
1、應用場景
1.1 kafka場景
? Kafka最初是由LinkedIn公司采用Scala語言開發,基于ZooKeeper,現在已經捐獻給了Apache基金會,目前Kafka已經定位為一個分布式流式處理平臺,它以 高吞吐、可持久化、可水平擴展、支持流處理等多種特性而被廣泛應用,
? Apache Kafka能夠支撐海量資料的資料傳遞,在離線和實時的訊息處理業務系統中,Kafka都有廣泛的應用,
(1)日志收集:收集各種服務的log,通過kafka以統一介面服務的方式開放 給各種consumer,例如Hadoop、Hbase、Solr等;
(2)訊息系統:解耦和生產者和消費者、快取訊息等;
(3)用戶活動跟蹤:Kafka經常被用來記錄web用戶或者app用戶的各種活動,如瀏覽網頁、搜索、點 擊等活動,這些活動資訊被各個服務器發布到kafka的topic中,然后訂閱者通過訂閱這些topic來做實時 的監控分析,或者裝載到Hadoop、資料倉庫中做離線分析和挖掘;
(4)運營指標:Kafka也經常用來記錄運營監控資料,包括收集各種分布式應用的資料,生產各種操作 的集中反饋,比如報警和報告;
(5)流式處理:比如spark streaming和storm;
1.2 kafka特性
kafka以高吞吐量著稱,主要有以下特性:
(1)高吞吐量、低延遲:kafka每秒可以處理幾十萬條訊息,它的延遲最低只有幾毫秒;
(2)可擴展性:kafka集群支持熱擴展;
(3)持久性、可靠性:訊息被持久化到本地磁盤,并且支持資料備份防止資料丟失;
(4)容錯性:允許集群中節點失敗(若副本數量為n,則允許n-1個節點失敗);
(5)高并發:支持數千個客戶端同時讀寫;
1.3 訊息對比
- 如果普通的業務訊息解耦,訊息傳輸,rabbitMq是首選,它足夠簡單,管理方便,性能夠用,
- 如果在上述,日志、訊息收集、訪問記錄等高吞吐,實時性場景下,推薦kafka,它基于分布式,擴容便捷
- 如果很重的業務,要做到極高的可靠性,考慮rocketMq,但是它太重,需要你有足夠的了解
1.4 大廠應用
- 京東通過kafka搭建資料平臺,用于用戶購買、瀏覽等行為的分析,成功抗住6.18的流量洪峰
- 阿里借鑒kafka的理念,推出自己的rocketmq,在設計上參考了kafka的架構體系
2、基礎組件
2.1 角色
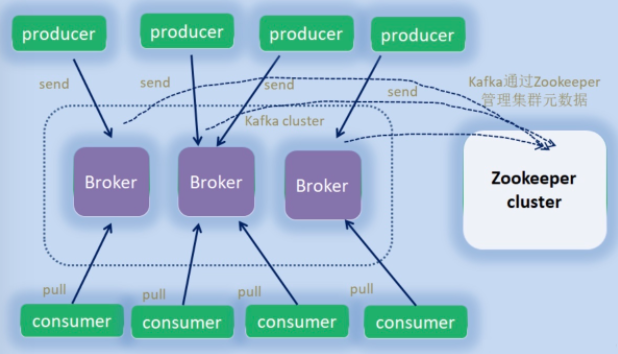
-
broker:節點,就是你看到的機器
-
provider:生產者,發訊息的
-
consumer:消費者,讀訊息的
-
zookeeper:資訊中心,記錄kafka的各種資訊的地方
-
controller:其中的一個broker,作為leader身份來負責管理整個集群,如果掛掉,借助zk重新選主
2.2 邏輯組件
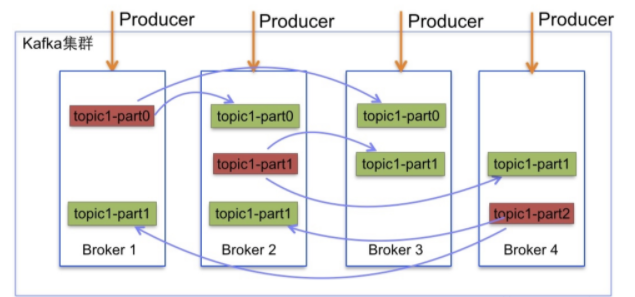
-
topic:主題,一個訊息的通道,收發總得知道訊息往哪投
-
partition:磁區,每個主題可以有多個磁區分擔資料的傳遞,多條路并行,吞吐量大
-
Replicas:副本,每個磁區可以設定多個副本,副本之間資料一致,相當于備份,有備胎更可靠
-
leader & follower:主從,上面的這些副本里有1個身份為leader,其他的為follower,leader處理partition的所有讀寫請求
2.3 副本集合
-
AR:所有副本的統稱,AR=ISR+OSR
-
ISR:同步中的副本,可以參與leader選主,一旦落后太多(數量滯后和時間滯后兩個維度)會被踢到OSR,
-
OSR:踢出同步的副本,一直追趕leader,追上后會進入ISR
2.4 訊息標記
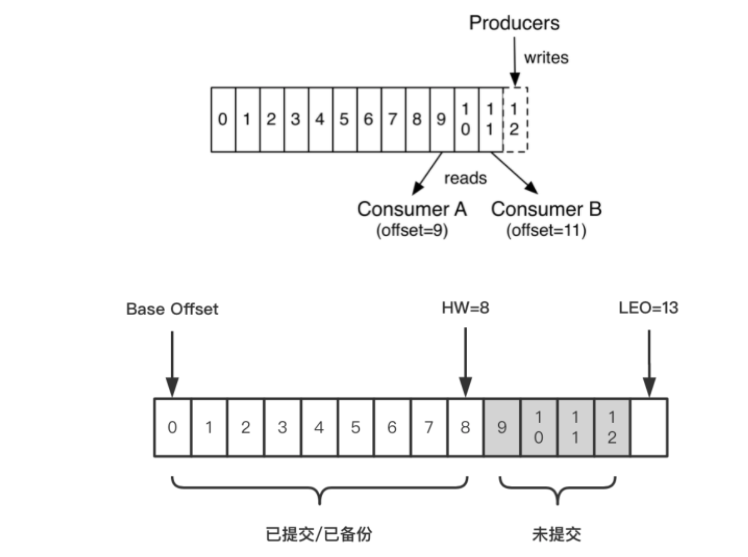
- offset:偏移量,訊息消費到哪一條了?每個消費者都有自己的偏移量
- HW:(high watermark):副本的高水印值,客戶端最多能消費到的位置,HW值為8,代表offset為[0,8]的9條訊息都可以被消費到,它們是對消費者可見的,而[9,12]這4條訊息由于未提交,對消費者是不可見的,
- LEO:(log end offset):日志末端位移,代表日志檔案中下一條待寫入訊息的offset,這個offset上實際是沒有訊息的,不管是leader副本還是follower副本,都有這個值,
那么這三者有什么關系呢?
比如在副本數等于3的情況下,訊息發送到Leader A之后會更新LEO的值,Follower B和Follower C也會實時拉取Leader A中的訊息來更新自己,HW就表示A、B、C三者同時達到的日志位移,也就是A、B、C三者中LEO最小的那個值,由于B、C拉取A訊息之間延時問題,所以HW一般會小于LEO,即LEO>=HW,
具體的同步原理,下面章節會詳細講到
3.1 發展歷程
http://kafka.apache.org/downloads
3.1.1 版本命名
Kafka在1.0.0版本前的命名規則是4位,比如0.8.2.1,0.8是大版本號,2是小版本號,1表示打過1個補丁
現在的版本號命名規則是3位,格式是“大版本號”+“小版本號”+“修訂補丁數”,比如2.5.0,前面的2代表的是大版本號,中間的5代表的是小版本號,0表示沒有打過補丁
我們所看到的下載包,前面是scala編譯器的版本,后面才是真正的kafka版本,
3.1.2 演進歷史
0.7版本
只提供了最基礎的訊息佇列功能,
0.8版本
引入了副本機制,至此Kafka成為了一個真正意義上完備的分布式高可靠訊息佇列解決方案,
0.9版本
增加權限和認證,使用Java重寫了新的consumer API,Kafka Connect功能;不建議使用consumer API;
0.10版本
引入Kafka Streams功能,正式升級成分布式流處理平臺;建議版本0.10.2.2;建議使用新版consumer API
0.11版本
producer API冪等,事務API,訊息格式重構;建議版本0.11.0.3;謹慎對待訊息格式變化
1.0和2.0版本
Kafka Streams改進;建議版本2.0;
3.2 集群搭建(助學)
1)原生啟動
kafka啟動需要zookeeper,第一步啟動zk:
docker run --name zookeeper-1 -d -p 2181 zookeeper:3.4.13
原生安裝:下載后解壓啟動即可 http://kafka.apache.org/downloads
bin/kafka-server-start.sh config/server.properties
#server.properties配置說明
#表示broker的編號,如果集群中有多個broker,則每個broker的編號需要設定的不同
broker.id=0
#brokder對外提供的服務入口地址,默認9092
listeners=PLAINTEXT://:9092
#設定存放訊息日志檔案的地址
log.dirs=/tmp/kafka/log
#Kafka所需Zookeeper集群地址,這里是關鍵!加入同一個zk的kafka為同一集群
zookeeper.connect=zookeeper:2181
2)推薦docker-compose 一鍵啟動
#參考資料中的kafka.yml
#注意hostname問題,ip地址:52.82.98.209,換成你自己服務器的
#docker-compose -f kafka.yml up -d 啟動
version: '3'
services:
zookeeper:
image: zookeeper:3.4.13
kafka-1:
container_name: kafka-1
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10903:9092
environment:
KAFKA_BROKER_ID: 1
HOST_IP: 52.82.98.209
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
#docker部署必須設定外部可訪問ip和埠,否則注冊進zk的地址將不可達造成外部無法連接
KAFKA_ADVERTISED_HOST_NAME: 52.82.98.209
KAFKA_ADVERTISED_PORT: 10903
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
kafka-2:
container_name: kafka-2
image: wurstmeister/kafka:2.12-2.2.2
ports:
- 10904:9092
environment:
KAFKA_BROKER_ID: 2
HOST_IP: 52.82.98.209
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_HOST_NAME: 52.82.98.209
KAFKA_ADVERTISED_PORT: 10904
volumes:
- /etc/localtime:/etc/localtime
depends_on:
- zookeeper
3.3 組件探秘
命令列工具是管理kafka集群最直接的工具,官方自帶,不需要額外安裝,
3.2.1 主題創建
#進入容器
docker exec -it kafka-1 sh
#進入bin目錄
cd /opt/kafka/bin
#創建
kafka-topics.sh --zookeeper zookeeper:2181 --create --topic test --partitions 2 --replication-factor 1
3.2.2 查看主題
kafka-topics.sh --zookeeper zookeeper:2181 --list
3.2.3 主題詳情
kafka-topics.sh --zookeeper zookeeper:2181 --describe --topic test
#分析輸出:
Topic:test PartitionCount:2 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: test Partition: 1 Leader: 1 Replicas: 1 Isr: 1
3.2.4 訊息收發
#使用docker連接任意集群中的一個容器
docker exec -it kafka-1 sh
#進入kafka的容器內目錄
cd /opt/kafka/bin
#客戶端監聽
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test
#另起一個終端,驗證發送
./kafka-console-producer.sh --broker-list localhost:9092 --topic test
3.2.5 分組消費
#啟動兩個consumer時,如果不指定group資訊,訊息被廣播
#指定相同的group,讓多個消費者分工消費(畫圖:group原理)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group aaa
#結果:在發送方,連續發送 1-4 ,4條訊息,同一group下的兩臺consumer交替消費,并發執行
注意!!!
這是在消費者和磁區數相等(都是2)的情況下,
如果同一group下的 ( 消費者數量 > 磁區數量 ) 那么就會有消費者閑置,
驗證方式:
可以再多啟動幾個消費者試一試,會發現,超出2個的時候,有的始終不會消費到訊息,
停掉可以消費到的,那么閑置的會被激活,進入作業狀態
3.2.6 指定磁區
#指定磁區通過引數 --partition,注意!需要去掉上面的group
#指定磁區的意義在于,保障訊息傳輸的順序性(畫圖:kafka順序性原理)
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 1
#結果:發送1-4條訊息,交替出現,說明訊息被均分到各個磁區中投遞
#默認的發送是沒有指定key的
#要指定磁區發送,就需要定義key,那么相同的key被路由到同一個磁區
./kafka-console-producer.sh --broker-list kafka-1:9092 --topic test --property parse.key=true
#攜帶key再發送,注意key和value之間用tab分割
>1 1111
>1 2222
>2 3333
>2 4444
#查看consumer的接收情況
#結果:相同的key被同一個consumer消費掉
3.2.7 偏移量
#偏移量決定了訊息從哪開始消費,支持:開頭,還是末尾
# earliest:當各磁區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,從頭開始消費
# latest:當各磁區下有已提交的offset時,從提交的offset開始消費;無提交的offset時,消費新產生的該磁區下的資料
# none:topic各磁區都存在已提交的offset時,從offset后開始消費;只要有一個磁區不存在已提交的offset,則拋出例外
# 注意點!!!有提交偏移量的話,仍然以提交的為主,即便使用earliest,比提交點更早的也不會被提取
#--offset [earliest|latest(默認)] , 或者 --from-beginning
#新起一個終端,指定offset位置
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --offset earliest
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --partition 0 --from-beginning
#結果:之前發送的訊息,從頭又消費了一遍!
3.4 zk探秘
前面說過,zk存盤了kafka集群的相關資訊,本節來探索內部的秘密,
kafka的資訊記錄在zk中,進入zk容器,查看相關節點和資訊
docker exec -it kafka_zookeeper_1 sh
>./bin/zkCli.sh
>ls /
#結果:得到以下配置資訊
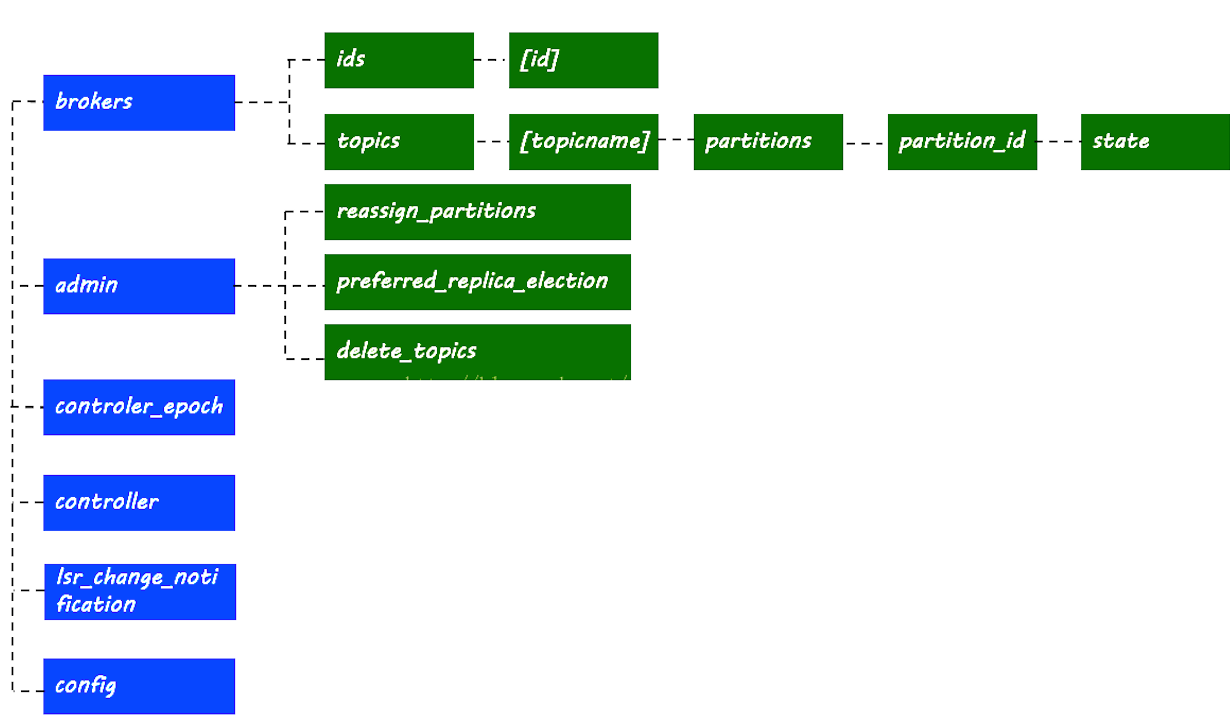
3.4.1 broker資訊
[zk: localhost:2181(CONNECTED) 0] ls /brokers
[ids, topics, seqid]
[zk: localhost:2181(CONNECTED) 1] ls /brokers/ids
[1, 2]
#機器broker資訊
[zk: localhost:2181(CONNECTED) 4] get /brokers/ids/1
{"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://52.82.98.209:10903"],"jmx_port":-1,"host":"52.82.98.209","timestamp":"1609825245500","port":10903,"version":4}
cZxid = 0x27
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x27
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x27
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 196
numChildren = 0
3.4.2 主題與磁區
#磁區節點路徑
[zk: localhost:2181(CONNECTED) 5] ls /brokers/topics
[test, __consumer_offsets]
[zk: localhost:2181(CONNECTED) 6] ls /brokers/topics/test
[partitions]
[zk: localhost:2181(CONNECTED) 7] ls /brokers/topics/test/partitions
[0, 1]
[zk: localhost:2181(CONNECTED) 8] ls /brokers/topics/test/partitions/0
[state]
#磁區資訊,leader所在的機器id,isr串列等
[zk: localhost:2181(CONNECTED) 18] get /brokers/topics/test/partitions/0/state
{"controller_epoch":1,"leader":1,"version":1,"leader_epoch":0,"isr":[1]}
cZxid = 0xb0
ctime = Tue Jan 05 05:56:06 GMT 2021
mZxid = 0xb0
mtime = Tue Jan 05 05:56:06 GMT 2021
pZxid = 0xb0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 72
numChildren = 0
3.4.3 消費者與偏移量
[zk: localhost:2181(CONNECTED) 15] ls /consumers
[]
#空的???
#那么,消費者以及它的偏移記在哪里呢???
kafka 消費者記錄 group 的消費 偏移量 有兩種方式 :
1)kafka 自維護 (新)
2)zookpeer 維護 (舊) ,已經逐漸被廢棄
查看方式:
上面的消費用的是控制臺工具,這個工具使用--bootstrap-server,不經過zk,也就不會記錄到/consumers下,
其消費者的offset會更新到一個kafka自帶的topic【__consumer_offsets】下面
#先起一個消費端,指定group
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --group aaa
#使用控制臺工具查看消費者及偏移量情況
./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --list
KMOffsetCache-44acff134cad
aaa
#查看偏移量詳情
./kafka-consumer-groups.sh --bootstrap-server kafka-1:9092 --describe --group aaa
當前與LEO保持一致,說明訊息都完整的被消費過

停掉consumer后,往provider中再發幾條記錄,offset開始滯后:

重新啟動consumer,消費到最新的訊息,同時再回傳看偏移量,訊息得到同步:

3.4.4 controller
#當前集群中的主控節點是誰
[zk: localhost:2181(CONNECTED) 17] get /controller
{"version":1,"brokerid":1,"timestamp":"1609825245694"}
cZxid = 0x2a
ctime = Tue Jan 05 05:40:45 GMT 2021
mZxid = 0x2a
mtime = Tue Jan 05 05:40:45 GMT 2021
pZxid = 0x2a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x105a2db626b0000
dataLength = 54
numChildren = 0
3.5 km
3.5.1 啟動
kafka-manager是目前最受歡迎的kafka集群管理工具,最早由雅虎開源,提供可視化kafka集群操作
官網:https://github.com/yahoo/kafka-manager/releases
注意它的版本,docker社區的景象版本滯后于kafka,我們自己來打鏡像,
#Dockerfile
FROM daocloud.io/library/java:openjdk-8u40-jdk
ADD kafka-manager-2.0.0.2/ /opt/km2002/
CMD ["/opt/km2002/bin/kafka-manager","-Dconfig.file=/opt/km2002/conf/application.conf"]
#打包,注意將kafka-manager-2.0.0.2放到同一目錄
docker build -t km:2002 .
#啟動:在上面的yml里,services節點下加一段
#參考資料:km.yml
#執行: docker-compose -f km.yml up -d
km:
image: km:2002
ports:
- 10906:9000
depends_on:
- zookeeper
3.5.2 使用
使用km可以方便的查看以下資訊:
- cluster:創建集群,填寫zk地址,選中jmx,consumer資訊等選項
- brokers:串列,機器資訊
- topic:主題資訊,主題內的磁區資訊,創建新的主題,增加磁區
- cosumers: 消費者資訊,偏移量等
本文由傳智教育博學谷 - 狂野架構師教研團隊發布
如果本文對您有幫助,歡迎關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/501597.html
標籤:其他