雙向鏈表與資料結構
引言
在上小節中
我們分析了ArrayList的底層實作,
知道了ArrayList底層是基于陣列實作的,因此具有查找修改快而插入、洗掉慢的特點
本章我們介紹的LinkedList是List介面的另一種實作
它的底層是基于雙向鏈表實作的
因此它具有插入、洗掉快而查找修改慢的特點
什么是LinkedList
LinkList是一個雙向鏈表(雙鏈表);它是鏈表的一種,也是最常見的資料結構,其內部資料呈線性排列,屬于線性表結構.
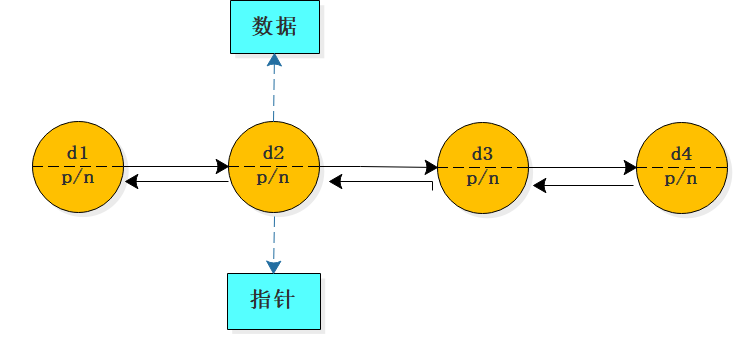
它的每個資料結點中都有兩個指標,分別指向直接后繼和直接前驅,所以,從雙向鏈表中的任意一個結點開始,都可以很方便地訪問它的前驅結點和后繼結點,所以是雙向鏈表.
LinkList特點:
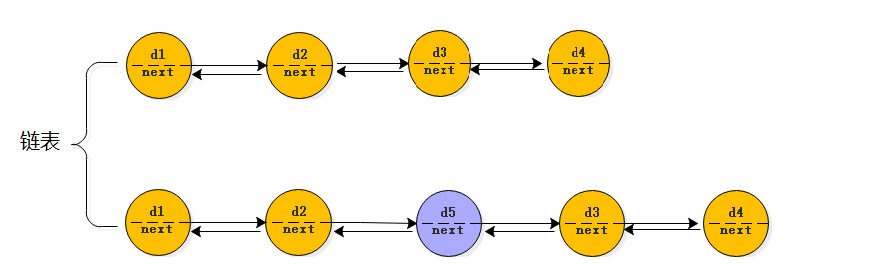
鏈表: 優勢:不是連續的記憶體,隨便插入(前、中間、尾部) 插入O(1) 劣勢:查詢慢O(N)
執行緒不安全的,允許為null,允許重復元素
藍色表示;可隨意插入、洗掉
查詢回圈回圈鏈表
總結
雙鏈表的節點既有指向下一個節節點的指標,也有指向上一個結點的指標(雙向讀)
所謂指標,就是指向其他節點的一個物件的參考(說白了就是定義了兩個成員變數)
雙向鏈表執行緒不安全的,允許為null,允許重復元素
查詢O(n)
插入洗掉O(1)
1.2 雙向鏈表繼承關系
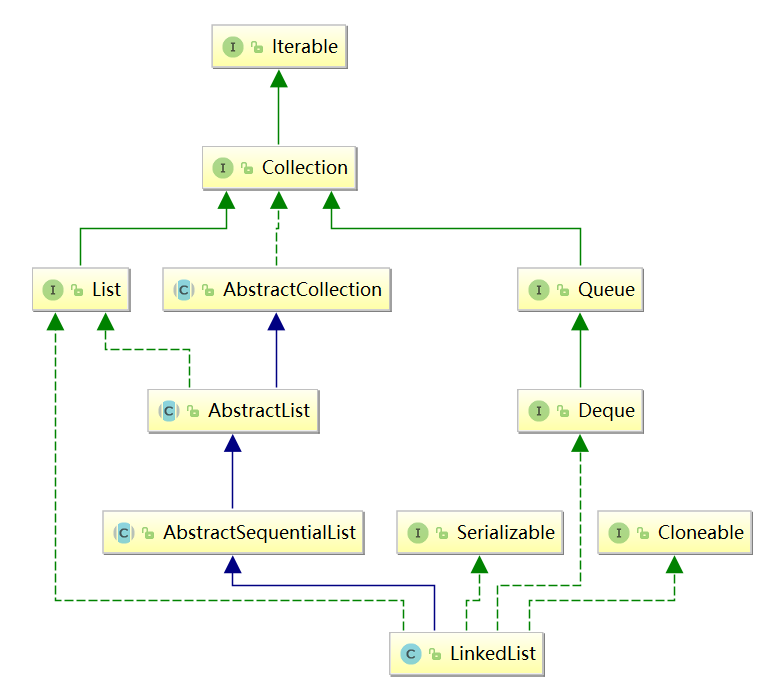
LinkedList 是一個繼承于AbstractSequentialList的雙向鏈表,
LinkedList 實作 List 介面,能對它進行佇列操作,
LinkedList 實作 Deque 介面,能將LinkedList當作雙端佇列(double ended queue)使用,
LinkedList 實作了Cloneable介面,即覆寫了函式clone(),能克隆,
LinkedList 實作java.io.Serializable介面,這意味著LinkedList支持序列化,能通過序列化去傳輸,
1.3 雙向鏈表原始碼深度剖析
案例代碼
com.llist.LList
package com.llist;
import java.util.ArrayList;
import java.util.Collection;
import java.util.LinkedList;
public class LList {
public static void main(String[] args) {
LinkedList<String> linkedList = new LinkedList<String>();
linkedList.add("100");//尾插,等價于 linkedList.addLast()
linkedList.add("200");
linkedList.add("300");
//*******中間插入linkedList..add(3,"700")*************
linkedList.add("400");
linkedList.add("500");
linkedList.add("600");
System.out.println(linkedList);
linkedList.add(3,"700");//中間插入
System.out.println(linkedList);
//*******修改***************************************
linkedList.set(3,"700000000");
System.out.println(linkedList);
//*******查詢***************************************
System.out.println(linkedList.getFirst());//頭查
System.out.println(linkedList.getLast());//尾查
// for(int s=0;s<linkedList.size();s++){
// System.out.println(linkedList.get(s));//隨機插
// }
//*******移除***************************************
LinkedList<String> linkedListRemove = new LinkedList<String>();
linkedListRemove.add("100");
linkedListRemove.add("200");
linkedListRemove.add("300");
linkedListRemove.remove(1);//指定移除
linkedListRemove.removeAll(linkedList);//也呼叫上面的unlink方法;LinkedList.ListItr.remove
}
}
1.3.1 鏈表成員變數與內部類
我們先來定義幾個叫法,后面會用到它
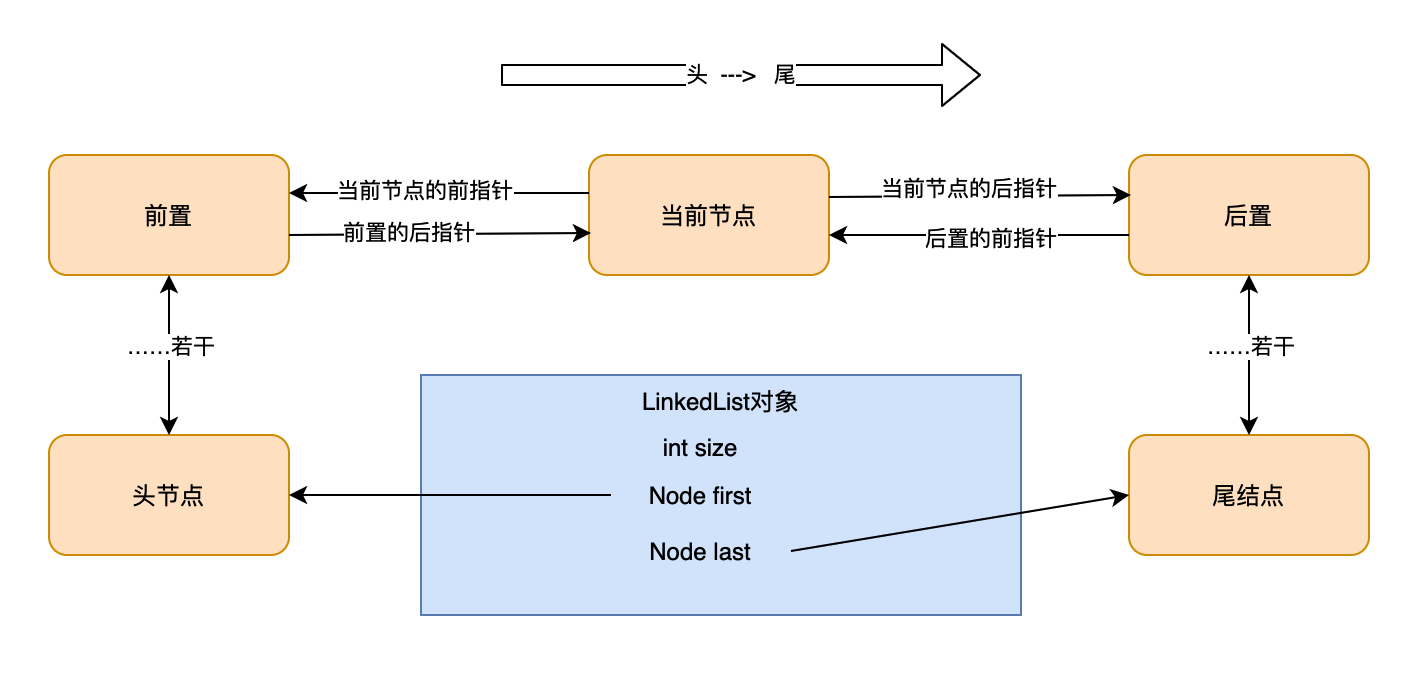
transient int size = 0;//元素個數
transient Node<E> first;//頭結點參考(查詢時獲取)
transient Node<E> last;//尾節點參考(查詢時獲取)
private static class Node<E> { //鏈表節點元素,封裝了真實資料,同時加入了前后指標
E item;//元素,這是放入的真實資料
Node<E> next;//下一個節點,指標也是Node型別
Node<E> prev;//上一個節點
//構造器,前、值、后,很清晰
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;//新元素
this.next = next;//下個節點
this.prev = prev;//上個節點
}
}
1.3.2 雙向鏈表構造器
無參構造器: 沒有做任何事情
public LinkedList() { //無參構造器
}
有參構造器:傳入外部集合的構造器
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
秘密就藏在addAll上(重點,畫圖展示)
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index); //邊界判斷
Object[] a = c.toArray(); //不管你傳啥型別,統一轉成陣列
int numNew = a.length; //需要新插入的個數
if (numNew == 0)
return false;
//兩個指標,這倆表示你要插入點的前后兩個節點,我們稱之為前置node和后置node
//比如你的index=2 : 【 000 1111(pred) (index) 2222(succ) 33333 …… 】
Node<E> pred, succ;
if (index == size) { //下面就要定位到這倆指標的位置
succ = null; //如果指定的index和尾部相等,很顯然后置是沒有的
pred = last; //前置就是最后一個元素last
} else {
succ = node(index); //否則的話,后置就是當前index位置的node,這個方法下面有詳細介紹先不管它
pred = succ.prev; //前置就是當前index位置的prev,很好理解
}
for (Object o : a) { //開始回圈遍歷插入元素
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null); //定義個新節點,包裝當前元素
if (pred == null) //如果前置為空,注意什么時候才為空?只有頭插或當前list沒有元素的時候
first = newNode; //說明是第一次放入元素,將first指向當前元素,完工
else
pred.next = newNode; //否則的話,前置node的后指標指向當前元素(接上了)
pred = newNode; //讓前置指標后移,指向剛新建的node,為下一次回圈做準備
} //依次回圈,往上接,接完后,pred就是最后一個插入的元素
//全部回圈接完以后,再來處理新接鏈條的后指標
if (succ == null) { //如果后置是nul的話,說明我們一直在尾部插入
last = pred; //將last指向最后一個插入的元素即可,它就是尾巴
} else {
pred.next = succ; //否則的話,最后一個插入的next指向原來插入前的后置
succ.prev = pred; //后置的前指標指向最后插入的元素,這兩步是一對操作缺一不可
} //到此為止,截斷的后半截鏈條也對接上了,
size += numNew; //最后不要忘記,元素數量增加
modCount++; //操作計數器增加
return true;
}
1.3.3 鏈表插入(重點)
1) 雙向鏈表尾插法
1、add(E e),
2、addLast;
呼叫的方法都一樣(linkLast)
public boolean add(E e) {
linkLast(e);//在鏈表尾部添加
return true;
}
在鏈表尾部添加
/**
* 在鏈表尾部添加
*/
void linkLast(E e) {
final Node<E> l = last;//取出當前最后一個節點
final Node<E> newNode = new Node<>(l, e, null); //創建一個新節點,注意其前驅節點為l
last = newNode;//尾指標指向新節點
if (l == null)//如果原來的尾巴節點為空,則表示鏈表為空,則將first節點也賦值為newNode
first = newNode;
else
l.next = newNode; // 否則的話,將原尾巴節點的后指標指向新節點,構成雙向環
size++;// 計數
modCount++; //計數
}
結論:默認add就是尾插法,追加到尾部
2)雙向鏈表中間插入
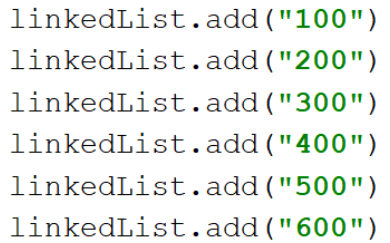
目標:將700插入到400的位置
插入前
插入后的
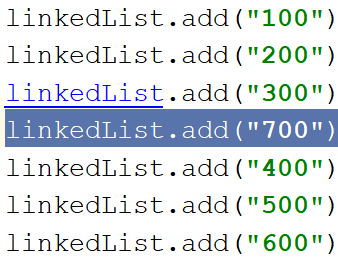
雙向鏈表中間插入add(int index, E element)
//自定義插入
linkedList.add(3,"700");
原始碼如下
public void add(int index, E element) {
checkPositionIndex(index);//越界檢查
if (index == size)//如果index就是指向的尾部,自然調尾插即可
linkLast(element);
else
linkBefore(element, node(index));//否則的話,找到index位置的node,插隊到它前面去
}
/**
* 那它怎么找的呢?看以下方法(畫圖展示)
*/
Node<E> node(int index) {
// 這里有一個討巧的設計!很靈活的應用了我們的first和last
if (index < (size >> 1)) { // index如果小于鏈表長度的1/2 (size右移1就是除以2)
Node<E> x = first;
for (int i = 0; i < index; i++) //從鏈表頭開始移動 index 次
x = x.next; //依次往后指
return x; //回圈完后,就找到了index位置的node,回傳即可
} else { // 否則,說明index在鏈表的后半截,我們從鏈表尾部倒著往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--) //一直回圈,直到index位置
x = x.prev;
return x; //抓到后回傳,完工!
}
}
//畫圖展示
void linkBefore(E e, Node<E> succ) { //找到之后,也就是這里的succ,我們就開始在它前面插入新元素
// assert succ != null;
final Node<E> pred = succ.prev;//上個節點
final Node<E> newNode = new Node<>(pred, e, succ);//構建新的雙向節點
succ.prev = newNode;//修改后置節點的前指標
if (pred == null) //如果前驅節點為空,鏈表為空
first = newNode; //那么當前插入的就是頭節點
else
pred.next = newNode;//否則修改前置的后指標,指向新節點,雙向鏈表對接成功!
size++;//個數加1
modCount++;//修改次數加1
}
1.3.4 雙向鏈表修改方法
非常簡單!
找到包裝值的node,修改掉里面的屬性即可
public E set(int index, E element) {
checkElementIndex(index);//越界檢查
Node<E> x = node(index);//通過鏈表索引找到node
E oldVal = x.item;//獲取原始值
x.item = element;//新值賦值
return oldVal;//回傳老值
}
1.3.5 雙向鏈表查詢方法
簡單!
get(int index):按照下標獲取元素; 通用方法
getFirst():獲取第一個元素; 特有方法,直接拿指標就是
getLast():獲取最后一個元素; 特有方法,同樣直接拿指標
public E get(int index) {
checkElementIndex(index);//越界檢查
return node(index).item;//找到原始陣列對應index的node
}
System.out.println(linkedList.getFirst());//頭查
System.out.println(linkedList.getLast());//尾查
1.3.6 雙向鏈表洗掉方法
remove(E e):移除指定元素; 通用方法
removeAll(Collection<?> c) 移除指定集合的元素; 也呼叫的unlink方法
兩步走:1找,2刪
public boolean remove(Object o) {
if (o == null) { //如果要移除null元素
for (Node<E> x = first; x != null; x = x.next) { //從fist順著鏈表往后找
if (x.item == null) { //發現就干掉
unlink(x); //重點!干掉元素呼叫的其實是unlink方法
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) { //如果不是移除null的話,路子一個樣,無非就是==換成equals判斷
unlink(x);
return true;
}
}
}
return false;
}
/**
* 畫圖展示:將要移除的Node,比如【100】【200】【300】
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;//元素
final Node<E> next = x.next;//下個節點
final Node<E> prev = x.prev;//上個節點
if (prev == null) {
first = next;//上個為空,說明當前要移除的就是頭節點,將fist指標指向后置,我被移除后它升級為頭了
} else {
prev.next = next; //否則,前置的后指標指向后置
x.prev = null; //當前節點的前指標切斷!
}
if (next == null) {
last = prev;//后置為空說明當前要移除的是尾節點,我被移除后,我的前置成為尾巴
} else {
next.prev = prev; //否則,后置的前指標指向前置節點
x.next = null; //當前節點的后指標切斷!
} //到這里前后指標就理清了,該斷的斷了,該接的接了
x.item = null;// 把當前元素改成null,交給垃圾回收
size--;//鏈表大小減一
modCount++;//修改次數加一
return element; //已洗掉元素
}
本文由傳智教育博學谷 - 狂野架構師教研團隊發布
如果本文對您有幫助,歡迎關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/501060.html
標籤:其他