等
假設 P = aaaab
| 不匹配時end位置 | P.substring(0,end) | 重合度 | 下一次start位置 | 下一次end位置 |
|---|---|---|---|---|
| 4 | aaaa | 3 | start+4-3 | 3 |
| 3 | aaa | 2 | start+3-2 | 2 |
| 2 | aa | 1 | start+2-1 | 1 |
| 1 | a | 0 | start+1-0 | 0 |
| 0 | "" | 0 | start+0-(-1) | 0 |
我們可以發現,start下一次的位置為 start +( end - P.substring(0,end)的重合度). (end - 重合度) 其實就是start需要位移的距離
end下一次的位置為 P.substring(0,end)的重合度
但是由于P.substring(0,0)為空字串,比較特殊,首位不同時,start是直接右移一位
故令next[0] = -1 , 當 next[end] < 0時,下一次的end位置指向 0
獲取next陣列
public static int[] getNext(String part) {
int[] next = new int[part.length()];
int start = 1;
while (start < part.length()) {
next[start] = getPublicPart(part.substring(0, start));
start++;
}
next[0] = -1;
return next;
}
我們將end位不同時,P.substring(0,end)它的子串與自身的重合度,稱之為部分匹配表
Tips:
這里有一個很關鍵的地方,start可以直接從0移動到2嗎?不可以,因為KMP無法違背普通匹配,或者說違背匹配的規律,只有start每次右移一位,即P.charAt(0)與T串的每一位開始比較,才能確認這個位置含不含有可能性,而我們next陣列的獲取就是通過每次右移一位獲取到的.
完整代碼
KMP演算法的本質就是通過窮舉end位不匹配時start與end的移動軌跡,來達到復用的效果.
public static int indexOf(String total, String part) {
char[] totalChars = total.toCharArray();
char[] partChars = part.toCharArray();
int[] next = getNext(part);
int start = 0;
int end = 0;
while (start < total.length()) {
if (totalChars[start + end] == partChars[end]) {
end++;
} else {
// 與普通匹配不同的其實就是end位不同時,下一次start與end的位置選擇
start = start + end - next[end];
end = Math.max(0, next[end]);
}
if (end == part.length()) {
return start;
}
}
return -1;
}
小小的一篇文章,寫了快一個月,每天晚上將思想轉化為文字時,總會有新的理解,修修改改了這么長時間,總覺得文字不夠干練.人生亦是如此.
本文來自博客園,作者:貍子橘花茶,轉載請注明原文鏈接:https://www.cnblogs.com/yusishi/p/16403675.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/499758.html
標籤:其他
上一篇:如何使用java代碼將一個set集合中的元素轉換為一個“逗號分隔的字串”呢
下一篇:java中==和equals區別