底層架構
先停一下,學習之前,先看下如何學習,兩篇不錯的干貨文章分享給你,一定要點開看下
-
如何從普通程式員,進階架構師!
-
作業幾年?如何快速晉升架構師!!
6.1 存盤架構
6.1.1 分段存盤
開篇講過,kafka每個主題可以有多個磁區,每個磁區在它所在的broker上創建一個檔案夾
每個磁區又分為多個段,每個段兩個檔案,log檔案里順序存訊息,index檔案里存訊息的索引
段的命名直接以當前段的第一條訊息的offset為名
注意是偏移量,不是序號! 第幾條訊息 = 偏移量 + 1,類似陣列長度和下標,
所以offset從0開始(可以開新佇列新groupid消費第一條訊息列印offset得到驗證)

例如:
0.log -> 有8條,offset為 0-7
8.log -> 有兩條,offset為 8-9
10.log -> 有xx條,offset從10-xx

6.1.2 日志索引
每個log檔案配備一個索引檔案 *.index
檔案格式為: (offset , 記憶體偏移地址)
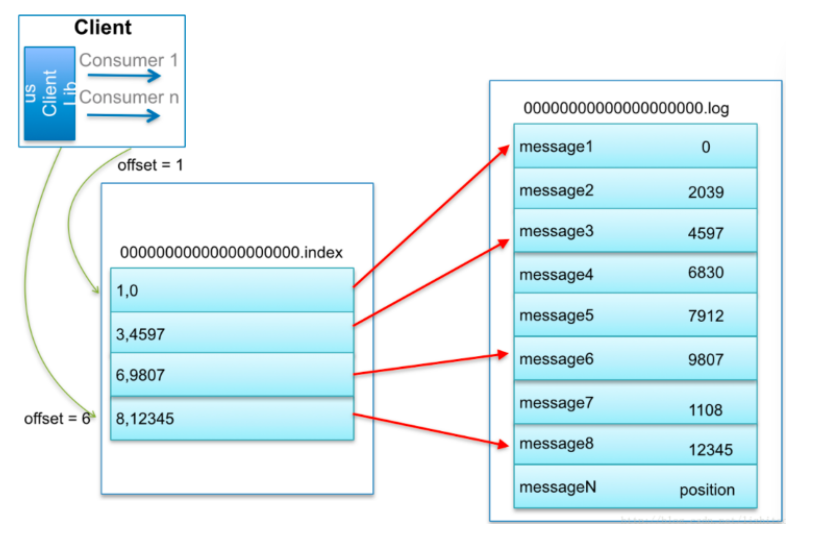
綜合上述,來看一個訊息的查找:
- consumer發起請求要求從offset=6的訊息開始消費
- kafka直接根據檔案名大小,發現6號訊息在00000.log這個檔案里
- 那檔案找到了,它在檔案的哪個位置呢?
- 根據index檔案,發現 6,9807,說明訊息藏在這里!
- 從log檔案的 9807 位置開始讀取,
- 那讀多長呢?簡單,讀到下一條訊息的偏移量停止就可以了
6.1.3 日志洗掉
Kafka作為訊息中間件,資料需要按照一定的規則洗掉,否則資料量太大會把集群存盤空間占滿,
洗掉資料方式:
- 按照時間,超過一段時間后洗掉過期訊息
- 按照訊息大小,訊息數量超過一定大小后洗掉最舊的資料
Kafka洗掉資料的最小單位:segment,也就是直接干掉檔案!一刪就是一個log和index檔案
6.1.4 存盤驗證
1)資料準備
將broker 2和3 停掉,只保留1
docker pause kafka-2 kafka-3
2)刪掉test主題,通過km新建一個test主題,加2個磁區
新建時,注意下面的選項:
segment.bytes = 1000 ,即:每個log檔案到達1000byte時,開始創建新檔案
洗掉策略:
retention.bytes = 2000,即:超出2000byte的舊日志被洗掉
retention.ms = 60000,即:超出1分鐘后的舊日志被洗掉
以上任意一條滿足,就會洗掉,
3)進入kafka-1這臺容器
docker exec -it kafka-1 sh
#查看容器中的檔案資訊
/ # ls /
bin dev etc home kafka lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
/ # cd /kafka/
/kafka # ls
kafka-logs-d0b9c75080d6
/kafka # cd kafka-logs-d0b9c75080d6/
/kafka/kafka-logs-d0b9c75080d6 # ls -l | grep test
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-0
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-1
#2個磁區的日志檔案清單,注意當前還沒有任何訊息寫進來
#timeindex:日志的時間資訊
#leader-epoch,下面會講到
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
4)往里灌資料,啟動專案通過swagger發送訊息
注意!邊發送邊查看上一步的檔案串列資訊!

#先發送2條,訊息開始進來,log檔案變大!訊息在兩個磁區之間逐個增加,
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#繼續逐條發送,回傳再來看檔案,大小為1000,到達邊界!
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#繼續發送訊息!1號磁區的log檔案開始分裂
#說明第8條訊息已經進入了第二個log
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 125 Jan 15 14:46 00000000000000000008.log #第二個log檔案!
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持續發送,另一個磁區也開始分離
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 20
-rw-r--r-- 1 root root 0 Jan 15 15:55 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 15:55 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 15:55 00000000000000000008.index
-rw-r--r-- 1 root root 625 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 15:55 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 15:55 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 750 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持續發送訊息,磁區越來越多,
#過一段時間后再來查看,清理任務將會執行,超出的日志被洗掉!(默認調度間隔5min)
#log.retention.check.interval.ms 引數指定
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
6.2 零拷貝
Kafka 在執行訊息的寫入和讀取這么快,其中的一個原因是零拷貝(Zero-copy)技術
6.2.1 傳統檔案讀寫
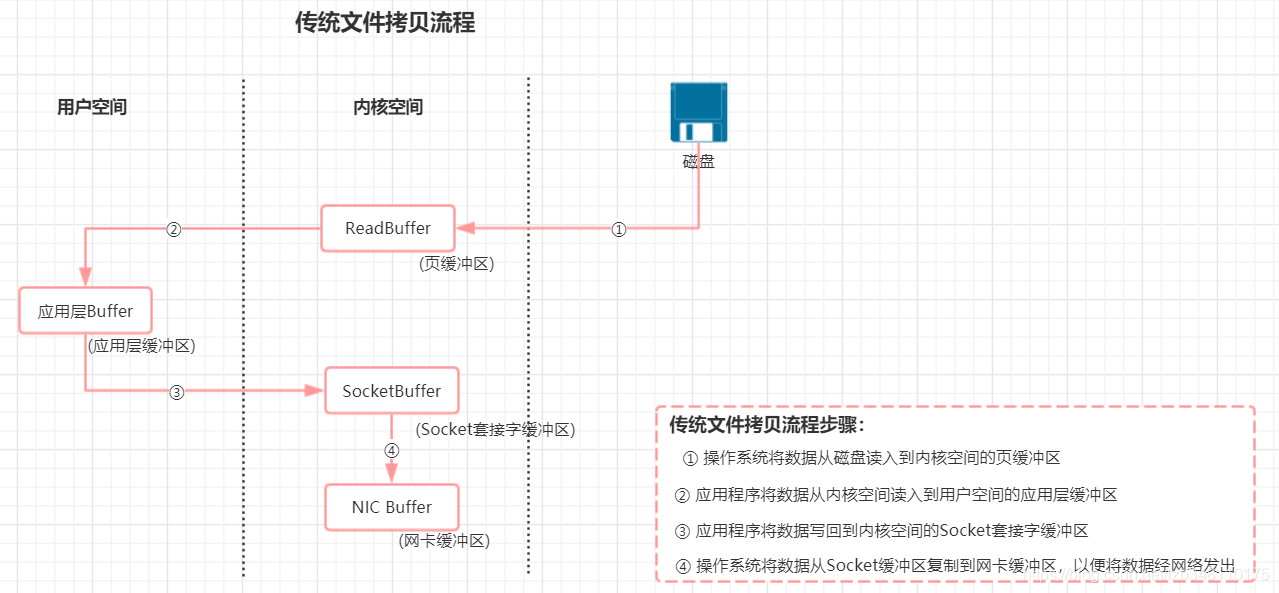
傳統讀寫,涉及到 4 次資料的復制,但是這個程序中,資料完全沒有變化,我們僅僅是想從磁盤把資料送到網卡,
那有沒有辦法不繞這一圈呢?讓磁盤和網卡之類的外圍設備直接訪問記憶體,而不經過cpu?
有! 這就是DMA(Direct Memory Access 直接記憶體訪問),
6.2.2 DMA
DMA其實是由DMA芯片(硬體支持)來控制的,通過DMA控制芯片,可以讓網卡等外部設備直接去讀取記憶體,而不是由cpu來回拷貝傳輸,這就是所謂的零拷貝
目前計算機主流硬體基本都支持DMA,就包括我們的硬碟和網卡,
kafka就是調取作業系統的sendfile,借助DMA來實作零拷貝資料傳輸的
6.2.3 java實作
為加深理解,類比為java中的零拷貝:
-
在Java中的零拷貝是通過java.nio.channels.FileChannel中的transferTo方法來實作的
-
transferTo方法底層通過native調作業系統的sendfile
-
作業系統sendfile負責把資料從某個fd(linux file descriptor)傳輸到另一個fd
備注:linux下所有的設備都是一個檔案描述符fd
代碼參考:
File file = new File("0.log");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
//檔案通道,來源
FileChannel fileChannel = raf.getChannel();
//網路通道,去處
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("1.1.1.1", 1234));
//對接上,通過transfer直接送過去
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
6.3 磁區一致性
6.3.1 水位值
1)先回顧兩個值:
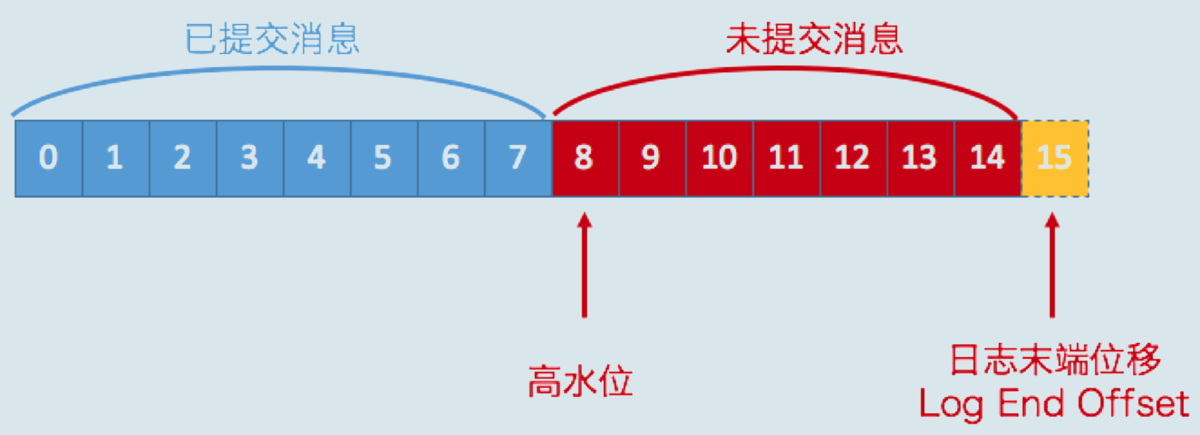
2)再看下幾個值的存盤位置:
注意!磁區是有leader和follower的,最新寫的訊息會進入leader,follower從leader不停的同步
無論leader還是follower,都有自己的HW和LEO,存盤在各自磁區所在的磁盤上
leader多一個Remote LEO,它表示針對各個follower的LEO,leader又額外記了一份!
3)為什么這么做呢?
leader會拿這些remote值里最小的來更新自己的hw,具體程序我們詳細往下看
6.3.2 同步原理
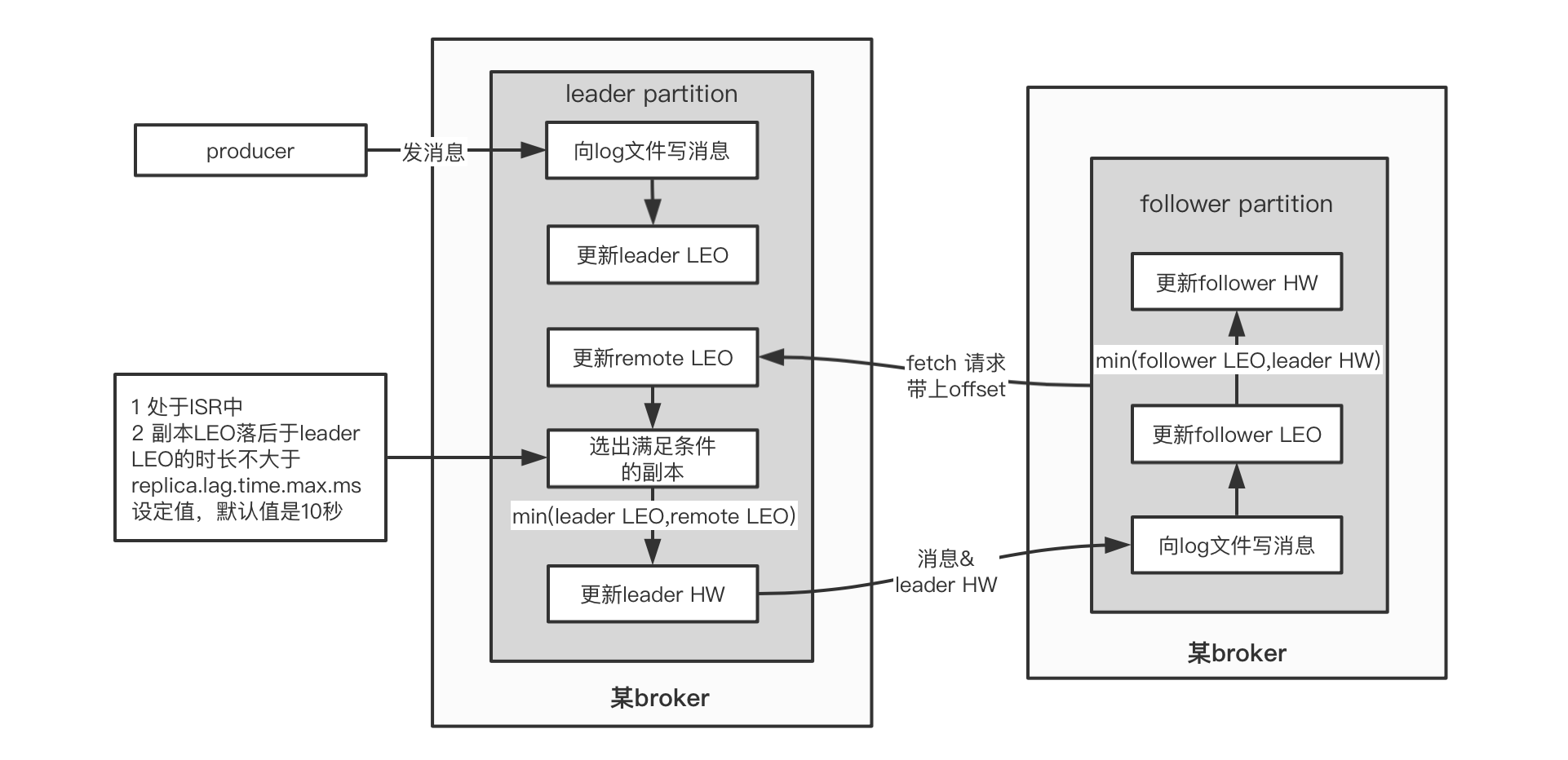
我們來看這幾個值是如何更新的:
1)leader.LEO
這個很簡單,每次producer有新訊息發過來,就會增加
2)其他值
另外的4個值初始化都是 0
他們的更新由follower的fetch(同步訊息執行緒)得到的資料來決定!
如果把fetch看做是leader上提供的方法,由follower遠程請求呼叫,那么它的偽代碼大概是這個樣子:
//java偽代碼!
//follower端的操作,不停的請求從leader獲取最新資料
class Follower{
private List<Message> messages;
private HW hw;
private LEO leo;
@Schedule("不停的向leader發起同步請求")
void execute(){
//向leader發起fetch請求,將自己的leo傳過去
//leader回傳leo之后最新的訊息,以及leader的hw
LeaderReturn lr = leader.fetch(this.leo) ;
//存訊息
this.messages.addAll(lr.newMsg);
//增加follower的leo值
this.leo = this.leo + lr.newMsg.length;
//比較自己的leo和leader的hw,取兩者小的,作為follower的hw
this.hw = min(this.leo , lr.leaderHW);
}
}
//leader回傳的報文
class LeaderReturn{
//新增的訊息
List<Messages> newMsg;
//leader的hw
HW leaderHW;
}
//leader在接到follower的fetch請求時,做的邏輯
class Leader{
private List<Message> messages;
private LEO leo;
private HW hw;
//Leader比follower多了個Remote!
//注意!如果有多個副本,那么RemoteLEO也有多個,每個副本對應一個
private RemoteLEO remoteLEO;
//接到follower的fetch請求時,leader做的事情
LeaderReturn fetch(LEO followerLEO){
//根據follower傳過來的leo,來更新leader的remote
this.remoteLEO = followerLEO ;
//然后取ISR(所有可用副本)的最小leo作為leader的hw
this.hw = min(this.leo , this.remoteLEO) ;
//從leader的訊息串列里,查找大于follower的leo的所有新訊息
List<Message> newMsg = queryMsg(followerLEO) ;
//將最新的訊息(大于follower leo的那些),以及leader的hw回傳給follower
LeaderReturn lr = new LeaderReturn(newMsg , this.hw)
return lr;
}
}
6.3.3 Leader Epoch
1)產生的背景
0.11版本之前的kafka,完全借助hw作為訊息的基準,不管leo,
發生故障后的規則:
- follower故障再次恢復后,從磁盤讀取hw的值并從hw開始剔除后面的訊息,并同步leader訊息
- leader故障后,新當選的leader的hw作為新的磁區hw,其余節點按照此hw進行剔除資料,并重新同步
- 上述根據hw進行資料恢復會出現資料丟失和不一致的情況,下面分開來看
假設:
我們有兩個副本:leader(A),follower(B)
場景一:丟資料
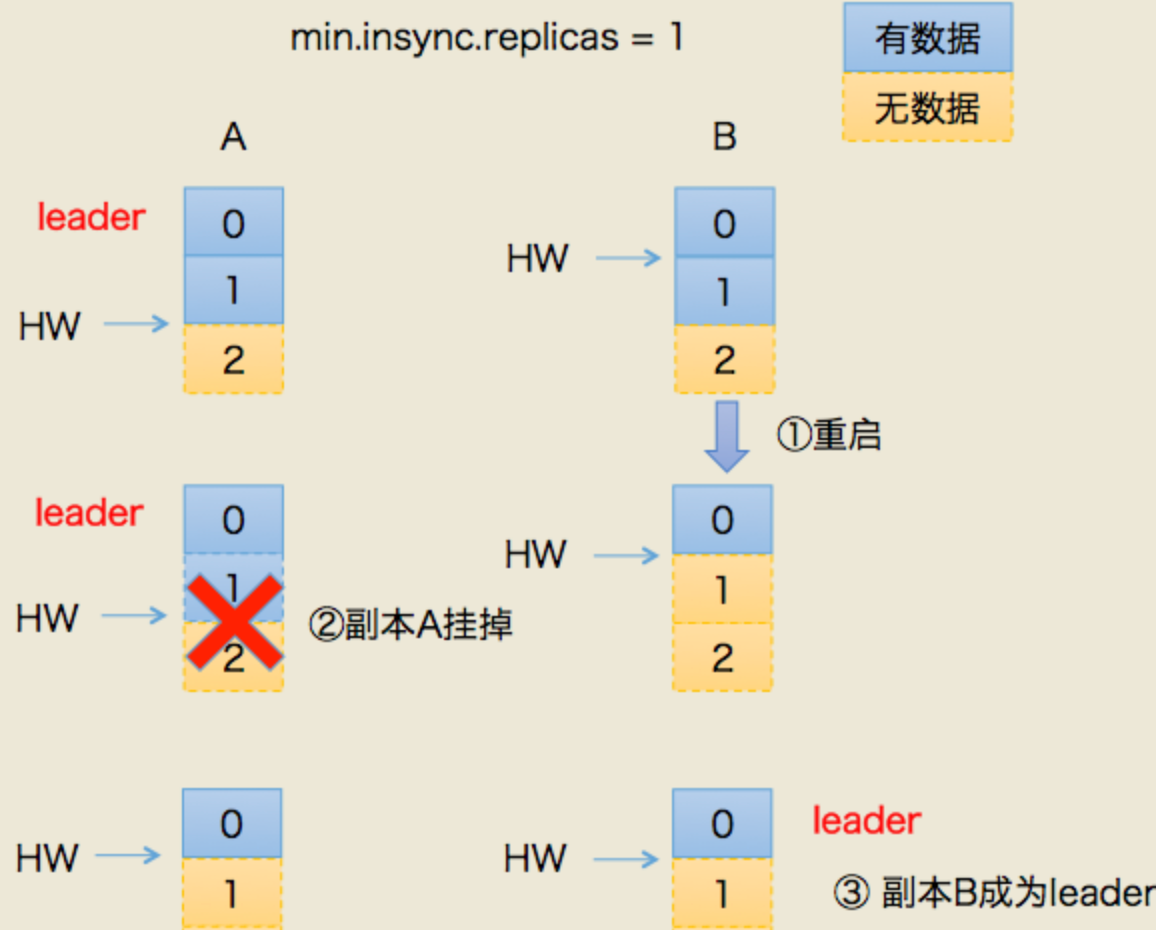
- 某個時間點B掛了,當它恢復后,以掛之前的hw為準,設定 leo = hw
- 這就造成一個問題:現實中,leo 很可能是 大于 hw的,leo被回退了!
- 如果這時候,恰恰A也掛掉了,kafka會重選leader,B被選中,
- 過段時間,A恢復后變成follower,從B開始同步資料,
- 問題來了!上面說了,B的資料是被回退過的,以它為基準會有問題
- 最終結果:兩者的資料都發生丟失,沒有地方可以找回!
場景二:資料不一致
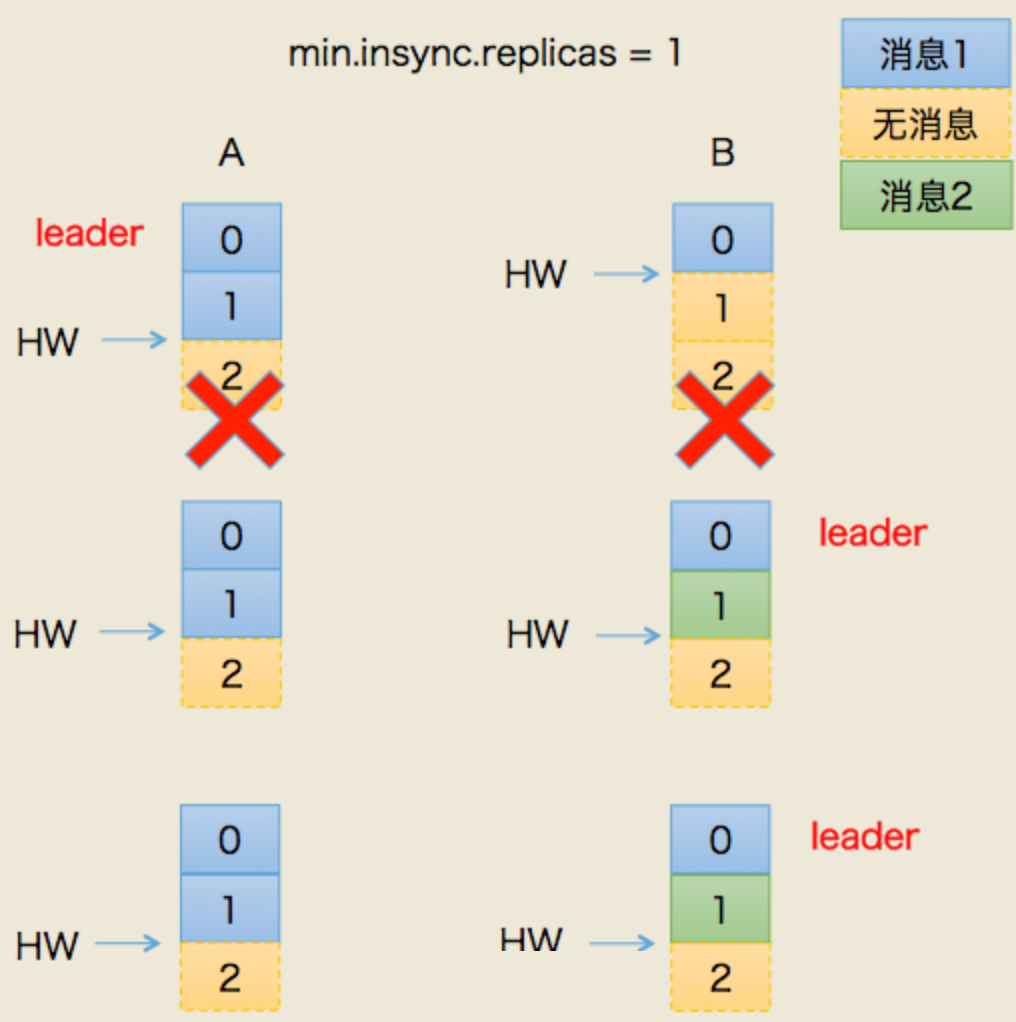
- 這次假設AB全掛了,比較慘
- B先恢復,但是它的hw有可能掛之前沒從A同步過來(原來A是leader)
- 我們假設,A.hw = 2 , B.hw = 1
- B恢復后,集群里只有它自己,所以被選為leader,開始接受新訊息
- B.hw上漲,變成2
- 然后,A恢復,原來A.hw = 2 ,恢復后以B的hw,也就是2為基準開始同步,
- 問題來了!B當leader后新接到的2號訊息是不會同步給A的,A一直保留著它當leader時的舊資料
- 最終結果:資料不一致了!
2)改進思路
0.11之后,kafka改進了hw做主的規則,這就是leader epoch
leader epoch給leader節點帶了一個版本號,類似于樂觀鎖的設計,
它的思想是,一旦發生機器故障,重啟之后,不再機械的將leo退回hw
而是借助epoch的版本資訊,去請求當前leader,讓它去算一算leo應該是什么
3)實作原理
對比上面丟資料的問題:
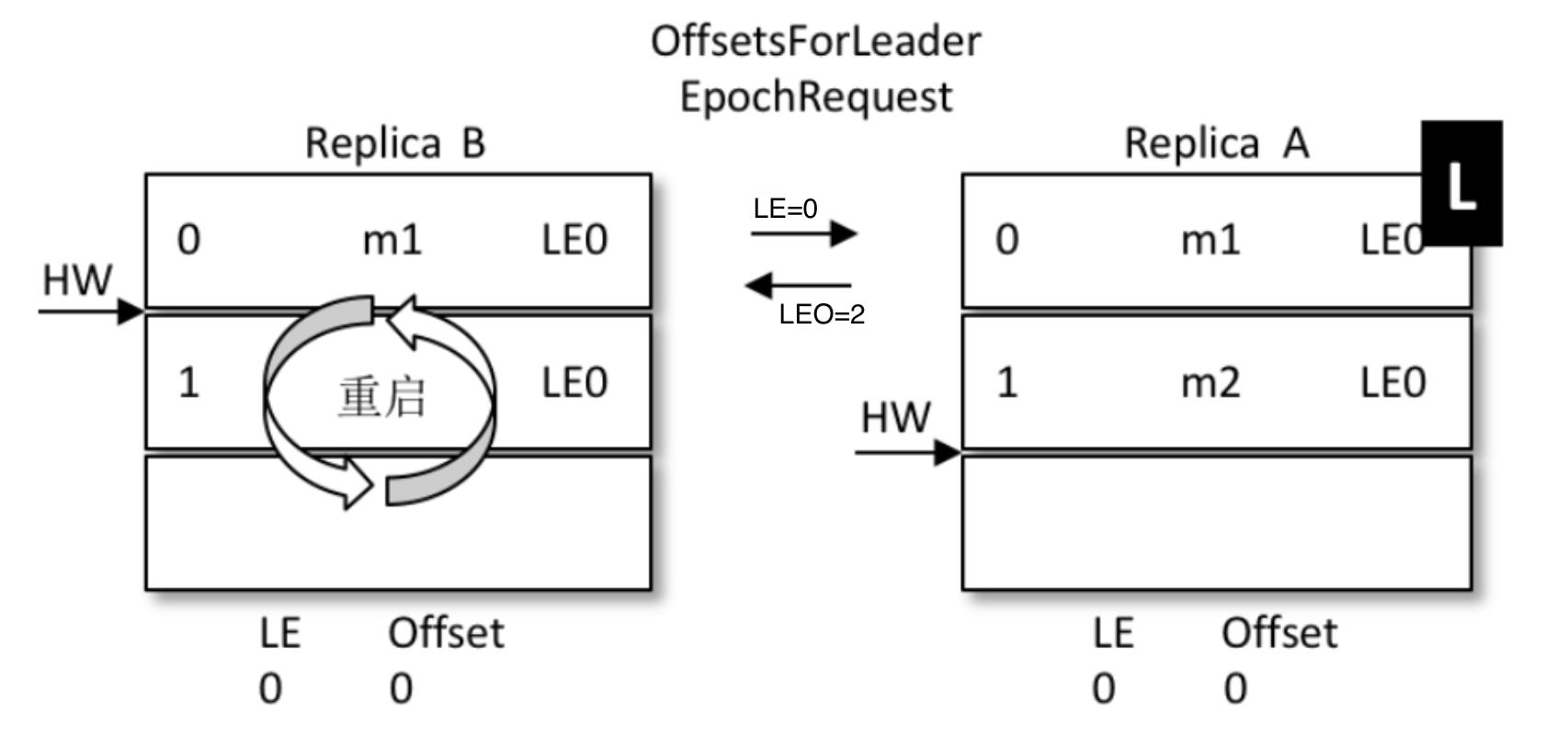
- A為(leo=2 , hw=2),B為(leo=2 , hw=1)
- B重啟,但是B不再著急將leo打回hw,而是發起一個Epoch請求給當前leader,也就是A
- A收到LE=0后,發現和自己的LE一樣,說明B在掛掉前后,leader沒變,都是A自己
- 那么A就將自己的leo值回傳給B,也就是數字2
- B收到2后和自己的leo比對取較小值,發現也是2,那么不再退回到hw的1
- 沒有回退,也就是資訊1的位置沒有被覆寫,最大程度的保護了資料
- 如果和上面一樣的場景,A掛掉,B被選為leader
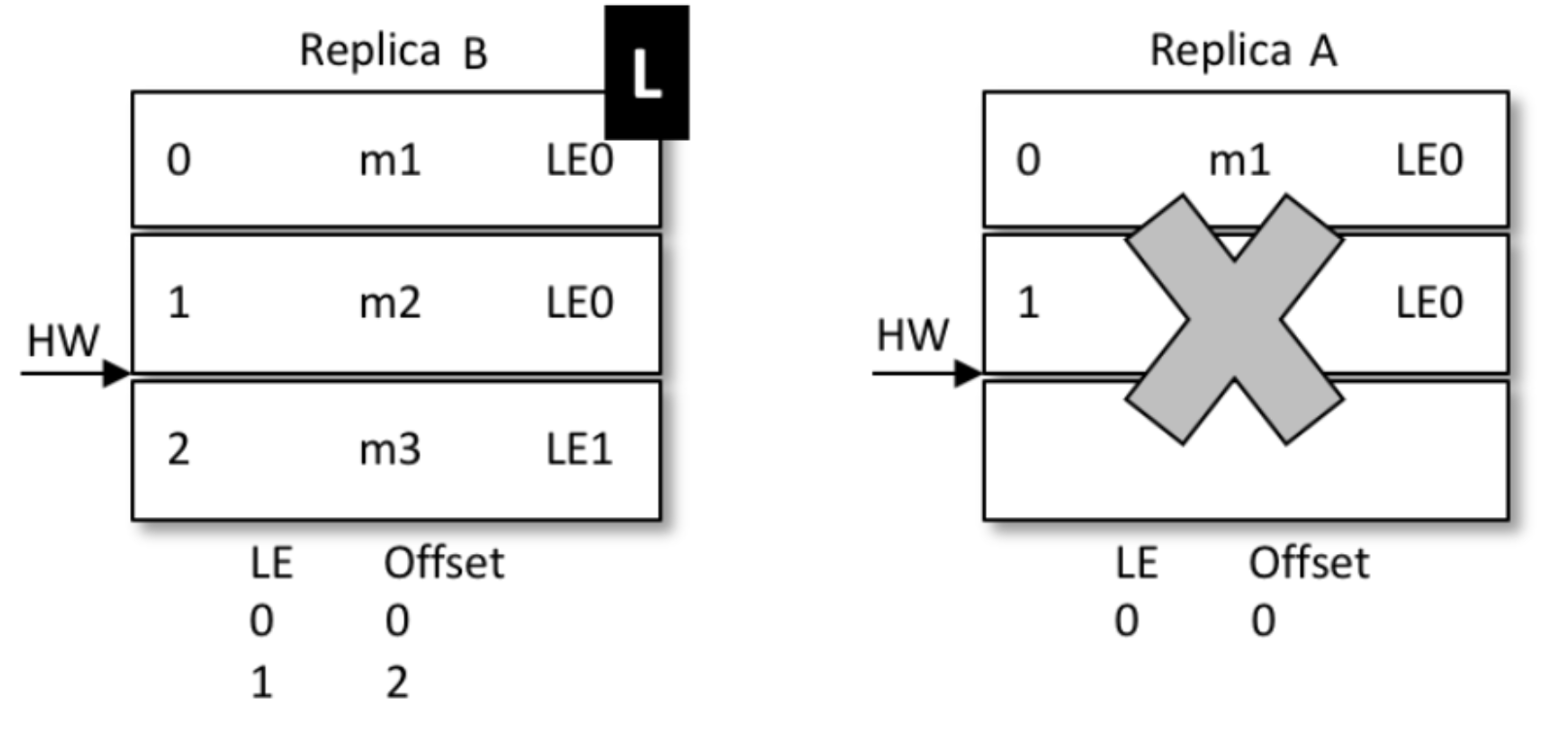
-
那么A再次啟動時后,從B開始同步資料
-
因為B之前沒有回退,1號資訊得到了保留
-
同時,B的LE(epoch號碼)開始增加,從0變成1,offset記錄為B當leader時的位置,也就是2
-
A傳過來的epoch為0,B是1,不相等,那么取大于0的所有epoch里最小的
(現實中可能發生了多次重新選主,有多條epoch)
-
其實就是LE=1的那條,現實中可能有多條,并找到它對應的offset(也就是2)給A回傳去
-
最終A得到了B同步過來的資料
再來看一致性問題的解決:
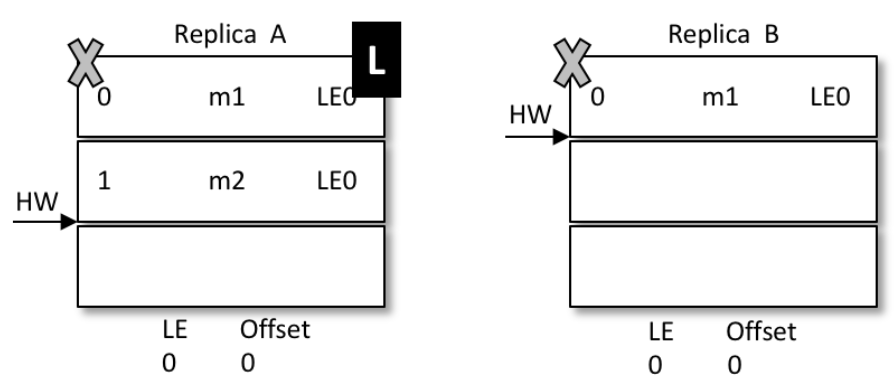
-
還是上面的場景,AB同時掛掉,但是hw還沒同步,那么A.hw=2 , B.hw=1
-
B先啟動被選成了leader,新leader選舉后,epoch加了一條記錄(參考下圖,LE=1,這時候offset=1)
-
表示B從1開始往后繼續寫資料,新來了條資訊,內容為m3,寫到1號位
-
A啟動前,集群只有B自己,訊息被確認,hw上漲到2,變成下面的樣子
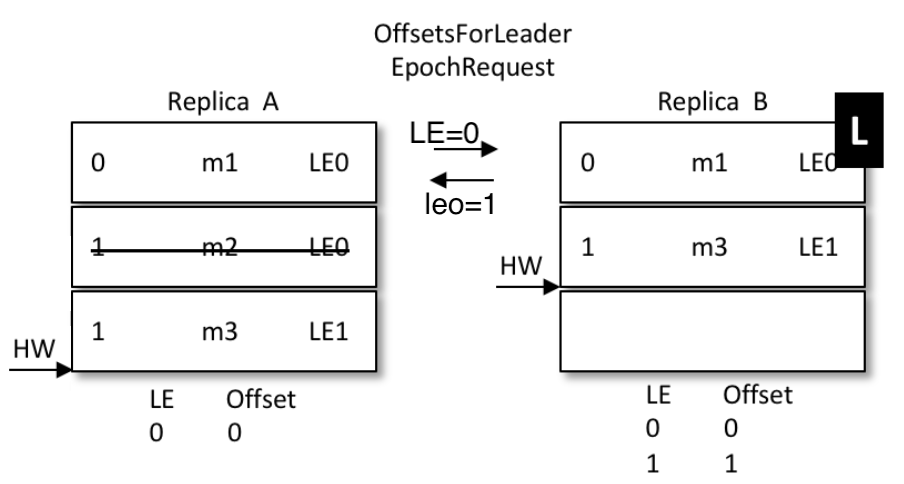
-
A開始恢復,啟動后向B發送epoch請求,將自己的LE=0告訴leader,也就是B
-
B發現自己的LE不同,同樣去大于0的LE里最小的那條,也就是1 , 對應的offset也是1,回傳給A
-
A從1開始同步資料,將自己本地的資料截斷、覆寫,hw上升到2
-
那么最新的寫入的m3從B給同步到了A,并覆寫了A上之前的舊資料m2
-
結果:資料保持了一致
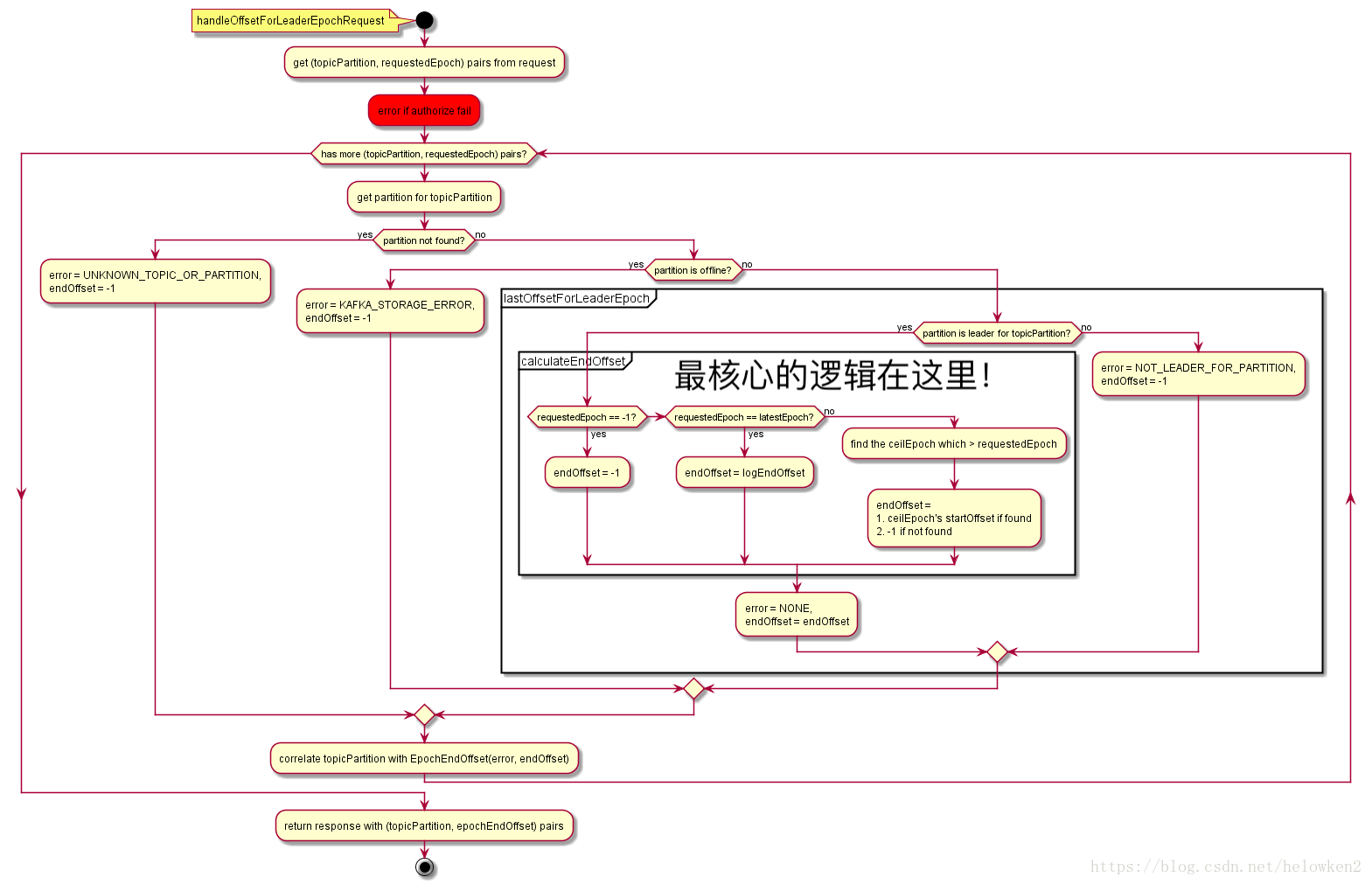
附:epochRequest的詳細流程圖
本文由傳智教育博學谷 - 狂野架構師教研團隊發布
如果本文對您有幫助,歡迎關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/501892.html
標籤:其他
上一篇:字串的基本運用