資料量 (Data Stream) 是在 Elasticsearch 7.9 版推出的一項功能,它可以很方便的處理時間序列資料,
1、簡介
1.1、什么是 Time Series Data
TSD 始終與時間戳關聯,該時間戳標識創建事件時該資料的時間點事件, 例如,它可以是傳感器資料(溫度測量)或安全設備日志,這些資料有什么共同點? 隨著時間的流逝,它的重要性趨于松散,與過去事件相關的舊檔案不如與新事件相關的檔案重要, 你可能不再對上個月的傳感器相關資料感興趣,尤其是非常精確的資料,
因此,在 ES 中,在彈性搜索中處理此資料的最佳選擇是使用基于時間的索引,
time Series Data 具有以下的特點:
它可以是來自一些服務器的日志或者是一些設施的指標,社交媒體流,基于時間的事件
由時間戳 + 資料組成
通常搜索最近事件
舊檔案變得不太重要
基于時間的索引是最佳選擇
每天,每周,每月,每年...創建一個新索引
1.2、處理 Time Series Data 的挑戰
當我們處理 TSD 資料時,會臨很多的挑戰:
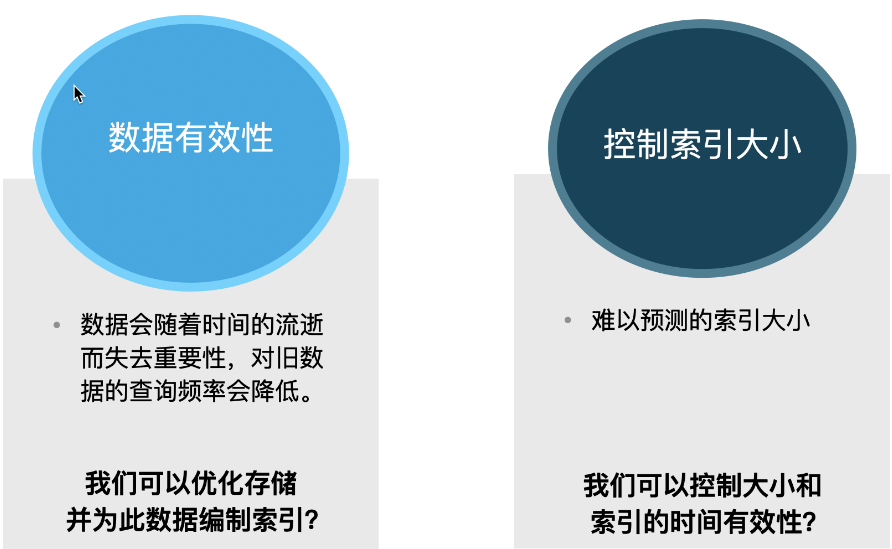
從資料的有效性來說,資料會隨著時間的流失而失去它的重要性,并且對舊的資料的查詢率會變低,我們需要使用新的存盤模式來對資料進行保存,比如,洗掉時間很久的資料,或者對稍微久一點的資料保存于一些價格較為便宜的存盤設備上以節省成本,并同時設定該索引為只讀,我們甚至對一些歷史更久的索引進行 close/frozen 操作從而更加進一步節省運行資源,
另外從控制索引的大小來說,我們很難預測索引的大小,當我們開始收集資料時,我們只有很少量的資料:
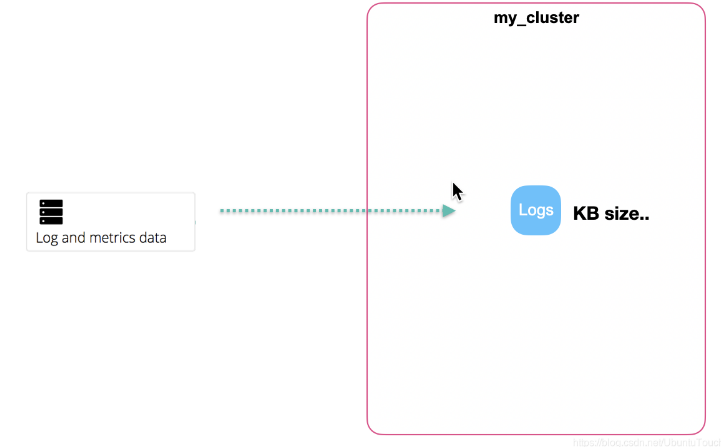
隨著資料量的增加:
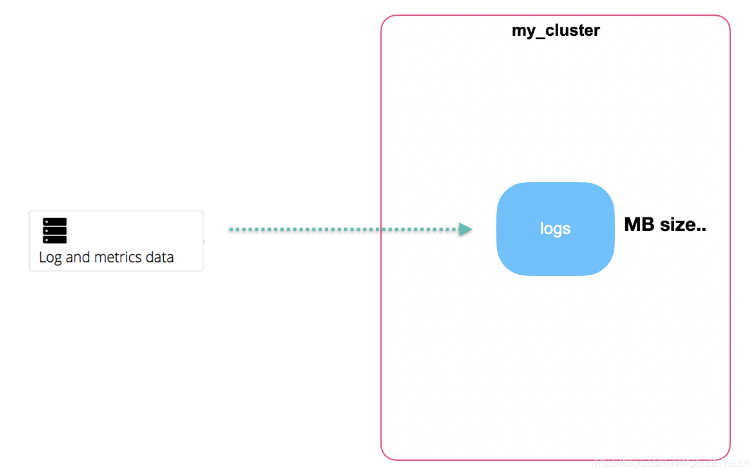
最終,我們可能看到更多的資料被收集上來:
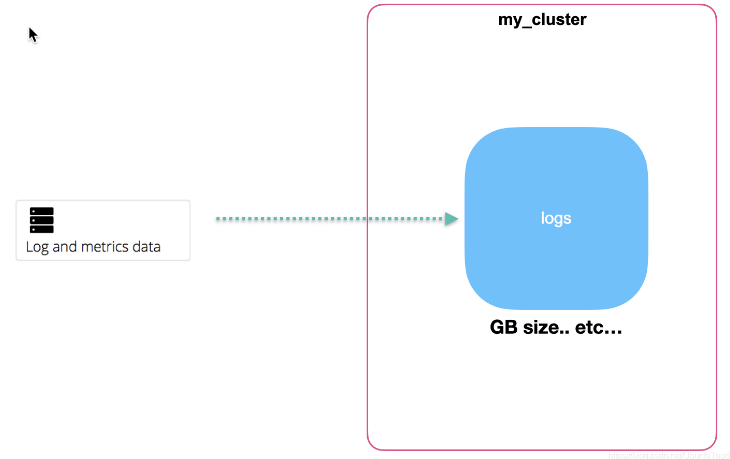
這對于我們計劃集群的大小和分片的個數帶來挑戰,我們需要按照我們需求針對每天,或者每周來分別創建索引來滿足自己業務的需求,我們甚至洗掉一些不需要的時間久一些的索引資料,這個就是我們通常所說的 ILM (索引生命周期管理),
避免過大的單個索引,而是把一個大的索引分為多個小的索引來進行存盤:
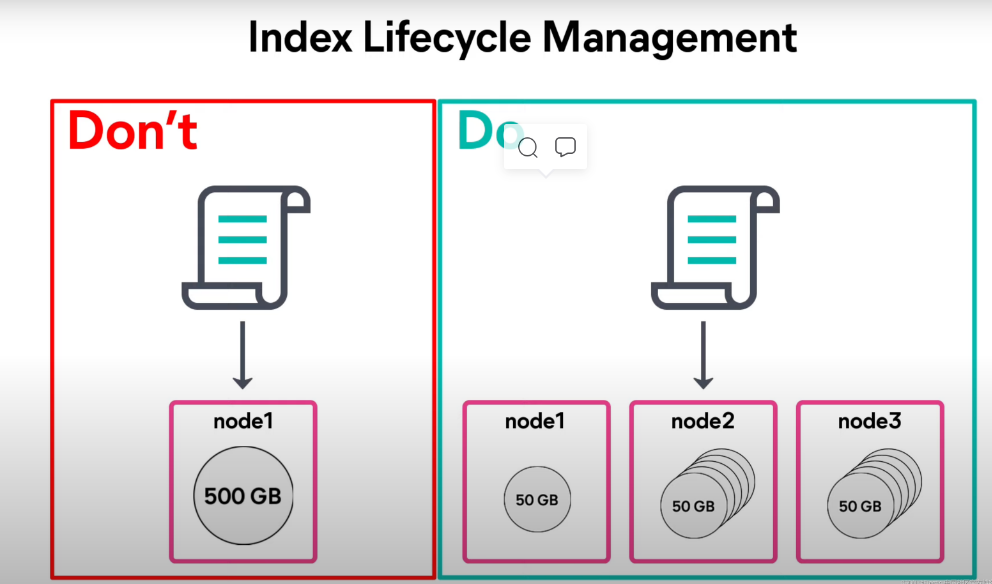
不要讓一個索引的大小過大,但是也不要讓一個索引的大小過小:
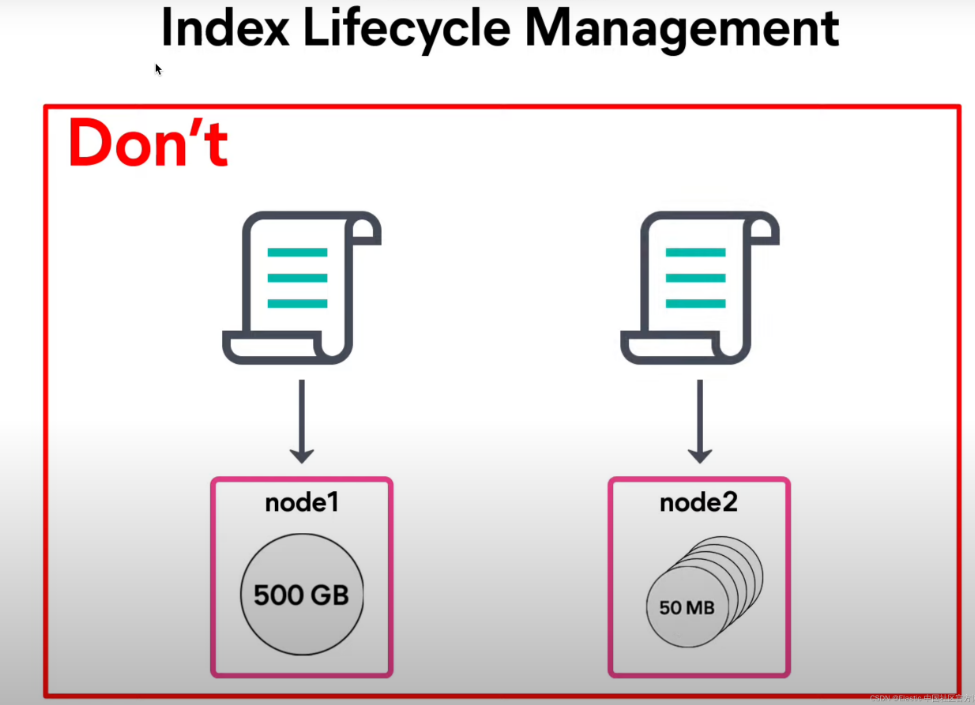
1.3、Data Stream
Data stream (資料流)是 Elastic Stack 7.9 的一個新的功能,Data stream 使你可以跨多個索引存盤只追加資料的時間序列資料,同時為請求提供唯一的一個命名資源, data stream 非常適合日志,事件,指標以及其他持續生成的資料,
你可以將索引和搜索請求直接提交到 data stream, stream 自動將請求路由到存盤流資料的后備索引, 你可以使用索引生命周期管理(ILM)來自動管理這些后備索引, 例如,你可以使用 ILM 自動將較舊的后備索引移動到較便宜的硬體上,并洗掉不需要的索引, 隨著資料的增長,ILM 可以幫助你降低成本和開銷,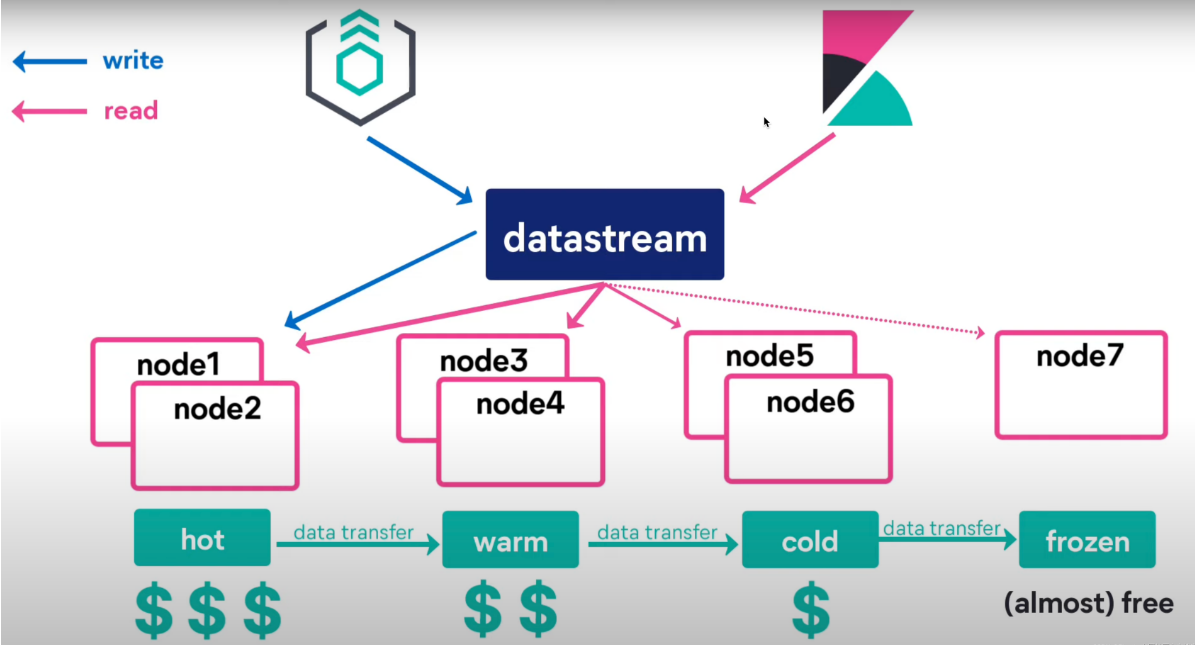
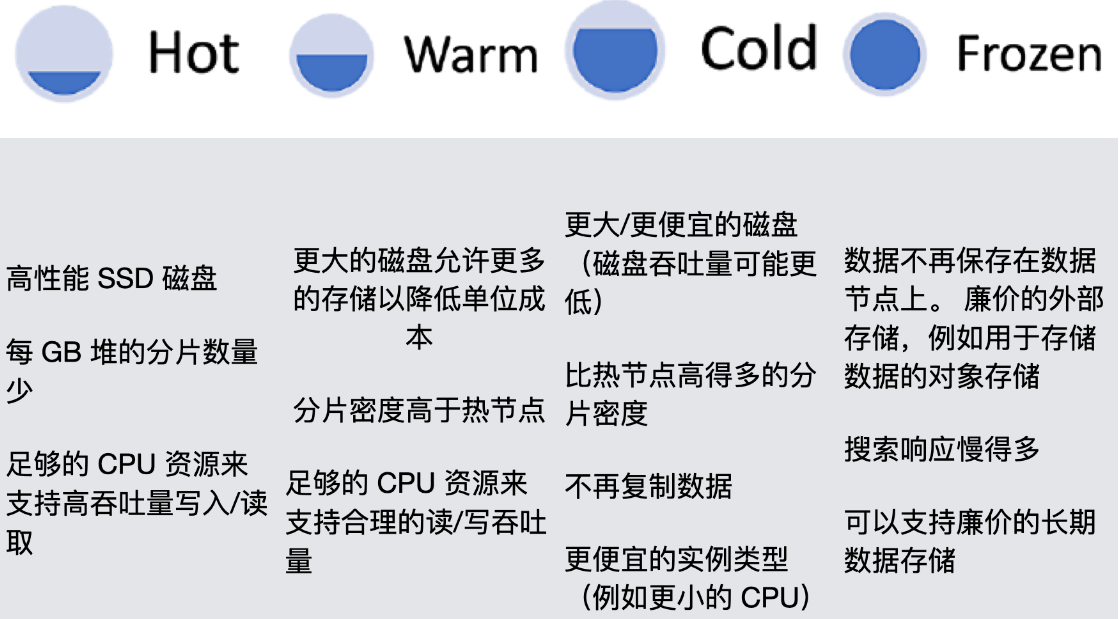
請注意,并非所有資料集都以相同的方式老化, 資料層不適用于產品搜索或全文搜索用例,例如,隨著檔案的老化,查詢的頻率會降低, 通常,資料生命周期概念適用于時間序列資料,但某些用例可能會有所不同,隨著索引的老化而移動索引的程序由稱為索引生命周期管理的功能管理,
1.3.1、后備索引(Backing indices)
資料流由一個或多個 hidden 的自動生成的后備索引(Backing indices)組成,
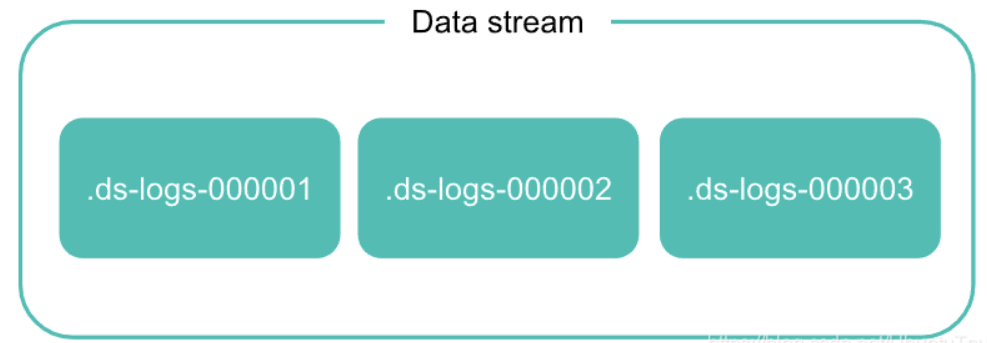
每個資料流都需要一個匹配的索引模板, 該模板包含用于配置流的后備索引的映射和設定,
索引到資料流的每個檔案都必須包含一個 @timestamp 欄位,該欄位映射為 date 或 date_nanos 欄位型別, 如果索引模板未為 @timestamp 欄位指定映射,則 Elasticsearch 將@timestamp 映射為具有默認選項的日期欄位,
同一個索引模板可用于多個資料流, 你不能洗掉資料流正在使用的索引模板,
1.3.2、讀請求
當你向資料流提交讀取請求時,該流會將請求路由到其所有后備索引,
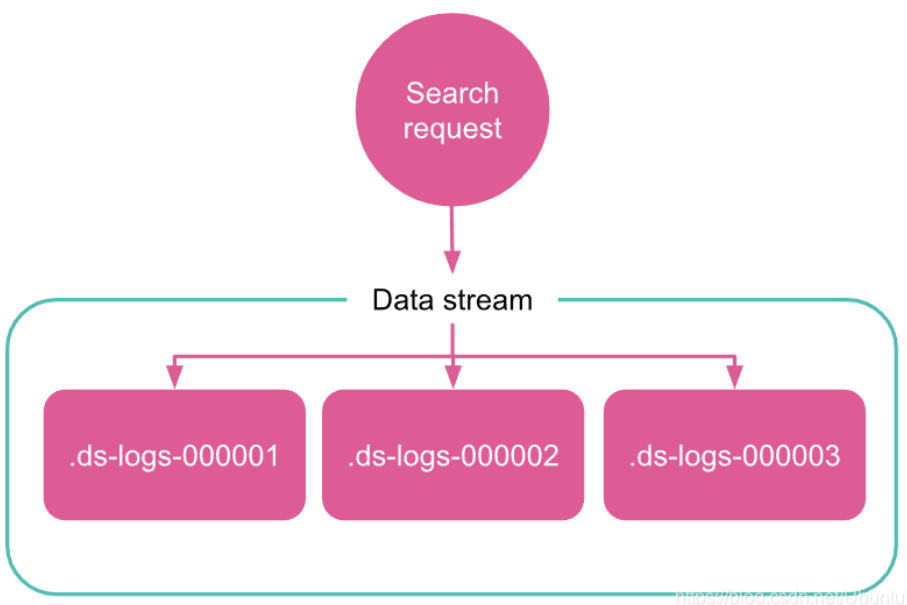
1.3.4、寫索引
最新創建的后備索引是資料流的寫索引, 流僅將新檔案添加到該索引,
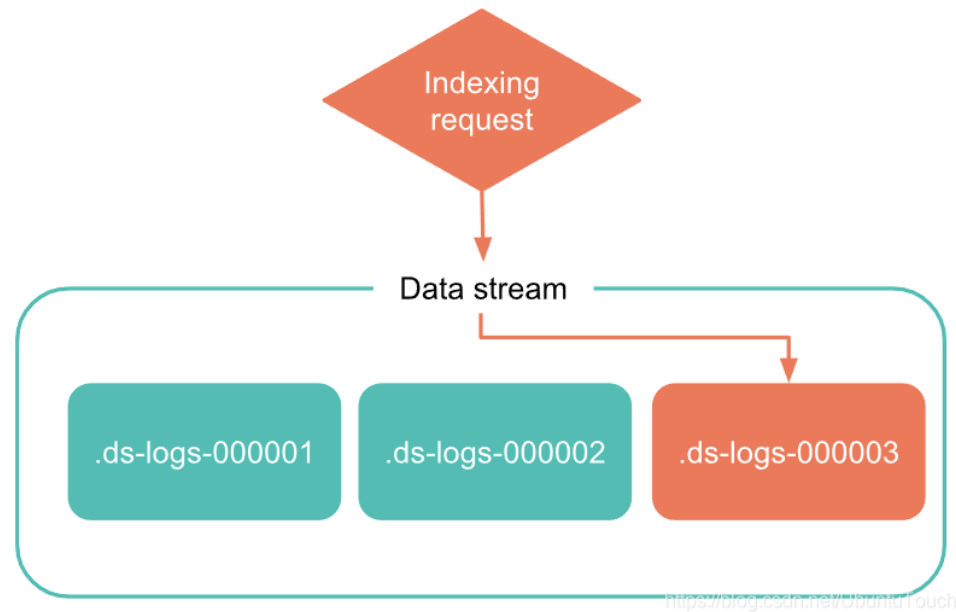
你不能將新檔案添加到其他支持索引,即使直接將請求發送到索引也是如此,
你也不能對可能阻礙寫索引執行如下的操作:
- Clone
- Close
- Delete
- Freeze
- Shrink
- Split
1.3.5、Rollover
創建資料流時,Elasticsearch 會自動為該流創建一個后備索引, 該索引還充當流的第一個寫入索引, rollover 會創建一個新的后備索引,該后備索引將成為流的新寫入索引,
我們建議當寫入索引達到指定的使用期限或大小時,使用 ILM 自動翻轉資料流, 如果需要,你還可以手動將資料 rollover,
1.3.6、Data Stream 生成
每個資料流都跟蹤其生成:一個六位數,零填充的整數,用作該流的 rollover 的累積計數,從 000001 開始,
創建支持索引時,將使用以下約定來命名該索引:
.ds-<data-stream>-<date>-<generation>
具有更高 generation 的后備索引包含更新的資料, 例如,web-server-logs 資料流有一個 generation 為 34,該流的最新后備索引名為 .ds-web-server-logs-000034,
某些操作(例如 shrink 或 restore)可以更改后備索引的名稱, 這些名稱更改不會從其資料流中洗掉后備索引,
1.3.7、只追加
資料流專為很少更新現有資料(如果有的話)的用例而設計, 你不能將對現有檔案的更新或洗掉請求直接發送到資料流, 而是使用 update by query 和 delete by query 洗掉,
如果需要,你可以通過直接向檔案的后備索引提交請求來更新或洗掉檔案,
提示:如果您經常更新或洗掉現有檔案,請使用索引別名和索引模板,而不要使用資料流, 你仍然可以使用 ILM 管理別名的索引,
2、Data Stream 演示
2.1、啟動 Elasticsearch 集群
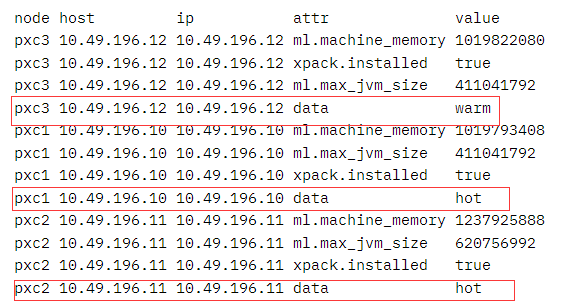
啟動三個節點(10.49.196.10、10.49.196.11、10.49.196.12)的集群,其中兩個為 hot 節點(存放 hot 階段的資料),一個為 warm 節點(存放 warm 階段的資料),
在 10.49.196.10、10.49.196.11 上運行:
bin/elasticsearch -d -E node.attr.data=https://www.cnblogs.com/wuyongyin/p/hot
在 10.49.196.12 上運行:
bin/elasticsearch -d -E node.attr.data=https://www.cnblogs.com/wuyongyin/p/warm
查看 node 屬性資訊:
GET _cat/nodeattrs?v
2.2、創建 Index Lifecycle Policy
PUT _ilm/policy/demo-policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "10mb", "max_age": "1d", "max_docs": 5 } } }, "warm": { "min_age": "5m", "actions": { "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 0, "require": { "data": "warm" } } } }, "delete": { "min_age": "10m", "actions": { "delete": {} } } } } }
這里定義的 policy 意思為:
熱階段
索引創建 1 天后、索引大小達到 10MB 或 索引檔案數達到 5(符合任何一個即可),該索引將滾動更新,系統將創建一個新索引,該新索引將重新啟動策略,而當前的索引(剛剛滾動更新的索引)將在滾動更新后等待 5 分鐘進入溫階段,
溫階段
索引進入溫階段后,ILM 會將索引收縮到 1 個分片 0 個副本,通過分配操作將索引移動到溫節點,完成該操作后,索引將再等待 5 分鐘 (時間都是從滾動跟新算起,10 - 5 = 5)后進入洗掉階段,
洗掉階段
洗掉階段具有用于洗掉索引的洗掉操作,在洗掉階段,您將始終需要有一個 min_age 條件,以允許索引在給定時段內待在熱、溫或冷階段,
2.3、創建 Index template
PUT _index_template/demo-template { "index_patterns": ["demo-*"], "data_stream": {}, "template": { "settings": { "index.lifecycle.name": "demo-policy", "index.lifecycle.rollover_alias": "demo-alias", "index.routing.allocation.require.data": "hot", "index": { "number_of_shards": 2, "number_of_replicas": 1 } }, "mappings": { "properties": { "@timestamp": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis" }, "age": { "type": "integer" }, "name": { "type": "keyword" }, "poems": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "about": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "success": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } } }
上面創建了一個名字為 demo-template 的 index template,data_stream 為一個空的 object;新建的索引在 hot 節點,分片為 2,副本為 1,
2.4、創建 Data Stream
PUT _data_stream/demo-ds
由于在上面已經創建了以 demo-* 為 index_pattern 的 index template,所以創建成功,
2.5、查看 Data Stream
GET _data_stream/demo-ds
{ "data_streams": [ { "name": "demo-ds", "timestamp_field": { "name": "@timestamp" }, "indices": [ { "index_name": ".ds-demo-ds-2022.07.12-000001", "index_uuid": "6YhZxvQLRpuiE14rbeUl4g" } ], "generation": 1, "status": "GREEN", "template": "demo-template", "ilm_policy": "demo-policy", "hidden": false, "system": false, "allow_custom_routing": false, "replicated": false } ] }
2.6、發送資料到 Data Stream
POST /demo-ds/_bulk { "create":{"_id":"1"} } {"@timestamp":"2022-07-07 10:51:21","age": 30,"name": "李白1","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度"} { "create":{"_id":"2"} } {"@timestamp":"2022-07-07 10:51:22","age": 30,"name": "李白2","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度"} { "create":{"_id":"3"} } {"@timestamp":"2022-07-07 10:51:23","age": 30,"name": "李白3","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度"} { "create":{"_id":"4"} } {"@timestamp":"2022-07-07 10:51:24","age": 30,"name": "李白4","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度"} { "create":{"_id":"5"} } {"@timestamp":"2022-07-07 10:51:25","age": 30,"name": "李白5","poems": "靜夜思","about": "字太白","success": "創造了古代浪漫主義文學高峰、歌行體和七絕達到后人難及的高度"}
2.7、rollover
已經有超過 5 個檔案了,將會 rollover;rollover 掃描間隔默認時 10 分鐘,可以通過修改 indices.lifecycle.poll_interval 引數來改變默認的間隔時間,

PUT _cluster/settings
{
"transient": {
"indices.lifecycle.poll_interval": "30s"
}
}
rollover 后會生成新的索引:
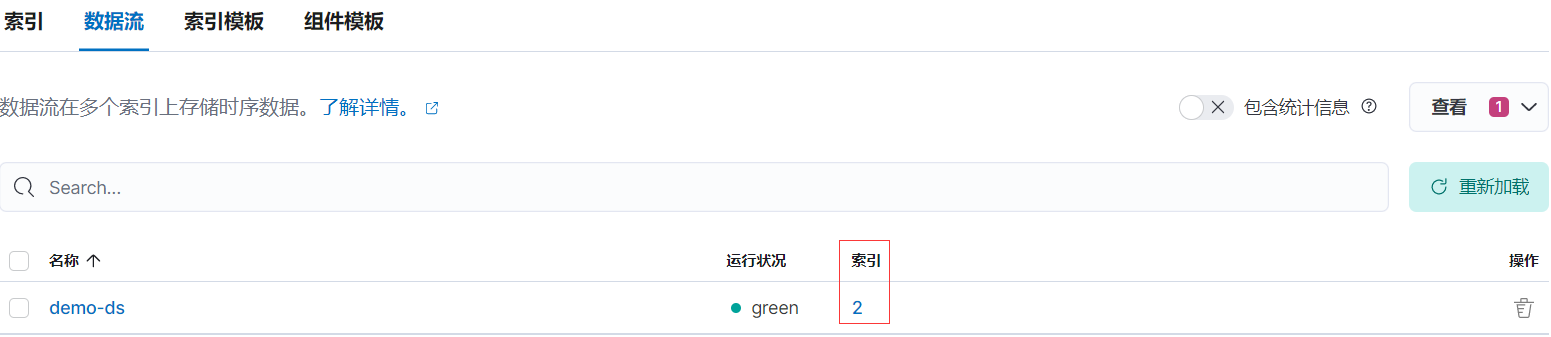
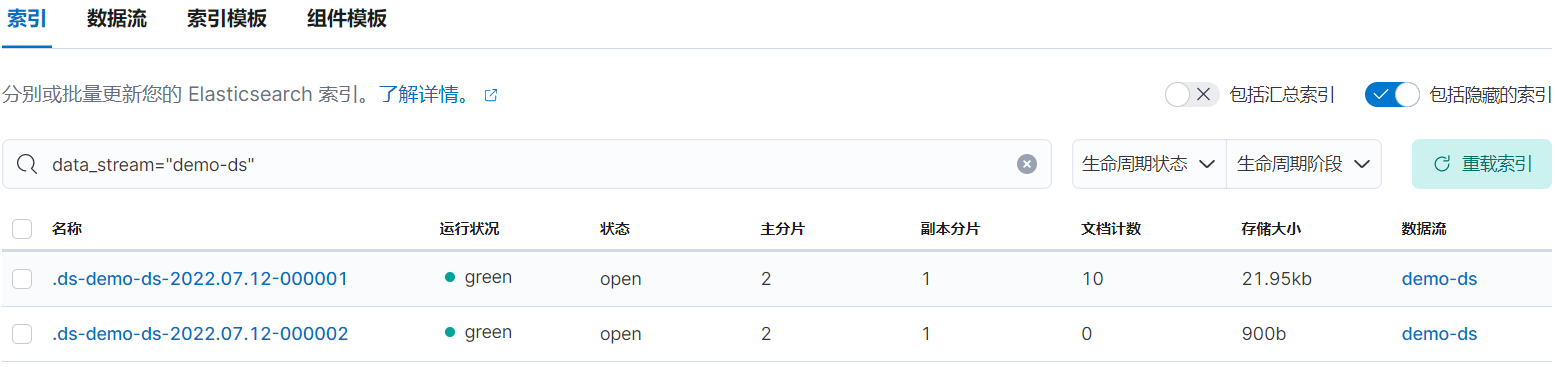
2.8、進入 warm 階段
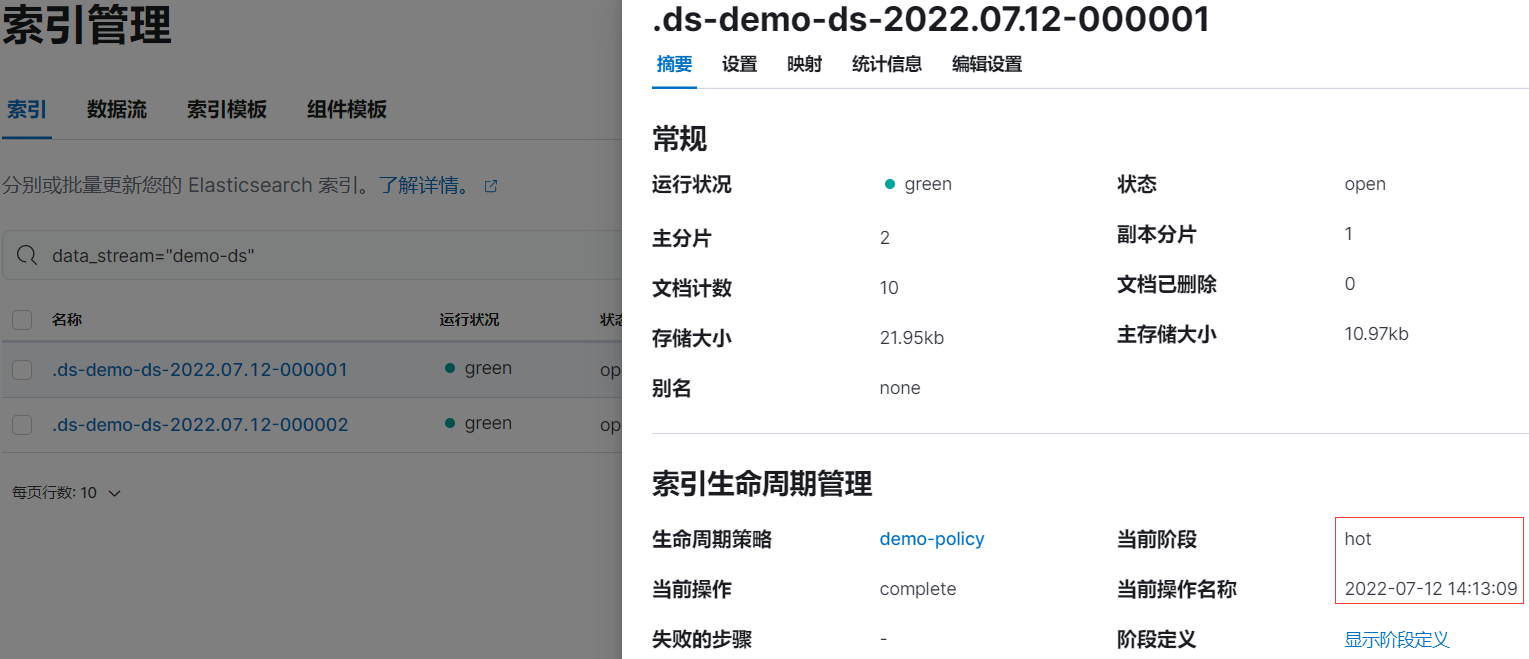
rollover 后,索引 .ds-demo-ds-2022.07.12-000001 等待 5 分鐘左右后將會進入 warm 階段,
rollover 后的情況:
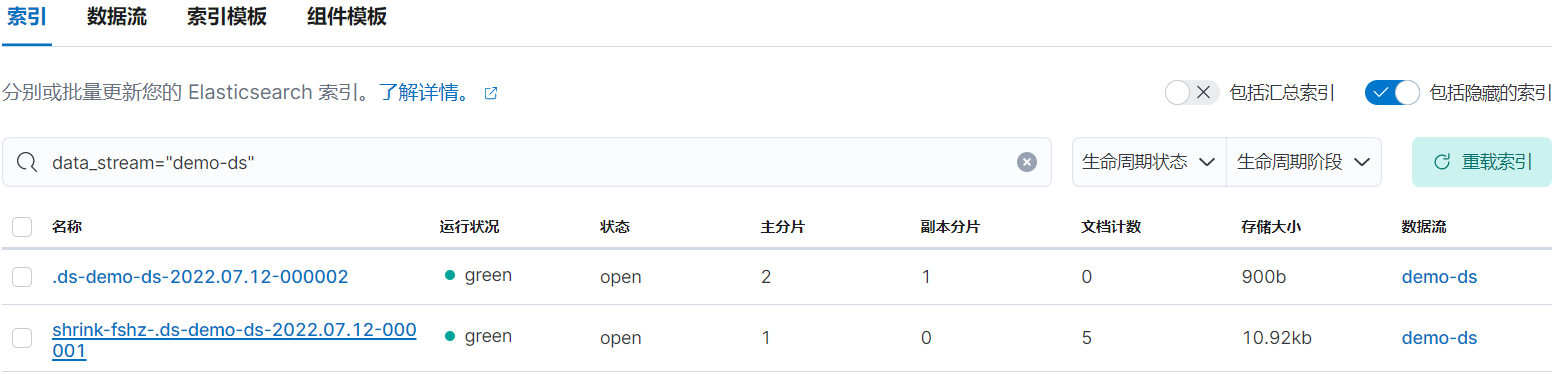
rollover 后等待 5 分鐘左右后,索引 .ds-demo-ds-2022.07.12-000001 已被重命名為 shrink-fshz-.ds-demo-ds-2022.07.12-000001:
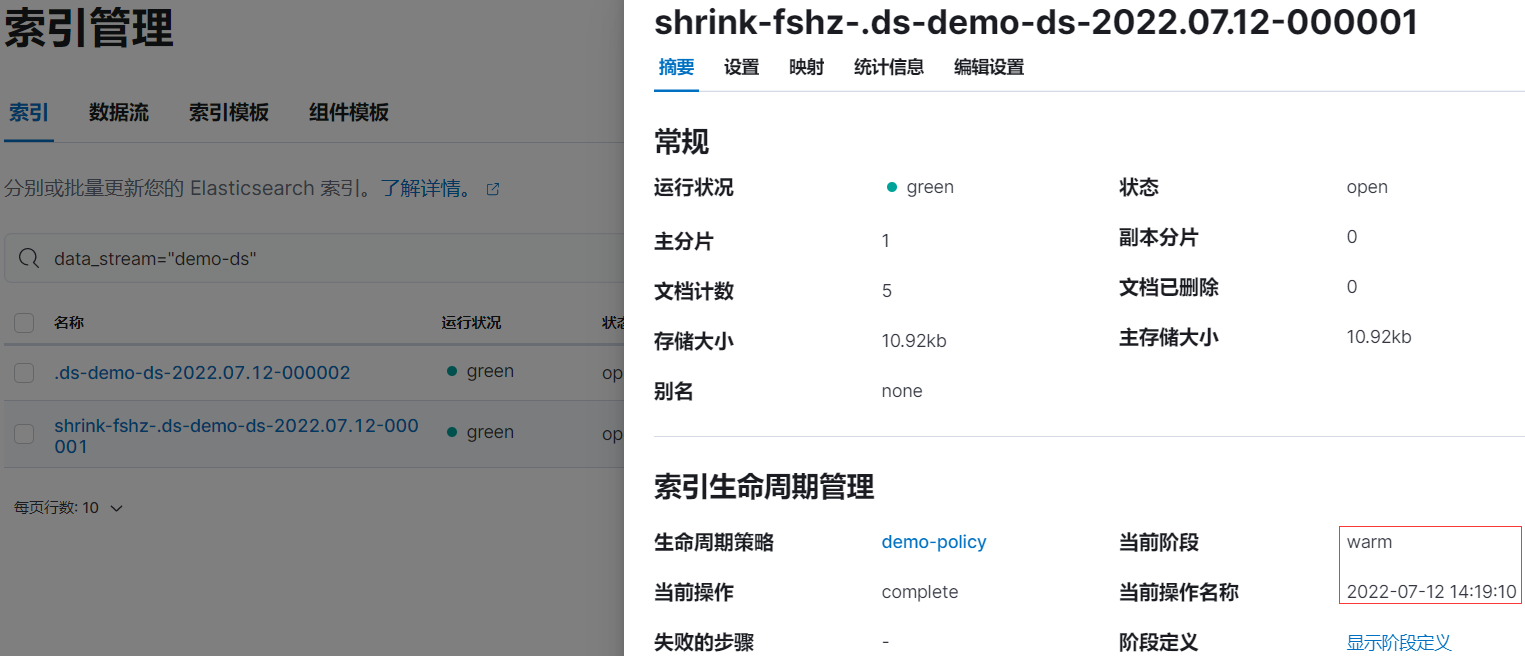
2.7、進入 delete 階段
在 warm 階段再等待 5 分鐘(10m - 5m)左右后, shrink-fshz-.ds-demo-ds-2022.07.12-000001 進入 delete 階段,索引將被洗掉,
參考:https://blog.csdn.net/UbuntuTouch/article/details/110528838
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/501154.html
標籤:Java
上一篇:12-Java中執行緒的狀態型別