HashMap原始碼:
- 加載因子:loadFactory -- 默認 0.75f
- 初始容量大小: capacity 默認 16, 最大限制 1<<30
- 擴容: 當陣列元素的數量 > 初始容量大小 * 加載因子,就會擴容. 會呼叫rehash方法將陣列長度擴容到之前的兩倍.擴容的時候,會生成一個新的陣列,原來的所有資料需要重新計算哈希碼值重新分配到新的陣列,所以擴容的操作非常消耗性能.
Jdk1.7和jdk1.8區別
- jdk1.7之前 采用的是 陣列 + 鏈表的方式, 采用的是頭插法,擴容時會改變鏈表中元素原本的順序,以至于在并發場景下導致鏈表成環的問題
- jdk1.8之后 采用的是 陣列 + 鏈表/紅黑樹的方式 當某個位置出現哈希沖突時,會將元素放到該位置的鏈表后面,當鏈表長度超過8時, 會嘗試采用紅黑樹來存盤, 若陣列長度 若大于 64,鏈表長度 大于8會 將鏈表的所有節點都轉換成紅黑樹,若陣列長度 小于64,會擴容
Map get() 和 put()原理
- 1.8中put: put中呼叫putVal()方法
- 1)首先判斷map中是否有資料,沒有就執行resize方法(擴容也是通過這個方法)
- 2)如果要插入的鍵值對要存放的這個位置剛好沒有元素,那么就把他封裝成Node物件,放在這個位置上
- 3)如果這個元素的key和與要插入的一樣,就替換一下
- 4)如果當前節點是TreeNode型別的資料,執行putTreeVal方法
-
get:
-
1)呼叫k的hashCode()計算出哈希值,并通過哈希演算法轉換成陣列的下標.
-
2)通過上一步哈希演算法轉換成陣列的下標后,通過陣列快速定位到某個位置.如果這個位置上什么都沒有,回傳null如果有,則拿著K和單向鏈表上的每一個節點K進行equals,如果所有equals都回傳false,則回傳null若true,則回傳該value.
-
resize方法: 兩個職責,創建初始存盤表格,或者在容量不滿足需求的時候,進行擴容.
具體鍵值對在哈希表中的位置取決于該位運算: i = (n-1) & hash
-
熱點問題:
為什么HashMap要樹化?
? 本質上是因為安全問題.因為,在元素的存放程序中,如果一個物件哈希沖突,都被放到一個桶里,則會形成一個鏈表,而鏈表的查詢是線性的會嚴重影響存取的性能.而現實情況中,構造哈希沖突的資料并不是非常復雜的事情,惡意代碼就會利用這些資料與服務器大量互動,導致服務器端cpu大量占用,這就構成了哈希碰撞拒絕服務攻擊.
ps:用哈希碰撞發起拒絕服務攻擊(DOS,Denial-Of-Service attack),常見的場景是攻擊者可以事先構造大量相同哈希值的資料,然后以JSON資料的形式發送給服務器,服務器端在將其構建成為Java物件程序中,通常以Hashtable或HashMap等形式存盤,哈希碰撞將導致哈希表發生嚴重退化,演算法復雜度可能上升一個資料級,進而耗費大量CPU資源,
HashMap,HashTable,TreeMap,LinkedHashMap的區別
-
HashMap繼承自AbstractMap類,而HashTable繼承自Dictionary類,不過它們都同時實作了map,cloneable,serializable介面.存盤的內容是基于 key-value的鍵值對映射,key不能重復,一個key只能映射一個value.HashSet的底層就是基于HashMap實作的.
-
HashTable的key,value都不能為null
HashMap key 和 value 都可以為null,但只能有一個key為null,可以有多個null的value
TreeMap 鍵值都不能為null -
一般情況下,選用HashMap,因為HashMap的鍵值對在取出時是隨機的,依據key的hashCode和鍵的equals方法來存取資料,具有很快的訪問速度,所以在map中插入,洗掉及索引元素時效率較高.而TreeMap的鍵值對在取出時是排過序的,所以效率低一點.
-
TreeMap是基于紅黑樹的一種提供順序訪問的map,與HashMap不同的是它的get,put,remove之類的操作都是o(log(n))的時間復雜度,具體順序可以由指定的Comparator來決定,或者根據鍵的自然順序來判斷.
-
LinkedHashMap適合需要輸出的順序和輸入的順序相同的情況
-
HashMap是執行緒不安全的,HashTable是執行緒安全的.所以HashTable的效率比不上HashMap
前者默認初始化陣列大小為16,后者為11,擴容時,擴大兩倍,后者擴大兩倍+1
-
HashMap需要重新計算hash值,而hashTable直接使用物件的hashCode
HashMap在1.7和1.8之間的變化
- 1.7中采用陣列+鏈表,1.8采用陣列+鏈表/紅黑樹
- 1.7擴容時需要重新計算哈希值和索引位置,1.8并不重新計算哈希值,巧妙地采用和擴容后容量進行&操作來計算新的索引位置.
- 1.7采用頭插法: 擴容時會改變鏈表中元素的原本順序,以至于在并發場景下導致鏈表成環的問
- 1.8采用尾插法: 擴容時會保持鏈表原本的順序,避免了鏈表成環的問題.
當兩個物件的hashCode相同時會發生什么?
- hashCode相同,equals不一定為true,所以兩個物件所在陣列的下標相同,"碰撞"就此發生.會存盤在陣列該位置的鏈表(紅黑樹)中.
你知道hash的實作嗎?為什么要這樣實作?
-
1.8中,通過hashCode()的高16位異或低16位實作的
(h = k.hashCode()) ^ (h >>> 16)主要是從速度,功效和質量來考慮的,減少系統的開銷,也不會因為高位沒有參與下標的計算,從而引起碰撞
-
用異或運算子,保證了物件的hashCode的32位值只要有一位發生改變,整個hash()回傳值就會改變,盡可能的減少碰撞
拉鏈法導致的鏈表過深問題為什么不用二叉樹代替,而選擇紅黑樹?為什么不一直使用紅黑樹?
- 紅黑樹是為了解決二叉查找樹的缺陷,二叉查找樹在特殊情況下會變成一條線性結構(這就跟原來使用鏈表結構一樣了,同樣會造成很深的問題),遍歷查找會非常慢.
- 紅黑樹在插入新資料后會通過左旋,右旋或者變色操作來保持平衡,引入紅黑樹是為了查找資料快,解決鏈表查詢深度的問題,紅黑樹屬于平衡二叉樹,盡管為了保持平衡會付出代價,但該代價損耗的資源相比遍歷線性鏈表來說要少.所以,當長度大于8的時候,會使用紅黑樹.而為什么是8,是因為符合泊松分布,為8時資源損耗相對來說較少.
HashMap和CuncurrentHashMap的區別?
- ConcurrentHashMap類是java并發包java.util.concurrent中提供的一個執行緒安全且高效的HashMap實作.
- 1.7中ConcurrentHashMap采用分段鎖(ReentrantLock + segment +hashEntry),相當于把一個HashMap分成多個段,每段分配一把鎖,這樣支持多執行緒訪問.鎖粒度:基于segment,包含多個HashEntry
- 1.8中采用CAS + synchronized + Node + 紅黑樹.鎖粒度: Node.鎖粒度降低了
- HashTable則使用synchronized關鍵字加鎖
- 區別: ConcurrentHashMap鍵值對都不允許為null
ConcurrentHashMap簡單介紹一下?
-
java.util.concurrent.ConcurrentHashMap屬于JUC包下的一個集合類,可以實作執行緒安全.
-
1.8之前:
- 由多個Segment組合而成,Segment本身就相當于一個HashMap物件.同HashMap一樣,Segment包含一個HashEntry陣列,陣列中的每一個HashEntry既是一個鍵值對,也是一個鏈表的頭節點.
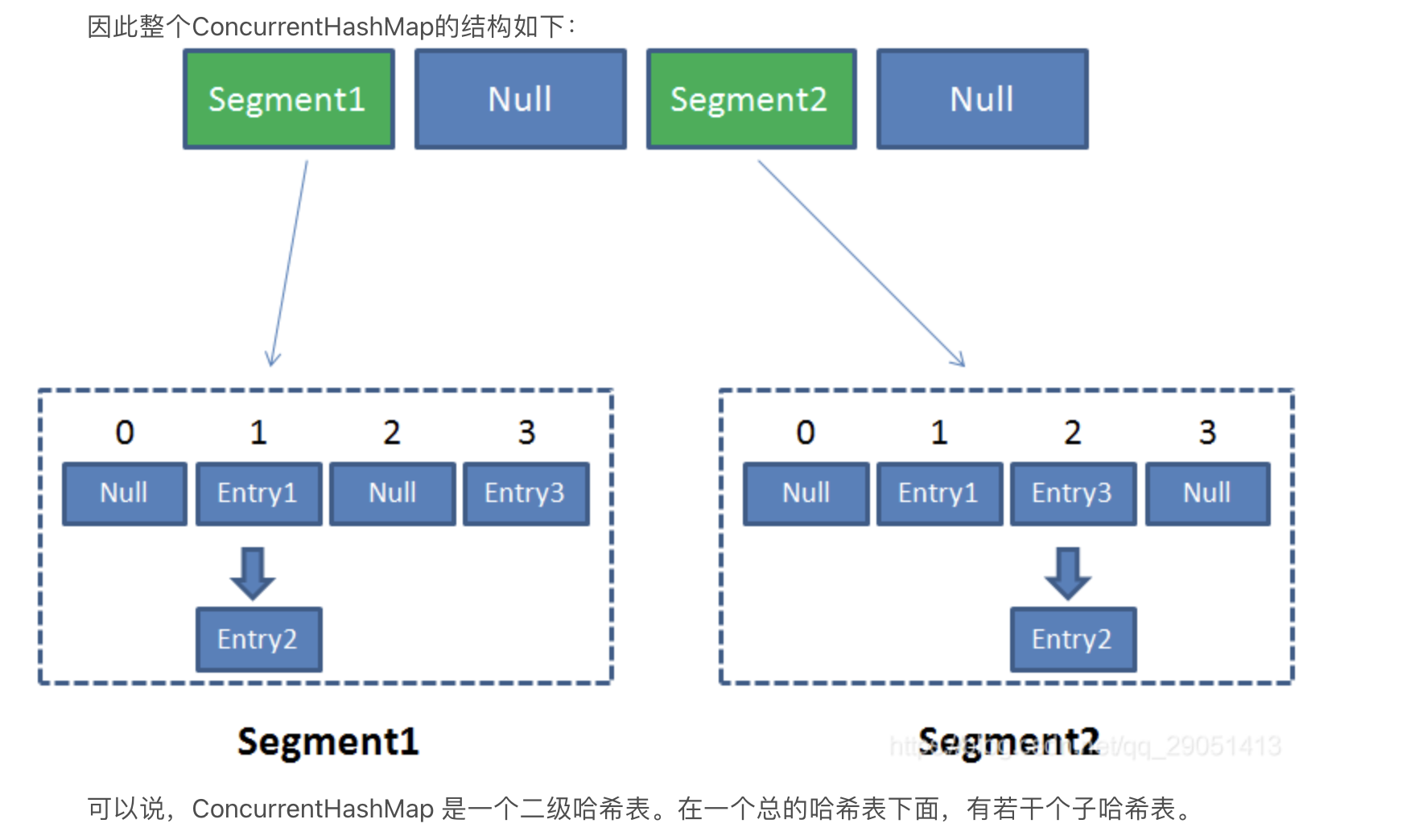
-
Put: 首先,會嘗試獲取鎖,若獲取失敗,則利用scanAndLockForPut()自旋獲取鎖.如果重試的次數達到了MAX_SCAN_RETRIES則改為阻塞鎖獲取,保證能獲取成功.接著,遍歷該HashEntry,如果不為空則判斷傳入的key和當前遍歷的key是否相等,相等則覆寫舊的value.為空,則需要新建一個HashEntry并加入到Segment中,同時會先判斷是否需要擴容.
-
Get: key通過hash之后定位到具體的segment,再通過一次hash定位到具體元素上.
由于HashEntry中的value屬性是用volatile關鍵字修飾的,保證了記憶體可見性,所以每次獲取時都是最新值. 整個程序非常搞笑,不需要加鎖.
- 由多個Segment組合而成,Segment本身就相當于一個HashMap物件.同HashMap一樣,Segment包含一個HashEntry陣列,陣列中的每一個HashEntry既是一個鍵值對,也是一個鏈表的頭節點.
- 1.8之后:
- 陣列+鏈表 改為 陣列+鏈表/紅黑樹,HashEntry改為Node
ConcurrentHashMap的key,value是否可以為null,為什么?
-
都不可以為null,為null時會拋出空指標例外.
ConcurrentHashMap是一個用于多執行緒并發場景下的并發容器(map),在多執行緒環境下執行增刪改查方法要保證執行緒安全性.
-
不能為null,因為會產生二義性問題: 當我們用get方法去獲取一個value為null的時候,可能會沒有這個key,也可能會有這個key,只不過value為null.
-
HashMap如何解決二義性問題
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}- 如果存在key為null的元素(key = null對應的hash值為0),getNode獲取到值不為null
- 如果不存在key為null的元素,此時hash值=0對應的下標元素為null,即getNode獲取到的值為null
-
ConcurrentHashMap為什么不能解決二義性問題
- 因為ConcurrentHashMap是一個用在多執行緒并發的map容器,不能put null 是因為無法分辨是key沒找到null,還是有key的值為null.這在多執行緒里沒法保證會不會有其他執行緒修改為null鍵和null值的情況,所以不讓put null.
參考檔案
-
HashMap詳解
-
面試:HashMap奪命二十一問
-
深入淺出ConcurrentHashMap
-
ConcurrentHashMap(1.8)講解及常見面試題
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/503171.html
標籤:Java
上一篇:C++ inline
下一篇:因勢而變,因時而動,Go lang1.18入門精煉教程,由白丁入鴻儒,Go lang泛型(generic)的使用EP15