前言
嗨嘍,大家好呀~這里是愛看美女的茜茜吶
又到了學Python時刻~

你還在為一個一個下載壁紙而煩惱嗎,那有沒有更加簡單的方法呢?
跟著我,一起來看看我是如何批量下載的吧
環境使用:
-
python3.8 | Anaconda
-
pycharm
相關模塊:
-
requests >>> pip install requests
-
parsel
模塊安裝方法:win + R 輸入 cmd 點擊確定, 輸入安裝命令 pip install 模塊名, 回車
插 件:
xpath helper擴展工具包
安裝步驟:先獲取xpath helper擴展工具包(注意:不要解壓)
》》 打開Google瀏覽器 --> 更多工具 --> 擴展程式 --> 打開開發者模式 --> 把xpath helper擴展工具包直接拖入 --> 重繪
使用方法:快捷鍵 ctrl+shift+X
基本思路
1.網頁的圖片怎么來的?
寫代碼(爬蟲): 網頁源代碼 瀏覽器 --> 決議資料
第一頁 --> 41頁
-
發送請求
-
回應資料
-
決議資料 圖片
-
保存資料
代碼
import requests # 需要下載 知道 1 不知道 2 pip install requests win+R --> cmd import re # 正則 不需要下載 import parsel #資料決議 需要下載

# 偽裝 headers = { # 用戶代理 瀏覽器基本的身份資訊 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } # 發送請求 response資料請求狀態 response = requests.get(url,headers) # print 列印輸出 <Response [200]> 回應物件 200 狀態碼 成功 print(response) """ 2.回應資料 網頁源代碼 """ # print(response.text) """ 3.決議資料 圖片 re """ # .*? 精準查找 re_data = re.findall('<a href="https://www.cnblogs.com/Qqun261823976/p/(.*?)" target="_blank"rel="bookmark">(.*?)</a>',response.text) print(re_data) # for回圈 for link,title in re_data: # print(link) response_1 = requests.get(link, headers).text # print(response_1) # 決議資料 標簽詳情頁 selector = parsel.Selector(response_1) # css:定位 img_url 圖片鏈接 img_url = selector.css('.entry-content img::attr(src)').getall() # print(img_url) for img in img_url: print(img) img_name = img.split('/')[-1] # content 二進制 content = requests.get(img,headers).content """ 4.保存資料 """ with open('img\\'+ img_name, mode='wb') as file: file.write(content)
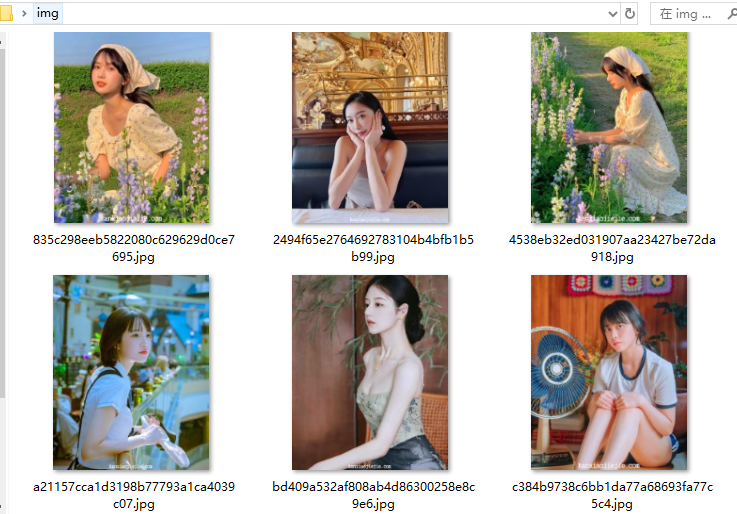








文章看不懂,我專門錄了對應的視頻講解,本文只是大致展示,完整代碼和視頻教程點擊下方藍字
==點擊 藍色字體 自取,我都放在這里了,==
尾語 ??
感謝你觀看我的文章吶~本次航班到這里就結束啦 ??
希望本篇文章有對你帶來幫助 ??,有學習到一點知識~
躲起來的星星??也在努力發光,你也要努力加油(讓我們一起努力叭),
最后,博主要一下你們的三連呀(點贊、評論、收藏),不要錢的還是可以搞一搞的嘛~
不知道評論啥的,即使扣個6666也是對博主的鼓舞吖 ?? 感謝 ??

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/508058.html
標籤:Python
下一篇:python 模塊、原始字串