(本文首發于“資料庫架構師”公號,訂閱“資料庫架構師”公號,一起學習資料庫技術,助力職業發展)
本篇為Redis性能問題診斷系列的第三篇,主要從Redis服務層面上進行講解,重點對相關機制的作業原理進行剖析,及如何最優的使用來提高處理性能,
一.資料持久化的影響
為了保證 Redis 資料的安全性,我們可能會開啟Redis的持久化將資料落盤,避免Redis服務崩潰或者服務器宕機導致的資料丟失,
Redis當前支持兩種典型的持久化模式:RDB、AOF,
- RDB持久化,稱為記憶體快照,這種模式是把當前Redis服務的記憶體資料在某一點dump生成快照保存到磁盤上的程序,由于是某一時刻的快照,開啟快照后發起后所有操作命令都不會再被記錄,
- AOF 持久化,AOF持久化以日志的形式記錄Redis所執行的每個寫操作,注意查詢操作不會記錄,可以打開磁盤檔案看到每條詳細的操作記錄,
關于Redis持久化這里不做過多詳細介紹,大家需要記住開啟持久化后會對Redis的訪問性能帶來影響就行,后面會專文講解兩種持久化模式的細節,本文主要對持久化影響Redis訪問回應進行分析說明,
1.RDB鏡像落盤及AOF重寫時的影響
Redis開始執行RDB或者AOF Rewrite后,主行程都會創建出一個子行程進行資料的持久化落盤操作,在這個程序中,則會呼叫作業系統的 fork 操作,
通過 fork 對記憶體資料的 copy-On-Write 機制最廉價的實作記憶體鏡像,雖然記憶體是 copy on write 的,但是虛擬記憶體表是在 fork 的瞬間就需要分配,所以這個操作會造成主執行緒短時間的卡頓(停止所有讀寫操作),這個卡頓時間和當前 Redis 的記憶體使用量有關,
根據經驗 GB 量級的 Redis 進行 fork 操作的時間在毫秒級,
如果這個Redis實體很大,CPU負載再高些,那么 fork 的耗時就會更長,甚至達到秒級,也就會嚴重影響 Redis 的訪問回應時間,
這時反映到業務層面表現就是仿佛Redis服務有一瞬間卡主了,所有的請求不再快速回傳,大量的超時出現,然后一會突然又好了,
# 相關監控指標上一次fork操作耗時,單位微秒
redis> info stats
,,
latest_fork_usec:67412
可以添加一個監控,如果發現這個耗時過長且頻繁出現,就需要警惕了,
為了避免這種情況,可以采取以下優化方式:
- 關閉RDB和AOF的自動觸發機器,避免業務高峰自動觸發執行;
- 控制 Redis 使用記憶體大小,建議控制在20G 以下,因為執行 fork 的耗時與資料記憶體大小有關,資料越多,耗時會越久;
- 對于主從集群架構,建議關閉主庫AOF,從庫開啟;對于有備份需求的集群,也可以在從庫發起RDB備份操作;
- 合理配置 repl-backlog-size大小,降低主從全量重傳【2.8版本之前的節點強烈建議升級】;
- 盡量不要使用虛擬機,fork 的耗時也與系統也有關,虛擬機比物理機耗時更長,
2.AOF持久化磁盤IO帶來的影響
前文主要介紹了兩種持久化程序中Fork操作對性能的影響,現在主要說下AOF持久化開啟后對性能的影響,
關于AOF持久化刷盤的三種策略【no/everysec/always】,這里不過多講解,大家可以自行查閱資料,
當 Redis 開啟 AOF持久化 后,兩個主要動作:
- Redis 接收寫命令后,把命令寫入 AOF 檔案緩沖區中(AOF write)
- 根據AOF 刷盤策略【everysec/always】,把 AOF 緩沖資料刷到磁盤上(AOF fsync)
AOF 持久化最耗時的刷盤操作,都是在后臺執行緒執行的,但為什么也會影響到 Redis 主執行緒處理請求呢?
這里需要分析下AOF執行檔案持久化重繪時的流程:
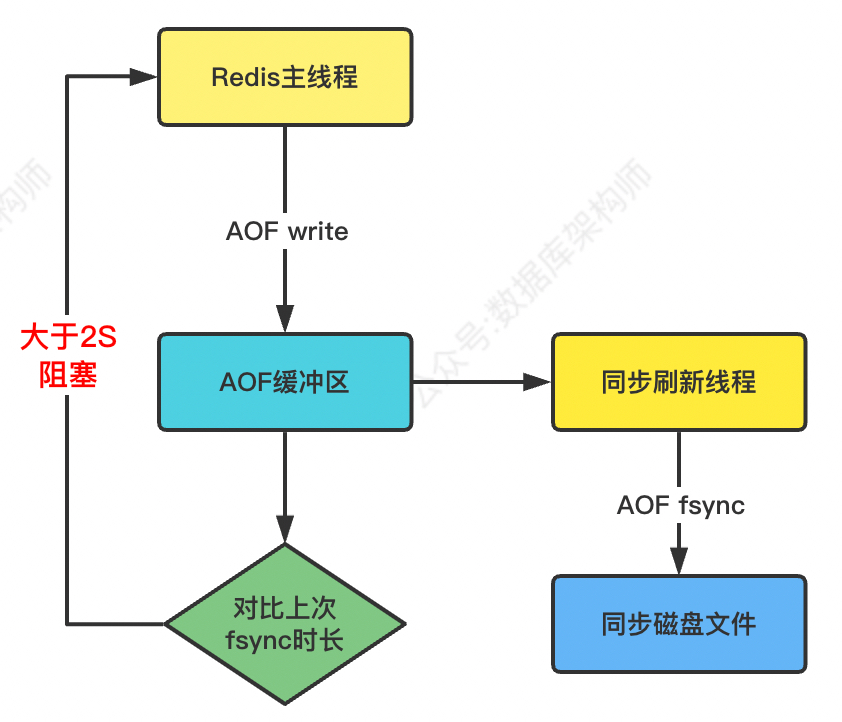
具體處理流程:
- 資料寫入請求來后,主執行緒寫入AOF緩沖區;
- AOF fsync后臺執行緒每秒一次執行磁盤檔案刷入操作,并記錄最近一次同步時間;
- 主執行緒對比AOF同步時間:
- 如果距離上次fsync同步時間在兩秒內,主執行緒繼續進行寫入
- 如果距離上次fsync同步時間超過兩秒(比如磁盤的 IO 負載很高導致同步寫磁盤很慢,還在持續寫入沒有結束),主執行緒將會被阻塞, 直到同步完成,
如果fsync過慢,這時系統日志中會有如下提示資訊:
Asynchronous AOF fsync is taking too long (disk is busy?). Writing the AOF buffer without waiting for fsync to complete, this may slow down Redis.
Redis自身也提供了相關的性能指標:
redis>info Persistence
,,
aof_delayed_fsync:2
如果aof_delayed_fsync一直在增加,說明主執行緒頻繁出現被阻塞情況,那么就需要關注是否持久化過慢造成Redis訪問變慢了,
針對AOF持久化對Redis性能可能帶來的影響可以參考如下幾種解決方案:
- SSD 磁盤存盤,確保AOF刷盤時有充足的IO能力
- 對于主從集群架構,建議關閉主庫AOF,從庫開啟
- 將no-appendfsync-on-rewrite引數設定為yes, 確保aof檔案rewrite期間不做fsync操作,減少IO爭用
- 單臺服務器不要部署過多持久化實體節點,避免磁盤IO爭搶帶來持久化壓力
二、記憶體碎片過大及整理帶來的性能損耗
Redis 的所有資料都在記憶體中,當應用頻繁修改時,就會導致產生記憶體碎片,過高的記憶體碎片率,不僅會浪費記憶體資源還會影響請求處理的效率,
那么,是什么原因導致Redis 產生碎片的呢?原理是什么,能避免嗎?
當前Redis 都默認使用jemalloc記憶體分配器來分配記憶體,它一般是按固定大小來分配記憶體空間,而不會按照應用程式申請的記憶體大小給實際分配,當程式申請的記憶體大小最接近某個固定值時,如8 byte、16 byte,…,2KB、4KB 等,jemalloc 會給它分配相應大小的空間,
這樣的方式好處是為了減少分配次數,假設Redis申請一個 10 byte的記憶體空間存盤資料,jemalloc 會分配 16 byte,此時,如果應用還要再寫入 4 byte的資料,Redis 就不用再向作業系統申請空間了,因為剛才分配的 16 byte已經夠用了,也就避免了一次額外分配操作開銷,
所以Redis每次分配的記憶體空間一般都會比申請的實際需求空間大一些,這種分配方式就自然會導致形成碎片,
從目前Redis記憶體的分配機制來看,目前碎片無法完全避免,
Redis 的記憶體利用率的高低除了成本外,也會直接影響到 Redis 運行效率的高低,可以使用如下命令查看Redis記憶體使用、碎片率、分配器版本等詳細資訊:
redis> info Memory
used_memory:6617819416
used_memory_human:6.16G
used_memory_rss:9788588032
used_memory_rss_human:9.12G
...
rss_overhead_ratio:1.00
rss_overhead_bytes:-21159936
mem_fragmentation_ratio:1.48
mem_fragmentation_bytes: 3250855264
...
mem_allocator:jemalloc-5.1.0
...
mem_fragmentation_ratio 就是Redis 當前的記憶體碎片率大小,碎片率計算方法:
mem_fragmentation_ratio=used_memory_rss/used_memory
used_memory 表示存盤的資料實際占用記憶體的大小,而used_memory_rss 指作業系統分配給 Redis行程服務的實際大小,也就是使用top命令查看Redis行程占用的記憶體,
一般當mem_fragmentation_ratio>1.5時,就說明記憶體碎片率已經超過了50%,此時建議采取措施來降低記憶體碎片大小,
如何清理記憶體碎片呢?根據版本的不同有兩種方式:
- Redis 4.0 以前的低版本,只能通過重啟實體來解決,不能自動配置回收
- 從 4.0版本以后,提供了一種記憶體碎片自動回收的方法,可以通過配置動態開啟碎片整理
但要注意:開啟記憶體碎片整理,會導致 Redis 服務性能下降,
Redis 的碎片整理作業是在主執行緒中執行的,當其進行碎片整理時,作業系統會把多份資料拷貝到新位置以把原有空間釋放出來,這會帶來時間開銷,而這個程序就會阻塞Redis處理請求,
為了降低碎片整理帶來的性能影響,Redis 為自動記憶體碎片整理功機制提供了多個引數,具體有:
activedefrag yes #是否開啟碎片整理
active-defrag-ignore-bytes 500mb #碎片大小超過 500MB 時才會觸發整理
active-defrag-threshold-lower 20 #碎片大小占作業系統分配總空間比超過 20% 時觸發整理
active-defrag-cycle-min 15 #碎片整理程序占用的CPU比例不低于 15%,保證整理可以正常執行
active-defrag-cycle-max 70 #碎片整理程序占用的CPU比例不高于70%,一旦超過就暫停整理,避免大量的記憶體拷貝等整理程序占用過多的CPU進而影響正常請求
active-defrag-max-scan-fields 500 #碎片整理程序中,對于 Hash、List、Set、ZSet 等成員集合型別一次掃描的元素數量
在開啟碎片自動整理時,一定要優先評估當前 Redis 服務的負載狀態,以及應用程式可接受的回應延遲,合理設定碎片整理的引數值和回收時間段【比如放到凌晨程式定時觸發】,來盡可能降低碎片整理期間對Redis服務的影響,

如果這篇文章對你有識訓,還請幫忙點贊、在看、轉發 一下,您的支持會激勵我們輸出更多高質量的文章,非常感謝!
如果你還想看更多優質文章,歡迎關注公號「資料庫架構師」或掃描我的二維碼,添加個人微信,技術交流、圍觀朋友圈,一起學習和成長
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/507132.html
標籤:Java
上一篇:一文快速了解Nacos
下一篇:從Spring中學到的【1】--讀懂繼承鏈