文章來源:【公眾號:同程藝龍技術中心】
背景
會員系統是一種基礎系統,跟公司所有業務線的下單主流程密切相關,如果會員系統出故障,會導致用戶無法下單,影響范圍是全公司所有業務線,所以,會員系統必須保證高性能、高可用,提供穩定、高效的基礎服務,
隨著同程和藝龍兩家公司的合并,越來越多的系統需要打通同程 APP、藝龍 APP、同程微信小程式、藝龍微信小程式等多平臺會員體系,
例如微信小程式的交叉營銷,用戶買了一張火車票,此時想給他發酒店紅包,這就需要查詢該用戶的統一會員關系,
因為火車票用的是同程會員體系,酒店用的是藝龍會員體系,只有查到對應的藝龍會員卡號后,才能將紅包掛載到該會員賬號,
除了上述講的交叉營銷,還有許多場景需要查詢統一會員關系,例如訂單中心、會員等級、里程、紅包、常旅、實名,以及各類營銷活動等等,
所以,會員系統的請求量越來越大,并發量越來越高,今年清明小長假的秒并發 tps 甚至超過 2 萬多,
在如此大流量的沖擊下,會員系統是如何做到高性能和高可用的呢?這就是本文著重要講述的內容,
ES 高可用方案
| ES 雙中心主備集群架構
同程和藝龍兩家公司融合后,全平臺所有體系的會員總量是十多億,在這么大的資料體量下,業務線的查詢維度也比較復雜,
有的業務線基于手機號,有的基于微信 unionid,也有的基于藝龍卡號等查詢會員資訊,
這么大的資料量,又有這么多的查詢維度,基于此,我們選擇 ES 用來存盤統一會員關系,ES 集群在整個會員系統架構中非常重要,那么如何保證 ES 的高可用呢?
首先我們知道,ES 集群本身就是保證高可用的,如下圖所示:
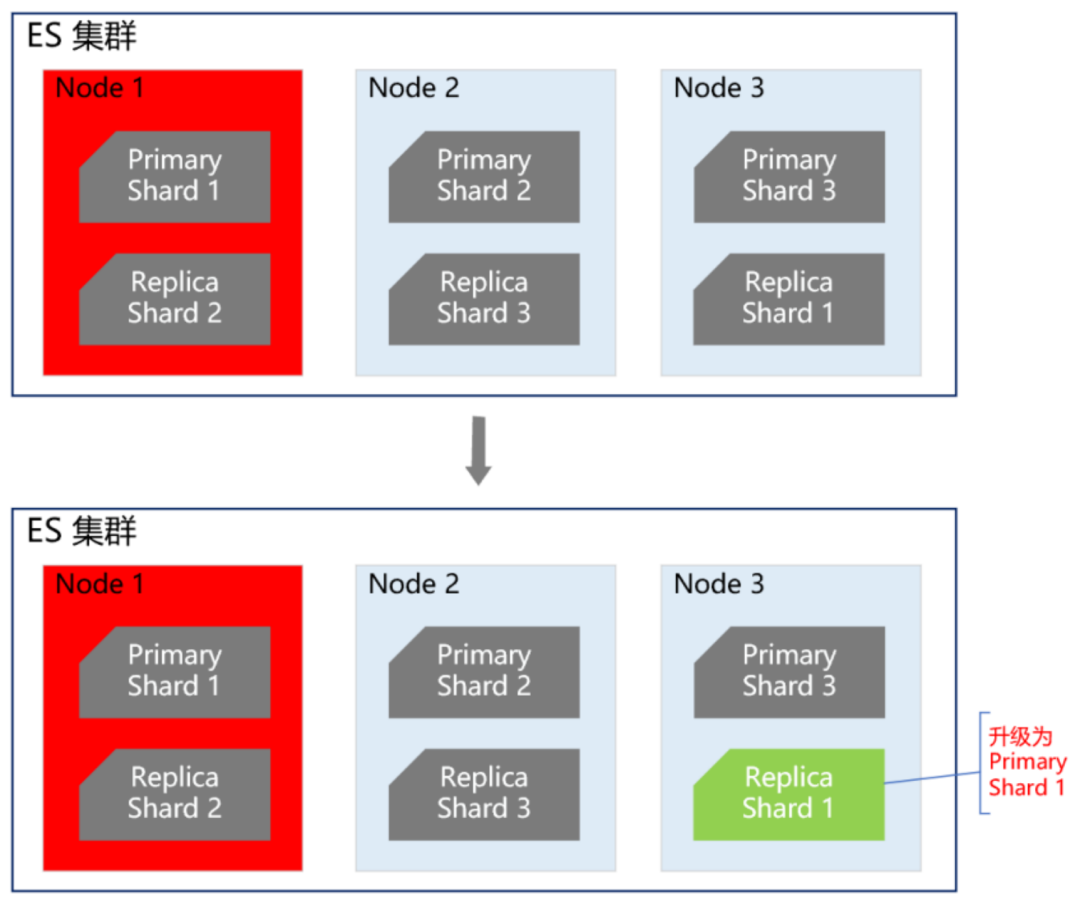
當 ES 集群有一個節點宕機了,會將其他節點對應的 Replica Shard 升級為 Primary Shard,繼續提供服務,
但即使是這樣,還遠遠不夠,例如 ES 集群都部署在機房 A,現在機房 A 突然斷電了,怎么辦?
例如服務器硬體故障,ES 集群大部分機器宕機了,怎么辦?或者突然有個非常熱門的搶購秒殺活動,帶來了一波非常大的流量,直接把 ES 集群打死了,怎么辦?面對這些情況,讓運維兄弟沖到機房去解決?
這個非常不現實,因為會員系統直接影響全公司所有業務線的下單主流程,故障恢復的時間必須非常短,如果需要運維兄弟人工介入,那這個時間就太長了,是絕對不能容忍的,
那 ES 的高可用如何做呢?我們的方案是 ES 雙中心主備集群架構,
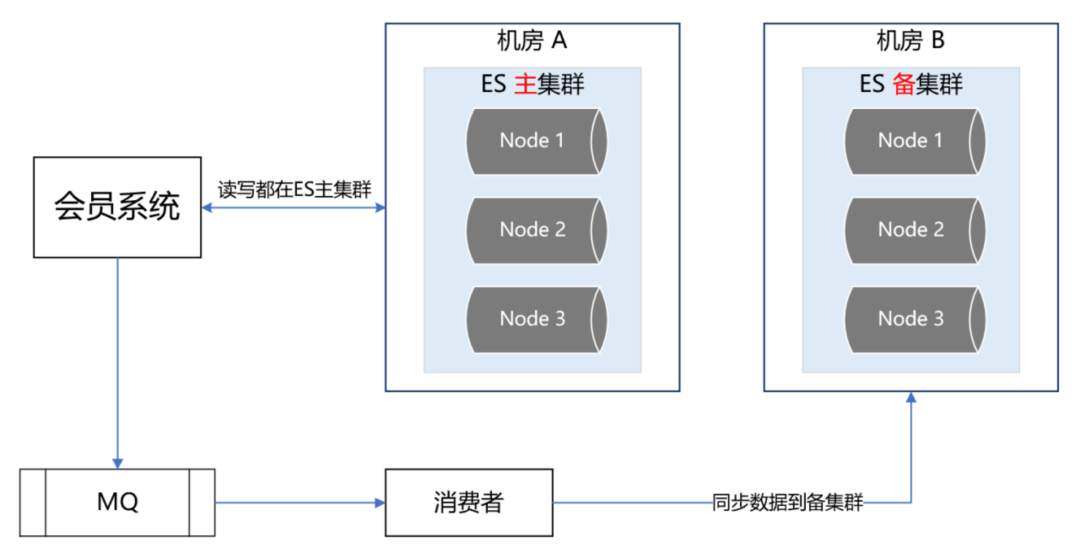
我們有兩個機房,分別是機房 A 和機房 B,我們把 ES 主集群部署在機房 A,把 ES 備集群部署在機房 B,會員系統的讀寫都在 ES 主集群,通過 MQ 將資料同步到 ES 備集群,
此時,如果 ES 主集群崩了,通過統一配置,將會員系統的讀寫切到機房 B 的 ES 備集群上,這樣即使 ES 主集群掛了,也能在很短的時間內實作故障轉移,確保會員系統的穩定運行,
最后,等 ES 主集群故障恢復后,打開開關,將故障期間的資料同步到 ES 主集群,等資料同步一致后,再將會員系統的讀寫切到 ES 主集群,
| ES 流量隔離三集群架構
雙中心 ES 主備集群做到這一步,感覺應該沒啥大問題了,但去年的一次恐怖流量沖擊讓我們改變了想法,
那是一個節假日,某個業務上線了一個營銷活動,在用戶的一次請求中,回圈 10 多次呼叫了會員系統,導致會員系統的 tps 暴漲,差點把 ES 集群打爆,
這件事讓我們后怕不已,它讓我們意識到,一定要對呼叫方進行優先級分類,實施更精細的隔離、熔斷、降級、限流策略,
首先,我們梳理了所有呼叫方,分出兩大類請求型別:
- 第一類是跟用戶的下單主流程密切相關的請求,這類請求非常重要,應該高優先級保障,
- 第二類是營銷活動相關的,這類請求有個特點,他們的請求量很大,tps 很高,但不影響下單主流程,
基于此,我們又構建了一個 ES 集群,專門用來應對高 tps 的營銷秒殺類請求,這樣就跟 ES 主集群隔離開來,不會因為某個營銷活動的流量沖擊而影響用戶的下單主流程,
如下圖所示:
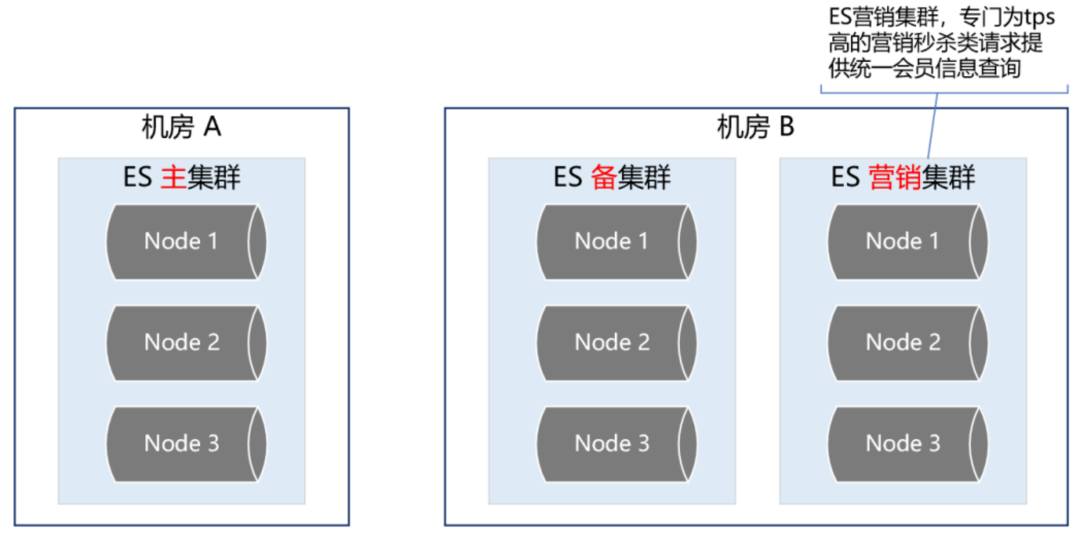
| ES 集群深度優化提升
講完了 ES 的雙中心主備集群高可用架構,接下來我們深入講解一下 ES 主集群的優化作業,
有一段時間,我們特別痛苦,就是每到飯點,ES 集群就開始報警,搞得每次吃飯都心慌慌的,生怕 ES 集群一個扛不住,就全公司炸鍋了,
那為什么一到飯點就報警呢?因為流量比較大, 導致 ES 執行緒數飆高,cpu 直往上竄,查詢耗時增加,并傳導給所有呼叫方,導致更大范圍的延時,那么如何解決這個問題呢?
通過深入 ES 集群,我們發現了以下幾個問題:
- ES 負載不合理,熱點問題嚴重,ES 主集群一共有幾十個節點,有的節點上部署的 shard 數偏多,有的節點部署的 shard 數很少,導致某些服務器的負載很高,每到流量高峰期,就經常預警,
- ES 執行緒池的大小設定得太高,導致 cpu 飆高,我們知道,設定 ES 的 threadpool,一般將執行緒數設定為服務器的 cpu 核數,即使 ES 的查詢壓力很大,需要增加執行緒數,那最好也不要超過“cpu core * 3 / 2 + 1”,如果設定的執行緒數過多,會導致 cpu 在多個執行緒背景關系之間頻繁來回切換,浪費大量 cpu 資源,
- shard 分配的記憶體太大,100g,導致查詢變慢,我們知道,ES 的索引要合理分配 shard 數,要控制一個 shard 的記憶體大小在 50g 以內,如果一個 shard 分配的記憶體過大,會導致查詢變慢,耗時增加,嚴重拖累性能,
- string 型別的欄位設定了雙欄位,既是 text,又是 keyword,導致存盤容量增大了一倍,會員資訊的查詢不需要關聯度打分,直接根據 keyword 查詢就行,所以完全可以將 text 欄位去掉,這樣就能節省很大一部分存盤空間,提升性能,
- ES 查詢,使用 filter,不使用 query,因為 query 會對搜索結果進行相關度算分,比較耗 cpu,而會員資訊的查詢是不需要算分的,這部分的性能損耗完全可以避免,
- 節約 ES 算力,將 ES 的搜索結果排序放在會員系統的 jvm 記憶體中進行,
- 增加 routing key,我們知道,一次 ES 查詢,會將請求分發給所有 shard,等所有shard回傳結果后再聚合資料,最后將結果回傳給呼叫方,如果我們事先已經知道資料分布在哪些 shard 上,那么就可以減少大量不必要的請求,提升查詢性能,
經過以上優化,成果非常顯著,ES 集群的 cpu 大幅下降,查詢性能大幅提升,ES 集群的 cpu 使用率:
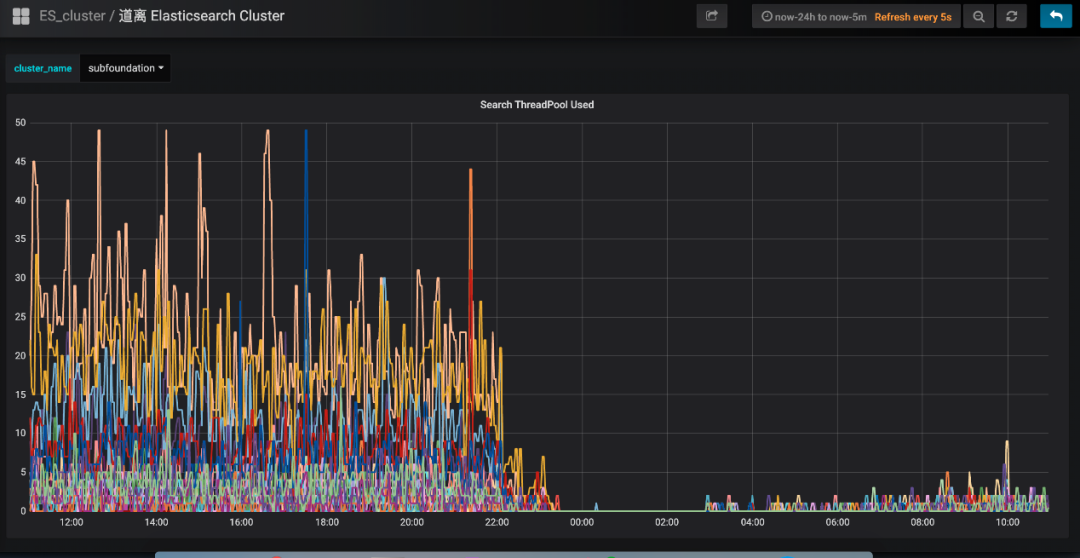
會員系統的介面耗時:
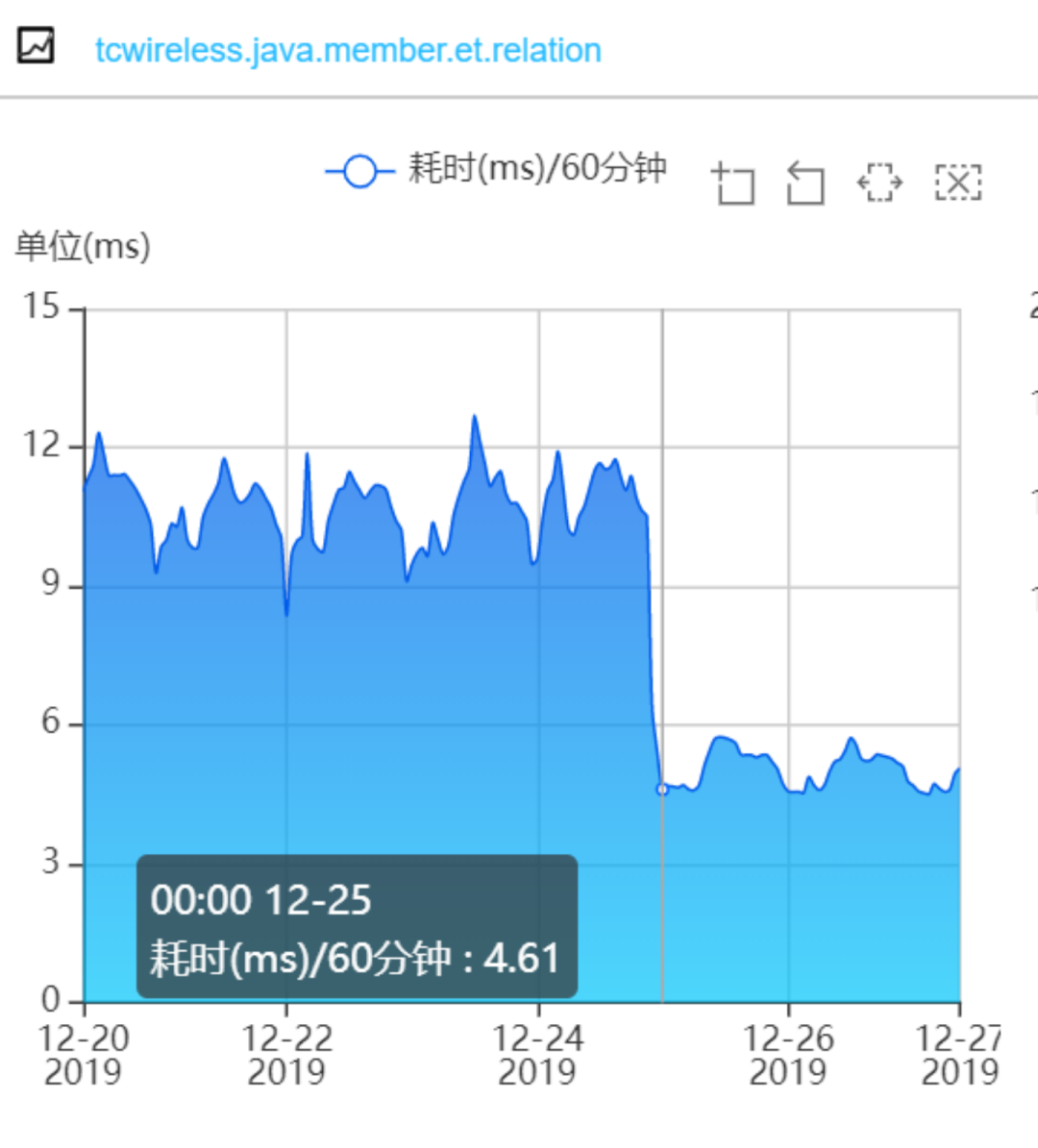
會員 Redis 快取方案
一直以來,會員系統是不做快取的,原因主要有兩個:
- 第一個,前面講的 ES 集群性能很好,秒并發 3 萬多,99 線耗時 5 毫秒左右,已經足夠應付各種棘手的場景,
- 第二個,有的業務對會員的系結關系要求實時一致,而會員是一個發展了 10 多年的老系統,是一個由好多介面、好多系統組成的分布式系統,
所以,只要有一個介面沒有考慮到位,沒有及時去更新快取,就會導致臟資料,進而引發一系列的問題,
例如:用戶在 APP 上看不到微信訂單、APP 和微信的會員等級、里程等沒合并、微信和 APP 無法交叉營銷等等,
那后來為什么又要做快取呢?是因為今年機票的盲盒活動,它帶來的瞬時并發太高了,雖然會員系統安然無恙,但還是有點心有余悸,穩妥起見,最侄訓是決定實施快取方案,
| ES 近一秒延時導致的 Redis 快取資料不一致問題的解決方案
在做會員快取方案的程序中,遇到一個 ES 引發的問題,該問題會導致快取資料的不一致,
我們知道,ES 操作資料是近實時的,往 ES 新增一個 Document,此時立即去查,是查不到的,需要等待 1 秒后才能查詢到,
如下圖所示:
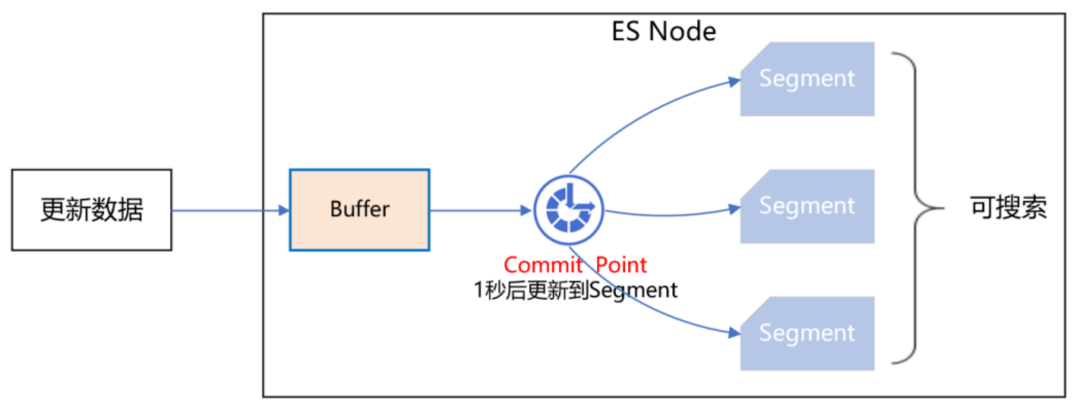
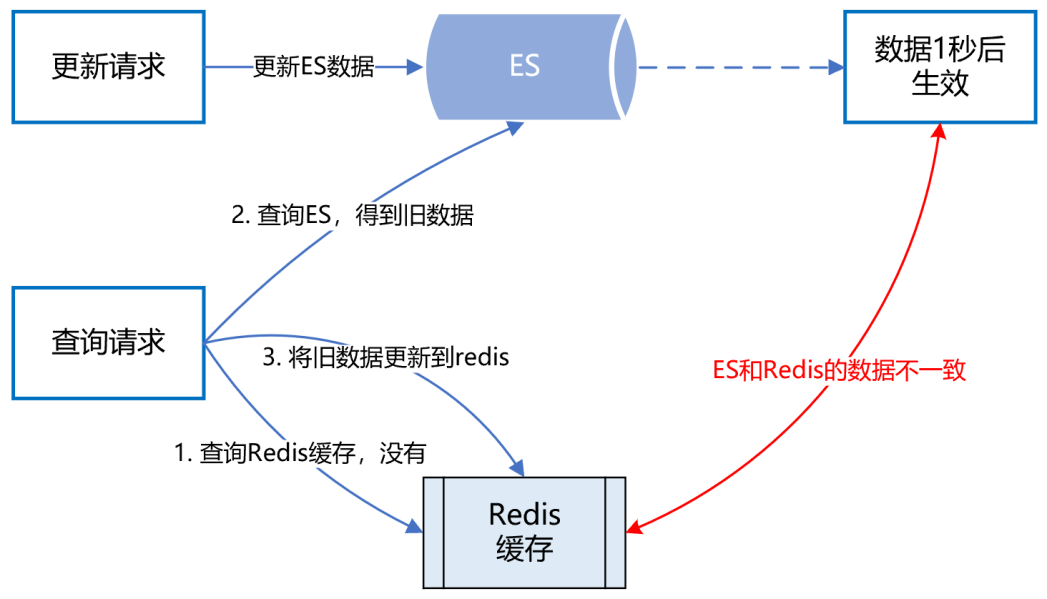
ES 的近實時機制為什么會導致 Redis 快取資料不一致呢?具體來講,假設一個用戶注銷了自己的 APP 賬號,此時需要更新 ES,洗掉 APP 賬號和微信賬號的系結關系,而 ES 的資料更新是近實時的,也就是說,1 秒后你才能查詢到更新后的資料,
而就在這 1 秒內,有個請求來查詢該用戶的會員系結關系,它先到 Redis 快取中查,發現沒有,然后到 ES 查,查到了,但查到的是更新前的舊資料,
最后,該請求把查詢到的舊資料更新到 Redis 快取并回傳,就這樣,1 秒后,ES 中該用戶的會員資料更新了,但 Redis 快取的資料還是舊資料,導致了 Redis 快取跟 ES 的資料不一致,
如下圖所示:
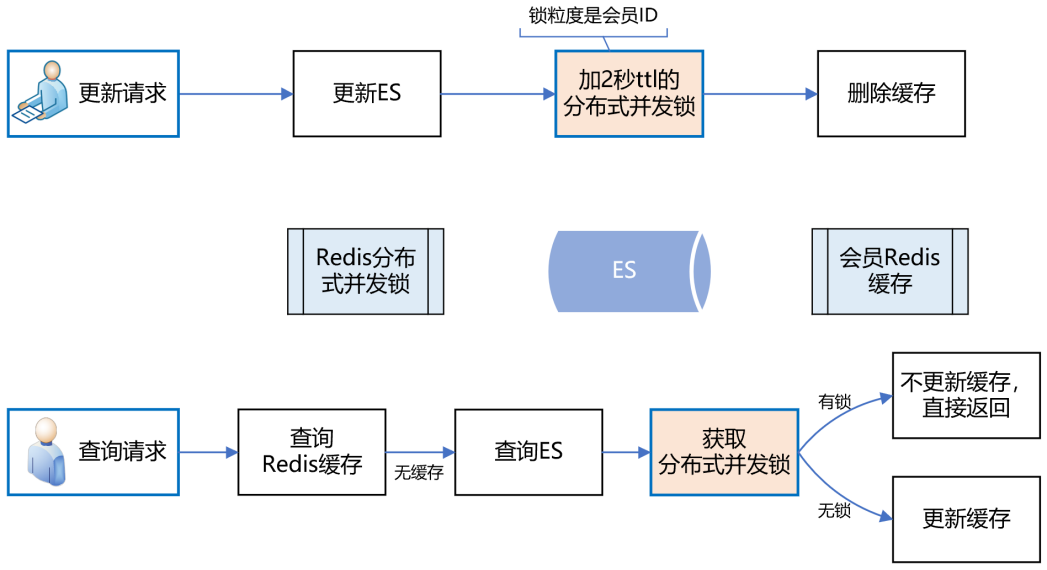
面對該問題,如何解決呢?我們的思路是,在更新 ES 資料時,加一個 2 秒的 Redis 分布式并發鎖,為了保證快取資料的一致性,接著再洗掉 Redis 中該會員的快取資料,
如果此時有請求來查詢資料,先獲取分布式鎖,發現該會員 ID 已經上鎖了,說明 ES 剛剛更新的資料尚未生效,那么此時查詢完資料后就不更新 Redis 快取了,直接回傳,這樣就避免了快取資料的不一致問題,
如下圖所示:
上述方案,乍一看似乎沒什么問題了,但仔細分析,還是有可能導致快取資料的不一致,
例如,在更新請求加分布式鎖之前,恰好有一個查詢請求獲取分布式鎖,而此時是沒有鎖的,所以它可以繼續更新快取,
但就在他更新快取之前,執行緒 block 了,此時更新請求來了,加了分布式鎖,并洗掉了快取,當更新請求完成操作后,查詢請求的執行緒活過來了,此時它再執行更新快取,就把臟資料寫到快取中了,
發現沒有?主要的問題癥結就在于“洗掉快取”和“更新快取”發生了并發沖突,只要將它們互斥,就能解決問題,
如下圖所示:
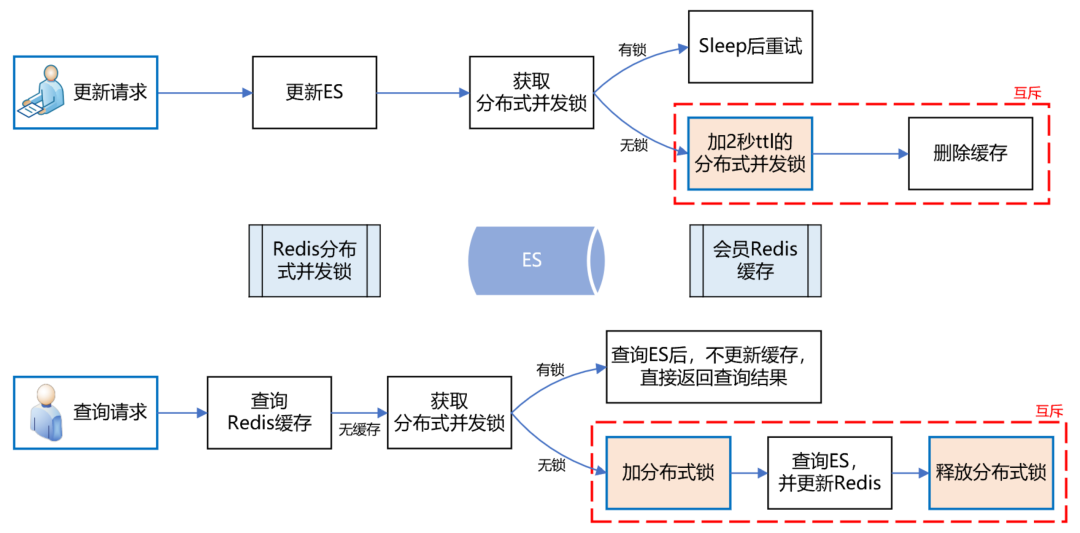
實施了快取方案后,經統計,快取命中率 90%+,極大緩解了 ES 的壓力,會員系統整體性能得到了很大提升,
| Redis 雙中心多集群架構
接下來,我們看一下如何保障 Redis 集群的高可用,
如下圖所示:
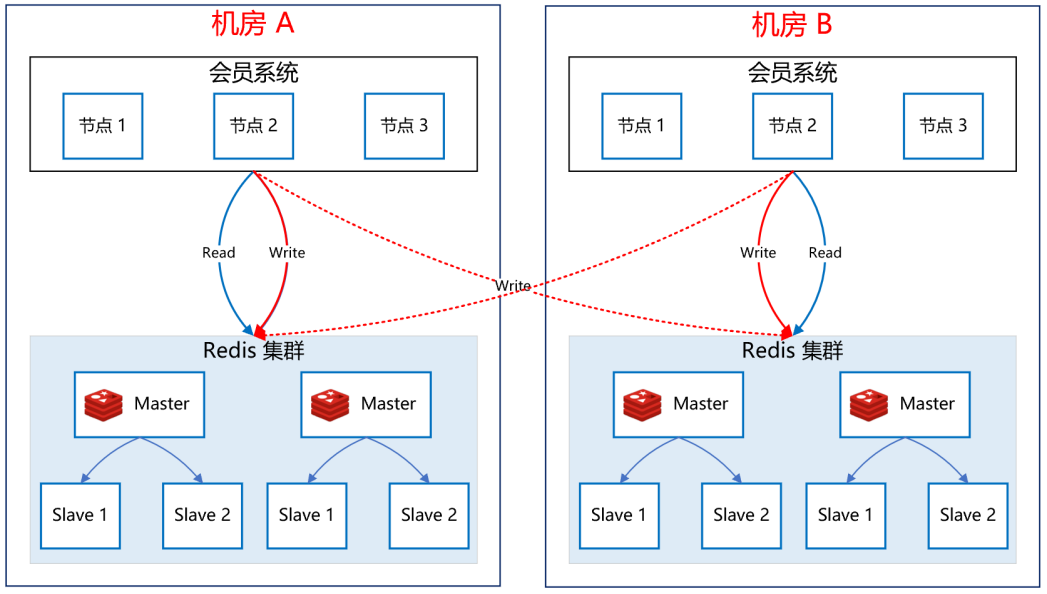
關于 Redis 集群的高可用,我們采用了雙中心多集群的模式,在機房 A 和機房 B 各部署一套 Redis 集群,
更新快取資料時,雙寫,只有兩個機房的 Redis 集群都寫成功了,才回傳成功,查詢快取資料時,機房內就近查詢,降低延時,這樣,即使機房 A 整體故障,機房 B 還能提供完整的會員服務,
高可用會員主庫方案
上述講到,全平臺會員的系結關系資料存在 ES,而會員的注冊明細資料存在關系型資料庫,
最早,會員使用的資料庫是 SqlServer,直到有一天,DBA 找到我們說,單臺 SqlServer 資料庫已經存盤了十多億的會員資料,服務器已達到物理極限,不能再擴展了,按照現在的增長趨勢,過不了多久,整個 SqlServer 資料庫就崩了,
你想想,那是一種什么樣的災難場景:會員資料庫崩了,會員系統就崩了;會員系統崩了,全公司所有業務線就崩了,想想就不寒而栗,酸爽無比,為此我們立刻開啟了遷移 DB 的作業,
| MySQL 雙中心 Partition 集群方案
經過調研,我們選擇了雙中心分庫分表的 MySQL 集群方案,如下圖所示:
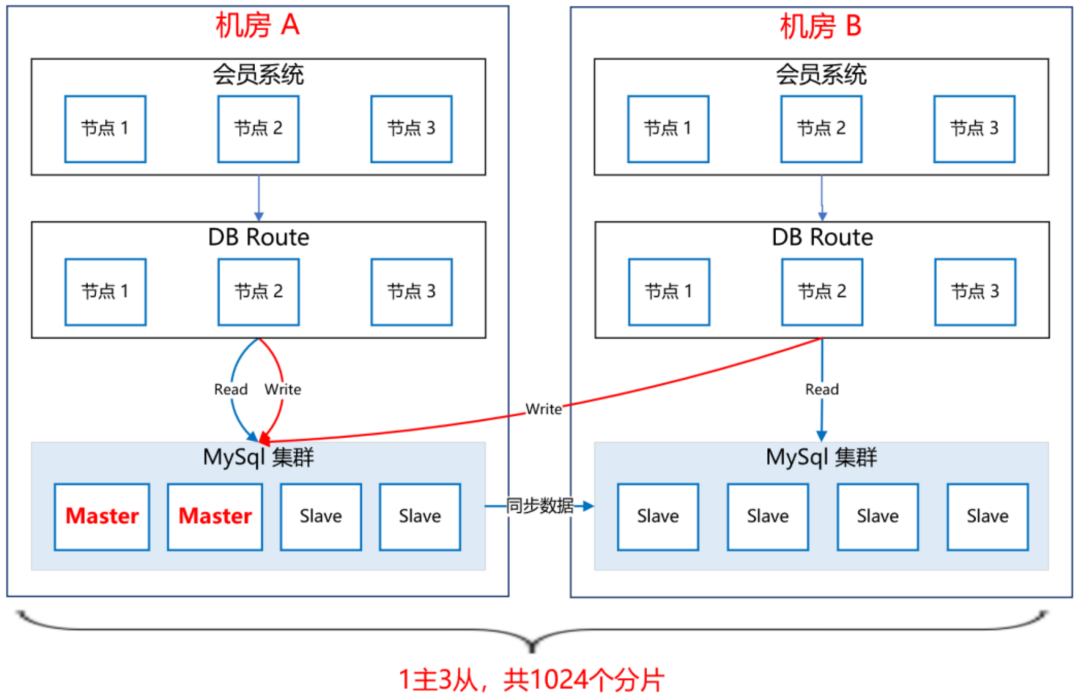
會員一共有十多億的資料,我們把會員主庫分了 1000 多個分片,平分到每個分片大概百萬的量級,足夠使用了,
MySQL 集群采用 1 主 3 從的架構,主庫放在機房 A,從庫放在機房 B,兩個機房之間通過專線同步資料,延遲在 1 毫秒內,
會員系統通過 DBRoute 讀寫資料,寫資料都路由到 master 節點所在的機房 A,讀資料都路由到本地機房,就近訪問,減少網路延遲,
這樣,采用雙中心的 MySQL 集群架構,極大提高了可用性,即使機房 A 整體都崩了,還可以將機房 B 的 Slave 升級為 Master,繼續提供服務,
雙中心 MySQL 集群搭建好后,我們進行了壓測,測驗下來,秒并發能達到 2 萬多,平均耗時在 10 毫秒內,性能達標,
| 會員主庫平滑遷移方案
接下來的作業,就是把會員系統的底層存盤從 SqlServer 切到 MySQL 上,這是個風險極高的作業,
主要有以下幾個難點:
- 會員系統是一刻都不能停機的,要在不停機的情況下完成 SqlServer 到 MySQL 的切換,就像是在給高速行駛的汽車換輪子,
- 會員系統是由很多個系統和介面組成的,畢竟發展了 10 多年,由于歷史原因,遺留了大量老介面,邏輯錯綜復雜,這么多系統,必須一個不落的全部梳理清楚,DAL 層代碼必須重寫,而且不能出任何問題,否則將是災難性的,
- 資料的遷移要做到無縫遷移,不僅是存量 10 多億資料的遷移,實時產生的資料也要無縫同步到 MySQL,另外,除了要保障資料同步的實時性,還要保證資料的正確性,以及 SqlServer 和 MySQL 資料的一致性,
基于以上痛點,我們設計了“全量同步、增量同步、實時流量灰度切換”的技術方案,
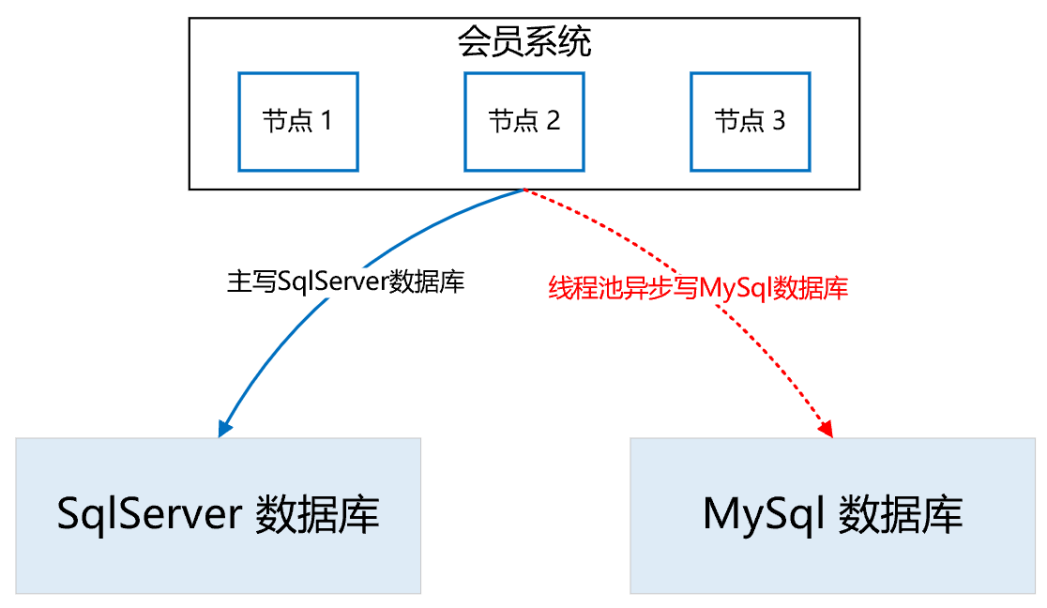
首先,為了保證資料的無縫切換,采用實時雙寫的方案,因為業務邏輯的復雜,以及 SqlServer 和 MySQL 的技術差異性,在雙寫 MySQL 的程序中,不一定會寫成功,而一旦寫失敗,就會導致 SqlServer 和 MySQL 的資料不一致,這是絕不允許的,
所以,我們采取的策略是,在試運行期間,主寫 SqlServer,然后通過執行緒池異步寫 MySQL,如果寫失敗了,重試三次,如果依然失敗,則記日志,然后人工排查原因,解決后,繼續雙寫,直到運行一段時間,沒有雙寫失敗的情況,
通過上述策略,可以確保在絕大部分情況下,雙寫操作的正確性和穩定性,即使在試運行期間出現了 SqlServer 和 MySQL 的資料不一致的情況,也可以基于 SqlServer 再次全量構建出 MySQL 的資料,
因為我們在設計雙寫策略時,會確保 SqlServer 一定能寫成功,也就是說,SqlServer 中的資料是全量最完整、最正確的,
如下圖所示:
講完了雙寫,接下來我們看一下“讀資料”如何灰度,整體思路是,通過 A/B 平臺逐步灰度流量,剛開始 100% 的流量讀取 SqlServer 資料庫,然后逐步切流量讀取 MySQL 資料庫,先 1%,如果沒有問題,再逐步放流量,最終 100% 的流量都走 MySQL資料庫,
在逐步灰度流量的程序中,需要有驗證機制,只有驗證沒問題了,才能進一步放大流量,
那么這個驗證機制如何實施呢?方案是,在一次查詢請求里,通過異步執行緒,比較 SqlServer 和 MySQL 的查詢結果是否一致,如果不一致,記日志,再人工檢查不一致的原因,直到徹底解決不一致的問題后,再逐步灰度流量,
如下圖所示:
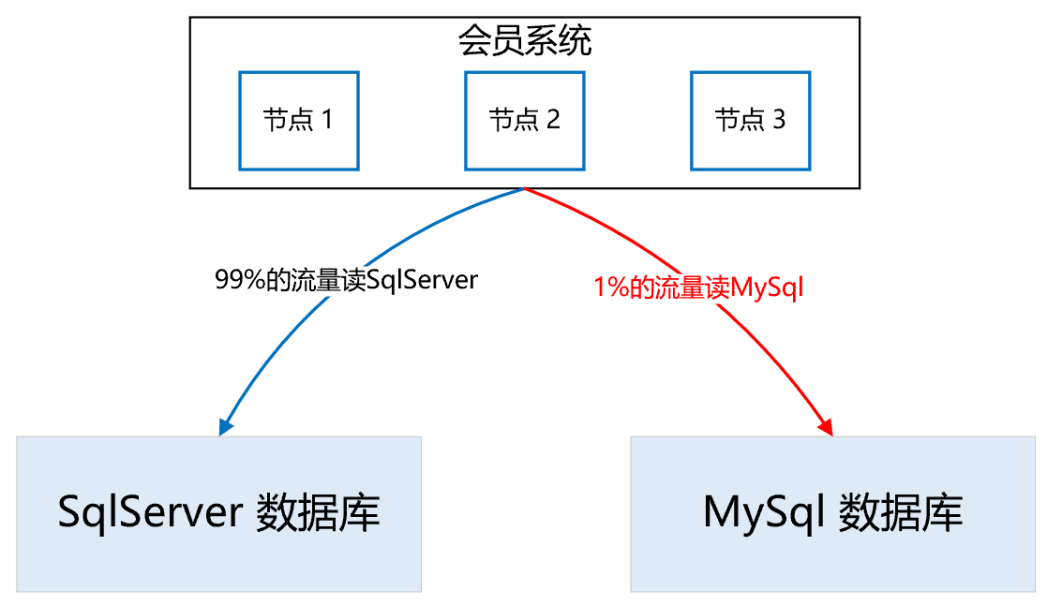
所以,整體的實施流程如下:

首先,在一個夜黑風高的深夜,流量最小的時候,完成 SqlServer 到 MySQL 資料庫的全量資料同步,
接著,開啟雙寫,此時,如果有用戶注冊,就會實時雙寫到兩個資料庫,那么,在全量同步和實時雙寫開啟之間,兩個資料庫還相差這段時間的資料,所以需要再次增量同步,把資料補充完整,以防資料的不一致,
剩下的時間,就是各種日志監控,看雙寫是否有問題,看資料比對是否一致等等,
這段時間是耗時最長的,也是最容易發生問題的,如果有的問題比較嚴重,導致資料不一致了,就需要從頭再來,再次基于 SqlServer 全量構建 MySQL 資料庫,然后重新灰度流量,
直到最后,100% 的流量全部灰度到 MySQL,此時就大功告成了,下線灰度邏輯,所有讀寫都切到 MySQL 集群,
| MySQL 和 ES 主備集群方案
做到這一步,感徑訓員主庫應該沒問題了,可 dal 組件的一次嚴重故障改變了我們的想法,
那次故障很恐怖,公司很多應用連接不上資料庫了,創單量直線往下掉,這讓我們意識到,即使資料庫是好的,但 dal 組件例外,依然能讓會員系統掛掉,
所以,我們再次異構了會員主庫的資料源,雙寫資料到 ES,如下所示:
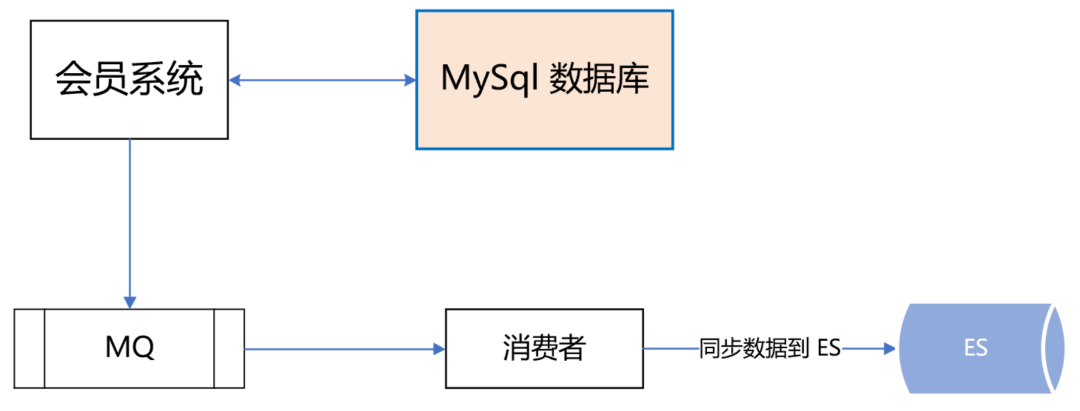
如果 dal 組件故障或 MySQL 資料庫掛了,可以把讀寫切到 ES,等 MySQL 恢復了,再把資料同步到 MySQL,最后把讀寫再切回到 MySQL 資料庫,
如下圖所示:
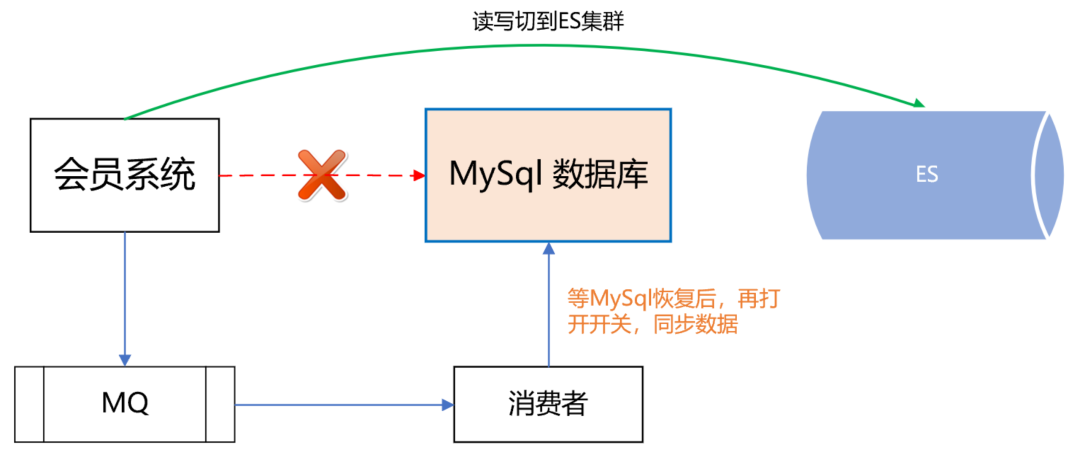
例外會員關系治理
會員系統不僅僅要保證系統的穩定和高可用,資料的精準和正確也同樣重要,
舉個例子,一個分布式并發故障,導致一名用戶的 APP 賬戶系結了別人的微信小程式賬戶,這將會帶來非常惡劣的影響,
首先,一旦這兩個賬號系結了,那么這兩個用戶下的酒店、機票、火車票訂單是互相可以看到的,
你想想,別人能看到你訂的酒店訂單,你火不火,會不會投訴?除了能看到別人的訂單,你還能操作訂單,
例如,一個用戶在 APP 的訂單中心,看到了別人訂的機票訂單,他覺得不是自己的訂單,就把訂單取消了,
這將會帶來非常嚴重的客訴,大家知道,機票退訂費用是挺高的,這不僅影響了該用戶的正常出行,還導致了比較大的經濟損失,非常糟糕,
針對這些例外會員賬號,我們進行了詳細的梳理,通過非常復雜燒腦的邏輯識別出這些賬號,并對會員介面進行了深度優化治理,在代碼邏輯層堵住了相關漏洞,完成了例外會員的治理作業,
如下圖所示:
展望:更精細化的流控和降級策略
任何一個系統,都不能保證百分之一百不出問題,所以我們要有面向失敗的設計,那就是更精細化的流控和降級策略,
| 更精細化的流控策略
熱點控制,針對黑產刷單的場景,同一個會員 id 會有大量重復的請求,形成熱點賬號,當這些賬號的訪問超過設定閾值時,實施限流策略,
基于呼叫賬號的流控規則,這個策略主要是防止呼叫方的代碼 bug 導致的大流量,例如,呼叫方在一次用戶請求中,回圈很多次來呼叫會員介面,導致會員系統流量暴增很多倍,所以,要針對每個呼叫賬號設定流控規則,當超過閾值時,實施限流策略,
全域流控規則,我們會員系統能抗下 tps 3 萬多的秒并發請求量,如果此時,有個很恐怖的流量打過來,tps 高達 10 萬,與其讓這波流量把會員資料庫、ES 全部打死,還不如把超過會員系統承受范圍之外的流量快速失敗,至少 tps 3 萬內的會員請求能正常回應,不會讓整個會員系統全部崩潰,
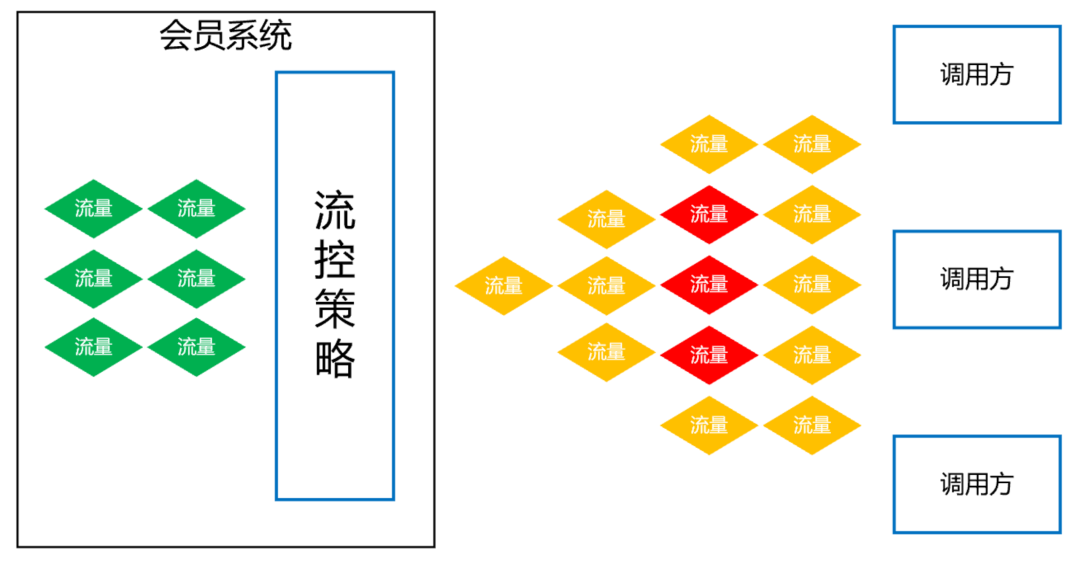
| 更精細化的降級策略
基于平均回應時間的降級,會員介面也有依賴其他介面,當呼叫其他介面的平均回應時間超過閾值,進入準降級狀態,
如果接下來 1s 內進入的請求,它們的平均回應時間都持續超過閾值,那么在接下的時間視窗內,自動地熔斷,
基于例外數和例外比例的降級,當會員介面依賴的其他介面發生例外,如果 1 分鐘內的例外數超過閾值,或者每秒例外總數占通過量的比值超過閾值,進入降級狀態,在接下的時間視窗之內,自動熔斷,
目前,我們最大的痛點是會員呼叫賬號的治理,公司內,想要呼叫會員介面,必須申請一個呼叫賬號,我們會記錄該賬號的使用場景,并設定流控、降級策略的規則,
但在實際使用的程序中,申請了該賬號的同事,可能異動到其他部門了,此時他可能也會呼叫會員系統,為了省事,他不會再次申請會員賬號,而是直接沿用以前的賬號過來呼叫,這導致我們無法判斷一個會員賬號的具體使用場景是什么,也就無法實施更精細的流控和降級策略,
所以,接下來,我們將會對所有呼叫賬號進行一個個的梳理,這是個非常龐大且繁瑣的作業,但無路如何,硬著頭皮也要做好,
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/503343.html
標籤:其他
上一篇:基礎資料型別之集合