前言
嗨嘍,大家好呀~這里是愛看美女的茜茜吶

我們在做采集資料的時候,過快或者訪問頻繁,或者一訪問就給彈出驗證碼,然后就蚌珠了~

那么今天!博主就給大家來一個簡單處理驗證碼的方法
環境模塊
Python和pycharm如果還有小伙伴沒安裝的話,可以在文章最下方掃碼獲取安裝包,
這里需要用到一個 ddddocr 模塊 ,這是別人開源寫好的一個東西,簡單又好用,但是精確度差一點點,但是還是非常好用的,
如果你追求精確度的話,可以呼叫別人寫好的一些API ,
第三方模塊安裝方法: win+r 彈出搜索框后輸入 cmd ,點擊確定彈出命令提示符視窗, 輸入pip install ddddocr 即可安裝,
代碼展示
代碼不多,非常簡單,
模塊安裝好之后咱們先匯入一下
import ddddocr
然后實體化一下,用一個 cor 接收一下這個資料,
ocr = ddddocr.DdddOcr()
我這里準備了兩個個驗證碼,純數字的和字母+數字的,分別測驗

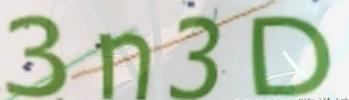
首先我們用 with open 來讀取一下這檔案,讀取方式使用 rb ,因為是圖片的話就讀取它的二進制資料
with open('img_3.png', 'rb') as f:
使用 f.read() 將資料讀取出來,再自定義一個變數接收一下,
img_bytes = f.read()
然后我們通過 classification 將它傳進去,把結果列印出來就可以了,
result = ocr.classification(img_bytes)
print(result)
更多資料獲取加Q裙:261823976 點擊藍字加入【python學習裙】

實作效果
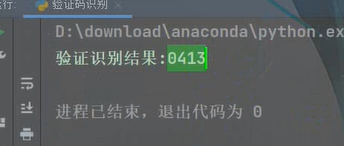
純數字的
字母+數字的
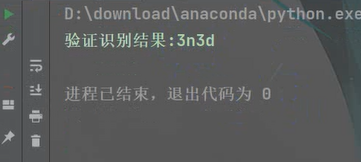
可以看到都完整的識別出來了,即使上面有一些花里胡哨的橫線啥的,
嗶站視頻號個人主頁:Python芊
200+ Python案例講解
尾語 ??
感謝你觀看我的文章吶~本次航班到這里就結束啦 ??
希望本篇文章有對你帶來幫助 ??,有學習到一點知識~
躲起來的星星??也在努力發光,你也要努力加油(讓我們一起努力叭),
最后,博主要一下你們的三連呀(點贊、評論、收藏),不要錢的還是可以搞一搞的嘛~
不知道評論啥的,即使扣個6666也是對博主的鼓舞吖 ?? 感謝 ??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/502430.html
標籤:Python
上一篇:多道技術、同步異步和阻塞非阻塞