一. 圖的概念
??1.定義
??某類具體事物(頂點)和這些事物之間的聯系(邊),由頂點(vertex)和邊(edge)組成, 頂點的集合V,邊的集合E,圖記為G = (V,E)
2.分類
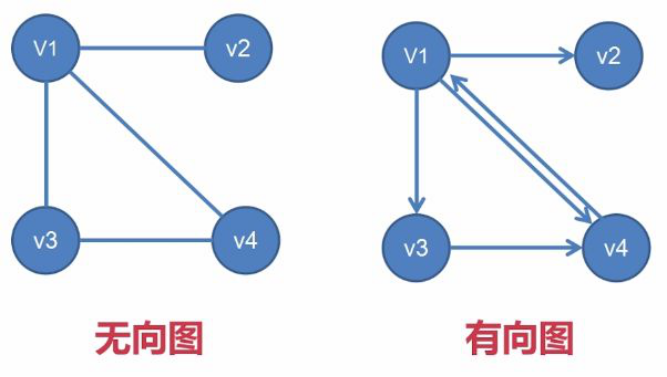
????1、無向圖 Def:邊沒有指定方向的圖
????2、有向圖 Def:邊具有指定方向的圖 (有向圖中的邊又稱為弧,起點稱為弧頭,終點稱為 弧尾)
????3.帶權圖 Def: 邊上帶有權值的圖,(不同問題中,權值意義不同,可以是距離、時間、價格、代價等不同屬性)
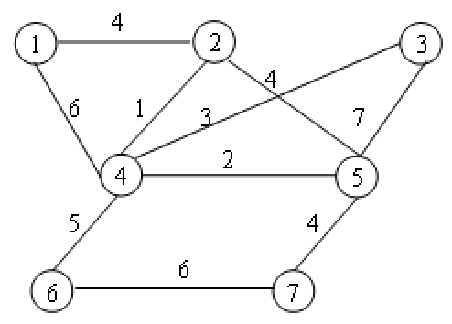
3.無向圖的術語
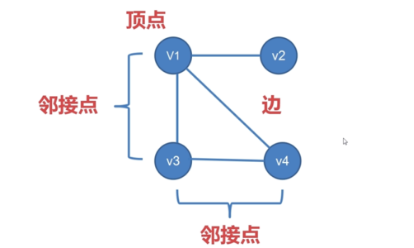
?兩個頂點之間如果有邊連接,那么就視為兩個頂點相鄰,
?路徑:相鄰頂點的序列,
?圈:起點和終點重合的路徑,
?連通圖:任意兩點之間都有路徑連接的圖,
?度:頂點連接的邊數叫做這個頂點的度,
樹:沒有圈的連通圖,
?森林:沒有圈的非連通圖,
??????????????????連通圖 非連通圖
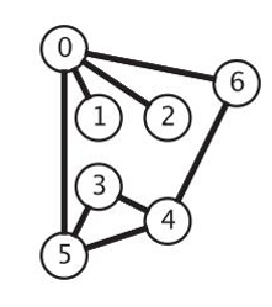
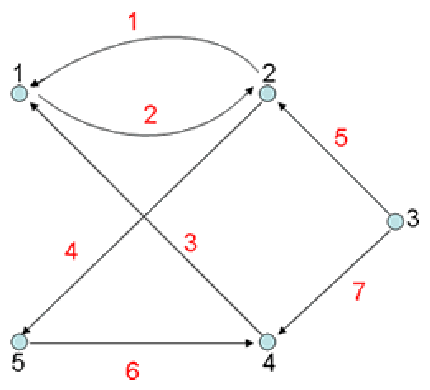
4.有向圖的術語
在有向圖中,邊是單向的:每條邊所連接的兩個頂點是一個有序對,他們的鄰接性是單向的,
有向路徑:相鄰頂點的序列,
有向環:一條至少含有一條邊且起點和終點相同的有向路徑,
有向無環圖(DAG):沒有環的有向圖,
度:一個頂點的入度與出度之和稱為該頂點的度,
??1)入度:以頂點為弧頭的邊的數目稱為該頂點的入度
??2)出度:以頂點為弧尾的邊的數目稱為該頂點的出度
eg.
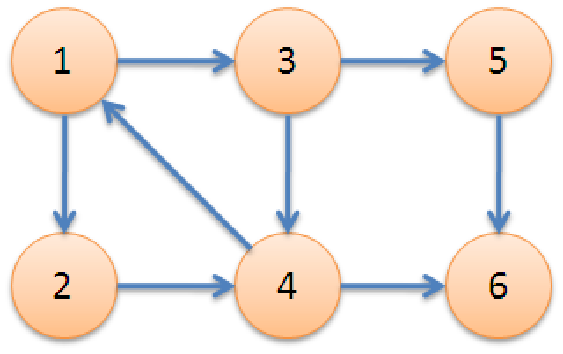
1->3->5->6 :有向路徑 ??1->3->4->1 :有向環 ????(3、4、5、6) :無環有向圖
節點1的度:3 節點1的入度:1 節點1的出度:2
二.圖的表示
??引入:如何用計算機來存盤圖的資訊(頂點、邊),這是圖的存盤結構要解決的問題?

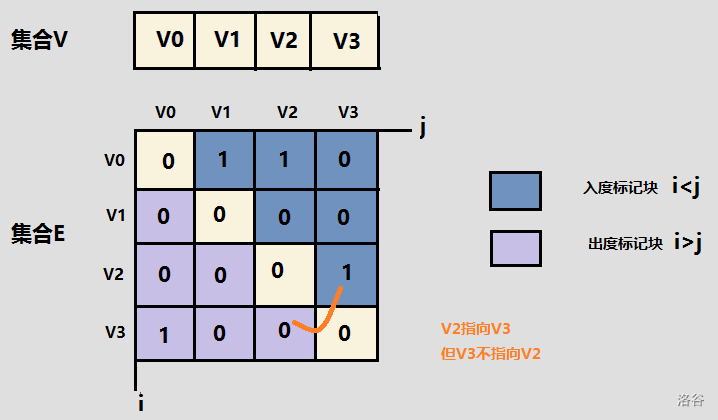
?1、鄰接矩陣
??對于一個有V的頂點的圖而言,可以使用V*V的二維陣列表示,G[i][j] 表示的是頂點i與頂點j的關系,
????如果頂點i和頂點j之間 有邊相連, G[i][j]=1
????如果頂點i和頂點j之間 無邊相連, G[i][j]=0
??對于無向圖:G[i][j]=G[j][i]
??在帶權圖中,如果在邊不存在的情況下,將G[i][j]設定為0,則無法與權值為0的情況分開,因此選擇較大的常數INF即可,
??鄰接矩陣的優點:可以在常數時間內判斷兩點之間是否有邊存在,
? 鄰接矩陣的缺點:表示稀疏圖時,浪費大量記憶體空間,表示稠密圖還是很劃算,
??
??eg. 鄰接矩陣存盤圖
Code
#include<bits/stdc++.h>
using namespace std;
int a[1005][1005];
int main(){
int n,m;
scanf("%d%d",&n,&m);
int u,v;
for(int i=1;i<=m;i++){
scanf("%d%d",&u,&v);
a[u][v]=a[v][u]=1;
}
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(a[i][j])
printf("%d ",j);
}
printf("\n");
}
return 0;
}?2、鄰接表
??通過把“從頂點0出發有到頂點2,3,5的邊”這樣的資訊保存在鏈表中來表示圖,
??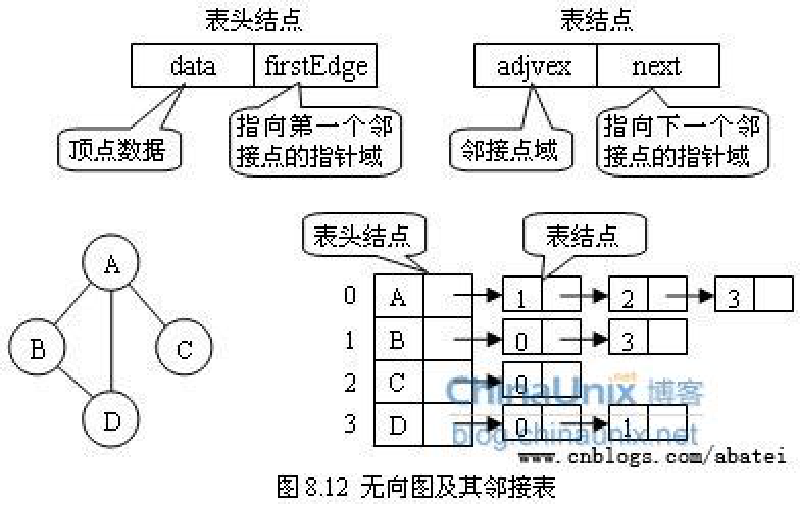
出邊表的表結點存放的是從表頭結點出發的有向邊所指的尾頂點
入邊表的表結點存放的則是指向表頭結點的某個頭頂點
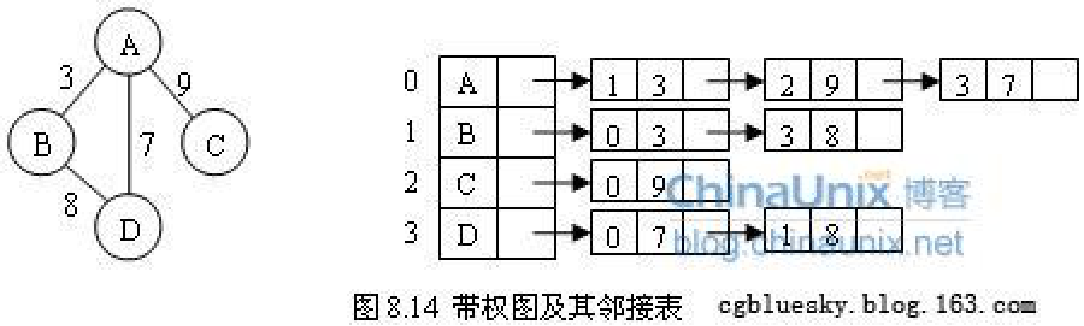
?帶權圖的鄰接表 :在表結點中增加一個存放權的欄位
??
eg.
將如下的圖利用鄰接表進行表示,并輸出每個頂點的度,
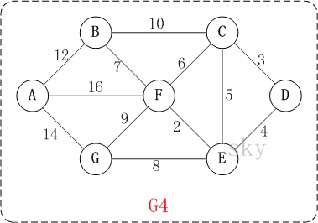
Code(偽)
#include<vector>
//存邊(編號和邊權)
struct edge{
int v,w;
edge(){}
//建構式
edge(int V,int W){
v=V;
w=W;
}
};
vector<edge> G[maxn];
void addEdge(int u,int v,int w){
G[u].push_back(edge(v,w));
}
for(int i=1;i<=N;++i){
int u,v,w;
cin>>u>>v>>w;
addEdge(u,v,w);
addEdge(v,u,w);
}?3.鏈式前向星
??參考:鏈式前向星--最通俗易懂的講解
如果說鄰接表是不好寫但效率好,鄰接矩陣是好寫但效率低的話,前向星就是一個相對中庸的資料結構,前向星固然好寫,但效率并不高,而在優化為鏈式前向星后,效率也得到了較大的提升,雖然說,世界上對鏈式前向星的使用并不是很廣泛,但在不愿意寫復雜的鄰接表的情況下,鏈式前向星也是一個很優秀的資料結構, ——摘自《百度百科》
鏈式前向星其實就是靜態建立的鄰接表,時間效率為O(m),空間效率也為O(m),遍歷效率也為O(m),
對于下面的資料,第一行5個頂點,7條邊,接下來是邊的起點,終點和權值,也就是邊1 -> 2 權值為1,
樣例
5 7
1 2 1
2 3 2
3 4 3
1 3 4
4 1 5
1 5 6鏈式前向星存的是以【1,n】為起點的邊的集合,對于上面的資料輸出就是:
1 //以1為起點的邊的集合
1 5 6
1 3 4
1 2 1
2 //以2為起點的邊的集合
2 3 2
3 //以3為起點的邊的集合
3 4 3
4 //以4為起點的邊的集合
4 5 7
4 1 5
5 //以5為起點的邊不存在
對比鄰接表
對于鄰接表來說是這樣的:
1 -> 2 -> 3 -> 5
2 -> 3
3 -> 4
4 -> 1 -> 5
5 -> ^
對于鏈式前向星來說是這樣的:
edge[0].to = 2; edge[0].next = -1; head[1] = 0;
edge[1].to = 3; edge[1].next = -1; head[2] = 1;
edge[2].to = 4; edge[2],next = -1; head[3] = 2;
edge[3].to = 3; edge[3].next = 0; head[1] = 3;
edge[4].to = 1; edge[4].next = -1; head[4] = 4;
edge[5].to = 5; edge[5].next = 3; head[1] = 5;
edge[6].to = 5; edge[6].next = 4; head[4] = 6;
簡化后:1 -> 5 -> 3 -> 2??由此可見對于每一個節點,輸出的順序為輸入時的逆序
我們先對上面的7條邊進行編號第一條邊是0以此類推編號【0~6】,然后我們要知道兩個變數的含義:
- Next :表示與這個邊起點相同的上一條邊的編號,
- head[ i ] :陣列,表示以 i 為起點的最后一條邊的編號,
??加邊函式是這樣的:
void add_edge(int u, int v, int w)//加邊,u起點,v終點,w邊權
{
edge[cnt].to = v; //終點
edge[cnt].w = w; //權值
edge[cnt].next = head[u];//以u為起點上一條邊的編號,也就是與這個邊起點相同的上一條邊的編號
head[u] = cnt++;//更新以u為起點上一條邊的編號
}??遍歷函式是這樣的:
for(int i = 1; i <= n; i++)//n個起點
{
cout << i << endl;
for(int j = head[i]; j != -1; j = edge[j].next)//遍歷以i為起點的邊
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}第一層for回圈是找每一個點,依次遍歷以【1,n】為起點的邊的集合,第二層for回圈是遍歷以 i 為起點的所有邊,k首先等于head[ i ],注意head[ i ]中存的是以 i 為起點的最后一條邊的編號,然后通過edge[ j ].next來找下一條邊的編號,我們初始化head為-1,所以找到你最后一個邊(也就是以 i 為起點的第一條邊)時,你的edge[ j ].next為 -1做為終止條件,
Code
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1005;//點數最大值
int n, m, cnt;//n個點,m條邊
struct Edge
{
int to, w, next;//終點,邊權,同起點的上一條邊的編號
}edge[maxn];//邊集
int head[maxn];//head[i],表示以i為起點的第一條邊在邊集陣列的位置(編號)
void init()//初始化
{
for (int i = 0; i <= n; i++) head[i] = -1;
cnt = 0;
}
void add_edge(int u, int v, int w)//加邊,u起點,v終點,w邊權
{
edge[cnt].to = v; //終點
edge[cnt].w = w; //權值
edge[cnt].next = head[u];//以u為起點上一條邊的編號,也就是與這個邊起點相同的上一條邊的編號
head[u] = cnt++;//更新以u為起點上一條邊的編號
}
int main()
{
cin >> n >> m;
int u, v, w;
init();//初始化
for (int i = 1; i <= m; i++)//輸入m條邊
{
cin >> u >> v >> w;
add_edge(u, v, w);//加邊
/*
加雙向邊
add_edge(u, v, w);
add_edge(v, u, w);
*/
}
for (int i = 1; i <= n; i++)//n個起點
{
cout << i << endl;
for (int j = head[i]; j != -1; j = edge[j].next)//遍歷以i為起點的邊
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}
return 0;
}
三.圖的遍歷
??從圖中的某個頂點出發,按某種方法對圖中的所有頂點訪問且僅訪問一次,為了保證圖中的頂點在遍歷程序中僅訪問一次,要為每一個頂點設定一個訪問標志,
??1.DFS
概念
深度優先搜索(Depth-First Search)遍歷類似于樹的先根遍歷,是樹的先根遍歷的推廣,假設初始狀態是圖中所有頂點未曾被訪問,則深度優先搜索可從圖中某 個頂點v出發,訪問此頂點,然后依次從v的未被訪問的鄰接點出發深度優先遍歷圖,直至圖中所有和v有路徑相通的頂點都被訪問到;若此時圖中尚有頂點未被訪 問,則另選圖中一個未曾被訪問的頂點作起始點,重復上述程序,直至圖中所有頂點都被訪問到為止,
Code
#include<bits/stdc++.h>
#define Maxn 205
using namespace std;
int n, m;
bool a[Maxn][Maxn], vis[Maxn];
void DFS(int i) {
cout << i << ' ';
vis[i] = 1;
for (int j = 1; j <= n; j++) {
if (a[i][j]) {
if (!vis[j]) {
vis[j] = 1;
DFS(j);
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int x, y;
cin >> x >> y;
a[x][y] = 1;
}
for (int i = 1; i <= n; i++) {
if (!vis[i])
DFS(i);
}
return 0;
}2.BFS
對(a)進行廣度優先搜索 遍歷的程序如圖(b)所示, 得到的頂點訪問序列為: v1->v2->v3->v4->v5->v6->v7->v8
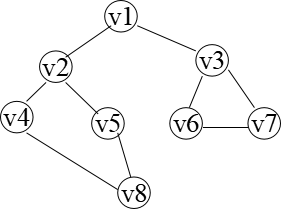
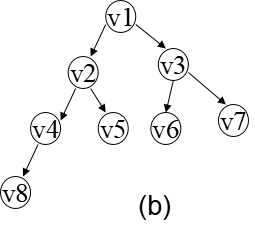
概念
廣度優先搜索(Breadth-First Search)遍歷類似于樹的按層次遍歷的程序, 假設從圖中某頂點v出發,在訪問v之后依次訪問v的各個未被訪問過的鄰接點,然后分別從這些鄰接點出發依次訪問它們的鄰接點,并使“先被訪問的頂點的鄰接 點”先于“后被訪問的頂點的鄰接點”被訪問,直至圖中所有已被訪問的頂點的鄰接點都被訪問到,若此時圖中尚有頂點未被訪問,則另選圖中一個未曾被訪問的 頂點作起始點,重復上述程序,直至圖中所有頂點都被訪問到為止,換句話說,廣度優先搜索遍歷圖的程序是以v為起始點,由近至遠,依次訪問和v有路徑相通 且路徑長度為1,2,…的頂點,
Code
#include<bits/stdc++.h>
using namespace std;
int n,m;
int a[205][205],vis[205];
void bfs(int x){
queue<int> Q;
Q.push(x);
printf("%d ",x);
vis[x]=1;
while(!Q.empty()){
int now=Q.front();
Q.pop();
for(int i=1;i<=n;i++){
if(a[now][i]&&!vis[i]){
Q.push(i);
printf("%d ",i);
vis[i]=1;
}
}
}
}
int main() {
scanf("%d%d",&n,&m);
int u,v;
for(int i=1;i<=m;i++){
scanf("%d%d",&u,&v);
a[u][v]=a[v][u]=1;
}
int k;
scanf("%d",&k);
bfs(k);
return 0;
} 3.歐拉路徑和歐拉回路
歐拉路是指存在這樣一種圖 , 可以從其中一點出發 , 不重復地走完其所有的邊 . 如果歐拉路的起點與終點相同 則稱之為歐拉回路
歐拉路存在的充要條件 : 圖是連通的 ,因為若不連通不可能一次性遍歷所有邊,
對于無向圖有且僅有兩個點 ,與其相連的邊數為奇數 ,其他點相連邊數皆為偶數 ;對于兩個奇數點 , 一個為起點 , 一個為終點 . 起點需要出去 ,終點需要進入 ,故其必然與奇數個邊相連 .
對于有向圖 除去起點和終點 , 所有點的出度與入度相等 ,且起點出度比入度大 1,終點入度比出度大 1, 若起點終點出入度也相同 ,則稱為歐拉回路,
可參見鴿巢原理
eg.一筆畫問題
Code
#include <bits/stdc++.h>
using namespace std;
int g[1005][1005], ans[1005], num[1005], idx = 0, n, m, st = 1;
;
void dfs(int i) {
for (int j = 1; j <= n; j++) {
if (g[i][j]) {
g[i][j] = g[j][i] = 0;
dfs(j);
}
}
ans[++idx] = i;
}
int main() {
memset(g, 0, sizeof(g));
scanf("%d%d", &n, &m);
for (int i = 1; i <= m; i++) {
int x, y;
scanf("%d%d", &x, &y);
g[x][y] = g[y][x] = 1;
num[x]++;
num[y]++;
}
for (int i = 1; i <= n; i++) {
if (num[i] % 2)
st = i;
}
dfs(st);
for (int i = 1; i <= idx; i++) {
printf("%d ", ans[i]);
}
return 0;
}4.哈密頓路
哈密頓路徑也稱作哈密頓鏈,指在一個圖中沿邊訪問每個頂點恰好一次的路徑,
Code
#include<bits/stdc++.h>
using namespace std;
int n,a[105][105],ans=0;
bool mp[105];
void dfs(int k,int t)
{
if(t==n){
ans++;
return;
}
for(int i=1;i<=n;i++)
{
if(a[k][i]==1 &&mp[i]==true)
{
mp[i]=false;
dfs(i,t+1);
mp[i]=true;
}
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
scanf("%d",&a[i][j]);
for(int i=1;i<=n;i++){
memset(mp,true,sizeof(mp));
mp[i]=false;
dfs(i,1);
}
printf("%d",ans);
return 0;
}四.最短路問題
最短路徑問題是圖論研究中的一個經典演算法問題, 旨在尋找圖(由結點和路徑組成的)中兩結點之間的最短路徑,
1.Floyd
佛洛伊德是最簡單的最短路徑演算法,可以計算圖中任意兩點間的最短路徑,時間復雜度為O(N3),適用于出現負邊權的情況,
演算法描述:
(a)初始化:點u、v如果有邊相連,則F[u][v]=w[u][v]
如果不相連,則
for(int k=1;k<=n;k++) {
for(int i=1;i<=n;i++) {
for(int j=1;j<=n;j++) {
F[i][j]=max(F[i][j],F[i][k]+F[k][j]);
}
}
}(c)演算法結束:F[i][j]得出的就是任意起點i到任意終點j的最短路徑,
疑問:為什么列舉中間點的回圈k要放在最外層?
Answer
可以從一定不經過k點與一定經過k點的三維陣列比較中推匯出來
動態規劃以”途徑點集大小”為階段?
決策需要列舉中轉點,不妨考慮也以中轉點集為階段
F[k,i,j]表示”可以經過標號≤k的點中轉時”從i到j的最短路
F[0,i,j]=W[i,j],W為前面定義的鄰接矩陣
F[k,i,j]=min{F[k-1,i,j] , F[k-1,i,k]+F[k-1,k,j]},O(N^3)
k這一維空間可以省略,變成F[i,j]
就成為了我們平時常見的Floyd演算法
由于k是DP的階段回圈,所以k回圈必須要放在最外層動態規劃以”途徑點集大小”為階段?
決策需要列舉中轉點,不妨考慮也以中轉點集為階段 F[k,i,j]表示”可以經過標號≤k的點中轉時”從i到j的最短路 F[0,i,j]=W[i,j],W為前面定義的鄰接矩陣 F[k,i,j]=min{F[k-1,i,j] , F[k-1,i,k]+F[k-1,k,j]},O(N3)
k這一維空間可以省略,變成F[i,j] 就成為了我們平時常見的Floyd演算法 由于k是DP的階段回圈,所以k回圈必須要放在最外層 ,
也就是說每進行一次K的回圈,計算的都是任意兩點之間只經過前K個中轉點(可以不選)的最短路,
使用floyd輸出最短路徑
Floyd演算法輸出路徑也是采用記錄前驅點的方式,因為floyd是計算任意兩點間最短路徑的演算法,F[i][j]記錄從i到j的最短路徑值,故我們定義pre[i][j]為一個二維陣列,記錄從i到j的最短路徑中,j的前驅點是哪一個,遞回還原路徑,
初始化pre[i][i]為0,輸入相連邊時,重置相連邊尾結點的前驅
若有無向邊:pre[a][b]=a; pre[b][a]=b; 更新若floyd最短路有更新,那么pre[i][j]=pre[k][j];
Q:(這能不能直接賦值k的值?)
Answer
不能,因為不一定選了第K個點,遞回輸出指兩點s,e的最短路,先輸出起點s,再將終點e放入遞回,輸出s+1~e的所有點,
Code
void print(int x) {
if(pre[s][x]==0) return;
print(pre[s][x]);
printf(“->%d”,x);
}
2.Dijkstra
預備知識:松弛操作
??原來用一根橡皮筋連接a,b兩點,現在有一點k,使得a->k->b比a->b的距離更短,則把橡皮筋改為a->k->b,這樣橡皮筋更加松弛,這樣說或許不好理解,畢竟兩點之間線段最短是常識,可以這樣想,如果今天我要去羅馬,有很多種選擇,當然選擇最短的路,但如果最短的那條路太堵了,還不如選遠一點但不堵的呢,就可以試著轉站,這就是帶權的最短路問題,
if(dis[b]<dis[k]+w[k][b])
dis[b]=dis[k]+w[k][b]結點分成兩組:已經確定最短路、尚未確定最短路 不斷從第2組中選擇路徑長度最短的點放入第1組并擴展 本質是貪心,只能應用于正權圖 普通的Dijkstra演算法O(N^2) 堆優化的Dijkstra演算法O(NlogN)~O(MlogN)
演算法描述:
設起點為s,dis[v]表示從指定起點s到v的最短路徑,pre[v]為v的前驅,用來輸出路徑
(a)初始化
memset(dis,+∞),memset(vis,false);
(v:1~n)dis[v]=w[s][v];
dis[s]=0;pre[s]=0;
vis[s]=true;
(b)for(i=1;i<=n-1;i++)
①在沒有被訪問過的點中找一個相鄰頂點k,使得dis[k]是最小的;
②k標記為已確定的最短路vis[k]=true;
③用for回圈更新與k相連的每個未確定最短路徑的頂點v (所有未確定最短路的點都松弛更新)
if(dis[k]+w[k][v]<dis[v]) dis[v]=dis[k]+w[k][v],pre[v]=k;
(c)演算法結束dis[v]為s到v的最短路距離;pre[v]為v的前驅結點,用來輸出路徑,
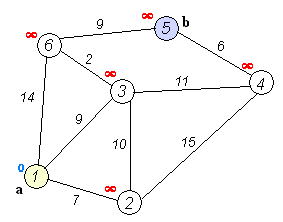
Code
#include <bits/stdc++.h>
using namespace std;
int n,m,s,t;
const int N =100001;
int dis[N];//從起始點到i的最短路
int vis[N];//是否確定最短路
struct edge {
int v,w;
};
struct node {
int u,dis;//下標,距離
bool operator<(const node &tmp)
const {
return dis>tmp.dis;//讓還沒有確定最短路的數以距離 從小到大,每一次選最小的作為松弛點
}
};
priority_queue<node> Q;
vector<edge> G[N];
int Dijkstra(int S,int T) {
memset(vis,0,sizeof(vis));
memset(dis,0x3f,sizeof(dis));
dis[S]=0;
Q.push((node){S,0});//將起點壓入佇列
while(!Q.empty()) {
int u=Q.top().u;//取出起點下標
Q.pop();
if(vis[u]) continue;//如果已經確定最短路徑,continue
vis[u]=1;
int v,w,siz=G[u].size();
for(int i=0;i<siz;i++) {//列舉與u相鄰的點
v=G[u][i].v,w=G[u][i].w;//取出與它相鄰點下的標,與它的距離
if(dis[v]>dis[u]+w) {//將起點到此相鄰點的距離 與將u作為起點到v的松弛點比較(進行松弛操作)
dis[v]=dis[u]+w;
Q.push((node){v,dis[v]}); //如果進行松弛操作,壓入佇列
}
}
}
return dis[T];
}
int main()
{
int u,v,w;
scanf("%d %d %d %d",&n,&m,&s,&t);
for(int i=0;i<m;i++) {
scanf("%d %d %d",&u,&v,&w);
G[u].push_back((edge){v,w});
G[v].push_back((edge){u,w});
}
cout<<Dijkstra(s,t);
return 0;
}3.Bellman-Ford演算法 與SPFA演算法
Bellman-Ford演算法:對每條邊執行更新,迭代N-1次, 具體操作是對圖進行最多n-1次松弛操作,每次操作對所有的邊進行松弛,為什么是n-1次操作呢?這是因為我們輸入的邊不一定是按源點由近至遠,萬一是由遠至近最壞情況就得n-1次,我們可以以一個單鏈A→B→C→D來舉例(由老師寫黑板吧) 可以應用于負權圖
SPFA:對每條邊執行更新,迭代N-1次 SPFA = 佇列優化的Bellman-Ford演算法 本質上還是迭代——每更新一次就考慮入隊 稀疏圖上O(kN),稠密圖上退化到O(N^2)
SLF優化:Small Label First, 新入隊點與隊頭比較
LLL優化:Large Label Last, 隊頭與平均值比較 可以應用于有向負權圖
演算法實作:
在Bellmanford演算法中,有許多松弛是無效的,這給了我們很大的改進的空間,SPFA演算法正是對Bellmanford演算法的改進,它是由西南交通大學段丁凡1994提出的,它采用了佇列和松弛技術,先將源點加入佇列,然后從佇列中取出一個點(此時該點為源點),對該點的鄰接點進行松弛,如果該鄰接點松弛成功且不在佇列中,則把該點加入佇列,如此回圈往復,直到佇列為空,則求出了最短路徑, 判斷有無負環:如果某個點進入佇列的次數超過N次則存在負環 ( 存在負環則無最短路徑,如果有負環則會無限松弛,而一個帶n個點的圖至多松弛n-1次)

五.最小生成樹
??樹有這樣一個定理:N個點用N-1條邊連接成一個連通塊,形成的圖形只可能是樹,叫做生成樹!因此,一個有N個點的連通圖,邊一定是≥N-1條的!特別的 口袋的天空 ,如果想要連出k棵樹,就需要連n-k條邊,
1.Kruskal演算法
??利用并查集維護,初始時每個點單獨為一個集合,把邊的權值從小到大排序后依次掃描,如果這條邊的u,v在一個集合,那么如果把u,v連上就會形成一個回路,因此不管(見下圖),如果不在一個集合,就合并,
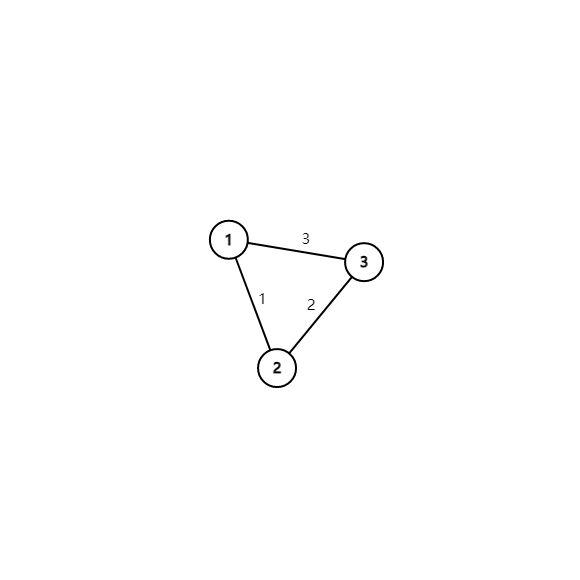
很顯然,按照我們的思路,權值為3的這條邊是不應該被連的,又因為前面排過序,保證了最小值的準確性
具體流程
(a)初始化
①寫出找祖先函式int find_father(int x)
②寫出合并函式void union_set(int x , int y)
③寫出sort的cmp(結構體a.u , a.v , a.w),對存在的邊權(a.w)從小到大排序
④主函式里面:for輸入邊,for把每個點的父節點初始化為自己,sort排序
⑤MST=0
(b)for(i=1;i<=m;i++)
①if兩個點的祖先不是同一個,連接兩個點,MST+=邊權,邊+1;
②if(邊==n-1)break;
(c)演算法結束:MST即為最小生成樹的權值之和,
Code
#include<bits/stdc++.h>
using namespace std;
struct edge {
int u,v,c;
}G[10005];
int fa[10005];
int Find(int x) {
if(fa[x]==x) return x;
return fa[x]=Find(fa[x]);
}
bool cmp(edge x,edge y) {
return x.c<y.c;
}
int main() {
int n,m;
scanf("%d %d",&n,&m);
for(int i=1;i<=n;i++)
fa[i]=i;
for(int i=1;i<=m;i++) {
scanf("%d %d %d",&G[i].u,&G[i].v,&G[i].c);
}
sort(G+1,G+m+1,cmp);
int cnt=0,sum=0;
for(int i=1;i<=m;i++) {
int x=Find(G[i].u),y=Find(G[i].v);
if(x==y) continue;
fa[x]=y;
sum=max(G[i].c,sum);
cnt++;
if(cnt==n) break;
}
printf("%d %d",n-1,sum);
return 0;
}2.Prim演算法
筆者還是更喜歡Kruskal
以任意一個點為基準點 節點分為兩組:
1. 在MST上到基準點的路徑已經確定的點
2. 尚未在MST中與基準點相連的點
不斷從第2組中選擇與第1組距離最近的點加入第1組 類似于Dijkstra,本質也是貪心,O(N^2)
具體流程
??也使用“藍白點”思想,白點代表已進入最小生成樹的點,藍點代表未進入最小生成樹的點,以1為起點生成最小生成樹,min[v]表示藍點v與白點相連的最小邊權,MST表示最小生成樹的權值之和,
??(a)初始化:min[v]=∞(v≠1); min[1]=0; MST=0;
??(b)for(i=1;i<=n;i++)
????①for尋找min[u],最小的藍點u;
????②將u標記為白點;
????③MST+=min[u];
????④for與白點u相連的所有藍點v(可暴力列舉,更好的是求vector的size)
?????if(w[u][v]<min[v]) min[v]=w[u][v];
??(c)演算法結束:MST即為最小生成樹的權值之和,
Code
#include<bits/stdc++.h>
using namespace std;
int n,ans, a[105][105],m[105],p[105];
int main()
{
scanf("%d",&n);
for (int i=1;i<=n;i++)
for (int j=1;j<=n;j++)
scanf("%d",&a[i][j]);
memset(m,0x3f,sizeof(m));
memset(p,0,sizeof(p));
m[1]=0;
for (int i=1;i<=n;i++)
{
int k=0;
for (int j=1;j<=n;j++)
if (p[j]==0&&m[j]<m[k])
k=j;
p[k]=1;
ans+=m[k];
for (int j=1;j<=n;j++)
if (p[j]!=1&&a[k][j]<m[j])
m[j]=a[k][j];
}
cout<<ans<<endl;
return 0;
}堆優化和鄰接表就不寫了吧……(心虛……)
Show time
No.1 走廊潑水節
??給定一棵N個節點的樹,要求增加若干條邊,把這棵樹擴充為完全圖,并滿足圖的唯一最小生成樹仍然是這棵樹,
求增加的邊的權值總和最小是多少,
?題目分析
??首先說明,筆者是看懂的 LINK 這篇博客,
??看到題面,我們首先需要知道完全圖是什么,度娘如是說道:“完全圖是一個簡單的無向圖,其中每對不同的頂點之間都恰連有一條邊相連”,相當于題目給了你一顆子樹,讓你填充,倒著想,如果給了你一顆完全圖求最小生成樹,你會怎么求?先從小到大排序,然后你會發現對于最小生成樹的每兩個,如果在完全圖中還存在另一邊(最小生成樹中不包含),那么這一邊一定比對于這兩點在最小生成樹的任意邊小,倒回來,你填充的任意邊必須比這兩點連通的邊大,
首先我們設Sx表示為x之前所在的連通塊 那么Sy表示為y之前所在的連通塊.
假如說點A屬于Sx這個集合之中 點B屬于Sy這個集合之中. 那么點A與點B之間的距離,必須要大于之前的w,否則就會破壞之前的最小生成樹,所以說(A,B)之間的距離最小為w+1,假如說我們知道Sx有p個元素,然后Sy有q個元素,那么將Sx與Sy連通塊的所有點相連.顯然這個兩個連通塊會增加.p×q?1條邊,然后每一條邊的最小長度都為w+1,
所以我們會得出
(w+1)×(p?q?1)為兩個連通塊成為完全圖的最小代價
Code
#include <bits/stdc++.h>
using namespace std;
int s[6005],fa[6005];
struct Edge {
int u,v,w;
}edge[6005];
bool cmp (Edge x,Edge y) {
return x.w<y.w;
}
int Find(int x) {
if(fa[x]==x) return x;
return fa[x]=Find(fa[x]);
}
int main() {
int t;
scanf("%d",&t);
while(t--) {
int n;
scanf("%d",&n);
for(int i=1;i<=n;i++)
fa[i]=i,s[i]=1;
for(int i=1;i<n;i++) {
scanf("%d %d %d",&edge[i].u,&edge[i].v,&edge[i].w);
}
sort(edge+1,edge+n,cmp);
int ans=0;
for(int i=1;i<n;i++) {
int x=Find(edge[i].u),y=Find(edge[i].v);
if(x==y) continue;
fa[x]=y;
ans+= (edge[i].w+1) * (s[x]*s[y]-1);
s[y]+=s[x];
}
printf("%d\n",ans);
}
return 0;
}
No.2 最短路上的統計
既然是多源最短路,就應該用Floyd來做,
我們先用三重回圈跑一遍Floyd,先求得最短路,
對于每一個ask,依次列舉每一個點看最短路經不經過,
Code
#include<bits/stdc++.h>
using namespace std;
int n,m,a[101][101],ans[101][101],p,x,y;
int main()
{
memset(a,127/3,sizeof(a));
scanf("%d%d",&n,&m);
for(int i=1;i<=m;++i){
scanf("%d%d",&x,&y);
a[x][y]=1;a[y][x]=1; //權值為1
}
for(int i=1;i<=n;++i) //初始化一下
a[i][i]=0;
for(int k=1;k<=n;k++) //Floyed
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
a[i][j]=min(a[i][j],a[i][k]+a[k][j]);
scanf("%d",&p);
for(int i=1;i<=p;++i){
scanf("%d%d",&x,&y);
if(ans[x][y]==0){
for(int k=1;k<=n;++k) //列舉點k
if(a[x][k]+a[k][y]==a[x][y]) ans[x][y]++; //如果點k在最短路上,ans++
ans[y][x]=ans[x][y];
}
printf("%d\n",ans[x][y]); //輸出
}
}
本文來自博客園,作者:Doria_tt,轉載請注明原文鏈接:https://www.cnblogs.com/pangtuan666/p/16503612.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/500340.html
標籤:C++
下一篇:C++ 中的Lambda運算式