集合
筆記目錄:(https://www.cnblogs.com/wenjie2000/p/16378441.html)
前面我們保存多個資料使用的是陣列,那么陣列有不足的地方,我們分析一下,
●陣列
- 長度開始時必須指定,而且一旦指定,不能更改
- 保存的必須為同一型別的元素
- 使用陣列進行增加元素的示意代碼-比較麻煩
寫出Person陣列擴容示意代碼,
Person[] pers = new Person[1]; // 大小是1
pers[0] = new Person();
//增加新的Person物件 ?
Person[]pers2 = new Person[pers.length + 1];//新創建陣列
for(){} //拷貝pers陣列的元素到pers2
pers2[pers2.length - 1] = new Person();//添加新的物件
集合
- 可以動態保存任意多個物件,使用比較方便!
- 提供了一系列方便的操作物件的方法:add、remove、set、get等
- 使用集合添加,洗掉新元素的示意代碼-簡潔了
集合的框架體系
Java的集合類很多,主要分為兩大類,如圖:[背下來]
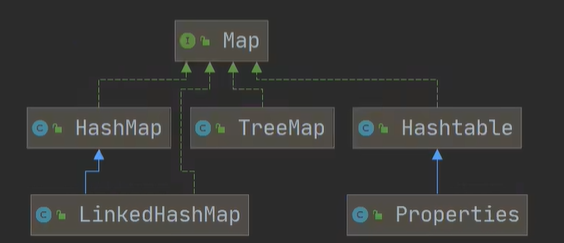
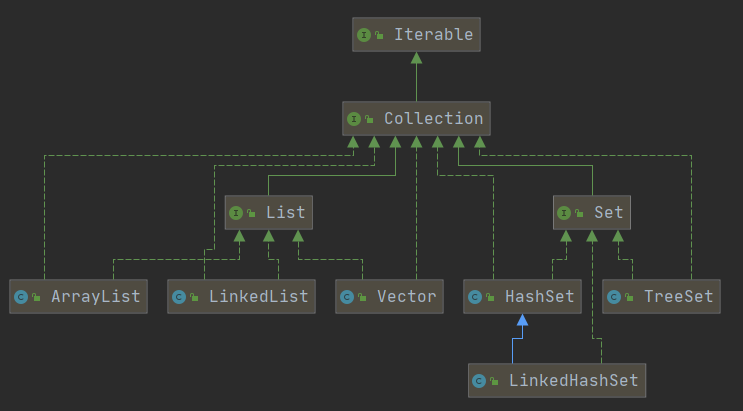
//老韓解讀
//1,集合主要是兩組(單列集合,雙列集合)
//2. Collection介面有兩個重要的子介面 List Set,他們的實作子類都是單列集合
//3. Map介面的實作子類是雙列集合,存放的 K-V
//4,把老師梳理的兩張圖記住
//collection
//Map
ArrayList arrayList = new ArrayList();
arrayList.add("jack ");
arrayList.add("tom");
HashMap hashMap = new HashMap();
hashMap.put("NO1", "北京");
hashMap.put("NO2","上海");
Collection
Collection介面實作類的特點
- collection實作子類可以存放多個元素,每個元素可以是Object
- 有些Collection的實作類,可以存放重復的元素,有些不可以
- 有些Collection的實作類,有些是有序的(List),有些不是有序(Set)
- Collection介面沒有直接的實作子類,是通過它的子介面Set 和 List來實作的
Collection介面常用方法,以實作子類ArrayList來演示.
-
add:添加單個元素
-
remove:洗掉指定元素
-
contains:查找元素是否存在
-
size:獲取元素個數
-
isEmpty:判斷是否為空
-
clear:清空
-
addAll:添加多個元素
-
containsAll:查找多個元素是否都存在
-
removeAll:洗掉多個元素
-
說明:以ArrayList實作類來演示.
List list = new ArrayList();
//add :添加單個元素
list.add("jack");
list.add(10);//此處10自動轉為Integer型別 list.add(new Integer(10))
list.add(true);
System.out.println("list=" + list);//list=[jack, 10, true]
//remove:洗掉指定元素
//list.remove(0);//洗掉第一個元素
list.remove(true) ;//指定洗掉某個元素
list.remove((Integer)10);//如果直接填10,java會認為是移除串列中第11個物件
System.out.println("list=" + list);//list=[jack]
//contains:查找元素是否存在
System.out.println(list.contains( "jack"));//T
//size:獲取元素個數
System.out.println(list.size());//1
//isEmpty:判斷是否為空
System.out.println(list.isEmpty());//F
//clear:清空list.clear();
list.clear();
System.out.println("list="+ list);//list=[]
//addAll:添加多個元素(只要實作了collection介面就能作為引數)
ArrayList list2 = new ArrayList();
list2.add("紅樓夢");list2.add("三國演義");
list.addAll(list2);
System.out.println("list=" + list);//list=[紅樓夢, 三國演義]
//containsAll:查找多個元素是否都存在(只要實作了collection介面就能作為引數)
System.out.println(list.containsAll(list2));//T
// removeAll:洗掉多個元素
list.add("聊齋");
list.removeAll(list2);
System.out.println("list=" + list);//list=[聊齋]
//說明:以ArrayList實作類來演示,
Collection介面遍歷元素方式1-使用Iterator(迭代器)
-
Iterator物件稱為迭代器,主要用于遍歷Collection集合中的元素,
-
所有實作了Collection介面的集合類都有一個iterator()方法,用以回傳一個實作了lterator介面的物件,即可以回傳一個迭代器,
-
Iterator的結構.[看圖]

- Iterator僅用于遍歷集合,lterator本身并不存放物件.
提示:在呼叫iterator.next()方法之前必須要呼叫iterator.hasNext()進行檢測,若不呼叫,且下一條記錄無效,直接呼叫it.next()會拋出NoSuchElementException例外,
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三國演義", "羅貫中", 10.1));
col.add(new Book("小李飛刀", "古龍", 5.1));
col.add(new Book("紅樓夢", "曹雪芹", 34.6));
// System.out.println("col=" + col);
//現在老師希望能夠遍歷col集合
//1,先得到col對應的迭代器
Iterator iterator = col.iterator();
//2.使用while回圈遍歷
//快捷鍵,快速生成while => itit (顯示所有的快捷鍵的的快捷鍵ctrl + j)
while (iterator.hasNext()) {//判斷是否還有資料
//回傳下一個元素,型別是0bject
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//3.當退出while回圈后,這時iterator迭代器,指向最后的元素
// iterator.next();//NoSuchElementException
// 4,如果希望再次遍歷,需要重置我們的迭代器
iterator=col.iterator();
System.out.println( "===第二次遍歷===");
while (iterator.hasNext()) {//判斷是否還有資料
//回傳下一個元素,型別是0bject
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
}
}
class Book {
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
Collection介面遍歷物件方式2-for回圈增強.
增強for回圈,可以代替iterator迭代器,特點:增強for就是簡化版的iterator,本質一樣,只能用于遍歷集合或陣列,
>基本語法
for(元素型別 元素名:集合名或陣列名){
訪問元素
}
演示
import java.util.ArrayList;
import java.util.Collection;
public class Test {
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("三國演義", "羅貫中", 10.1));
col.add(new Book("小李飛刀", "古龍", 5.1));
col.add(new Book("紅樓夢", "曹雪芹", 34.6));
//老韓解讀
//1.使用增強for,在Collection集合
// 2.增強for,底層仍然是迭代器
//3.增強for可以理解成就是簡化版本的迭代器遍歷
for (Object book : col) {
System.out.println("book=" + book);
}
//增強for,也可以直接在陣列使用
int[] nums = {1, 8, 10, 90};
for (int i : nums) {
System.out.println("i=" + i);
}
}
}
class Book {
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
}
List
List介面基本介紹
List 介面是Collection 介面的子介面 List .java
-
List集合類中元素有序(即添加順序和取出順序一致)、且可重復
-
List集合中的每個元素都有其對應的順序索引,即支持索引,(list.get(3))
-
List容器中的元素都對應一個整數型的序號記載其在容器中的位置,可以根據序號存取容器中的元素,
-
JDK API中List介面的實作類布置前文圖中展示的:
常用的有:ArrayList、LinkedList和Vector,
List介面的常用方法
List 集合里添加了一些根據索引來操作集合元素的方法
-
void add(int index, Object ele):在index位置插入ele元素
-
boolean addAll(int index, Collection eles):從index位置開始將eles中的所有元素添加進來
-
Object get(int index):獲取指定index位置的元素
-
int indexOf(Object obj):回傳obj在集合中首次出現的位置
-
int lastlndexOf(Object obj):回傳obj在當前集合中末次出現的位置
-
Object remove(int index):移除指定index位置的元素,并回傳此元素
-
Object set(int index,Object ele):設定指定index位置的元素為ele ,相當于是替換
-
List subList(int fromlndex, int tolndex):回傳從fromIndex到tolndex位置的子集合
List list = new ArrayList();
list.add("張三豐");
list.add("賈寶玉");
//void add(int index,0bject ele):在index位置插入ele元素
// 在index =1的位置插入一個物件
list.add(1, "韓順平");
System.out.println("list=" + list);
//boolean addAll(int index,Collection eles):從index位置開始將eles中的所有元素添加進來
List list2 = new ArrayList();
list2.add("jack");
list2.add("tom");
list.addAll(1, list2);
System.out.println("list=" + list);
//Object get(int index):獲取指定index位置的元素
//說過
//int indexOf(0bject obj):回傳obj在集合中首次出現的位置
System.out.println(list.indexOf("tom"));//2
//int lastIndexOf(Object obj):回傳obj在當前集合中末次出現的位置
list.add("韓順平");
System.out.println("list=" + list);
System.out.println(list.lastIndexOf("韓順平"));
//Object remove(int index):移除指定index位置的元素,并回傳此元素(直接修改list,而非回傳新的)
list.remove(0);
System.out.println("list=" + list);
//Object set(int index,0bject ele):設定指定index位置的元素為ele,相當于是替換
list.set(1, "瑪麗");
System.out.println("list=" + list);
//List subList(int fromIndex,int toIndex):回傳從fromIndex到toIndex位置的子集合
//注意回傳的子集合fromIndex <= subList < toIndex
List returnlist = list.subList(0, 2);//如果改動list元后,再列印returnlist會報錯,所以一般是即查即用
System.out.println("returnlist=" + returnlist);
List的三種遍歷方式 [ArrayList, LinkedList,Vector]
-
方式一:使用iterator
lterator iter = col.iterator(); while(iter.hasNext0){ Object o = iter.next(); } -
方式二:使用增強for
for(Object o:col){ } -
方式三:使用普通for
for(int i=o;i<list.size();i++){ Object object = list.get(i); System.out.println(object); }
說明:使用LinkedList完成使用方式和ArrayList一樣
★ArrayList
ArrayList的注意事項
- permits all elements, including null ,ArrayList可以加入null,并且多個
- ArrayList是由陣列來實作資料存盤的
- ArrayList基本等同于Vector,除了ArrayList是執行緒不安全(執行效率高)看原始碼.在多執行緒情況下,不建議使用ArrayList
ArrayList的底層操作機制原始碼分析(重點,難點.)
先說結論,在分析原始碼(示意圖)
- ArrayList中維護了一個Object型別的陣列elementData. [debug 看原始碼]
transient Object[] elementData;//transient表示瞬間,短暫的,表示該屬性不會被序列化
-
當創建ArrayList物件時,如果使用的是無參構造器,則初始elementData容量為0,第1次添加,則擴容elementData為10,如需要再次擴容,則擴容elementData為1.5倍,
-
如果使用的是指定大小的構造器,則初始elementData容量為指定大小,如果需要擴容,則直接擴容elementData為1.5倍,
建議:自己去debug一把我們的ArrayList的創建和擴容的流程,
★Vector
Vector的基本介紹
-
Vector類的定義說明
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable -
Vector底層也是一個物件陣列,protected Object[] elementData;
-
Vector是執行緒同步的,即執行緒安全, Vector類的操作方法帶有synchronized
public synchronized E get(int index) { if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); return elementData(index); } -
在開發中,需要執行緒同步安全時,考慮使用Vector
Vector和ArrayList的比較
| 底層結構 | 版本 | 執行緒安全(同步)效率 | 擴容倍數 | |
|---|---|---|---|---|
| ArrayList | 可變陣列 | jdk1.2 | 不安全,效率高 | 如果有參構造1.5倍 如果是無參 1.第一次10 2.從第二次開始安1.5擴 |
| Vector | 可變陣列Object[] | jdk1.0 | 安全,效率不高 | 如果是無參,默認10,滿后,就按2倍擴容 如果指定大小,則每次直接按2倍擴 |
LinkedList
LinkedList的全面說明
- LinkedList底層實作了雙向鏈表和雙端佇列特點
- 可以添加任意元素(元素可以重復),包括null
- 執行緒不安全,沒有實作同步
LinkedList的底層操作機制(需要有資料結構的雙向鏈表基礎)
- LinkedList底層維護了一個雙向鏈表.
- LinkedList中維護了兩個屬性first和last分別指向首節點和尾節點
- 每個節點(Node物件),里面又維護了prev、next、item三個屬性,其中通過prev指向前一個,通過next指向后一個節點,最終實作雙向鏈表,
- 所以LinkedList的元素的添加和洗掉,不是通過陣列完成的,相對來說效率較高,
- 模擬一個簡單的雙向鏈表【走代碼】
LinkedList的增刪改查案例
//建議用debug去看原始碼
LinkedList linkedList = new LinkedList();
for (int i = 1; i <= 2; i++) {
linkedList.add(0);
}
linkedList.add(100);
linkedList.add(100);
for (Object object : linkedList) {
System.out.println(object);
}
// linkedList.remove(0);
// linkedList.remove(kk);
linkedList.set(0, "韓順平教育");
System.out.println("===");
for (Object object : linkedList) {
System.out.println(object);
}
Object object = linkedList.get(0);
System.out.println("object=" + object);
System.out.println(linkedList.getFirst());
System.out.println(linkedList.getLast());
ArrayList和LinkedList的比較
| 底層結構 | 增刪的效率 | 改查的效率 | |
|---|---|---|---|
| ArrayList | 可變陣列 | 較低 陣列擴容 | 較高 |
| LinkedList | 雙向鏈表 | 較高,通過鏈表追加 | 較低 |
如何選擇ArrayList和LinkedList:
- 如果我們改查的操作多,選擇ArrayList
- 如果我們增刪的操作多,選擇LinkedList
- 一般來說,在程式中,80%-90%都是查詢,因此大部分情況下會選擇ArrayList
- 在一個專案中,根據業務靈活選擇,也可能這樣,一個模塊使用的是ArrayList,另外一個模塊是LinkedList,也就是說,要根據業務來進行選擇
Set
Set介面基本介紹
- 無序(添加和取出的順序不一致),沒有索引[后面演示]
- 不允許重復元素,所以最多包含一個null
Set介面的常用方法
和List介面一樣,Set介面也是Collection的子介面,因此,常用方法和Collection介面一樣.
Set介面的遍歷方式
同Collection的遍歷方式一樣,因為Set介面是Collection介面的子介面,
- 可以使用迭代器
- 增強for
- 不能使用索引的方式來獲取.
//1,以Set介面的實作類 HashSet 來講解Set介面的方法
//2. set 介面的實作類的物件(Set介面物件),不能存放重復的元素,可以添加一個null
//3. set介面物件存放資料是無序(即添加的順序和取出的順序不一致)
//4,注意:取出的順序的順序雖然不是添加的順序,但是他的固定,
Set set = new HashSet();
set.add("john");
set.add("lucy ");
set.add("john ");//重復 不會報錯,但也不會再次添加到set中 執行add方法后會回傳boolean值,成功true,失敗false
set.add("jack");
set.add("hsp");
set.add("mary");
set.add(null);//
set.add(null);//再次添加null, 不會報錯,但也不會再次添加到set中
set.remove("jack");
for (int i = 0; i < 10; i++) {
System.out.println("set=" + set);
}
//遍歷
//方式1:使用迭代器
System.out.println("=====使用迭代器====");
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object obj = iterator.next();
System.out.println("obj=" + obj);
}
//方式2:增強for
System.out.println( "=====增強for==== ");
for (Object o : set) {
System.out.println("o=" + o);
}
//set介面物件,不能通過索引來獲取
★HashSet
HashSet的全面說明
-
HashSet實作了Set介面
-
HashSet實際上是HashMap,看下原始碼.
public HashSet() { map = new HashMap<>(); } -
可以存放null值,但是只能有一個null
-
HashSet不保證元素是有序的,取決于hash后,再確定索引的結果.(即不保證存放和取出順序一致)
-
不能有重復元素/物件.在前面Set 介面使用已經講過(主要是看物件的地址,兩個地址不同,則使用equals方法判斷,看如下案例)
public class Test { public static void main(String[] args) { Set set = new HashSet(); System.out.println("set=" + set); //0 // 4 Hashset不能添加相同的元素/資料? set.add("lucy");//添加成功 set.add("Lucy");//加入不了 set.add(new Dog("tom"));//0K set.add(new Dog("tom"));//0k System.out.println("set=" + set);//set=[Dog{name='tom'}, Lucy, Dog{name='tom'}, lucy] //在加深一下,非常經典的面試題. //看原始碼,做分析,先給小伙伴留一個坑,以后講完原始碼,你就了然 //去看他的原始碼,即add到底發生了什么? set.add(new String("hsp"));//ok set.add(new String("hsp"));//加入不了, System.out.println( "set=" +set); } } class Dog { private String name; public Dog(String name) { this.name = name; } @Override public String toString() { return "Dog{" + "name='" + name + '\'' + '}'; } }
HashSet底層機制說明
分析HashSet的添加元素底層是如何實作(hash()+equals())
- HashSet底層是HashMap,第一次添加時,table陣列擴容到16,臨界值(threshold)是16*加載因子
(loadFactor)是0.75 = 12 - 如果table陣列使用到了臨界值size=12(此處的size指的是添加 的元素數量,而不是陣列元素數量),就會擴容到16*2 = 32,新的臨界值就是32*0.75 =24,依次類推
- 添加一個元素時,先得到hash值-會轉成->索引值
- 找到存盤資料表table,看這個索引位置是否已經存放的有元素
- 如果沒有,直接加入
- 如果有,呼叫equals比較(根據需求可在類中重寫equals()和hashCode()),如果相同,就放棄添加,如果不相同,則添加到最后
- 在Java8中,如果一條鏈表的元素個數大于 TREEIFY_THRESHOLD(默認是8),并且table的大小>=
MIN_TREEIFY_CAPACITY(默認64),就會進行樹化(紅黑樹),否則 任采用陣列擴容機制
//這里建議debug去看原始碼hashSet.add的原始碼
//筆記不方便說明,B站韓順平java課程P522和p523有詳細講解 需要重點掌握
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set=" + hashSet);
LinkedHashSet
LinkedHashSet底層任然呼叫HashSet,在它的基礎上就只是重寫了afterNodeAccess(e),加入了雙向鏈表,使添加和取出順序相同,核心部分還是呼叫的HashSet原始碼,
LinkedHashSet的全面說明
- LinkedHashSet 是 HashSet的子類
- LinkedHashSet底層是一個 LinkedHashMap,底層維護了一個陣列+雙向鏈表
- LinkedHashSet根據元素的hashCode值來決定元素的存盤位置,同時使用鏈表維護元素的次序(圖),這使得元素看起來是以插入順序保存的,
- LinkedHashSet不允許添重復元素
LinkedHashSet底層機制示意圖
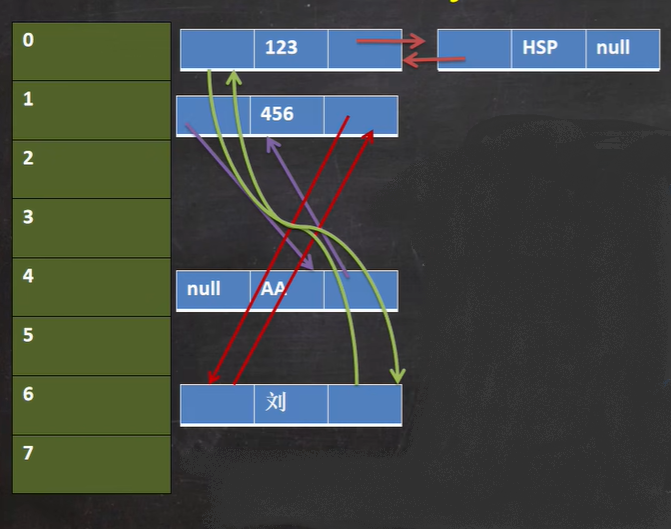
說明
- 在LinkedHastSet中維護了一個hash表和雙向鏈表(LinkedHashSet有head和tail )
- 每一個節點有pre和next屬性,這樣可以形成雙向鏈表3)在添加一個元素時,先求hash值,在求索引.,確定該元素在hashtable的位置,然后將添加的元素加入到雙向鏈表(如果已經存在,不添加[原則和hashset一樣])
tail.next = newElement //簡單指定
newElement.pre = tail
tail = newEelment; - 這樣的話,我們遍歷LinkedHashSet 也能確保插入順序和遍歷順序一致
TreeSet
按照資料型別默認排序,也可以根據自定義內部類自定義排序(底層為TreeMap)
添加的物件對應的類要么實作Comparable要么自定義排序,否則會報錯(原理看原始碼)
//1,當我們使用無參構造器,創建TreeSet時,是默認案編碼順序排
//2,老師希望添加的元素,按照字串大小來排序
//3.使用TreeSet提供的一個構造器,可以傳入一個比較器(匿名內部類)
// 并指定排序規則
//TreeSet treeSet = new TreeSet();
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//下面呼叫String的 compareTo方法進行字串大小比較
return ((String) o2).compareTo((String) o1);//注意回傳值為0時不添加,具體原因看原始碼
}
});
//添加資料,
treeSet.add("jack");
treeSet.add("tom");
treeSet.add("sp");
treeSet.add("a");
treeSet.add("abc");
System.out.println("treeSet=" + treeSet);
Map
Map介面實作類的特點[很實用]
注意:這里講的是JDK8的Map介面特點
-
Map與Collection并列存在,用于保存具有映射關系的資料:Key-Value
-
Map 中的key和value可以是任何參考型別的資料,會封裝到HashMap$Node物件中
-
Map中的key不允許重復,原因和HashSet一樣,前面分析過原始碼.(如果存在key相同,則會替換掉之前的key-value)
-
Map中的value可以重復
-
Map 的key 可以為null, value也可以為null,注意key為null, 只能有一個,value為null,可以多個.
-
常用String類作為Map的key
-
key和 value之間存在單向一對一關系,即通過指定的key總能找到對應的value(例:map.get(key)會回傳value)
-
Map存放資料的key-value示意圖,一對k-v是放在一個HashMap$Node中的,有因為Node 實作了 Entry 介面,有些書上也說一對k-v就是一個Entry
Map介面常用方法
- put:添加
- remove:根據鍵洗掉映射關系
- get:根據鍵獲取值(例Object value=https://www.cnblogs.com/wenjie2000/p/map.get(key);)
- size:獲取元素個數
- isEmpty:判斷個數是否為0
- clear:清除
- containsKey:查找鍵是否存在
Map介面遍歷方法
-
containsKey:查找鍵是否存在
-
keySet:獲取所有的鍵
-
entrySet:獲取所有關系k-v
-
values:獲取所有的值
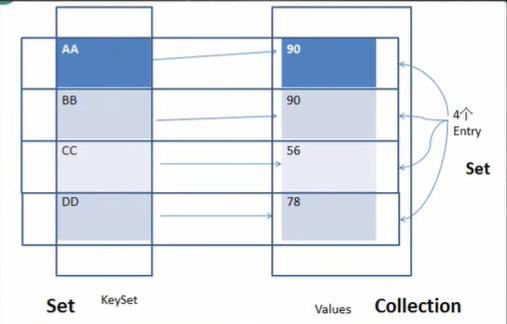
Map map = new HashMap();
map.put("鄧超", "孫儷");
map.put("王寶強", "馬蓉");
map.put("宋喆", "馬蓉");
map.put("劉令博", null);
map.put(null, "劉亦菲");
map.put("鹿啥", "關曉彤");
//第一組:先取出所有的Key ,通過Key取出對應的Value
Set keyset = map.keySet();
//(1)增強for
System.out.println("-—---第一種方式------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2)迭代器
System.out.println("----第二種方式--—-----");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//第二組:把所有的values取出
Collection values = map.values();
//這里可以使用所有的Collections使用的遍歷方法
// (1)增強for
System.out.println("---取出所有的value 增強for----");
for (Object value : values) {
System.out.println(value);
}
//(2)迭代器
System.out.println("---取出所有的value迭代器----");
Iterator iterator2 = values.iterator();
while (iterator2.hasNext()) {
Object value = https://www.cnblogs.com/wenjie2000/p/iterator2.next();
System.out.println(value);
}
//第三組:通過EntrySet來獲取k-v
Set entrySet = map.entrySet();// EntrySet>//(1)增強for
System.out.println("----使用EntrySet 的 for增強(第三種)----");
for (Object entry : entrySet) {
//將entry 轉成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2)迭代器
System.out.println("----使用EntrySet的迭代器(第4種)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next. getClass());//HashMap$Node -實作->Hap.Entry (getKey , getValue)
// 向下轉型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
★HashMap
HashMap小結
- Map介面的常用實作類:HashMap、Hashtable和Properties.
- HashMap是 Map 介面使用頻率最高的實作類,
- HashMap 是以 key-val對的方式來存盤資料(HashMap$Node型別)[案例Entry ]
- key不能重復,但是值可以重復,允許使用null鍵和null值,
- 如果添加相同的key,則會覆寫原來的key-val,等同于修改.(key不會替換,val會替換)
- 與HashSet一樣,不保證映射的順序,因為底層是以hash表的方式來存盤的. (jdk8的hashMap底層陣列+鏈表+紅黑樹)
- HashMap沒有實作同步,因此是執行緒不安全的,方法沒有做同步互斥的操作,沒有synchronized
HashMap底層機制及原始碼剖析
擴容機制[和HashSet相司]
- HashMap底層維護了Node型別的陣列table,默認為null
- 當創建物件時,將加載因子(loadfactor)初始化為0.75.
- 當添加key-val時,通過key的哈希值得到在table的索引,然后判斷該索引處是否有元素,如果沒有元素直接添加,如果該索引處有元素,繼續判斷該元素的key是否和準備加入的key相等,如果相等,則直接替換value;如果不相等需要判斷是樹結構還是鏈表結構,做出相應處理,如果添加時發現容量不夠,則需要擴容,
- 第1次添加,則需要擴容table容量為16,臨界值(threshold)為12(0.75*16).
- 以后再擴容,則需要擴容table容量為原來的2倍,臨界值為原來的2倍,即24,,依次類推,
- 在Java8中,如果一條鏈表的元素個數超過TREEIFY_THRESHOLD(默認是8),并且table的大小>= MIN_TREEIFY_CAPACITY(默認64),就會進行樹化(紅黑樹)
Hashtable
HashTable的基本介紹
- 存放的元素是鍵值對:即K-V
- hashtable的鍵和值都不能為null,否則會拋出NullPointerException
- hashTable使用方法基本上和HashMap一樣
- hashTable是執行緒安全的(synchronized), hashMap是執行緒不安全的
- 簡單看下底層結構
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
// table.put(null, 100);// 例外 NullPointerException
//table.put("john" ,null);//例外NullPointerException
table.put("lucy", 100); //ok
table.put("lic", 100); //ok
table.put("lic", 88);//替換
System.out.println(table);
//簡單說明一下Hashtable的底層
//1,底層有陣列 Hashtable$Entry[]初始化大小為1
//2,臨界值threshold 8 = 11 * 0.75
//3.擴容:按照自己的擴容機制來進行即可.
//4.執行方法 addEntry(hash,key,value,index);添加K-V封裝到Entry
//5.當if (count >= threshold)滿足時,就進行擴容
//6.按照int newCapacity = (oldCapacity << 1) +1;的大小擴容.
Hashtable和 HashMap對比
| 版本 | 執行緒安全(同步) | 效率 | 允許null建null值 | |
|---|---|---|---|---|
| HashMap | 1.2 | 不安全 | 高 | 可以 |
| HashTable | 1.0 | 安全 | 較低 | 不可以 |
LinkedHashMap
略(底層邏輯為HashMap添加了雙向鏈表,原理如LinkedHashSet)
TreeMap
//使用默認的構造器,創建TreeMap,是無序的(也沒有排序)
/*
要求:按照傳入的k(String)的大小進行排序
*/
//TreeMap treeMap = new TreeMap();
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照傳入的 k(String)的大小進行排序
//按照K(String)的長度大小排序
// return ((String) o2).compareTo((String) o1);
return ((String) o1).length() - ((String) o2).length();//注意回傳值為0時不添加,具體原因看原始碼
}
});
treeMap.put("jack", "杰克");
treeMap.put("tom", "湯姆");
treeMap.put("kristina", "克瑞斯提諾");
treeMap.put("smith", "斯密斯");
System.out.println("treemap=" + treeMap);
Properties
基本介紹
- Properties類繼承自Hashtable類并且實作了Map介面,也是使用一種鍵值對的形式來保存資料,
- 他的使用特點和Hashtable類似
- Properties還可以用于從xxx.properties檔案中,加載資料到Properties類物件,并進行讀取和修改
- 說明:作業后 xxx.properties檔案通常作為組態檔,這個知識點在IO流舉例,有興趣可先看文章
//1. Properties繼承Hashtable
//2.可以通過k-v存放資料,當然key 和 value 不能為null
// 增加
Properties properties = new Properties();
// properties.put(null,"abc ");//拋出空指標例外
// properties.put( "abc", null);//拋出空指標例外
properties.put( "john",100) ; //k-v
properties.put("lucy" ,100);
properties.put("lic",100);
properties.put("lic",88);//如果有相同的key , value被替換
System.out.println(properties.get("lic"));//88
//洗掉
properties.remove("lic");
System.out.println("properties=" + properties);//properties={john=100, lucy=100}
//修改
properties.put("john","約翰");
System.out.println("properties=" + properties);//properties={john=約翰, lucy=100}
//查找
System.out.println(properties.get("john"));//約翰
System.out.println(properties.getProperty("john"));//約翰
總結-開發中如何選擇集舍實作類(記住)
在開發中,選擇什么集合實作類,主要取決于業務操作特點,然后根據集合實作類特性進行選擇,分析如下:
-
先判斷存盤的型別(一組物件[單列]或一組鍵值對[雙列])
-
一組物件:Collection介面
允許重復:List
- 增刪多:LinkedList[底層維護了一個雙向鏈表](執行緒不安全)
- 改查多: ArrayList [底層維護Object型別的可變陣列](執行緒不安全,如果需要執行緒安全則用Vector)
不允許重復:Set
- 無序: HashSet [底層是HashMap,維護了一個哈希表即(陣列+鏈表+紅黑樹)](執行緒不安全)
- 排序:TreeSet
- 插入和取出順序一致:LinkedHashSet,維護陣列+雙向鏈表(執行緒不安全)
-
一組鍵值對:Map
鍵無序: HashMap [底層是:哈希表jdk7:陣列+鏈表,jdk8:陣列+鏈表+紅黑樹](執行緒不安全,如需要執行緒安全和key,value不為空,則使用Hashtable)
鍵排序:TreeMap
鍵插入和取出順序一致:LinkedHashMap(執行緒不安全)
讀取檔案 Properties(執行緒安全)
Collections工具類
Collections工具類介紹
- Collections是一個操作 Set、List 和Map等集合的工具類
- Collections中提供了一系列靜態的方法對集合元素進行排序、查詢和修改等操作
排序操作:(均為static方法)
- reverse(List):反轉 List 中元素的順序
- shuffle(List):對 List 集合元素進行隨機排序
- sort(List):根據元素的自然順序對指定 List集合元素按升序排序
- sort(List,Comparator):根據指定的 Comparator產生的順序對 List集合元素進行排序
- swap(List, int, int):將指定list 集合中的i處元素和j處元素進行交換
//創建ArrayList集合,用于測驗,
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
//reverse(List):反轉List 中元素的順序
Collections.reverse(list);
System.out.println("list=" + list);
//shuffle(List):對 List集合元素進行隨機排序
for (int i = 0; i < 5; i++) {
Collections.shuffle(list);
System.out.println("list=" + list);
}
//sort(List):根據元素的自然順序對指定 List集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
//sort(List,Comparator):根據指定的 Comparator產生的順序對List集合元素進行排序
// 我們希望按照字串的長度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).length() - ((String) o2).length();
}
});
System.out.println("字串長度大小排序=" + list);
//swap(List,int, int):將指定 list 集合中的i處元素和j處元素進行交換
// 比如
Collections.swap(list, 0, 1);
System.out.println("交換后的情況");
System.out.println("list=" + list);
查找、替換
- Object max(Collection):根據元素的自然順序,回傳給定集合中的最大元素
- Object max(Collection, Comparator):根據Comparator指定的順序,回傳給定集合中的最大元素
- Object min(Collection)
- Object min(Collection,Comparator)
- int frequency(Collection,Object):回傳指定集合中指定元素的出現次數
- void copy(List dest,List src):將src中的內容復制到dest中
- boolean replaceAll(List list, Object oldVal, Object newVal):使用新值替換 List物件的所有舊值
//創建ArrayList集合,用于測驗,
List list = new ArrayList();
list.add("king");
list.add("tom");
list.add("tom");
list.add("smith");
list.add("milan");
System.out.println(list);
//object max(Collection):根據元素的自然順序,回傳給定集合中的最大元素
System.out.println("自然順序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根據Comparator 指定的順序,回傳給定集合中的最大元素
//比如,我們要回傳長度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String) o1).length() - ((String) o2).length();//兩個反過來相減則是獲取最小元素
}
});
System.out.println("長度最大的元素=" + maxObject);
//Object min(collection)
//Object min(Collection,Comparator)
// 上面的兩個方法,參考max即可
ArrayList dest = new ArrayList();
//為了完成一個完整拷貝,我們需要先給dest賦值,大小大于等于list.size(),以防拷貝越界
for (int i = 0; i < list.size(); i++) {
dest.add("");
}
dest.add("dddd");
//拷貝
Collections.copy(dest, list);//從list拷貝到dest(覆寫dest中原先的部分資料)
System.out.println("dest=" + dest);//dest=[king, tom, tom, smith, milan, dddd]
System.out.println("list=" + list);//list=[king, tom, tom, smith, milan]
//boolean replaceAll(List list,Object oldVal,Object newNal):使用新值替換 List 物件的所有舊值
//將list中所有tom替換成湯姆
Collections.replaceAll(list, "tom", "湯姆");
System.out.println("list替換后=" + list);//list替換后=[king, 湯姆, 湯姆, smith, milan]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/502890.html
標籤:Java
上一篇:Java---Lambda