作業中,經常會碰到并發讀寫 map 而造成 panic 的情況,為什么在并發讀寫的時候,會 panic 呢?因為在并發讀寫的情況下,map 里的資料會被寫亂,之后就是 Garbage in, garbage out,還不如直接 panic 了,
目錄
- 是什么
- 有什么用
- 如何使用
- 原始碼分析
- 資料結構
- Store
- Load
- Delete
- LoadOrStore
- Range
- 其他
- 總結
- 參考資料
是什么
Go 語言原生 map 并不是執行緒安全的,對它進行并發讀寫操作的時候,需要加鎖,而 sync.map 則是一種并發安全的 map,在 Go 1.9 引入,
sync.map是執行緒安全的,讀取,插入,洗掉也都保持著常數級的時間復雜度,
sync.map的零值是有效的,并且零值是一個空的 map,在第一次使用之后,不允許被拷貝,
有什么用
一般情況下解決并發讀寫 map 的思路是加一把大鎖,或者把一個 map 分成若干個小 map,對 key 進行哈希,只操作相應的小 map,前者鎖的粒度比較大,影響效率;后者實作起來比較復雜,容易出錯,
而使用 sync.map 之后,對 map 的讀寫,不需要加鎖,并且它通過空間換時間的方式,使用 read 和 dirty 兩個 map 來進行讀寫分離,降低鎖時間來提高效率,
如何使用
使用非常簡單,和普通 map 相比,僅遍歷的方式略有區別:
package main
import (
"fmt"
"sync"
)
func main() {
var m sync.Map
// 1. 寫入
m.Store("qcrao", 18)
m.Store("stefno", 20)
// 2. 讀取
age, _ := m.Load("qcrao")
fmt.Println(age.(int))
// 3. 遍歷
m.Range(func(key, value interface{}) bool {
name := key.(string)
age := value.(int)
fmt.Println(name, age)
return true
})
// 4. 洗掉
m.Delete("qcrao")
age, ok := m.Load("qcrao")
fmt.Println(age, ok)
// 5. 讀取或寫入
m.LoadOrStore("stefno", 100)
age, _ = m.Load("stefno")
fmt.Println(age)
}
第 1 步,寫入兩個 k-v 對;
第 2 步,使用 Load 方法讀取其中的一個 key;
第 3 步,遍歷所有的 k-v 對,并列印出來;
第 4 步,洗掉其中的一個 key,再讀這個 key,得到的就是 nil;
第 5 步,使用 LoadOrStore,嘗試讀取或寫入 "Stefno",因為這個 key 已經存在,因此寫入不成功,并且讀出原值,
程式輸出:
18
stefno 20
qcrao 18
<nil> false
20
sync.map 適用于讀多寫少的場景,對于寫多的場景,會導致 read map 快取失效,需要加鎖,導致沖突變多;而且由于未命中 read map 次數過多,導致 dirty map 提升為 read map,這是一個 O(N) 的操作,會進一步降低性能,
原始碼分析
資料結構
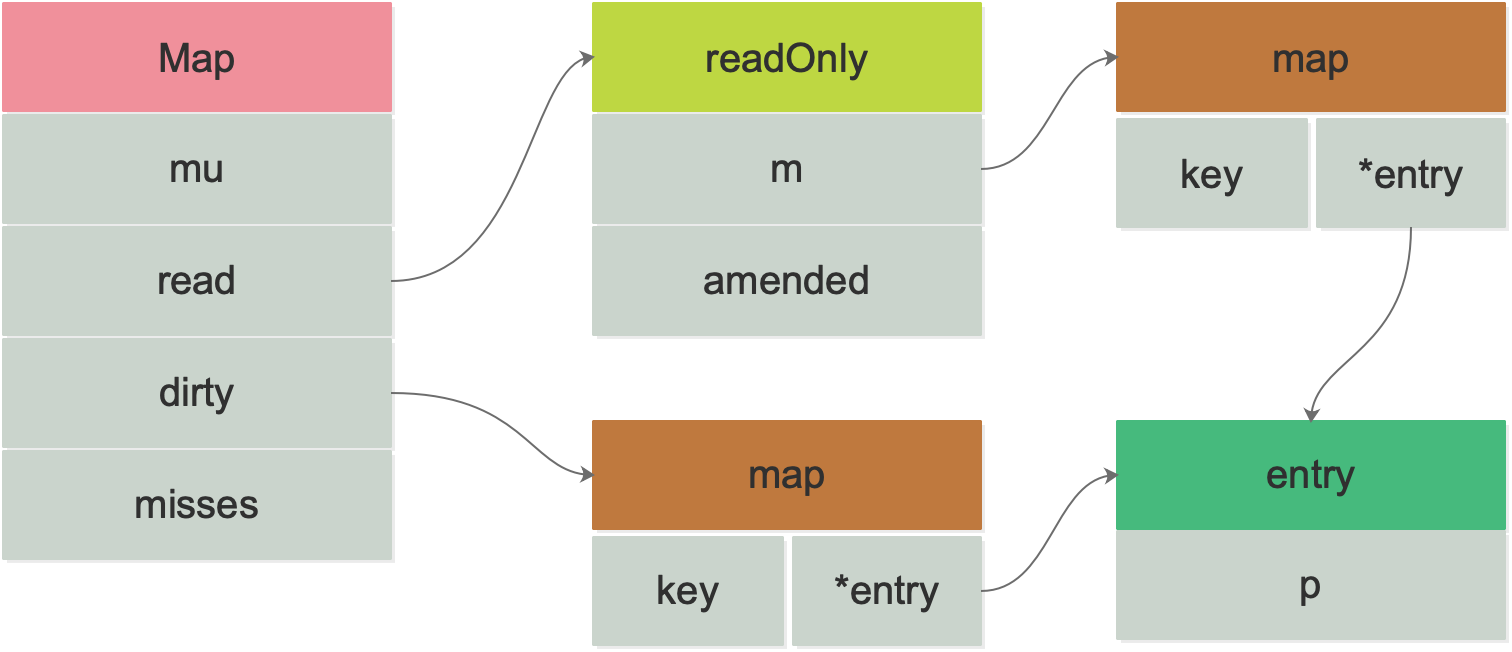
先來看下 map 的資料結構,去掉大段的注釋后:
type Map struct {
mu Mutex
read atomic.Value // readOnly
dirty map[interface{}]*entry
misses int
}
互斥量 mu 保護 read 和 dirty,
read 是 atomic.Value 型別,可以并發地讀,但如果需要更新 read,則需要加鎖保護,對于 read 中存盤的 entry 欄位,可能會被并發地 CAS 更新,但是如果要更新一個之前已被洗掉的 entry,則需要先將其狀態從 expunged 改為 nil,再拷貝到 dirty 中,然后再更新,
dirty 是一個非執行緒安全的原始 map,包含新寫入的 key,并且包含 read 中的所有未被洗掉的 key,這樣,可以快速地將 dirty 提升為 read 對外提供服務,如果 dirty 為 nil,那么下一次寫入時,會新建一個新的 dirty,這個初始的 dirty 是 read 的一個拷貝,但除掉了其中已被洗掉的 key,
每當從 read 中讀取失敗,都會將 misses 的計數值加 1,當加到一定閾值以后,需要將 dirty 提升為 read,以期減少 miss 的情形,
read map和dirty map的存盤方式是不一致的,
前者使用 atomic.Value,后者只是單純的使用 map,
原因是 read map 使用 lock free 操作,必須保證 load/store 的原子性;而 dirty map 的 load+store 操作是由 lock(就是 mu)來保護的,
真正存盤 key/value 的是 read 和 dirty 欄位,read 使用 atomic.Value,這是 lock-free 的基礎,保證 load/store 的原子性,dirty 則直接用了一個原始的 map,對于它的 load/store 操作需要加鎖,
read 欄位里實際上是存盤的是:
// readOnly is an immutable struct stored atomically in the Map.read field.
type readOnly struct {
m map[interface{}]*entry
amended bool // true if the dirty map contains some key not in m.
}
注意到 read 和 dirty 里存盤的東西都包含 entry,來看一下:
type entry struct {
p unsafe.Pointer // *interface{}
}
很簡單,它是一個指標,指向 value,看來,read 和 dirty 各自維護一套 key,key 指向的都是同一個 value,也就是說,只要修改了這個 entry,對 read 和 dirty 都是可見的,這個指標的狀態有三種:

當 p == nil 時,說明這個鍵值對已被洗掉,并且 m.dirty == nil,或 m.dirty[k] 指向該 entry,
當 p == expunged 時,說明這條鍵值對已被洗掉,并且 m.dirty != nil,且 m.dirty 中沒有這個 key,
其他情況,p 指向一個正常的值,表示實際 interface{} 的地址,并且被記錄在 m.read.m[key] 中,如果這時 m.dirty 不為 nil,那么它也被記錄在 m.dirty[key] 中,兩者實際上指向的是同一個值,
當洗掉 key 時,并不實際洗掉,一個 entry 可以通過原子地(CAS 操作)設定 p 為 nil 被洗掉,如果之后創建 m.dirty,nil 又會被原子地設定為 expunged,且不會拷貝到 dirty 中,
如果 p 不為 expunged,和 entry 相關聯的這個 value 可以被原子地更新;如果 p == expunged,那么僅當它初次被設定到 m.dirty 之后,才可以被更新,
整體用一張圖來表示:
Store
先來看 expunged:
var expunged = unsafe.Pointer(new(interface{}))
它是一個指向任意型別的指標,用來標記從 dirty map 中洗掉的 entry,
// Store sets the value for a key.
func (m *Map) Store(key, value interface{}) {
// 如果 read map 中存在該 key 則嘗試直接更改(由于修改的是 entry 內部的 pointer,因此 dirty map 也可見)
read, _ := m.read.Load().(readOnly)
if e, ok := read.m[key]; ok && e.tryStore(&value) {
return
}
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if e, ok := read.m[key]; ok {
if e.unexpungeLocked() {
// 如果 read map 中存在該 key,但 p == expunged,則說明 m.dirty != nil 并且 m.dirty 中不存在該 key 值 此時:
// a. 將 p 的狀態由 expunged 更改為 nil
// b. dirty map 插入 key
m.dirty[key] = e
}
// 更新 entry.p = value (read map 和 dirty map 指向同一個 entry)
e.storeLocked(&value)
} else if e, ok := m.dirty[key]; ok {
// 如果 read map 中不存在該 key,但 dirty map 中存在該 key,直接寫入更新 entry(read map 中仍然沒有這個 key)
e.storeLocked(&value)
} else {
// 如果 read map 和 dirty map 中都不存在該 key,則:
// a. 如果 dirty map 為空,則需要創建 dirty map,并從 read map 中拷貝未洗掉的元素到新創建的 dirty map
// b. 更新 amended 欄位,標識 dirty map 中存在 read map 中沒有的 key
// c. 將 kv 寫入 dirty map 中,read 不變
if !read.amended {
// 到這里就意味著,當前的 key 是第一次被加到 dirty map 中,
// store 之前先判斷一下 dirty map 是否為空,如果為空,就把 read map 淺拷貝一次,
m.dirtyLocked()
m.read.Store(readOnly{m: read.m, amended: true})
}
// 寫入新 key,在 dirty 中存盤 value
m.dirty[key] = newEntry(value)
}
m.mu.Unlock()
}
整體流程:
- 如果在 read 里能夠找到待存盤的 key,并且對應的 entry 的 p 值不為 expunged,也就是沒被洗掉時,直接更新對應的 entry 即可,
- 第一步沒有成功:要么 read 中沒有這個 key,要么 key 被標記為洗掉,則先加鎖,再進行后續的操作,
- 再次在 read 中查找是否存在這個 key,也就是 double check 一下,這也是 lock-free 編程里的常見套路,如果 read 中存在該 key,但
p == expunged,說明 m.dirty != nil 并且 m.dirty 中不存在該 key 值 此時: a. 將 p 的狀態由 expunged 更改為 nil;b. dirty map 插入 key,然后,直接更新對應的 value, - 如果 read 中沒有此 key,那就查看 dirty 中是否有此 key,如果有,則直接更新對應的 value,這時 read 中還是沒有此 key,
- 最后一步,如果 read 和 dirty 中都不存在該 key,則:a. 如果 dirty 為空,則需要創建 dirty,并從 read 中拷貝未被洗掉的元素;b. 更新 amended 欄位,標識 dirty map 中存在 read map 中沒有的 key;c. 將 k-v 寫入 dirty map 中,read.m 不變,最后,更新此 key 對應的 value,
再來看一些子函式:
// 如果 entry 沒被刪,tryStore 存盤值到 entry 中,如果 p == expunged,即 entry 被刪,那么回傳 false,
func (e *entry) tryStore(i *interface{}) bool {
for {
p := atomic.LoadPointer(&e.p)
if p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, unsafe.Pointer(i)) {
return true
}
}
}
tryStore 在 Store 函式最開始的時候就會呼叫,是比較常見的 for 回圈加 CAS 操作,嘗試更新 entry,讓 p 指向新的值,
unexpungeLocked 函式確保了 entry 沒有被標記成已被清除:
// unexpungeLocked 函式確保了 entry 沒有被標記成已被清除,
// 如果 entry 先前被清除過了,那么在 mutex 解鎖之前,它一定要被加入到 dirty map 中
func (e *entry) unexpungeLocked() (wasExpunged bool) {
return atomic.CompareAndSwapPointer(&e.p, expunged, nil)
}
Load
func (m *Map) Load(key interface{}) (value interface{}, ok bool) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果沒在 read 中找到,并且 amended 為 true,即 dirty 中存在 read 中沒有的 key
if !ok && read.amended {
m.mu.Lock() // dirty map 不是執行緒安全的,所以需要加上互斥鎖
// double check,避免在上鎖的程序中 dirty map 提升為 read map,
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
// 仍然沒有在 read 中找到這個 key,并且 amended 為 true
if !ok && read.amended {
e, ok = m.dirty[key] // 從 dirty 中找
// 不管 dirty 中有沒有找到,都要"記一筆",因為在 dirty 提升為 read 之前,都會進入這條路徑
m.missLocked()
}
m.mu.Unlock()
}
if !ok { // 如果沒找到,回傳空,false
return nil, false
}
return e.load()
}
處理路徑分為 fast path 和 slow path,整體流程如下:
- 首先是 fast path,直接在 read 中找,如果找到了直接呼叫 entry 的 load 方法,取出其中的值,
- 如果 read 中沒有這個 key,且 amended 為 fase,說明 dirty 為空,那直接回傳 空和 false,
- 如果 read 中沒有這個 key,且 amended 為 true,說明 dirty 中可能存在我們要找的 key,當然要先上鎖,再嘗試去 dirty 中查找,在這之前,仍然有一個 double check 的操作,若還是沒有在 read 中找到,那么就從 dirty 中找,不管 dirty 中有沒有找到,都要"記一筆",因為在 dirty 被提升為 read 之前,都會進入這條路徑
這里主要看下 missLocked 的函式的實作:
func (m *Map) missLocked() {
m.misses++
if m.misses < len(m.dirty) {
return
}
// dirty map 晉升
m.read.Store(readOnly{m: m.dirty})
m.dirty = nil
m.misses = 0
}
直接將 misses 的值加 1,表示一次未命中,如果 misses 值小于 m.dirty 的長度,就直接回傳,否則,將 m.dirty 晉升為 read,并清空 dirty,清空 misses 計數值,這樣,之前一段時間新加入的 key 都會進入到 read 中,從而能夠提升 read 的命中率,
再來看下 entry 的 load 方法:
func (e *entry) load() (value interface{}, ok bool) {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return nil, false
}
return *(*interface{})(p), true
}
對于 nil 和 expunged 狀態的 entry,直接回傳 ok=false;否則,將 p 轉成 interface{} 回傳,
Delete
// Delete deletes the value for a key.
func (m *Map) Delete(key interface{}) {
read, _ := m.read.Load().(readOnly)
e, ok := read.m[key]
// 如果 read 中沒有這個 key,且 dirty map 不為空
if !ok && read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
e, ok = read.m[key]
if !ok && read.amended {
delete(m.dirty, key) // 直接從 dirty 中洗掉這個 key
}
m.mu.Unlock()
}
if ok {
e.delete() // 如果在 read 中找到了這個 key,將 p 置為 nil
}
}
可以看到,基本套路還是和 Load,Store 類似,都是先從 read 里查是否有這個 key,如果有則執行 entry.delete 方法,將 p 置為 nil,這樣 read 和 dirty 都能看到這個變化,
如果沒在 read 中找到這個 key,并且 dirty 不為空,那么就要操作 dirty 了,操作之前,還是要先上鎖,然后進行 double check,如果仍然沒有在 read 里找到此 key,則從 dirty 中刪掉這個 key,但不是真正地從 dirty 中洗掉,而是更新 entry 的狀態,
來看下 entry.delete 方法:
func (e *entry) delete() (hadValue bool) {
for {
p := atomic.LoadPointer(&e.p)
if p == nil || p == expunged {
return false
}
if atomic.CompareAndSwapPointer(&e.p, p, nil) {
return true
}
}
}
它真正做的事情是將正常狀態(指向一個 interface{})的 p 設定成 nil,沒有設定成 expunged 的原因是,當 p 為 expunged 時,表示它已經不在 dirty 中了,這是 p 的狀態機決定的,在 tryExpungeLocked 函式中,會將 nil 原子地設定成 expunged,
tryExpungeLocked 是在新創建 dirty 時呼叫的,會將已被洗掉的 entry.p 從 nil 改成 expunged,這個 entry 就不會寫入 dirty 了,
func (e *entry) tryExpungeLocked() (isExpunged bool) {
p := atomic.LoadPointer(&e.p)
for p == nil {
// 如果原來是 nil,說明原 key 已被洗掉,則將其轉為 expunged,
if atomic.CompareAndSwapPointer(&e.p, nil, expunged) {
return true
}
p = atomic.LoadPointer(&e.p)
}
return p == expunged
}
注意到如果 key 同時存在于 read 和 dirty 中時,洗掉只是做了一個標記,將 p 置為 nil;而如果僅在 dirty 中含有這個 key 時,會直接洗掉這個 key,原因在于,若兩者都存在這個 key,僅做標記洗掉,可以在下次查找這個 key 時,命中 read,提升效率,若只有在 dirty 中存在時,read 起不到“快取”的作用,直接洗掉,
LoadOrStore
這個函式結合了 Load 和 Store 的功能,如果 map 中存在這個 key,那么回傳這個 key 對應的 value;否則,將 key-value 存入 map,這在需要先執行 Load 查看某個 key 是否存在,之后再更新此 key 對應的 value 時很有效,因為 LoadOrStore 可以并發執行,
具體的程序不再一一分析了,可參考 Load 和 Store 的原始碼分析,
Range
Range 的引數是一個函式:
f func(key, value interface{}) bool
由使用者提供實作,Range 將遍歷呼叫時刻 map 中的所有 k-v 對,將它們傳給 f 函式,如果 f 回傳 false,將停止遍歷,
func (m *Map) Range(f func(key, value interface{}) bool) {
read, _ := m.read.Load().(readOnly)
if read.amended {
m.mu.Lock()
read, _ = m.read.Load().(readOnly)
if read.amended {
read = readOnly{m: m.dirty}
m.read.Store(read)
m.dirty = nil
m.misses = 0
}
m.mu.Unlock()
}
for k, e := range read.m {
v, ok := e.load()
if !ok {
continue
}
if !f(k, v) {
break
}
}
}
當 amended 為 true 時,說明 dirty 中含有 read 中沒有的 key,因為 Range 會遍歷所有的 key,是一個 O(n) 操作,將 dirty 提升為 read,會將開銷分攤開來,所以這里直接就提升了,
之后,遍歷 read,取出 entry 中的值,呼叫 f(k, v),
其他
關于為何 sync.map 沒有 Len 方法,參考資料里給出了 issue,bcmills 認為對于并發的資料結構和非并發的資料結構并不一定要有相同的方法,例如,map 有 Len 方法,sync.map 卻不一定要有,就像 sync.map 有 LoadOrStore 方法,map 就沒有一樣,
有些實作增加了一個計數器,并原子地增加或減少它,以此來表示 sync.map 中元素的個數,但 bcmills 提出這會引入競爭:atomic 并不是 contention-free 的,它只是把競爭下沉到了 CPU 層級,這會給其他不需要 Len 方法的場景帶來負擔,
總結
-
sync.map是執行緒安全的,讀取,插入,洗掉也都保持著常數級的時間復雜度, -
通過讀寫分離,降低鎖時間來提高效率,適用于讀多寫少的場景,
-
Range 操作需要提供一個函式,引數是
k,v,回傳值是一個布林值:f func(key, value interface{}) bool, -
呼叫 Load 或 LoadOrStore 函式時,如果在 read 中沒有找到 key,則會將 misses 值原子地增加 1,當 misses 增加到和 dirty 的長度相等時,會將 dirty 提升為 read,以期減少“讀 miss”,
-
新寫入的 key 會保存到 dirty 中,如果這時 dirty 為 nil,就會先新創建一個 dirty,并將 read 中未被洗掉的元素拷貝到 dirty,
-
當 dirty 為 nil 的時候,read 就代表 map 所有的資料;當 dirty 不為 nil 的時候,dirty 才代表 map 所有的資料,
參考資料
【德志大佬-設計并發安全的 map】https://halfrost.com/go_map_chapter_one/
【德志大佬-設計并發安全的 map】https://halfrost.com/go_map_chapter_two/
【關于 sync.map 為什么沒有 len 方法的 issue】https://github.com/golang/go/issues/20680
【芮神增加了 len 方法】http://xiaorui.cc/archives/4972
【圖解 map 操作】https://wudaijun.com/2018/02/go-sync-map-implement/
【從一道面試題開始】https://segmentfault.com/a/1190000018657984
【原始碼分析】https://zhuanlan.zhihu.com/p/44585993
【行文通暢,流程圖清晰】https://juejin.im/post/5d36a7cbf265da1bb47da444
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/5027.html
標籤:Go