
1. Durid概述
Apache Druid是一個集時間序列資料庫、資料倉庫和全文檢索系統特點于一體的分析性資料平臺,本文將帶你簡單了解Druid的特性,使用場景,技術特點和架構,這將有助于你選型資料存盤方案,深入了解Druid存盤,深入了解時間序列存盤等,
Apache Druid是一個高性能的實時分析型資料庫,
1.1 為什么使用
1.1.1 云原生資料庫
一個現代化的云原生,流原生,分析型資料庫
? Druid是為快速查詢和快速攝入資料的作業流而設計的,Druid強在有強大的UI,運行時可操作查詢,和高性能并發處理,Druid可以被視為一個滿足多樣化用戶場景的資料倉庫的開源替代品,
1.1.2 輕松集成
輕松與現有的資料管道集成
? Druid可以從訊息總線流式獲取資料(如Kafka,Amazon Kinesis),或從資料湖批量加載檔案(如HDFS,Amazon S3和其他同類資料源),
1.1.3 超高性能
比傳統方案快100倍的性能
-
Druid對資料攝入和資料查詢的基準性能測驗大大超過了傳統解決方案,
-
Druid的架構融合了資料倉庫,時間序列資料庫和檢索系統最好的特性,
1.1.4 作業流
解鎖新的作業流
? Druid為Clickstream,APM(應用性能管理系統),supply chain(供應鏈),網路遙測,數字營銷和其他事件驅動形式的場景解鎖了新的查詢方式和作業流,Druid專為實時和歷史資料的快速臨時查詢而構建,
1.1.5 多種部署方式
可以部署在AWS/GCP/Azure,混合云,k8s和租用服務器上
? Druid可以部署在任Linux環境中,無論是內部環境還是云環境,部署Druid是非常easy的:通過添加或刪減服務來擴容縮容,
1.2 使用場景
Apache Druid適用于對實時資料提取,高性能查詢和高可用要求較高的場景,因此,Druid通常被作為一個具有豐富GUI的分析系統,或者作為一個需要快速聚合的高并發API的后臺,Druid更適合面向事件資料,
1.2.1 常見的使用場景
比較常見的使用場景
1.2.1.1 用戶活動和行為
? Druid經常用在點擊流,訪問流,和活動流資料上,具體場景包括:衡量用戶參與度,為產品發布追蹤A/B測驗資料,并了解用戶使用方式,Druid可以做到精確和近似計算用戶指標,例如不重復計數指標,這意味著,如榷訓用戶指標可以在一秒鐘計算出近似值(平均精度98%),以查看總體趨勢,或精確計算以展示給利益相關者,Druid可以用來做“漏斗分析”,去測量有多少用戶做了某種操作,而沒有做另一個操作,這對產品追蹤用戶注冊十分有用,
1.2.1.2 網路流
? Druid常常用來收集和分析網路流資料,Druid被用于管理以任意屬性切分組合的流資料,Druid能夠提取大量網路流記錄,并且能夠在查詢時快速對數十個屬性組合和排序,這有助于網路流分析,這些屬性包括一些核心屬性,如IP和埠號,也包括一些額外添加的強化屬性,如地理位置,服務,應用,設備和ASN,Druid能夠處理非固定模式,這意味著你可以添加任何你想要的屬性,
1.2.1.3 數字營銷
? Druid常常用來存盤和查詢在線廣告資料,這些資料通常來自廣告服務商,它對衡量和理解廣告活動效果,點擊穿透率,轉換率(消耗率)等指標至關重要,
? Druid最初就是被設計成一個面向廣告資料的強大的面向用戶的分析型應用程式,在存盤廣告資料方面,Druid已經有大量生產實踐,全世界有大量用戶在上千臺服務器上存盤了PB級資料,
1.2.1.4 應用性能管理
? Druid常常用于追蹤應用程式生成的可運營資料,和用戶活動使用場景類似,這些資料可以是關于用戶怎樣和應用程式互動的,它可以是應用程式自身上報的指標資料,Druid可用于下鉆發現應用程式不同組件的性能如何,定位瓶頸,和發現問題,
? 不像許多傳統解決方案,Druid具有更小存盤容量,更小復雜度,更大資料吞吐的特點,它可以快速分析數以千計屬性的應用事件,并計算復雜的加載,性能,利用率指標,比如,基于百分之95查詢延遲的API終端,我們可以以任何臨時屬性組織和切分資料,如以天為時間切分資料,如以用戶畫像統計,如按資料中心位置統計,
1.2.1.5 物聯網和設備指標
? Driud可以作為時間序列資料庫解決方案,來存盤處理服務器和設備的指標資料,收集機器生成的實時資料,執行快速臨時的分析,去估量性能,優化硬體資源,和定位問題,
? 和許多傳統時間序列資料庫不同,Druid本質上是一個分析引擎,Druid融合了時間序列資料庫,列式分析資料庫,和檢索系統的理念,它在單個系統中支持了基于時間磁區,列式存盤,和搜索索引,這意味著基于時間的查詢,數字聚合,和檢索過濾查詢都會特別快,
? 你可以在你的指標中包括百萬唯一維度值,并隨意按任何維度組合group和filter(Druid 中的 dimension維度類似于時間序列資料庫中的tag),你可以基于tag group和rank,并計算大量復雜的指標,而且你在tag上檢索和過濾會比傳統時間序列資料庫更快,
1.2.1.6 OLAP和商業智能
? Druid經常用于商業智能場景,公司部署Druid去加速查詢和增強應用,和基于Hadoop的SQL引擎(如Presto或Hive)不同,Druid為高并發和亞秒級查詢而設計,通過UI強化互動式資料查詢,這使得Druid更適合做真實的可視化互動分析,
1.2.2 適合的場景
如果您的使用場景符合以下的幾個特征,那么Druid是一個非常不錯的選擇:
- 資料插入頻率比較高,但較少更新資料
- 大多數查詢場景為聚合查詢和分組查詢(GroupBy),同時還有一定得檢索與掃描查詢
- 將資料查詢延遲目標定位100毫秒到幾秒鐘之間
- 資料具有時間屬性(Druid針對時間做了優化和設計)
- 在多表場景下,每次查詢僅命中一個大的分布式表,查詢又可能命中多個較小的lookup表
- 場景中包含高基維度資料列(例如URL,用戶ID等),并且需要對其進行快速計數和排序
- 需要從Kafka、HDFS、物件存盤(如Amazon S3)中加載資料
1.2.3 不適合的場景
如果您的使用場景符合以下特征,那么使用Druid可能是一個不好的選擇:
- 根據主鍵對現有資料進行低延遲更新操作,Druid支持流式插入,但不支持流式更新(更新操作是通過后臺批處理作業完成)
- 延遲不重要的離線資料系統
- 場景中包括大連接(將一個大事實表連接到另一個大事實表),并且可以接受花費很長時間來完成這些查詢
2. Durid是什么
Apache Druid 是一個開源的分布式資料存盤引擎,
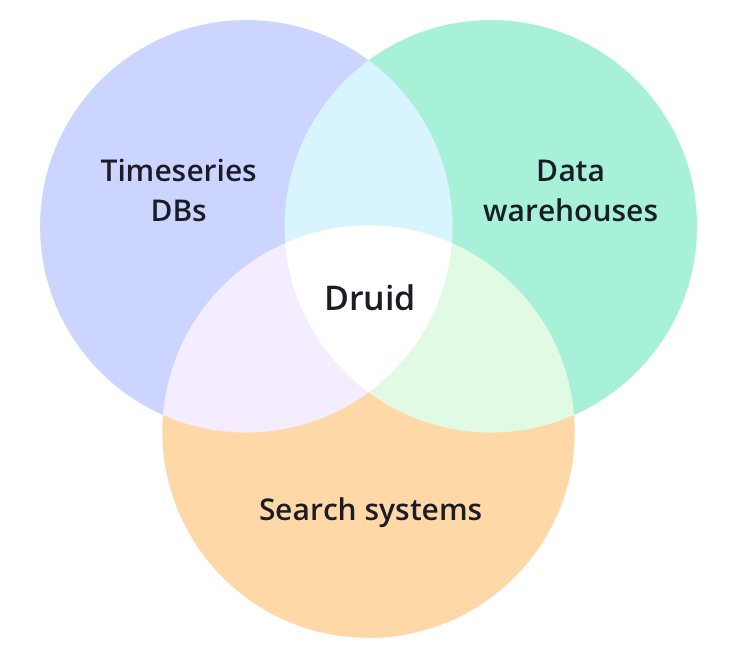
? Druid的核心設計融合了OLAP/analytic databases,timeseries database,和search systems的理念,以創造一個適用廣泛用例的統一系統,Druid將這三種系統的主要特性融合進Druid的ingestion layer(資料攝入層),storage format(存盤格式化層),querying layer(查詢層),和core architecture(核心架構)中,
2.1 主要特性
2.1.1 列式存盤
? Druid單獨存盤并壓縮每一列資料,并且查詢時只查詢特定需要查詢的資料,支持快速scan,ranking和groupBy,
2.2.2 原生檢索索引
? Druid為string值創建倒排索引以達到資料的快速搜索和過濾,
2.2.3 流式和批量資料攝入
? 開箱即用的Apache kafka,HDFS,AWS S3連接器connectors,流式處理器,
2.2.4 靈活的資料模式
? Druid優雅地適應不斷變化的資料模式和嵌套資料型別,
2.2.5 基于時間的優化磁區
? Druid基于時間對資料進行智能磁區,因此,Druid基于時間的查詢將明顯快于傳統資料庫,
2.2.6 支持SQL陳述句
? 除了原生的基于JSON的查詢外,Druid還支持基于HTTP和JDBC的SQL,
2.2.7 水平擴展能力
? 百萬/秒的資料攝入速率,海量資料存盤,亞秒級查詢,
2.2.8 易于運維
? 可以通過添加或移除Server來擴容和縮容,Druid支持自動重平衡,失效轉移,
2.3 技術選型
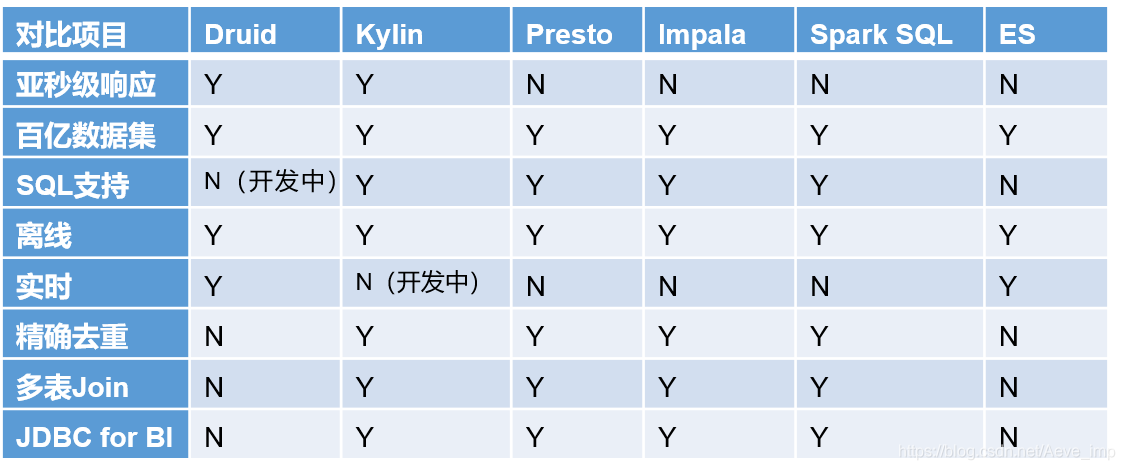
技術對比
Druid
? 是一個實時處理時序資料的OLAP資料庫,它的索引首先按照時間分片,查詢的時候也是按照時間線去路由索引,
Kylin
? 核心是Cube,Cube是一種預計算技術,預先對資料作多維索引,查詢時只掃描索引而不訪問原始資料從而提速,
Presto
? 它沒有使用MapReduce,大部分場景下比Hive快一個數量級,其中的關鍵是所有的處理都在記憶體中完成,
Impala
? 基于記憶體運算,速度快,支持的資料源沒有Presto多,
Spark SQL
? 基于Spark平臺上的一個OLAP框架,基本思路是增加機器來并行計算,從而提高查詢速度,
ES
? 最大的特點是使用了倒排索引解決索引問題,根據研究,ES在資料獲取和聚集用的資源比在Druid高,
框架選型
- 從超大資料的查詢效率來看:
Druid > Kylin > Presto > Spark SQL - 從支持的資料源種類來講:
Presto > Spark SQL > Kylin > Druid
2.4 資料攝入
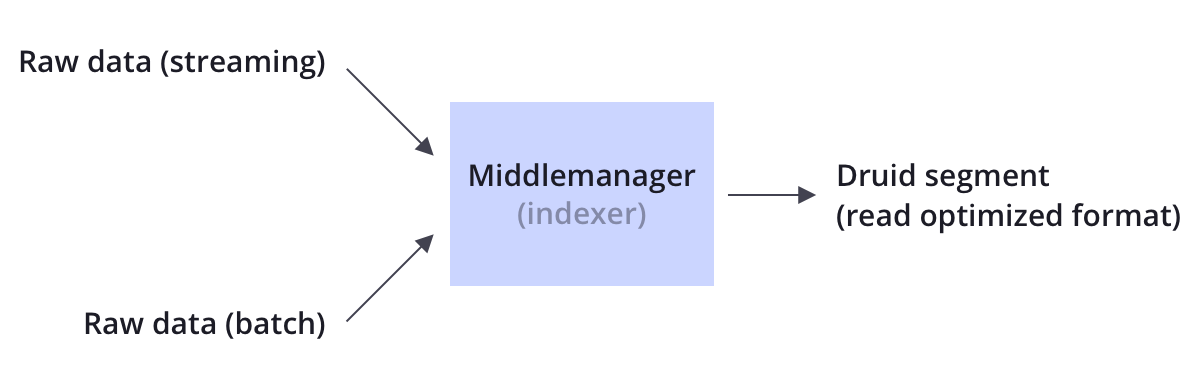
? Druid同時支持流式和批量資料攝入,Druid通常通過像Kafka這樣的訊息總線(加載流式資料)或通過像HDFS這樣的分布式檔案系統(加載批量資料)來連接原始資料源,
? Druid通過Indexing處理將原始資料以segment的方式存盤在資料節點,segment是一種查詢優化的資料結構,
2.5 資料存盤
? 像大多數分析型資料庫一樣,Druid采用列式存盤,根據不同列的資料型別(string,number等),Druid對其使用不同的壓縮和編碼方式,Druid也會針對不同的列型別構建不同型別的索引,
? 類似于檢索系統,Druid為string列創建反向索引,以達到更快速的搜索和過濾,類似于時間序列資料庫,Druid基于時間對資料進行智能磁區,以達到更快的基于時間的查詢,
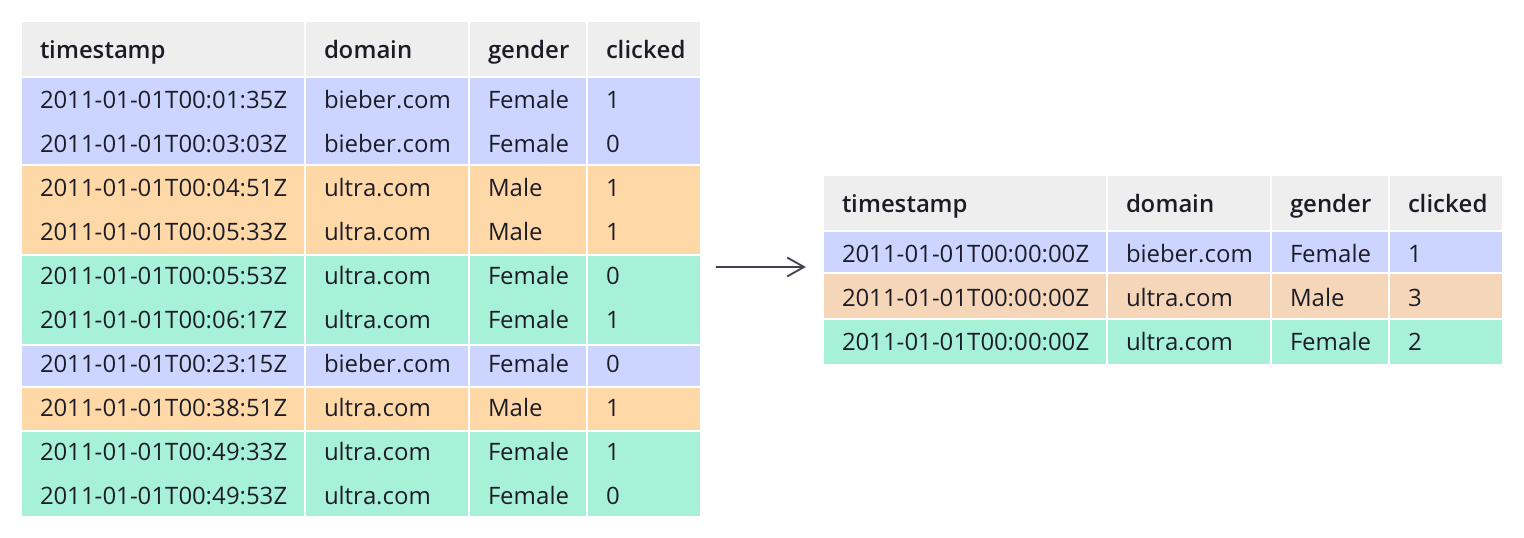
? 不像大多數傳統系統,Druid可以在資料攝入前對資料進行預聚合,這種預聚合操作被稱之為rollup,這樣就可以顯著的節省存盤成本,
2.6 查詢
? Druid支持JSON-over-HTTP和SQL兩種查詢方式,除了標準的SQL操作外,Druid還支持大量的唯一性操作,利用Druid提供的演算法套件可以快速的進行計數,排名和分位數計算,
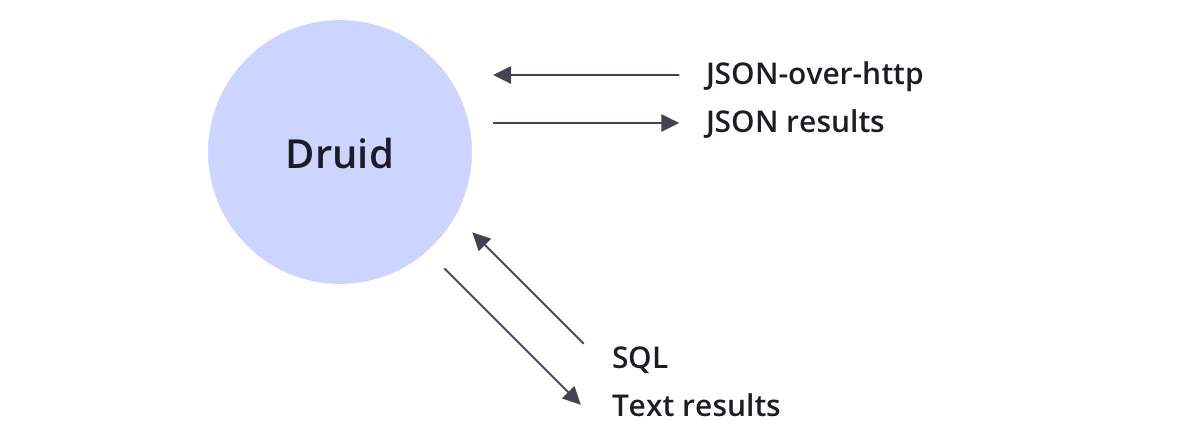
Drui被設計成一個健壯的系統,它需要7*24小時運行,
Druid擁有以下特性,以確保長期運行,并保證資料不丟失,
2.6.1 資料副本
? Druid根據配置的副本數創建多個資料副本,所以單機失效不會影響Druid的查詢,
2.6.2 獨立服務
? Druid清晰的命名每一個主服務,每一個服務都可以根據使用情況做相應的調整,服務可以獨立失敗而不影響其他服務的正常運行,例如,如果資料攝入服務失效了,將沒有新的資料被加載進系統,但是已經存在的資料依然可以被查詢,
2.6.3 自動資料備份
? Druid自動備份所有已經indexed的資料到一個檔案系統,它可以是分布式檔案系統,如HDFS,你可以丟失所有Druid集群的資料,并快速從備份資料中重新加載,
2.6.4 滾動更新
? 通過滾動更新,你可以在不停機的情況下更新Druid集群,這樣對用戶就是無感知的,所有Druid版本都是向后兼容,
3. 安裝部署
3.1 環境介紹
3.1.1 Durid埠串列
以下是Durid默認的埠串列,防止因為埠占用導致服務器啟動失敗
| 角色 | 埠 | 介紹 |
|---|---|---|
| Coordinator | 8081 | 管理集群上的資料可用性 |
| Historical | 8083 | 存盤歷史查詢到的資料 |
| Broker | 8082 | 處理來自外部客戶端的查詢請求 |
| Realtime | 8084 | |
| Overlord | 8090 | 控制資料攝取作業負載的分配 |
| MiddleManager | 8091 | 負責攝取資料 |
| Router | 8888 | 可以將請求路由到Brokers, Coordinators, and Overlords |
3.2 安裝方式
獲取Druid安裝包有以下幾種方式
3.2.1 源代碼編譯
? druid/release,主要用于定制化需求時,比如結合實際環境中的周邊依賴,或者是加入支持特定查詢的部分的優化等,
3.2.2 官網下載
? 官網安裝包下載:download,包含Druid部署運行的最基本組件
3.2.3 Imply組合套件
? Imply,該套件包含了穩定版本的Druid組件、實時資料寫入支持服務、圖形化展示查詢Web UI和SQL查詢支持組件等,目的是為更加方便、快速地部署搭建基于Druid的資料分析應用產品,
3.3 單機配置參考
3.3.1 Nano-Quickstart
1 CPU, 4GB 記憶體
- 啟動命令:
bin/start-nano-quickstart - 配置目錄:
conf/druid/single-server/nano-quickstart
3.3.2 微型快速入門
4 CPU, 16GB 記憶體
- 啟動命令:
bin/start-micro-quickstart - 配置目錄:
conf/druid/single-server/micro-quickstart
3.3.3 小型
8 CPU, 64GB 記憶體 (~i3.2xlarge)
- 啟動命令:
bin/start-small - 配置目錄:
conf/druid/single-server/small
3.3.4 中型
16 CPU, 128GB 記憶體 (~i3.4xlarge)
- 啟動命令:
bin/start-medium - 配置目錄:
conf/druid/single-server/medium
3.3.5 大型
32 CPU, 256GB 記憶體 (~i3.8xlarge)
- 啟動命令:
bin/start-large - 配置目錄:
conf/druid/single-server/large
3.3.6 超大型
64 CPU, 512GB 記憶體 (~i3.16xlarge)
- 啟動命令:
bin/start-xlarge - 配置目錄:
conf/druid/single-server/xlarge
3.4 單機版安裝
3.4.1 軟體要求
- Java 8 (8u92+)
- Linux, Mac OS X, 或者其他的類Unix OS (Windows是不支持的)
- 安裝Docker環境
- 安裝Docker-compose環境
3.4.2 硬體要求
Druid包括幾個單服務配置示例,以及使用這些配置啟動Druid行程的腳本,
? 如果您在筆記本電腦等小型機器上運行以進行快速評估,那么micro-quickstart配置是一個不錯的選擇,適用于 4CPU/16GB RAM環境,如果您計劃在教程之外使用單機部署進行進一步評估,我們建議使用比micro-quickstart更大的配置,
? 雖然為大型單臺計算機提供了示例配置,但在更高規模下,我們建議在集群部署中運行Druid,以實作容錯和減少資源爭用,
3.5 imply方式安裝
安裝推薦Imply方式,Imply方式出了提供druid組件,還有圖形化、報表等功能
3.5.1 安裝perl
因為啟動druid 需要用到perl環境,需要安裝下
yum install perl gcc kernel-devel
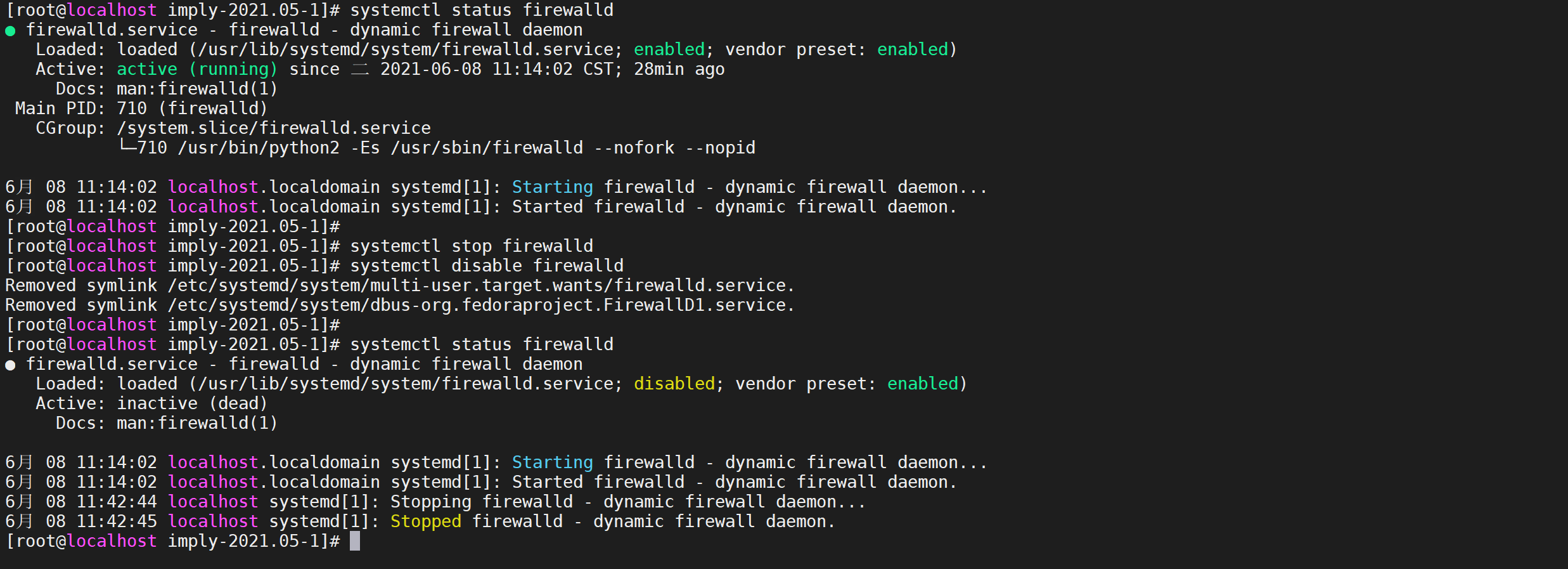
3.5.2 關閉防火墻
#查看防火狀態
systemctl status firewalld
#暫時關閉防火墻
systemctl stop firewalld
#永久關閉防火墻
systemctl disable firewalld
3.5.3 安裝JDK
選擇與自己系統相匹配的版本,我的是Centos7 64位的,所以如果是我的話我會選擇此版本,要記住的你們下載的話選擇的是以tar.gz結尾的,
3.5.3.1 下載JDK
到Oracle 官網下載jdk1.8,選擇
jdk-8u301-linux-x64.tar.gz
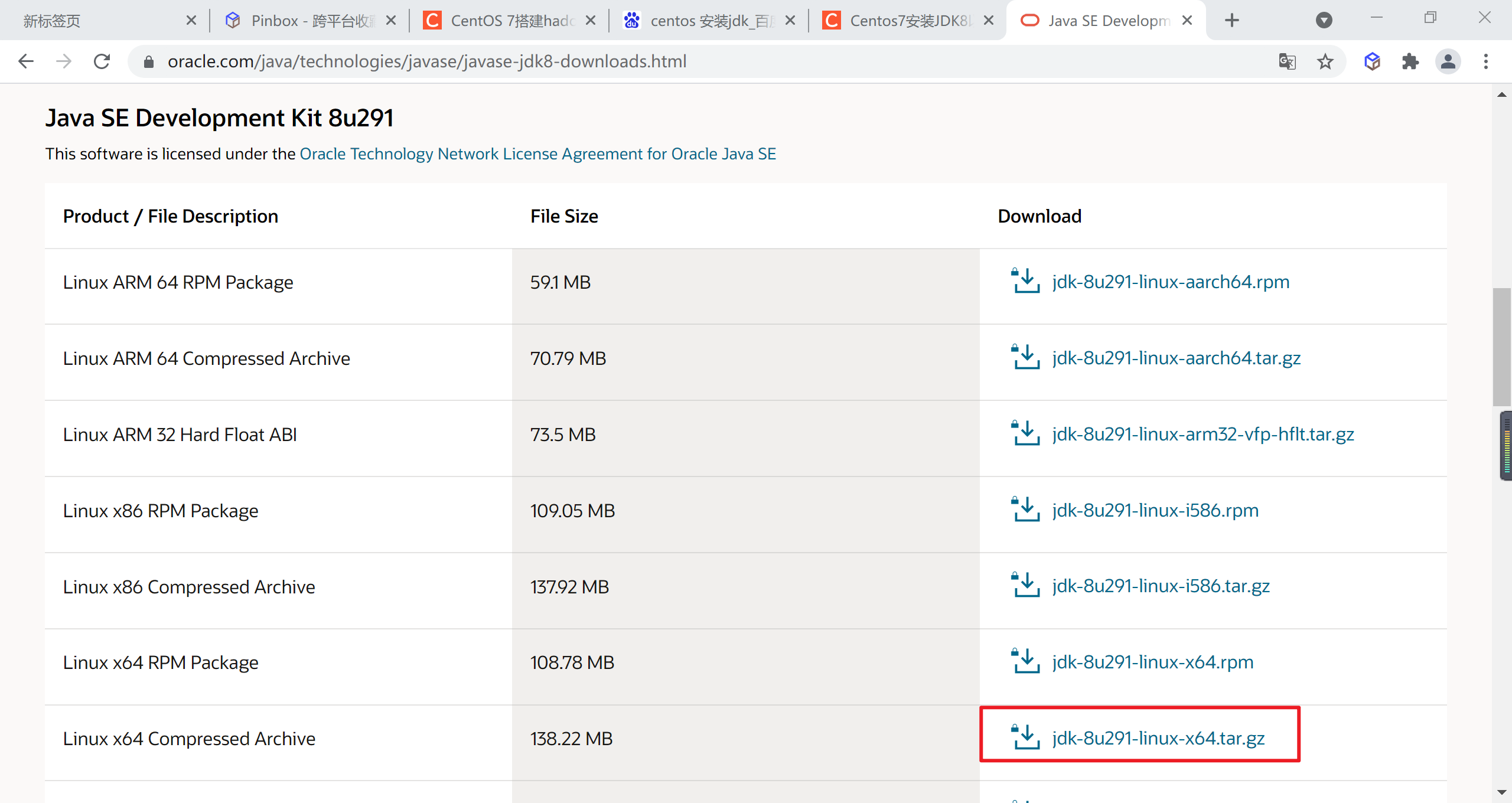
將檔案下載到本地后上傳到linux目錄下
3.5.3.2 上傳解壓
上傳檔案
mkdir /usr/local/java
解壓目錄
tar -zxvf jdk-8u301-linux-x64.tar.gz
3.5.3.3 配置環境變數
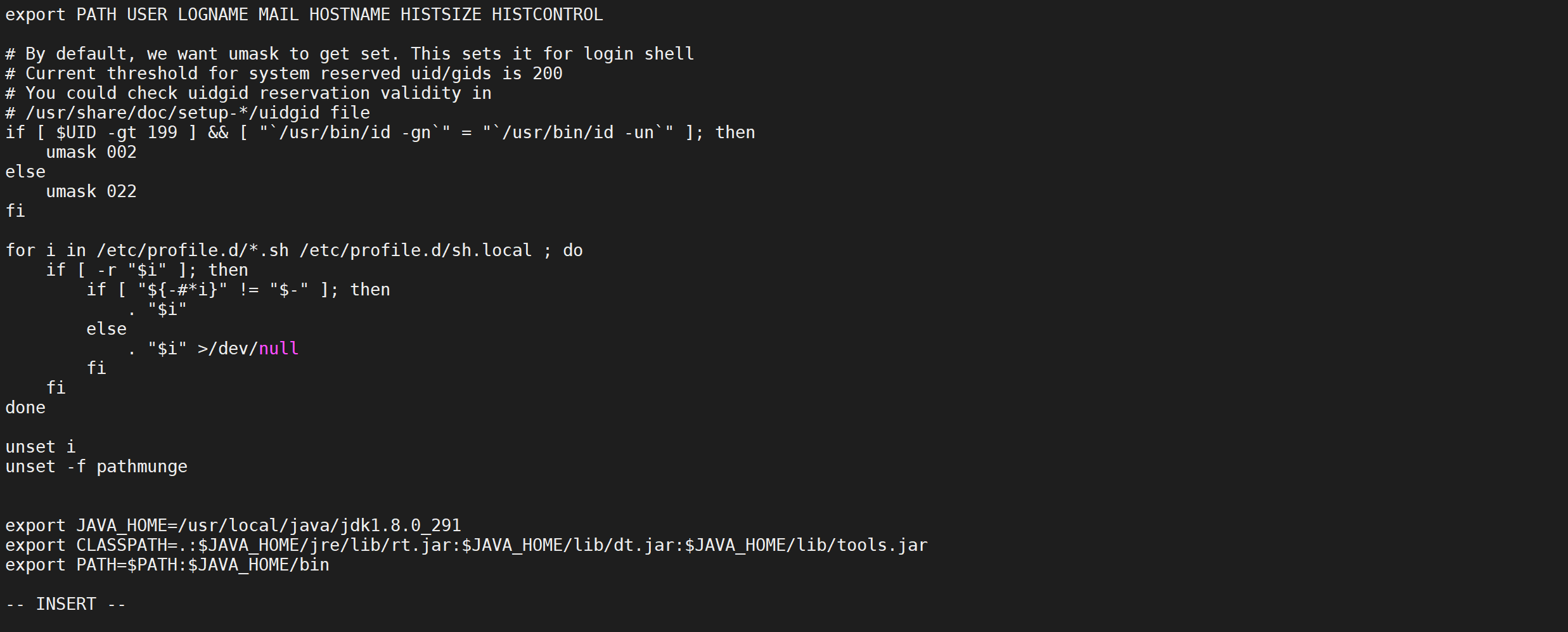
配置環境變數,修改profile檔案并加入如下內容
vi /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_301
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3.5.3.4 生效配置
source /etc/profile
3.5.3.5 檢查環境
java -version

3.5.4 安裝imply
3.5.4.1 登錄Imply官網
訪問https://imply.io/get-started,進入Imply官網,查找合適的imply的版本的安裝包,并填寫簡要資訊后就可以下載了
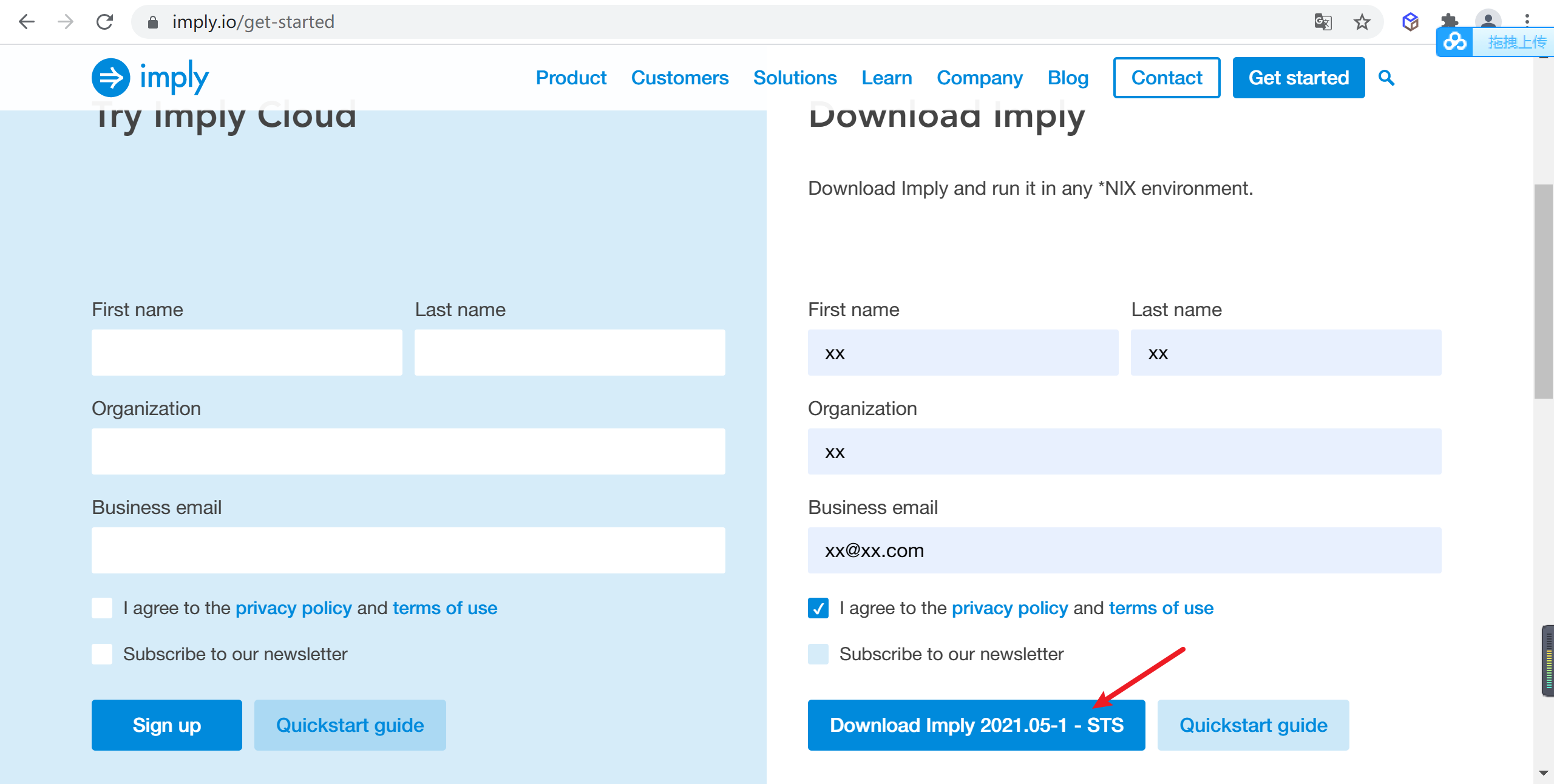
3.5.4.2 解壓imply
下載后上傳到服務器,并進行解壓
# 創建imply安裝目錄
mkdir /usr/local/imply
# 解壓imply
tar -zxvf imply-2021.05-1.tar.gz
3.5.4.3 環境準備
進入
imply-2021.05-1目錄后
# 進入imply目錄
cd imply-2021.05-1
3.5.4.4 快速啟動
使用本地存盤、默認元資料存盤derby,自帶zookeeper啟動,來體驗下
druid
# 創建日志目錄
mkdir logs
# 使用命令啟動
nohup bin/supervise -c conf/supervise/quickstart.conf > logs/quickstart.log 2>&1 &
3.5.4.5 查看日志
通過
quickstart.log來查看impl啟動日志
tail -f logs/quickstart.log
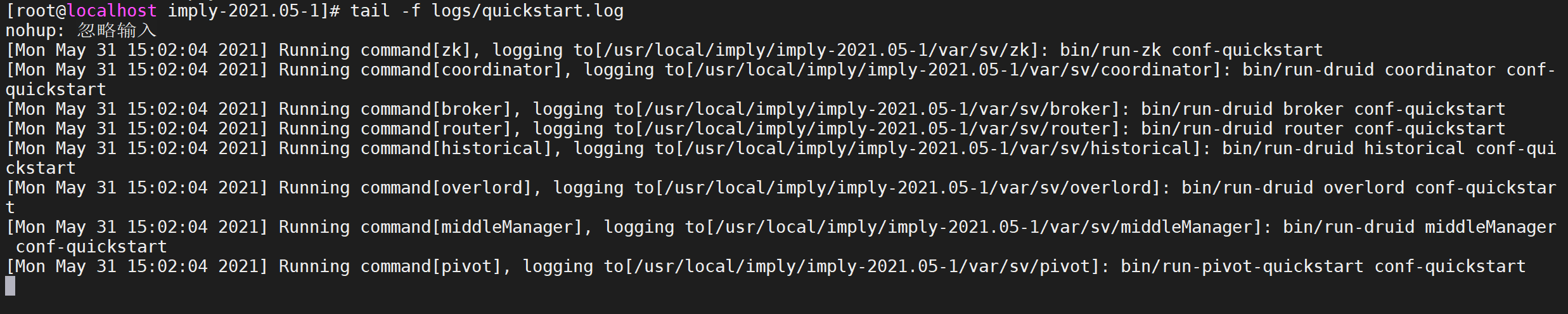
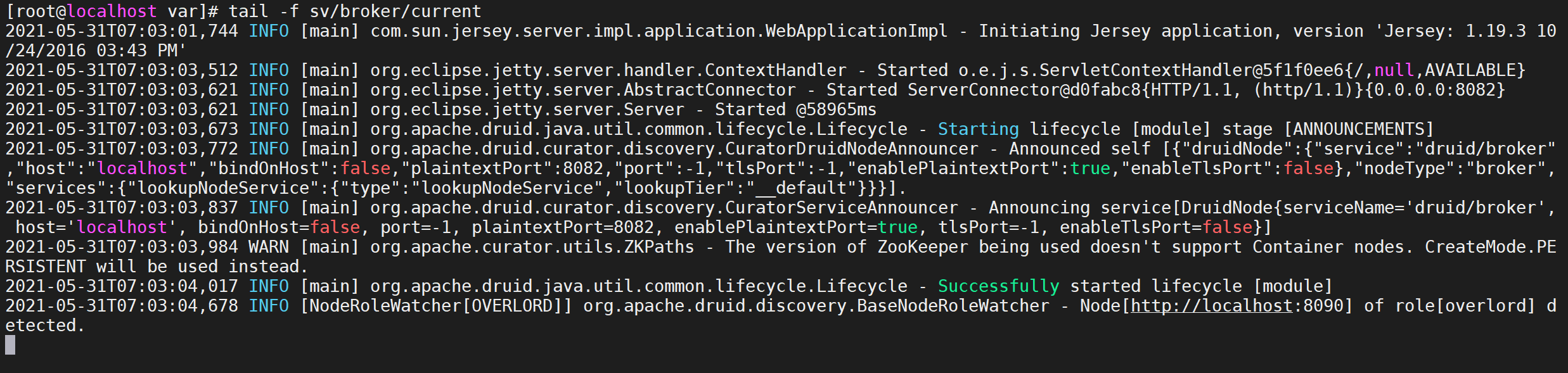
每啟動一個服務均會列印出一條日志,可以通過var/sv/xxx/current查看服務啟動時的日志資訊
tail -f var/sv/broker/current
3.5.4.6 訪問Imply
可以通過訪問
9095埠來訪問imply的管理頁面
http://192.168.64.173:9095/

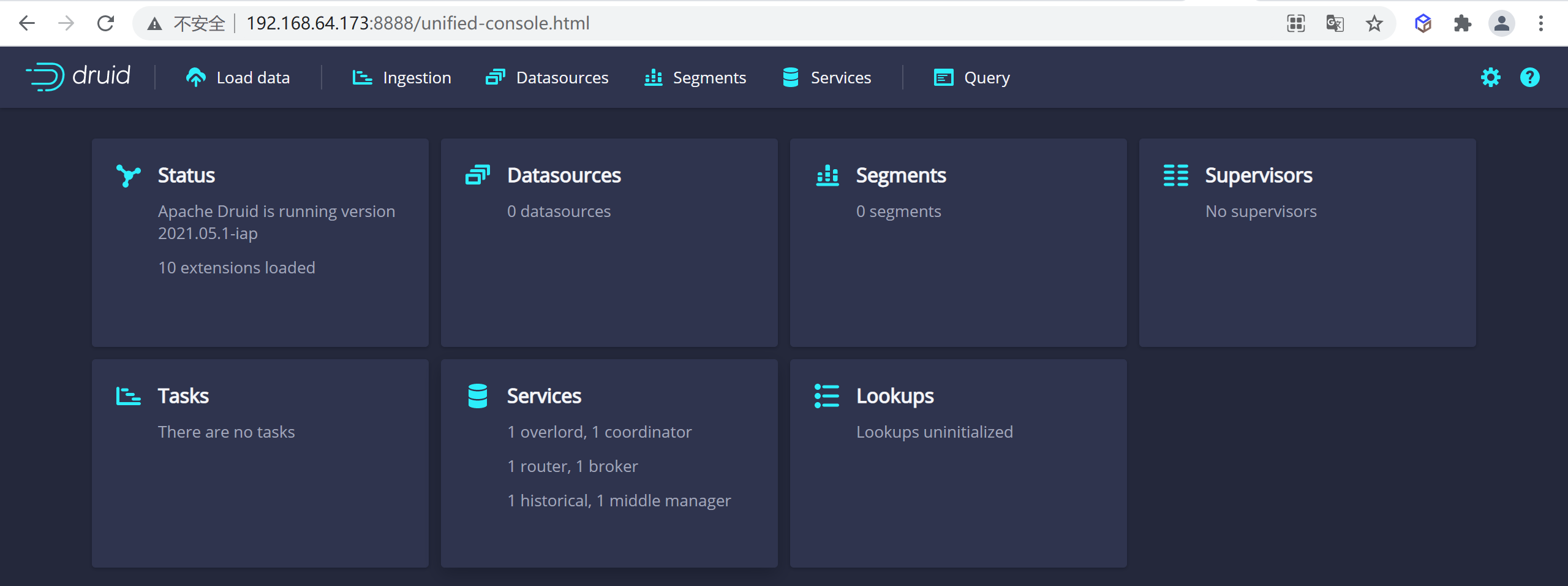
3.5.4.7 訪問Druid
訪問
8888埠就可以訪問到我們的druid了
http://192.168.64.173:8888/
本文由傳智教育博學谷 - 狂野架構師教研團隊發布
如果本文對您有幫助,歡迎關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力
轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/502822.html
標籤:其他
上一篇:類和物件