Java集合04
9.Set介面方法
-
Set介面基本介紹
- 無序(添加和取出的順序不一致),沒有索引
- 不允許重復元素,所以最多只有一個null
- JDK API中介面的實作類有:

-
Set介面的常用方法:和List介面一樣,Set介面也是Collection的子介面,因此,常用方法和Collection介面一樣,
-
Set介面的遍歷方式:同Collection的遍歷方式一樣,因為Set是Collection的子介面所以:
- 可以使用迭代器
- 增強for回圈
- 不能使用索引的方式來獲取

例子1:以Set介面的實作類HashSet來講解Set的方法
1.set介面的實作類的物件(set實作類物件),不能存放重復的資料,且最多只能添加一個null
2.set介面物件存放資料是無序的(即添加物件順序和取出的物件順序不一致)
3.注意:但是取出的順序是固定的
package li.collections.set;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
@SuppressWarnings("all")
public class SetMethod {
public static void main(String[] args) {
Set set = new HashSet();
set.add("john");
set.add("lucy");
set.add("john");
set.add("jack");
set.add("marry");
set.add(null);
set.add(null);
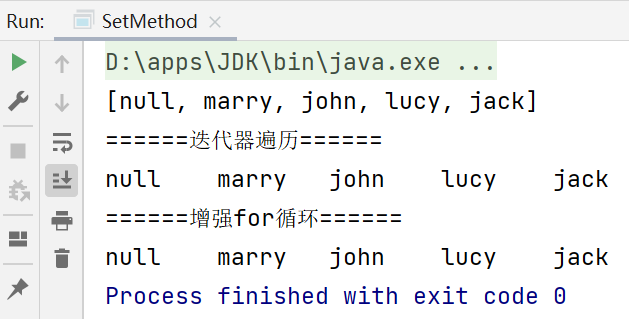
System.out.println(set);//取出的順序是一致的:[null, marry, john, lucy, jack]
//遍歷
//1.使用迭代器
Iterator iterator = set.iterator();
System.out.println("======迭代器遍歷======");
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.print(obj+"\t");
}
//2.增強for回圈
System.out.println('\n'+"======增強for回圈======");
for (Object o:set) {
System.out.print(o+"\t");
}
//set介面物件不能使用通過索引來獲取,因此沒有get方法
}
}
10.HashSet
- HashSet實作了介面Set
- HashSet實際上是HashMap

- 可以存放null值,但只能有一個null
- HashSet 不保證元素是有序的,取決于hash后,再確定索引的結果
- 不能有重復元素/物件
例子1:不允許重復元素
package li.collections.set;
import java.util.HashSet;
import java.util.Set;
@SuppressWarnings("all")
public class HasSet_ {
public static void main(String[] args) {
Set hashSet = new HashSet();
//1.HashSet可以存放null,但是只能存放一個null,即不允許重復元素
hashSet.add(null);
hashSet.add(null);
System.out.println(hashSet);//[null]
}
}
例子2:
package li.collections.set;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSet01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
//1.在執行add方法后會回傳一個boolean值,添加成功回傳true,失敗則回傳false
System.out.println(hashSet.add("john"));//true
System.out.println(hashSet.add("lucy"));//true
System.out.println(hashSet.add("john"));//false,可以看出這里添加失敗了,不允許重復元素
System.out.println(hashSet.add("jack"));//true
System.out.println(hashSet.add("rose"));//true
//2.可以通過remove()指定洗掉哪個物件
hashSet.remove("john");
System.out.println(hashSet);//[rose, lucy, jack]
}
}
10.1怎么理解不能添加相同的元素/資料?
例子:
package li.collections.set;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSet01 {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("lucy");//添加成功
hashSet.add("lucy");//添加失敗
hashSet.add("lucy");//添加失敗
hashSet.add(new Dog("tom"));//添加成功
hashSet.add(new Dog("tom"));//添加成功
System.out.println(hashSet);//[Dog{name='tom'}, Dog{name='tom'}, lucy]
//!!!經典面試題:
hashSet.add(new String("jackcheng"));//添加成功
hashSet.add(new String("jackcheng"));//添加失敗,為什么呢?
System.out.println(hashSet);//[jackcheng, Dog{name='tom'}, Dog{name='tom'}, lucy]
}
}
class Dog{
private String name;
public Dog(String name) {
this.name = name;
}
@Override
public String toString() {
return "Dog{" +
"name='" + name + '\'' +
'}';
}
}
為什么相同的兩個 hashSet.add(new Dog("tom")); hashSet.add(new Dog("tom"));陳述句可以添加成功,而卻添加失敗呢?原因在于HashSet的底層機制
hashSet.add(new String("jackcheng"));//添加成功
hashSet.add(new String("jackcheng"));//添加失敗,為什么呢?
10.2HashSet的底層擴容機制
HashSet底層是HashMap,HashMap底層是陣列+鏈表+紅黑樹
說明:
- HashSet底層是HashMap第一次添加時,table陣列擴容到16,臨界值(threshold)是16*加載因子(loadFactor,0.75)=12;如果table陣列容量使用到了臨界值12,就會擴容到16 * 2=32,新的臨界值就是32 * 0 .75=24,依此類推(兩倍擴容)
注意:這里的容量計算的不僅僅是table陣列上的容量,鏈表上的容量也算,即只要增加了一個元素,使用的容量就+1
例如:當一個table表的陣列某個索引位置上存盤了一個值,而這個值后面的鏈表存盤了7個值,加起來就是8,那么在陣列長度沒有超過64時,再加入一個值,陣列就會進行兩倍擴容
-
添加一個元素時,先得到一個hash值--會轉成--索引值
-
找到存盤資料表table,看這個索引位置是否已經存放有元素
3.1 如果沒有則直接加入
3.2 如果有,則呼叫equals()比較,如果相同就放棄添加;如果不相同則添加到最后
-
在jdk8中,如果一條鏈表的元素個數 >= TREEIFY_THRESHOLD (默認為8),并且table陣列的大小 >= MIN_TREEIFY_CAPACITY (默認為64)就會進行樹化(紅黑樹),否則仍然采用陣列擴容機制
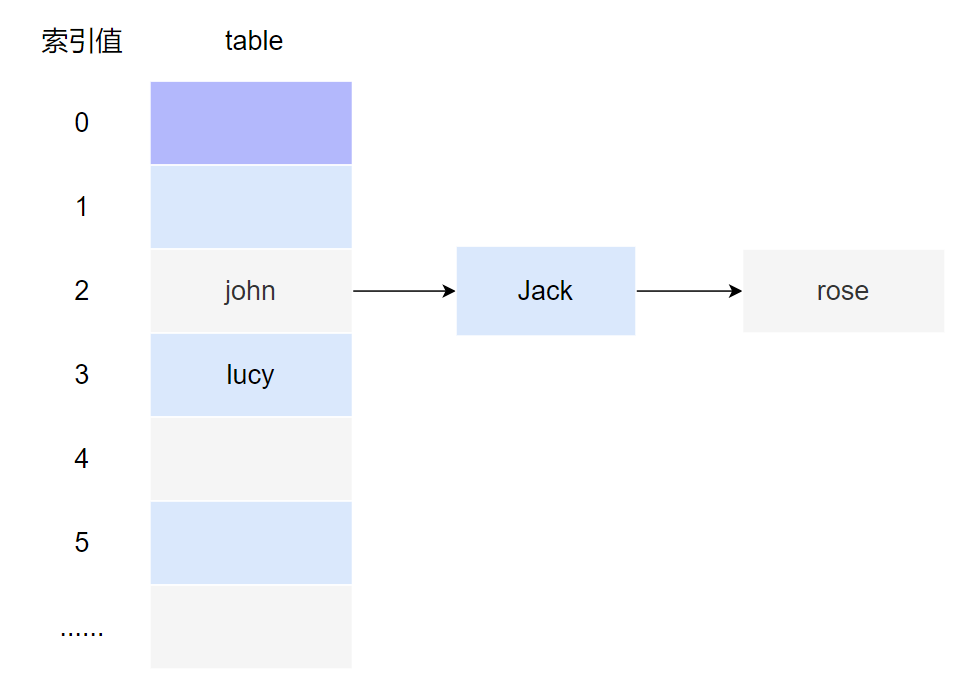
例子:模擬鏈表
package li.collections.set;
public class HashSetStructure {
public static void main(String[] args) {
//模擬一個HashSet的底層(即HashMap的底層結構)
//1.創建一個陣列,陣列的型別是Node
Node[] table = new Node[16];
System.out.println(table);
//2.創建結點
Node john = new Node("john", null);
table[2] = john;
Node jack = new Node("jack", null);
john.next = jack;//將Jack結點掛載到john后面
Node rose = new Node("rose", null);
jack.next = rose;//將rose結點掛載到jack后面
Node lucy = new Node("lucy", null);
table[3] = lucy;//把lucy存放到table表索引為3 的位置
System.out.println(table);
}
}
class Node {//結點,用于存放陣列,可以指向下一個節點從而形成鏈表
Object item;//存放資料
Node next;//指向下一個節點
public Node(Object item, Node next) {
this.item = item;
this.next = next;
}
}
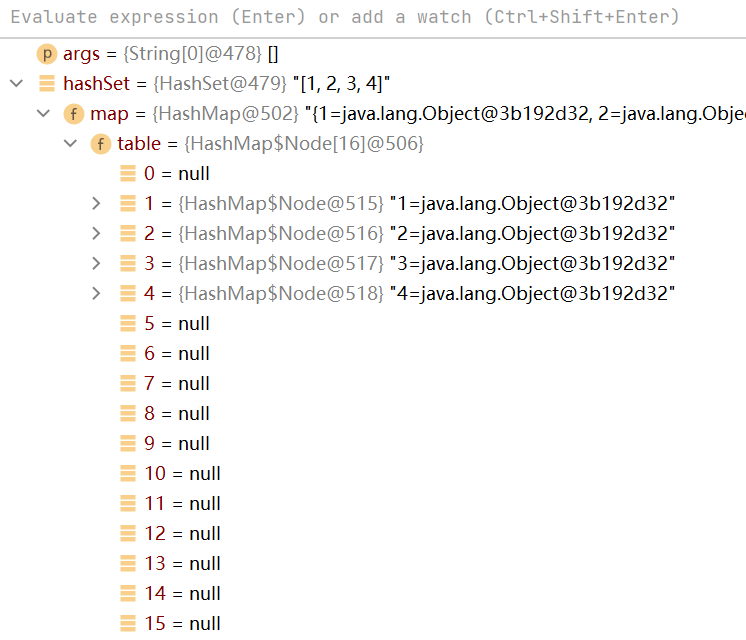
例子2:HashSet的兩倍擴容機制
- 如圖,HashSet第一次添加資料,table陣列的長度為16
-
在陣列容量使用到12(臨界值) 時,會進行一個兩倍的擴容(12*0.75=32)
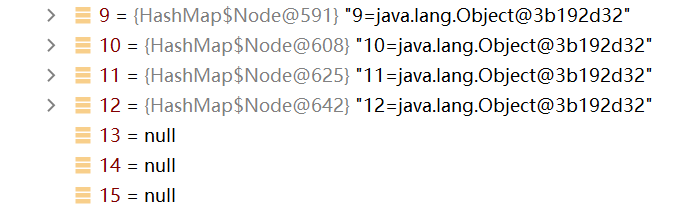
例子3:HashSet的樹化
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
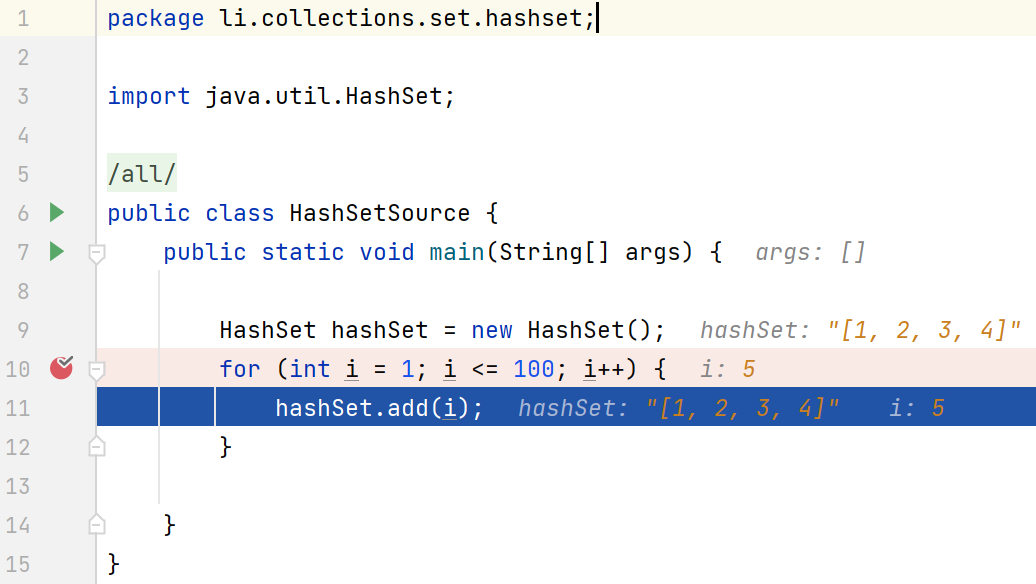
for (int i = 1; i <=12 ; i++) {
hashSet.add(new A(i));
}
System.out.println(hashSet);
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode(){//重寫hashCode方法
return 100;
}
}
如上所示,將hashCode方法重寫,使其回傳相同的哈希值,這樣可以快速地使table鏈表的值達到8以上
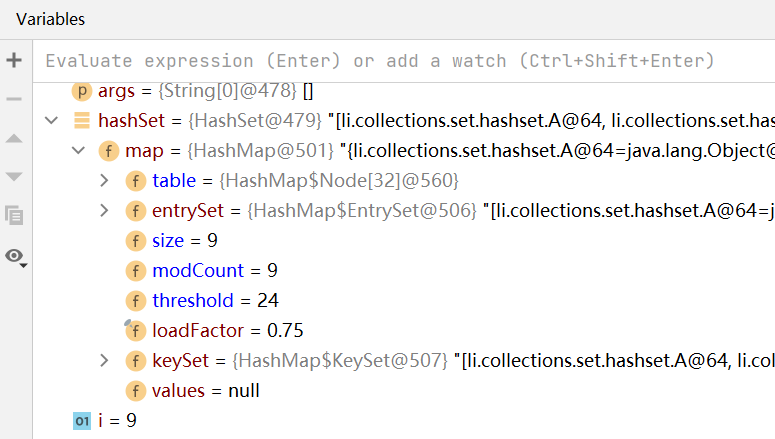
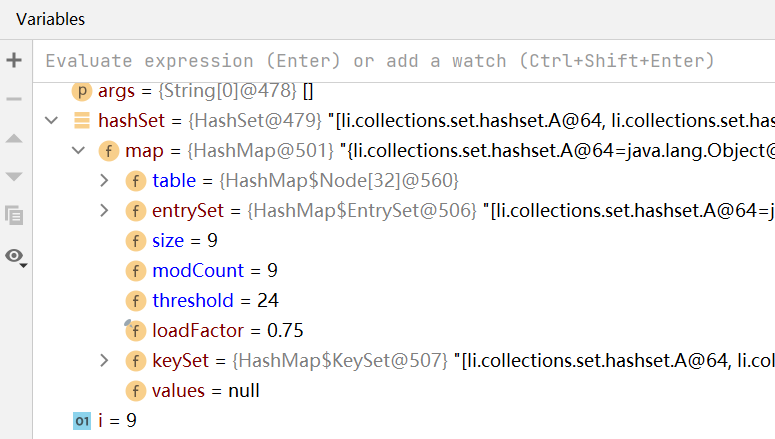
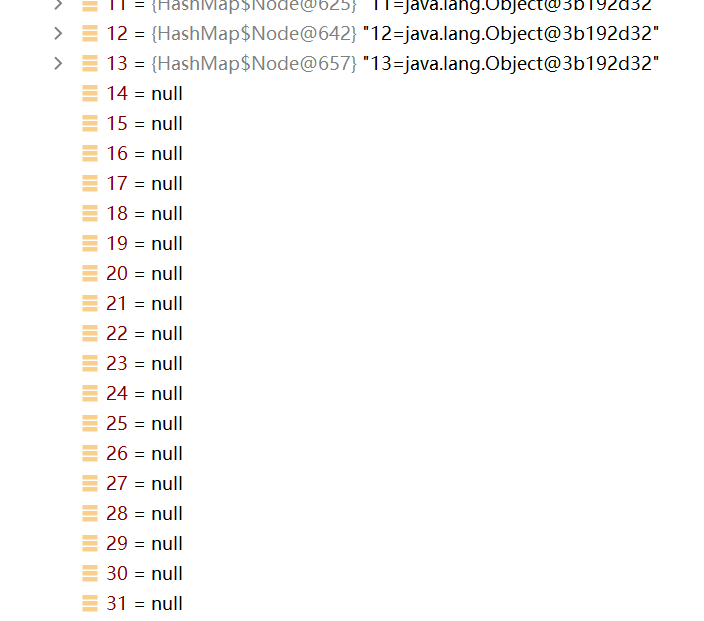
如上圖所示,當鏈表數量到達8之后,table的容量進行兩倍擴容,變成32,臨界值為24

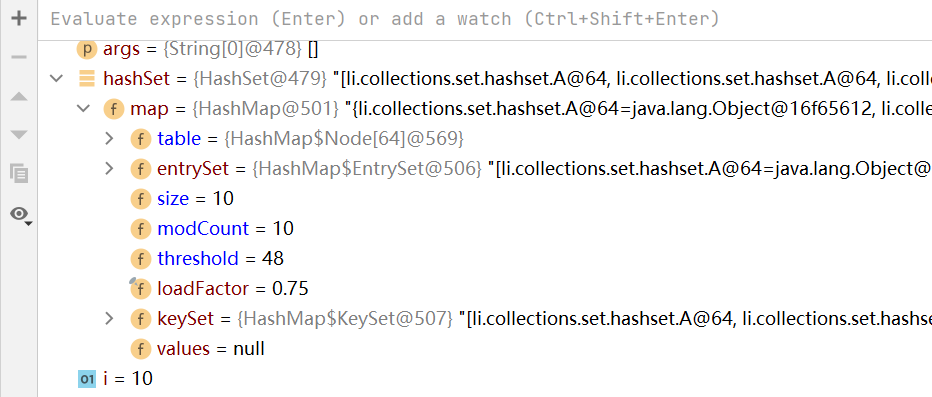
如上圖,當鏈表數量到達9之后,table的容量進行兩倍擴容,變成64,臨界值為48
如下所示:當鏈表數量到達10之后,table此刻符合樹化的條件(長度>=64,鏈表長度>=8),將鏈表轉變為紅黑樹,不再進行擴容

例子4:驗證--->擴容 需要的使用容量計算的不僅僅是陣列上的容量,鏈表上的容量也算
如下,重寫hashCode()方法,讓 其快速在某一個鏈表上添加
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
for (int i = 1; i <=7 ; i++) {//在table的某一條鏈表上添加了7個A個物件
hashSet.add(new A(i));
}
for (int i = 1; i <=7 ; i++) {//在table的另外一條鏈表上添加了7個B物件
hashSet.add(new B(i));
}
System.out.println(hashSet);
}
}
class B{
private int n;
public B(int n) {
this.n = n;
}
@Override
public int hashCode(){//重寫hashCode方法
return 200;
}
}
class A {
private int n;
public A(int n) {
this.n = n;
}
@Override
public int hashCode(){//重寫hashCode方法
return 100;
}
}
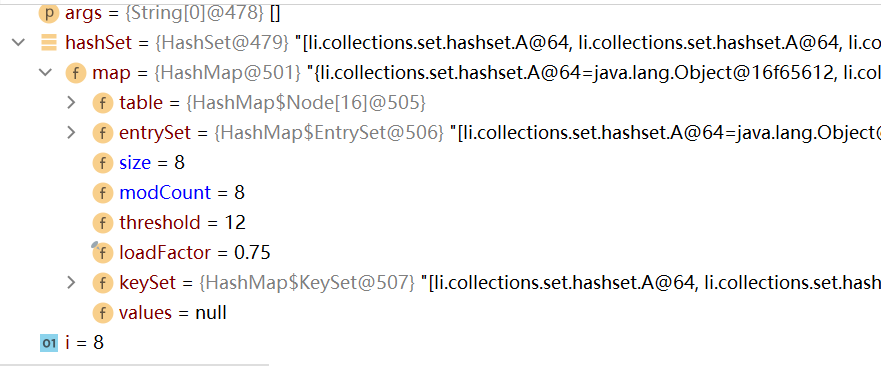
如下圖,在第二個回圈陳述句上打上斷點,可以看到在table表中有兩個鏈表,此時,在索引4的位置上存放了7個A物件,在索引8的位置上存放了5個物件,此時整個陣列的長度為16
接下來再添加一個資料,即此時陣列上的資料+鏈表上的資料總量為13,超過臨界值時4,可以看到table陣列進行了擴容(64)
說明擴容臨界值計算的是添加資料的總個數,而非單指table表上的資料個數
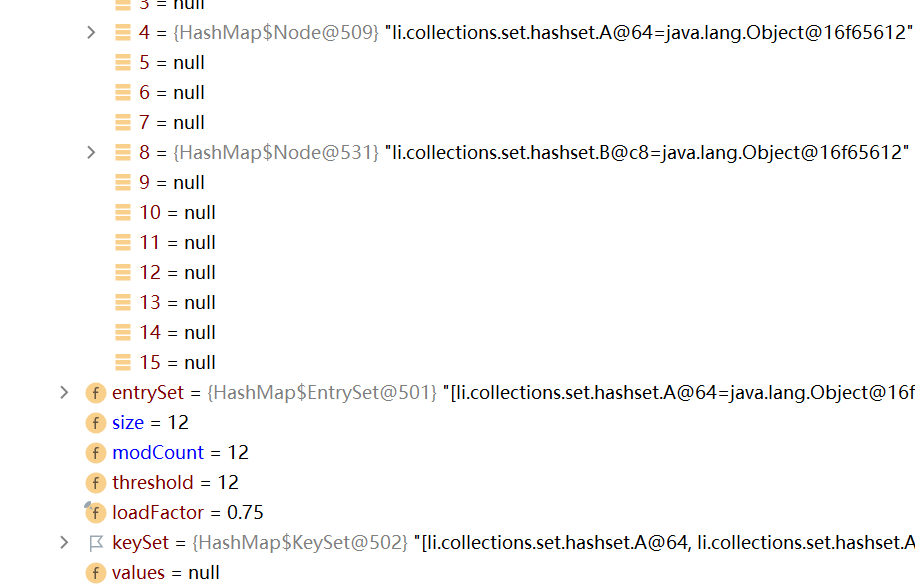
10.3HashSet原始碼解讀
package li.collections.set.hashset;
import java.util.HashSet;
@SuppressWarnings("all")
public class HashSetSource {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set="+hashSet);
}
}
-
HashSet hashSet = new HashSet();首先new HashSet()會呼叫HashSet構造器
-
hashSet.add("java");第一次呼叫add()方法:
-
add()方法又呼叫了put()方法:

其中,key就是傳遞的引數:java,而value則是add()方法的PRESENT,PRESENT是一個用于占位的Object物件,被設定為靜態且是常量

-
點擊hash(key)方法,查看:

可以看到,如果傳入的引數key為空的話,就回傳0;如果不為空,則求出 key 的 hashCode 值,然后將hashCode 值右移16位并且與原來的 hashCode 值進行 ^(按位異或) 操作,并回傳這個哈希值
-
回到上一層,點擊進入putVal()方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {// Node<K,V>[] tab; Node<K,V> p; int n, i;//定義了輔助變數 //這里定義的tablejiushi HashMap的一個陣列,型別是Node[]陣列 if ((tab = table) == null || (n = tab.length) == 0)//if 陳述句表示,如果當前table是null,或者大小=0,則進行第一次擴容,擴容到16個空間 n = (tab = resize()).length;//如果為第一次擴容,此時初始的table已經變成容量為16的陣列 /* 1.根據key,得到hash 去計算key應該放到table表的哪個索引位置,并且把這個未知的物件賦給賦值變數p 2.再判斷p是否為空 2.1如果p為空,表示該位置還沒存放元素,就創建一個Node (key="java", value=https://www.cnblogs.com/liyuelian/archive/2022/08/15/PRESENT)并把數 據放在該位置--table[i]=newNode(hash, key, value, null); */ if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { //2.2如果不為空,就會進入else陳述句 Node
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/501897.html
標籤:其他
上一篇:Pytest框架 — 07、Pytest的Fixture(部分前后置)(二)
下一篇:集合(set)