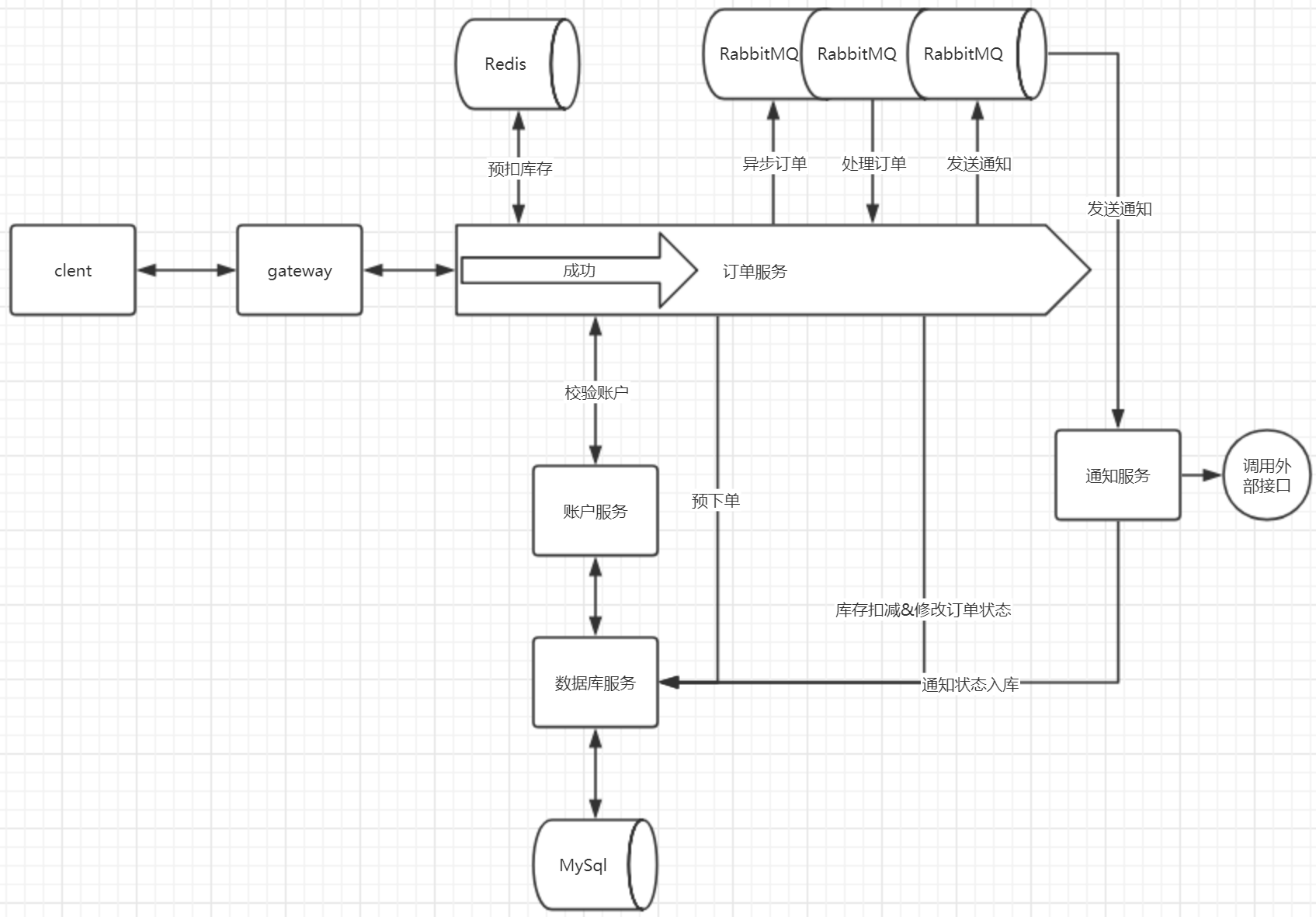
業務模塊介紹
現在我們對整體的業務進行介紹以及演示
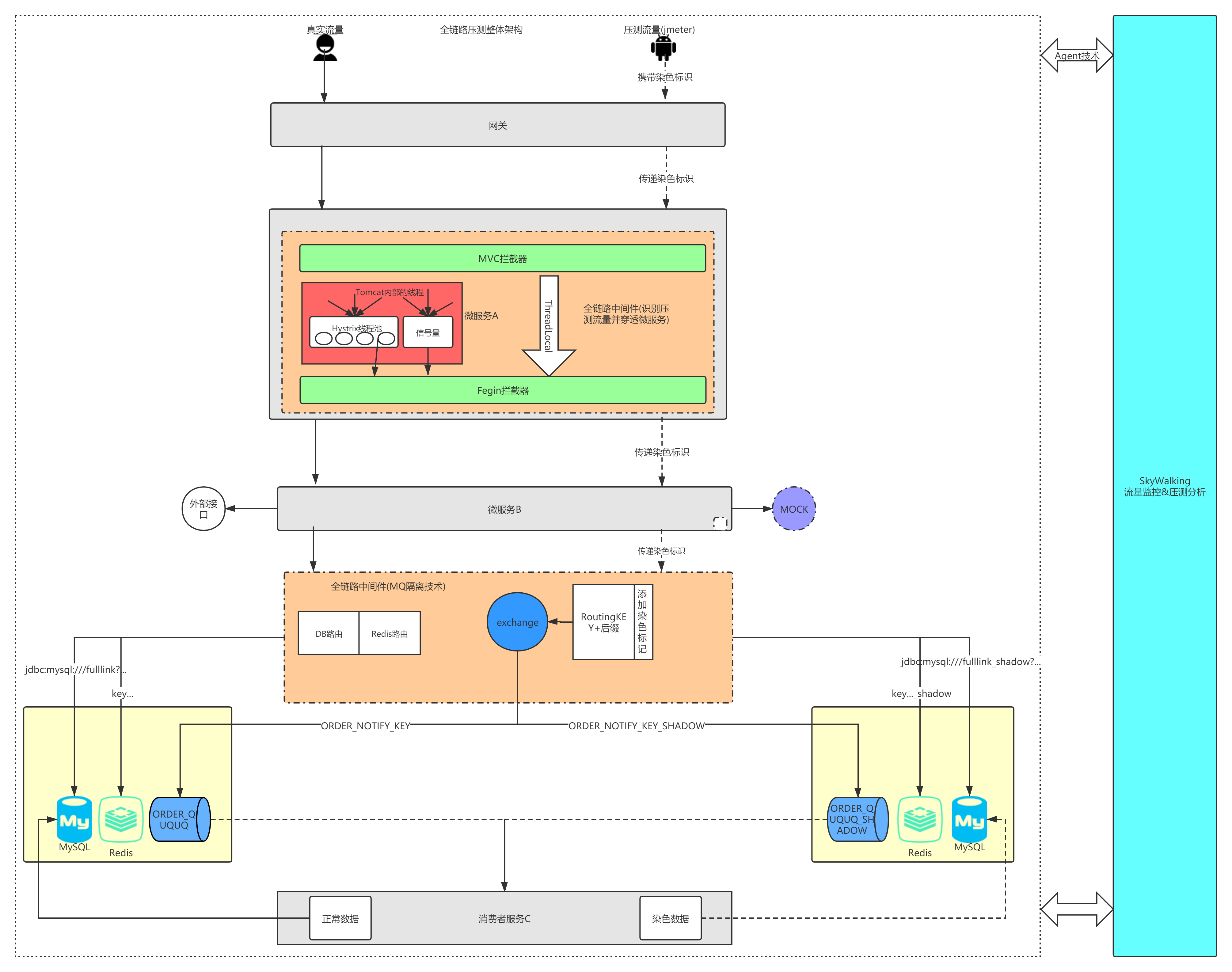
5. 全鏈路整體架構
上面介紹了為什么需要全鏈路壓測,下面來看下全鏈路壓測的整體架構,
? 整體架構如下主要是對壓測客戶端的壓測資料染色,全鏈路中間件識別出染色資料,并將正常資料和壓測資料區分開,進行資料隔離,這里主要涉及到mysql資料庫,RabbitMQ,Redis,還需要處理因為hystrix執行緒池不能通過ThreadLocal傳遞染色表示的問題,
5.1 需要應對的問題
5.1.1 業務問題
如何開展全鏈路壓測?在說這個問題前,我們先考慮下,全鏈路壓測有哪些問題比較難解決,
-
涉及的系統太多,牽扯的開發人員太多
? 在壓測程序中,做一個全鏈路的壓測一般會涉及到大量的系統,在整個壓測程序中,光各個產品的人員協調就是一個比較大的工程,牽扯到太多的產品經理和開發人員,如果公司對全鏈路壓測早期沒有足夠的重視,那么這個壓測作業是非常難開展的,
-
模擬的測驗資料和訪問流量不真實
? 在壓測程序中經常會遇到壓測后得到的資料不準確的問題,這就使得壓測出的資料參考性不強,為什么會產生這樣的問題?主要就是因為壓測的環境可能和生成環境存在誤差、引數存在不一樣的地方、測驗資料存在不一樣的地方這些因素綜合起來導致測驗結果的不可信,
-
壓測生產資料未隔離,影響生產環境
? 在全鏈路壓測程序中,壓測資料可能會影響到生產環境的真實資料,舉個例子,電商系統在生產環境進行全鏈路壓測的時候可能會有很多壓測模擬用戶去下單,如果不做處理,直接下單的話會導致系統一下子會產生很多廢訂單,從而影響到庫存和生產訂單資料,影響到日常的正常運營,
5.1.2 技術問題
5.1.2.1 探針的性能消耗
APM組件服務的影回應該做到足夠小,
? 服務呼叫埋點本身會帶來性能損耗,這就需要呼叫跟蹤的低損耗,實際中還會通過配置采樣率的方式,選擇一部分請求去分析請求路徑,在一些高度優化過的服務,即使一點點損耗也會很容易察覺到,而且有可能迫使在線服務的部署團隊不得不將跟蹤系統關停,
5.1.2.2 代碼的侵入性
即也作為業務組件,應當盡可能少入侵或者無入侵其他業務系統,對于使用方透明,減少開發人員的負擔,
? 對于應用的程式員來說,是不需要知道有跟蹤系統這回事的,如果一個跟蹤系統想生效,就必須需要依賴應用的開發者主動配合,那么這個跟蹤系統也太脆弱了,往往由于跟蹤系統在應用中植入代碼的bug或疏忽導致應用出問題,這樣才是無法滿足對跟蹤系統“無所不在的部署”這個需求,
5.1.2.3 可擴展性
? 一個優秀的呼叫跟蹤系統必須支持分布式部署,具備良好的可擴展性,能夠支持的組件越多當然越好,或者提供便捷的插件開發API,對于一些沒有監控到的組件,應用開發者也可以自行擴展,
5.1.2.4 資料的分析
? 資料的分析要快 ,分析的維度盡可能多,跟蹤系統能提供足夠快的資訊反饋,就可以對生產環境下的例外狀況做出快速反應,分析的全面,能夠避免二次開發,
5.2 全鏈路壓測核心技術
上面從總體架構層面分析了全鏈路壓測的核心,下面就分析下全鏈路壓測用到的核心技術點
5.2.1 全鏈路流量染色
做到微服務和中間件的染色標志的穿透
? 通過壓測平臺對輸出的壓力請求打上標識,在訂單系統中提取壓測標識,確保完整的程式背景關系都持有該標識,并且能夠穿透微服務以及各種中間件,比如 MQ,hystrix,Fegin等,
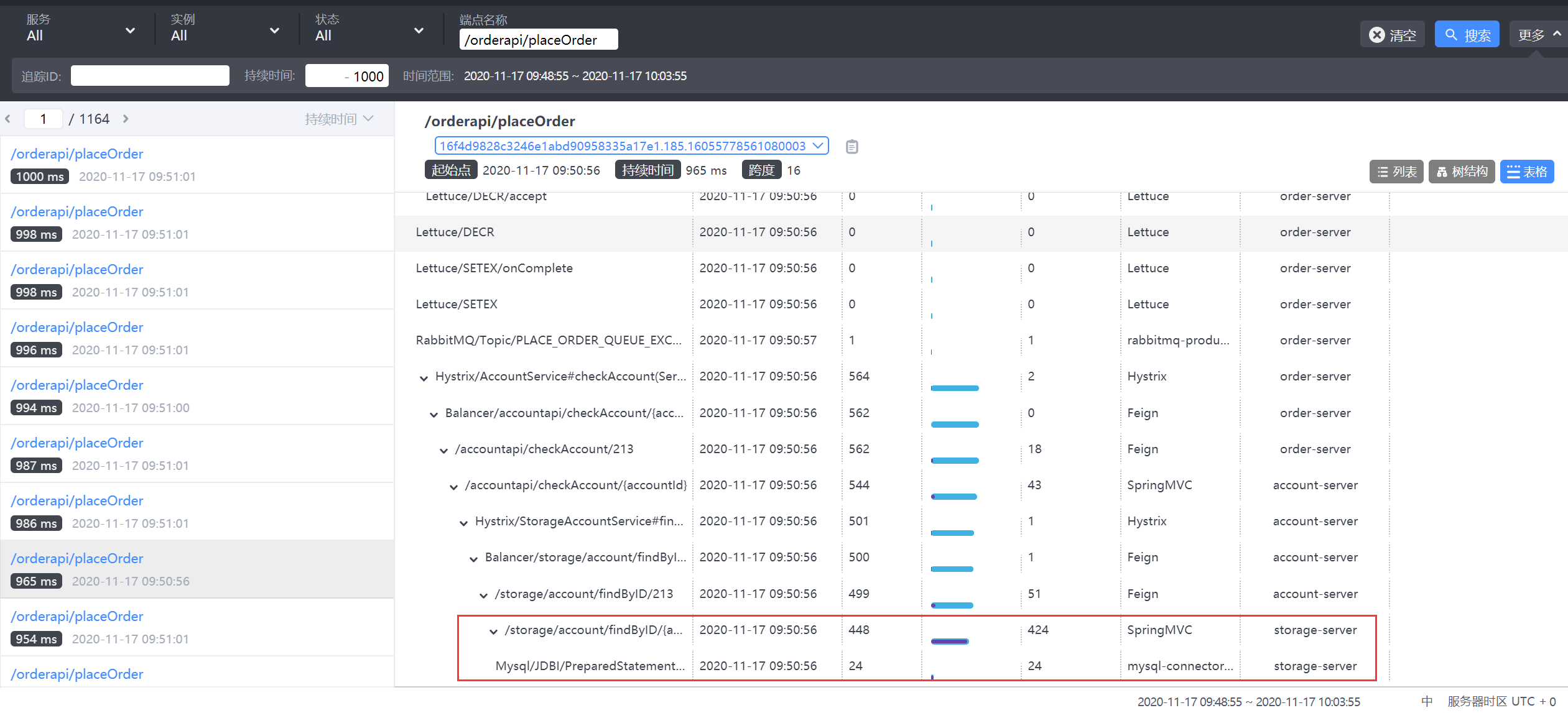
5.2.2 全鏈路服務監控
需要能夠實時監控服務的運行狀況以及分析服務的呼叫鏈,我們采用skywalking進行服務監控和壓測分析
5.2.3 全鏈路日志隔離
做到日志隔離,防止污染生產日志
? 當訂單系統向磁盤或外設輸出日志時,若流量是被標記的壓測流量,則將日志隔離輸出,避免影響生產日志,
5.2.4 全鏈路風險熔斷
流量控制,防止流量超載,導致集群不可用
? 當訂單系統訪問會員系統時,通過RPC協議延續壓測標識到會員系統,兩個系統之間服務通訊將會有白黑名單開關來控制流量流入許可,該方案設計可以一定程度上避免下游系統出現瓶頸或不支持壓測所帶來的風險,這里可以采用Sentinel來實作風險熔斷,
5.3 全鏈路資料隔離
對各種存盤服務以及中間件做到資料隔離,方式資料污染
2.3.1 資料庫隔離
? 當會員系統訪問資料庫時,在持久化層同樣會根據壓測標識進行路由訪問壓測資料表,資料隔離的手段有多種,比如影子庫、影子表,或者影子資料,三種方案的仿真度會有一定的差異,他們的對比如下,
| 隔離性 | 兼容性 | 安全級別 | 技術難度 | |
|---|---|---|---|---|
| 影子庫 | 高 | 高 | 高 | 高 |
| 影子表 | 中 | 低 | 中 | 中 |
| 影子資料 | 低 | 低 | 低 | 低 |
5.3.2 訊息佇列隔離
? 當我們生產的訊息扔到MQ之后,接著讓消費者進行消費,這個沒有問題,壓測的資料不能夠直接扔到MQ中的,因為它會被正常的消費者消費到的,要做好資料隔離,方案有佇列隔離,訊息隔離,他們對比如下,
| 隔離性 | 兼容性 | 安全級別 | 技術難度 | |
|---|---|---|---|---|
| 佇列隔離 | 高 | 好 | 高 | 高 |
| 訊息隔離 | 低 | 低 | 低 | 中 |
5.3.3 Redis 隔離
? 通過 key 值來區分,壓測流量的 key 值加統一后綴,通過改造RedisTemplate來實作key的路由,
框架實作
6.1 流量染色方案
上面分析了從整體分析了全鏈路壓測用的的核心技術,下面就來實作第一個流量染色,
6.1.1 流量識別
? 要想壓測的流量和資料不影響線上真實的生產資料,就需要線上的集群能識別出壓測的流量,只要能識別出壓測請求的流量,那么流量觸發的讀寫操作就很好統一去做隔離了,
全鏈路壓測發起的都是Http的請求,只需要要請求頭上添加統一的壓測請求頭,
? 通過在請求協議中添加壓測請求的標識,在不同服務的相互呼叫時,一路透傳下去,這樣每一個服務都能識別出壓測的請求流量,這樣做的好處是與業務完全的解耦,只需要應用框架進行感知,對業務方代碼無侵入,

6.1.2 MVC接收資料
? 客戶端傳遞過來的資料可以通過獲取Header的方式獲取到,并將其設定進當前的ThreadLocal,交給后面的方法使用,
6.1.2.1 MVC攔截器實作
/**
* 鏈路跟蹤Request設定值
*/
public class MvcWormholeWebInterceptor implements WebRequestInterceptor {
@Override
public void preHandle(WebRequest webRequest) {
//失效背景關系,解決Tomcat執行緒復用問題
WormholeContextHolder.invalidContext();
String wormholeValue = https://www.cnblogs.com/jiagooushi/archive/2022/09/14/webRequest.getHeader(WormholeContextHolder.WORMHOLE_REQUEST_MARK);
if (StringUtils.isNotEmpty(wormholeValue)) {
WormholeContextHolder.setContext(new WormholeContext(wormholeValue));
}
}
@Override
public void postHandle(WebRequest webRequest, ModelMap modelMap) throws Exception {
}
@Override
public void afterCompletion(WebRequest webRequest, Exception e) throws Exception {
}
}
6.1.2.2 Tomcat執行緒復用問題
? tomcat默認使用執行緒池來管理執行緒,一個請求過來,如果執行緒池里面有空閑的執行緒,那么會在執行緒池里面取一個執行緒來處理該請求,一旦該執行緒當前在處理請求,其他請求就不會被分配到該執行緒上,直到該請求處理完成,請求處理完成后,會將該執行緒重新加入執行緒池,因為是通過執行緒池復用執行緒,就會如果執行緒內部的ThreadLocal沒有清除就會出現問題,需要新的請求進來的時候,清除ThreadLocal,
6.1.3 Fegin傳遞傳遞染色標識
? 我們專案的微服務是使用Fegin來實作遠程呼叫的,跨微服務傳遞染色標識是通過MVC攔截器獲取到請求Header的染色標識,并放進ThreadLocal中,然后交給Fegin攔截器在發送請求之前從ThreadLocal中獲取到染色標識,并放進Fegin構建請求的Header中,實作微服務之間的火炬傳遞,
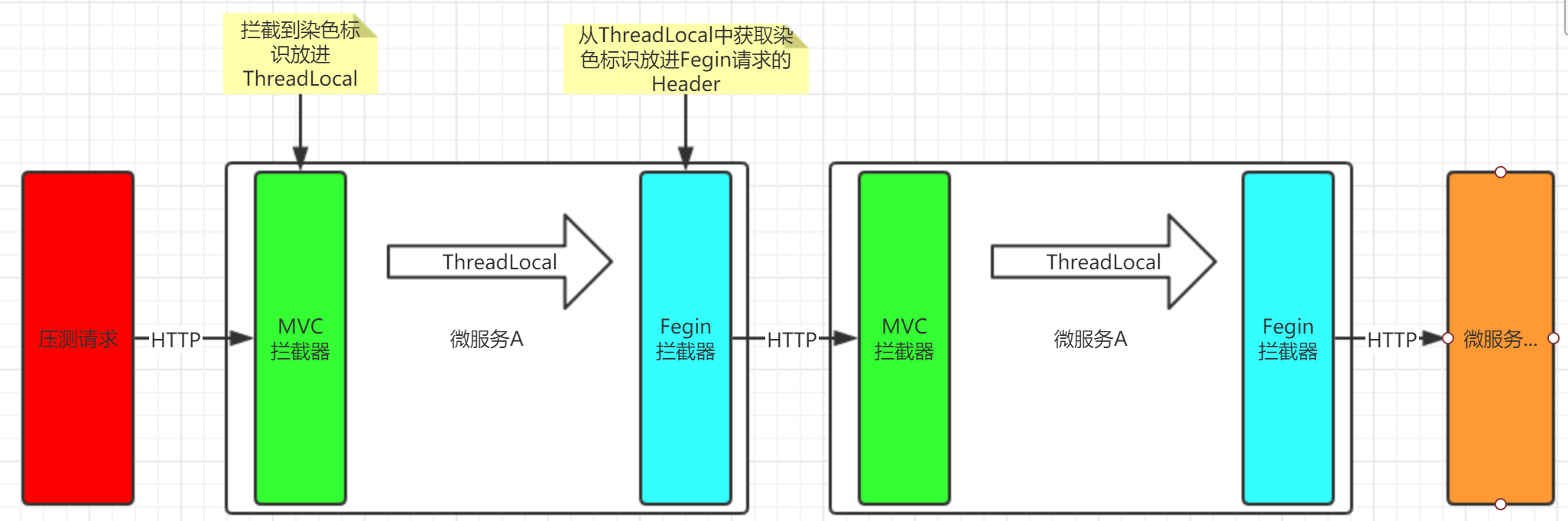
6.1.3.1 代碼實作
public class WormholeFeignRequestInterceptor implements RequestInterceptor {
@Override
public void apply(RequestTemplate requestTemplate) {
WormholeContext wormholeContext = WormholeContextHolder.getContext();
if (null != wormholeContext) {
requestTemplate.header(WormholeContextHolder.WORMHOLE_REQUEST_MARK, wormholeContext.toString());
}
}
}
6.1.4 Hystrix傳遞染色標識
6.1.4.1 Hystrix隔離技術
Hystrix 實作資源隔離,主要有兩種技術:
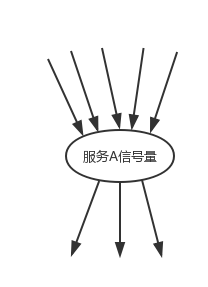
信號量
? 信號量的資源隔離只是起到一個開關的作用,比如,服務 A 的信號量大小為 10,那么就是說它同時只允許有 10 個 tomcat 執行緒來訪問服務 A,其它的請求都會被拒絕,從而達到資源隔離和限流保護的作用,
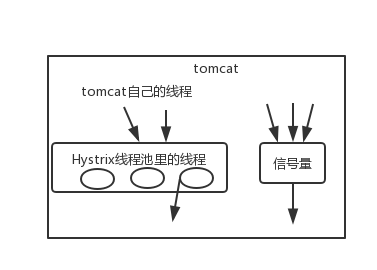
執行緒池
? 執行緒池隔離技術,是用 Hystrix 自己的執行緒去執行呼叫;而信號量隔離技術,是直接讓 tomcat 執行緒去呼叫依賴服務,信號量隔離,只是一道關卡,信號量有多少,就允許多少個 tomcat 執行緒通過它,然后去執行,
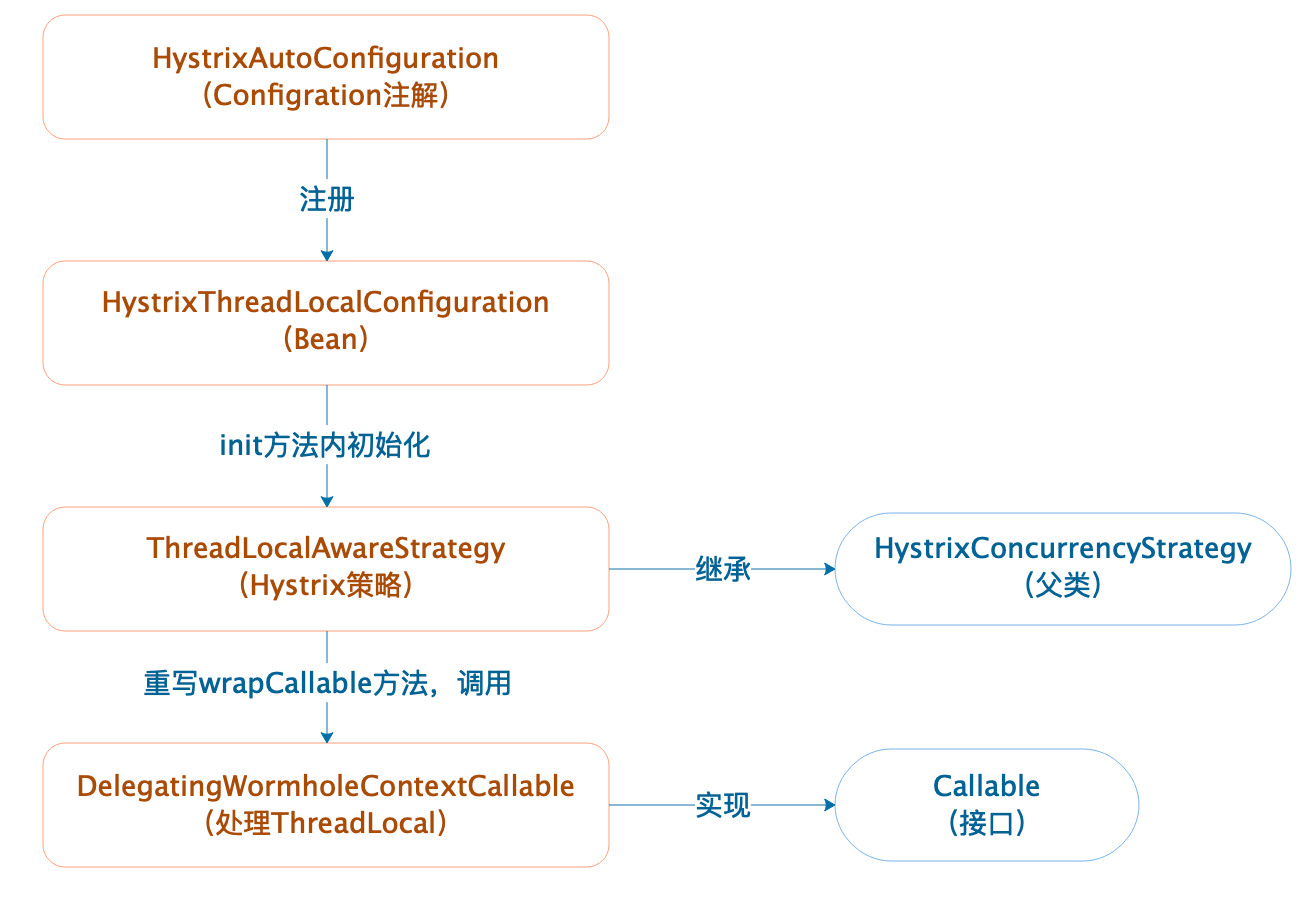
6.1.4.2 Hystrix穿透
? 如果使用執行緒池模式,那么存在一個ThreadLocal變數跨執行緒傳遞的問題,即在主執行緒的ThreadLocal變數,無法在執行緒池中使用,不過Hystrix內部提供了解決方案,
封裝Callable任務
public final class DelegatingWormholeContextCallable<V> implements Callable<V> {
private final Callable<V> delegate;
// 用戶資訊背景關系(根據專案實際情況定義ThreadLocal背景關系)
private WormholeContext orginWormholeContext;
public DelegatingWormholeContextCallable(Callable<V> delegate,
WormholeContext wormholeContext) {
this.delegate = delegate;
this.orginWormholeContext = wormholeContext;
}
public V call() throws Exception {
//防止執行緒復用銷毀ThreadLocal的資料
WormholeContextHolder.invalidContext();
// 將當前的用戶背景關系設定進Hystrix執行緒的TreadLocal中
WormholeContextHolder.setContext(orginWormholeContext);
try {
return delegate.call();
} finally {
// 執行完畢,記得清理ThreadLocal資源
WormholeContextHolder.invalidContext();
}
}
public static <V> Callable<V> create(Callable<V> delegate,
WormholeContext wormholeContext) {
return new DelegatingWormholeContextCallable<V>(delegate, wormholeContext);
}
}
實作Hystrix的并發策略類
因為Hystrix默認的并發策略不支持ThreadLocal傳遞,我們可以自定義并發策略類繼承HystrixConcurrencyStrategy
public class ThreadLocalAwareStrategy extends HystrixConcurrencyStrategy {
// 最簡單的方式就是引入現有的并發策略,進行功能擴展
private final HystrixConcurrencyStrategy existingConcurrencyStrategy;
public ThreadLocalAwareStrategy(
HystrixConcurrencyStrategy existingConcurrencyStrategy) {
this.existingConcurrencyStrategy = existingConcurrencyStrategy;
}
@Override
public BlockingQueue<Runnable> getBlockingQueue(int maxQueueSize) {
return existingConcurrencyStrategy != null
? existingConcurrencyStrategy.getBlockingQueue(maxQueueSize)
: super.getBlockingQueue(maxQueueSize);
}
@Override
public <T> HystrixRequestVariable<T> getRequestVariable(
HystrixRequestVariableLifecycle<T> rv) {
return existingConcurrencyStrategy != null
? existingConcurrencyStrategy.getRequestVariable(rv)
: super.getRequestVariable(rv);
}
@Override
public ThreadPoolExecutor getThreadPool(HystrixThreadPoolKey threadPoolKey,
HystrixProperty<Integer> corePoolSize,
HystrixProperty<Integer> maximumPoolSize,
HystrixProperty<Integer> keepAliveTime, TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
return existingConcurrencyStrategy != null
? existingConcurrencyStrategy.getThreadPool(threadPoolKey, corePoolSize,
maximumPoolSize, keepAliveTime, unit, workQueue)
: super.getThreadPool(threadPoolKey, corePoolSize, maximumPoolSize,
keepAliveTime, unit, workQueue);
}
@Override
public <T> Callable<T> wrapCallable(Callable<T> callable) {
return existingConcurrencyStrategy != null
? existingConcurrencyStrategy
.wrapCallable(new DelegatingWormholeContextCallable<>(callable, WormholeContextHolder.getContext()))
: super.wrapCallable(new DelegatingWormholeContextCallable<T>(callable, WormholeContextHolder.getContext()));
}
}
Hystrix注入新并發策略并進行重繪
public class HystrixThreadLocalConfiguration {
@Autowired(required = false)
private HystrixConcurrencyStrategy existingConcurrencyStrategy;
@PostConstruct
public void init() {
// Keeps references of existing Hystrix plugins.
HystrixEventNotifier eventNotifier = HystrixPlugins.getInstance()
.getEventNotifier();
HystrixMetricsPublisher metricsPublisher = HystrixPlugins.getInstance()
.getMetricsPublisher();
HystrixPropertiesStrategy propertiesStrategy = HystrixPlugins.getInstance()
.getPropertiesStrategy();
HystrixCommandExecutionHook commandExecutionHook = HystrixPlugins.getInstance()
.getCommandExecutionHook();
HystrixPlugins.reset();
HystrixPlugins.getInstance().registerConcurrencyStrategy(new ThreadLocalAwareStrategy(existingConcurrencyStrategy));
HystrixPlugins.getInstance().registerEventNotifier(eventNotifier);
HystrixPlugins.getInstance().registerMetricsPublisher(metricsPublisher);
HystrixPlugins.getInstance().registerPropertiesStrategy(propertiesStrategy);
HystrixPlugins.getInstance().registerCommandExecutionHook(commandExecutionHook);
}
}
6.2 資料隔離方案
6.2.1 JDBC資料源隔離
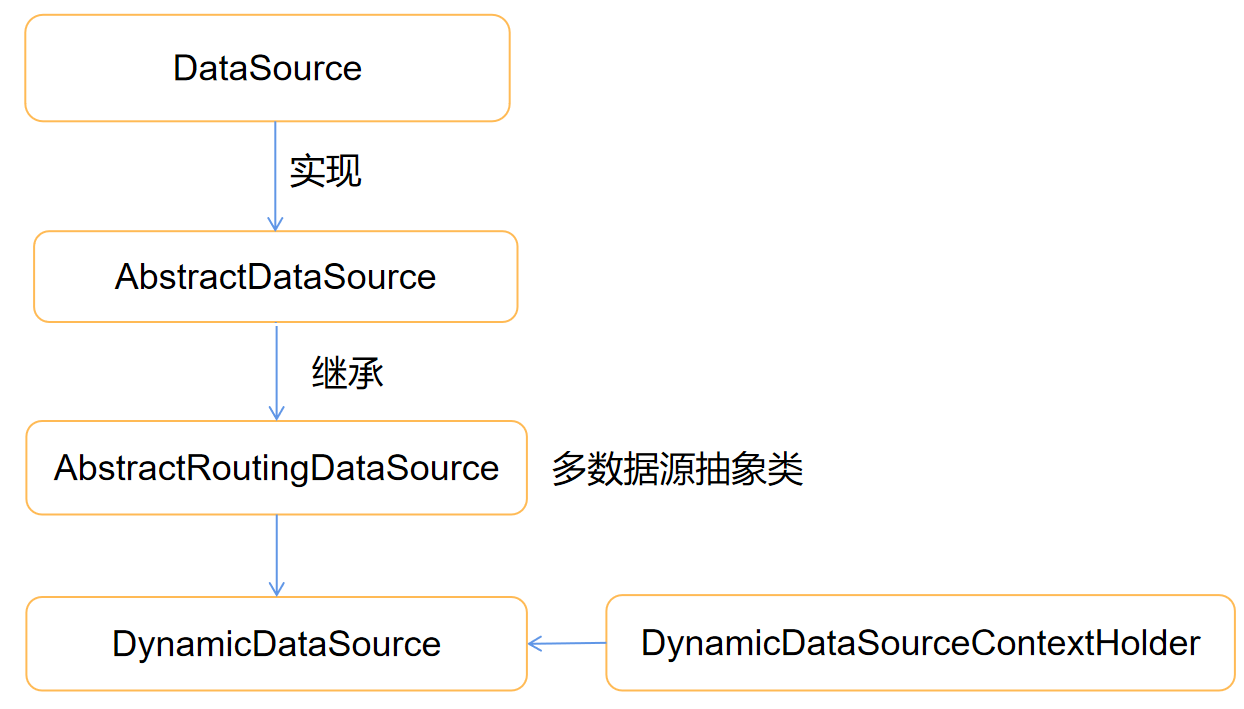
資料隔離需要對DB,Redis,RabbitMQ進行資料隔離
? 通過實作Spring動態資料源AbstractRoutingDataSource,通過ThreadLocal識別出來壓測資料,如果是壓測資料就路由到影子庫,如果是正常流量則路由到主庫,通過流量識別的改造,各個服務都已經能夠識別出壓測的請求流量了,
6.2.1.1 代碼實作
資料源路由Key持有物件
根據路由Key將選擇將操作路由給那個資料源
/**
* 動態資料源背景關系
*/
public class DynamicDataSourceContextHolder {
public static final String PRIMARY_DB = "primary";
public static final String SHADOW_DB = "shadow";
private static final ThreadLocal<String> contextHolder = new ThreadLocal<String>() {
/**
* 將 master 資料源的 key作為默認資料源的 key
*/
@Override
protected String initialValue() {
return PRIMARY_DB;
}
};
/**
* 資料源的 key集合,用于切換時判斷資料源是否存在
*/
public static List<Object> dataSourceKeys = new ArrayList<>();
/**
* 切換資料源
*
* @param key
*/
public static void setDataSourceKey(String key) {
contextHolder.set(key);
}
/**
* 獲取資料源
*
* @return
*/
public static String getDataSourceKey() {
return contextHolder.get();
}
/**
* 重置資料源
*/
public static void clearDataSourceKey() {
contextHolder.remove();
}
/**
* 判斷是否包含資料源
*
* @param key 資料源key
* @return
*/
public static boolean containDataSourceKey(String key) {
return dataSourceKeys.contains(key);
}
/**
* 添加資料源keys
*
* @param keys
* @return
*/
public static boolean addDataSourceKeys(Collection<? extends Object> keys) {
return dataSourceKeys.addAll(keys);
}
}
動態資料源實作類
根據路由Key實作資料源的切換
/**
* 動態資料源實作類
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
/**
* 如果不希望資料源在啟動配置時就加載好,可以定制這個方法,從任何你希望的地方讀取并回傳資料源
* 比如從資料庫、檔案、外部介面等讀取資料源資訊,并最侄訓傳一個DataSource實作類物件即可
*/
@Override
protected DataSource determineTargetDataSource() {
//獲取當前的背景關系
WormholeContext wormholeContext = WormholeContextHolder.getContext();
//如果不為空使用影子庫
if (null != wormholeContext) {
DynamicDataSourceContextHolder.setDataSourceKey(DynamicDataSourceContextHolder.SHADOW_DB);
} else {
//為空則使用主資料源
DynamicDataSourceContextHolder.setDataSourceKey(DynamicDataSourceContextHolder.PRIMARY_DB);
}
return super.determineTargetDataSource();
}
/**
* 如果希望所有資料源在啟動配置時就加載好,這里通過設定資料源Key值來切換資料,定制這個方法
*/
@Override
protected Object determineCurrentLookupKey() {
return DynamicDataSourceContextHolder.getDataSourceKey();
}
}
6.2.2 Redis 資料源隔離
? 同時通過ThreadLocal識別出來壓測資料,自定義Redis的主鍵的序列化方式,如果是壓測資料則在主鍵后面加上后綴,這樣就可以通過不同主鍵將Redis資料進行隔離,
6.2.2.1 實作key序列化
public class KeyStringRedisSerializer extends StringRedisSerializer {
@Resource
private WormholeIsolationConfiguration isolationConfiguration;
public byte[] serialize(@Nullable String redisKey) {
WormholeContext wormholeContext = WormholeContextHolder.getContext();
if (null != wormholeContext) {
redisKey = isolationConfiguration.generateIsolationKey(redisKey);
}
return super.serialize(redisKey);
}
}
6.2.2.2 配置序列化器
/**
* Redis 配置類
*/
@Configuration
@ConditionalOnClass({RedisTemplate.class, RedisOperations.class, RedisConnectionFactory.class})
public class WormholeRedisAutoConfiguration {
@Bean
public KeyStringRedisSerializer keyStringRedisSerializer() {
return new KeyStringRedisSerializer();
}
@Bean("redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory factory) {
RedisTemplate template = new RedisTemplate();
//使用fastjson序列化
FastJsonRedisSerializer fastJsonRedisSerializer = new FastJsonRedisSerializer(Object.class);
// value值的序列化采用fastJsonRedisSerializer
template.setValueSerializer(fastJsonRedisSerializer);
template.setHashValueSerializer(fastJsonRedisSerializer);
// key的序列化采用StringRedisSerializer
template.setKeySerializer(keyStringRedisSerializer());
template.setHashKeySerializer(keyStringRedisSerializer());
template.setConnectionFactory(factory);
return template;
}
@Bean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory factory) throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setKeySerializer(keyStringRedisSerializer());
template.setHashKeySerializer(keyStringRedisSerializer());
template.setConnectionFactory(factory);
return template;
}
}
6.2.3 RabbitMQ 資料隔離
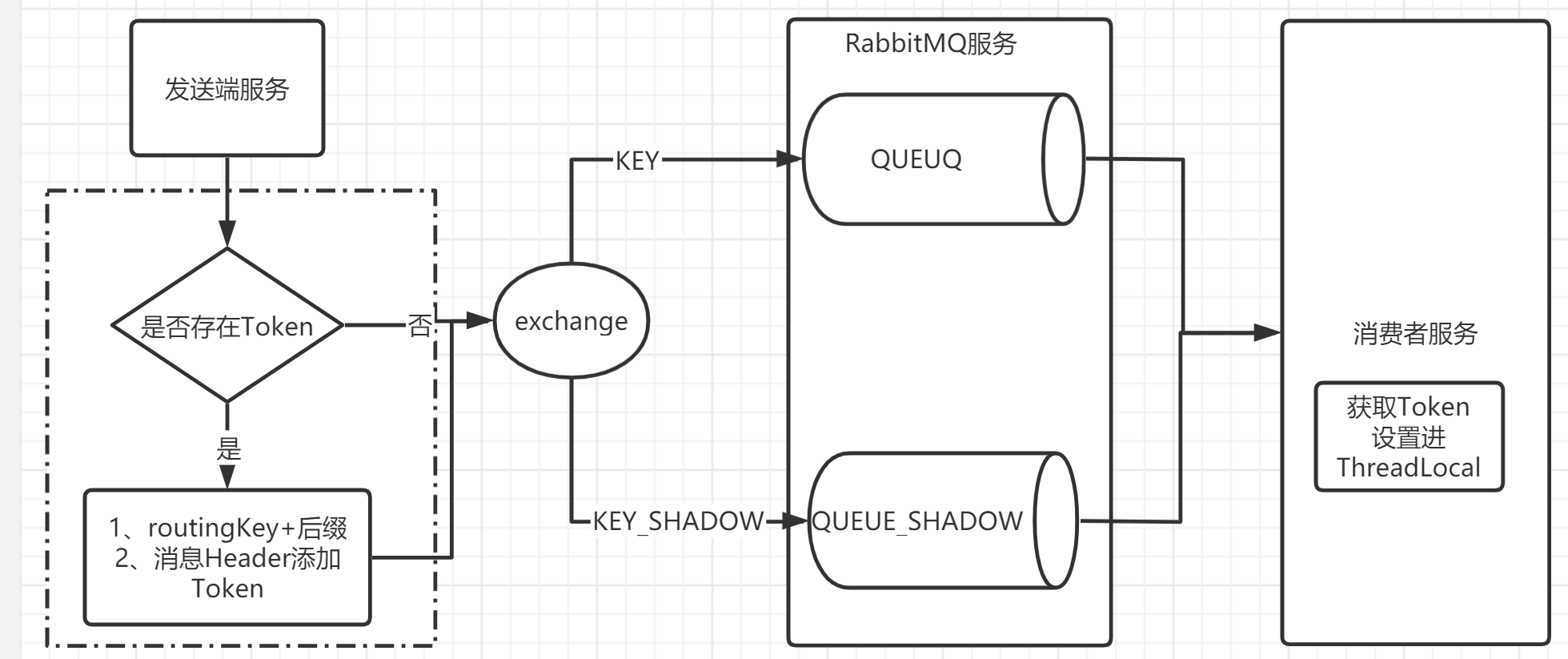
6.2.3.1 自動創建影子佇列
因為SpringAMQP中的
中的關鍵方法是私有的,無法通過繼承的方式進行實作對以配置好的佇列進行擴展,所以需要自定義該類,來實作對自動創建影子佇列,并和交換器進行系結
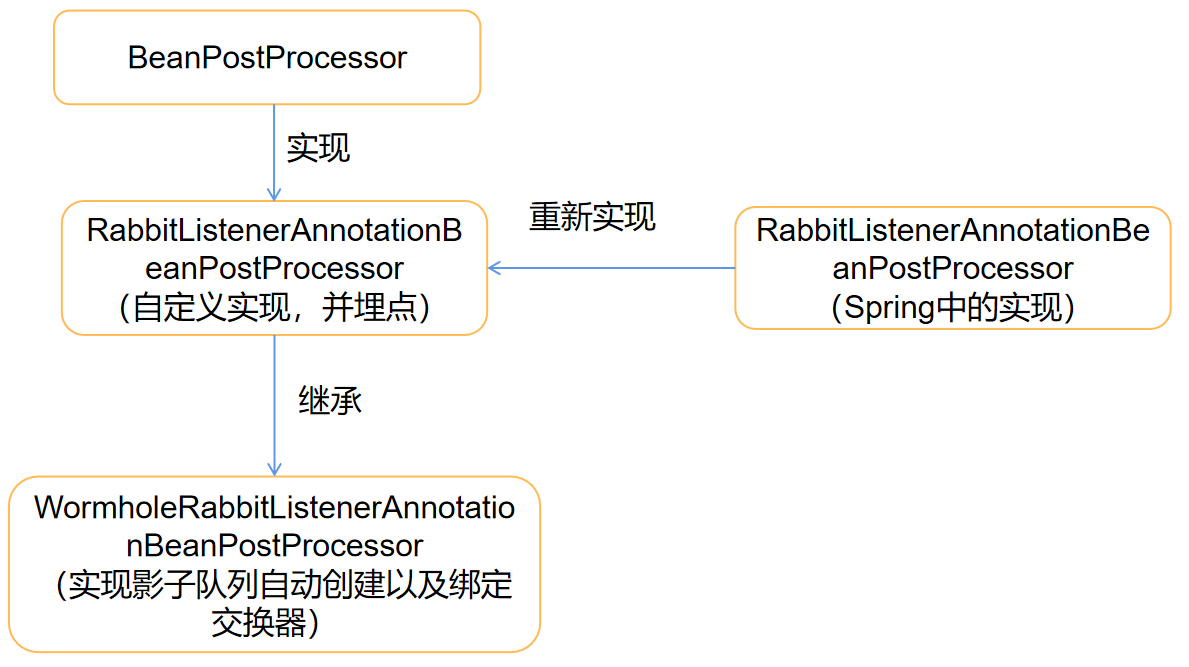
代碼實作
? 改造RabbitListenerAnnotationBeanPostProcessor類來實作創建MQ影子佇列以及將影子Key系結到影子佇列,
public class WormholeRabbitListenerAnnotationBeanPostProcessor extends RabbitListenerAnnotationBeanPostProcessor {
@Resource
private WormholeIsolationConfiguration wormholeIsolationConfiguration;
/**
* routingKey 前置處理器
*
* @param queueName
* @param routingKey
* @return
*/
@Override
public String preProcessingRoutingKey(String queueName, String routingKey) {
//如果是影子佇列就將routingKey轉換為 影子routingKey
if (wormholeIsolationConfiguration.checkIsolation(queueName) && !wormholeIsolationConfiguration.checkIsolation(routingKey)) {
return wormholeIsolationConfiguration.generateIsolationKey(routingKey);
}
return routingKey;
}
/**
* 處理佇列問題,如果來了一個佇列就生成一個shadow的佇列
*
* @param queues
* @return
*/
@Override
public List<String> handelQueues(List<String> queues) {
List<String> isolationQueues = new ArrayList<>();
if (null != queues && !queues.isEmpty()) {
for (String queue : queues) {
//添加shadow佇列
isolationQueues.add(wormholeIsolationConfiguration.generateIsolationKey(queue));
}
queues.addAll(isolationQueues);
}
return queues;
}
}
6.2.3.2 傳遞染色標識
? 因為MQ是異步通訊,為了傳遞染色標識,會在發送MQ的時候將染色標識傳遞過來,MQ接收到之后放進當前執行緒的ThreadLocal里面,這個需要擴展Spring的SimpleRabbitListenerContainerFactory來實作
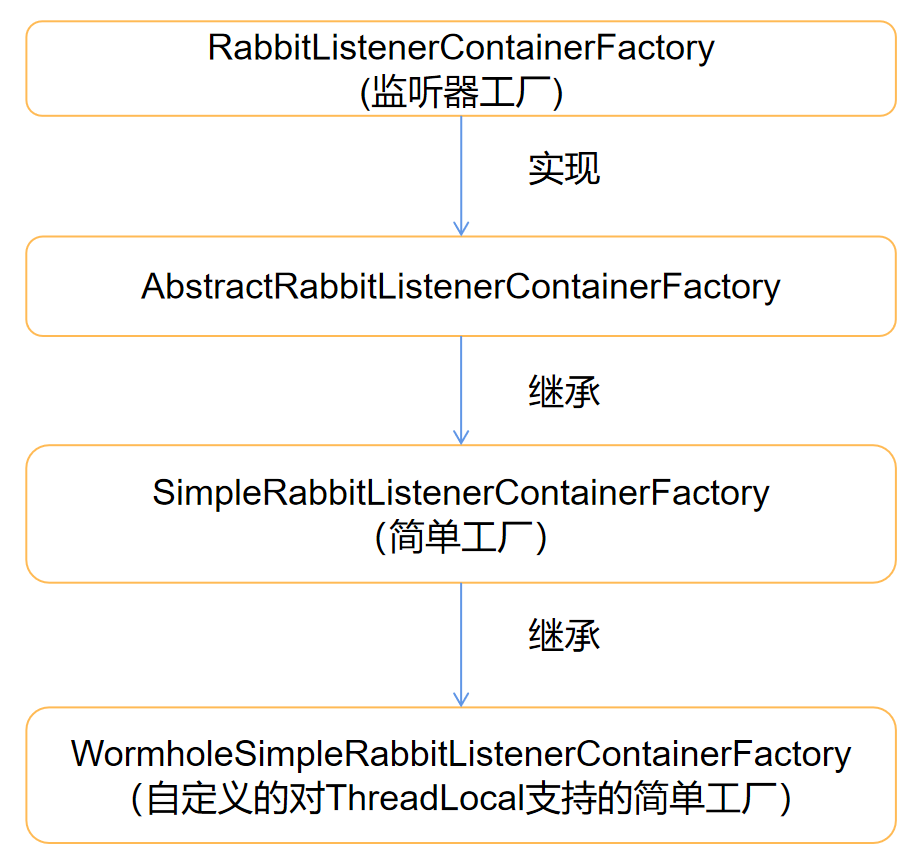
代碼實作
public class WormholeSimpleRabbitListenerContainerFactory extends SimpleRabbitListenerContainerFactory {
@Override
protected SimpleMessageListenerContainer createContainerInstance() {
SimpleMessageListenerContainer simpleMessageListenerContainer = new SimpleMessageListenerContainer();
simpleMessageListenerContainer.setAfterReceivePostProcessors(message -> {
//防止執行緒復用 銷毀ThreadLocal
WormholeContextHolder.invalidContext();
//獲取訊息屬性標識
String wormholeRequestContext = message.getMessageProperties().getHeader(WormholeContextHolder.WORMHOLE_REQUEST_MARK);
if (StringUtils.isNotEmpty(wormholeRequestContext)) {
WormholeContextHolder.setContext(wormholeRequestContext);
}
return message;
});
return simpleMessageListenerContainer;
}
}
6.2.3.3 發送MQ訊息處理
? 同上,需要傳遞染色標識,就通過繼承RabbitTemplate重寫convertAndSend方法來實作傳遞染色標識,
public class ShadowRabbitTemplate extends RabbitTemplate {
public ShadowRabbitTemplate(ConnectionFactory connectionFactory) {
super(connectionFactory);
}
@Autowired
private WormholeIsolationConfiguration isolationConfiguration;
@Override
public void send(final String exchange, final String routingKey,
final Message message, @Nullable final CorrelationData correlationData)
throws AmqpException {
WormholeContext wormholeContext = WormholeContextHolder.getContext();
if (null == wormholeContext) {
super.send(exchange, routingKey, message, correlationData);
} else {
message.getMessageProperties().setHeader(WormholeContextHolder.WORMHOLE_REQUEST_MARK, wormholeContext.toString());
//生成Rabbit 隔離Key
String wormholeRoutingKey = isolationConfiguration.generateIsolationKey(routingKey);
//呼叫父類進行發送
super.send(exchange, wormholeRoutingKey, message, correlationData);
}
}
}
6.3 介面隔離方法
6.3.1 Mock 第三方介面
? 對于第三方資料介面需要進行隔離,比如短信介面,正常的資料需要發送短信,對于壓測資料則不能直接呼叫介面發送短信,并且需要能夠識別出來壓測資料,并進行MOCK介面呼叫,
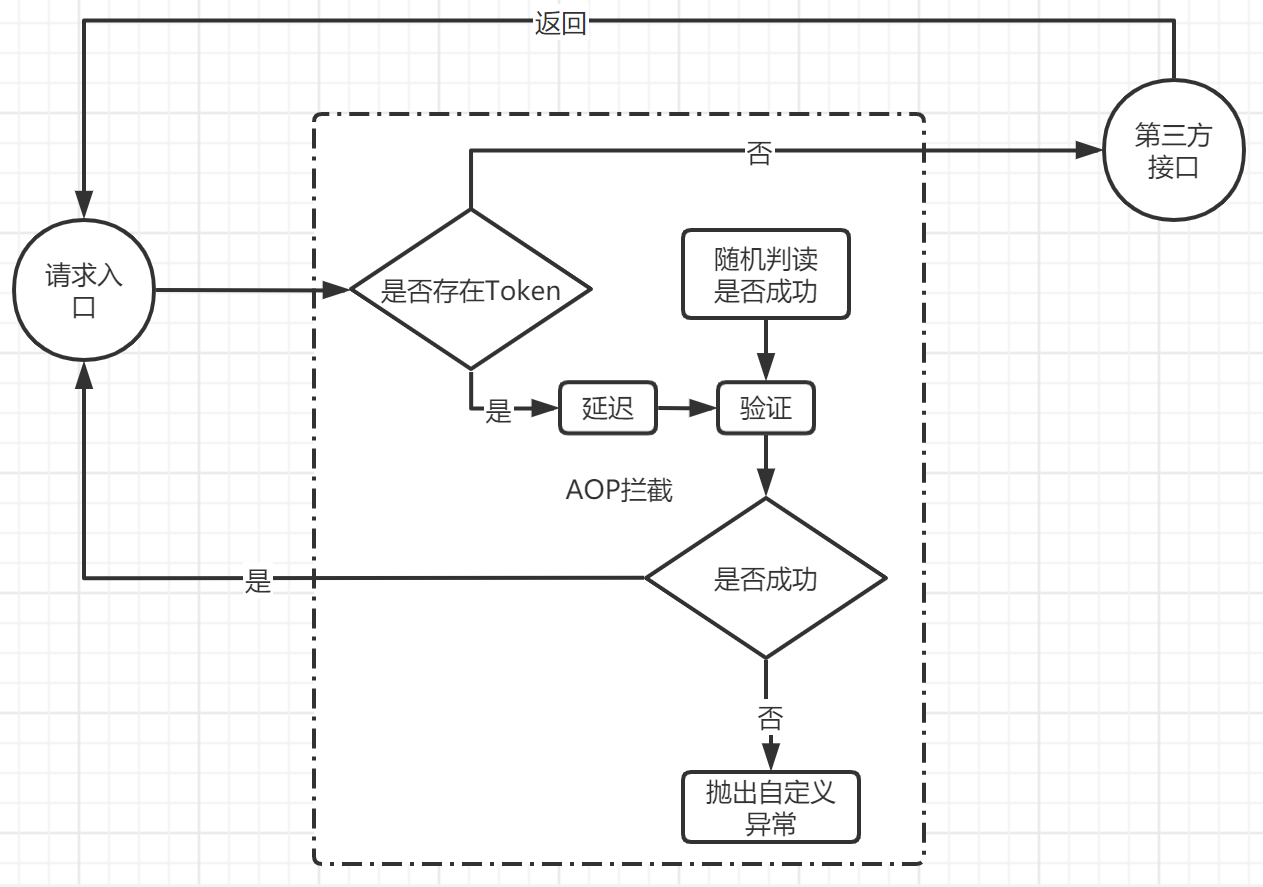
6.3.1.1 核心類實作
@Aspect
public class WormholeMockSection {
/**
* 切點 攔截@WormholeMock的注解
*/
@Pointcut("@annotation(com.heima.wormhole.component.mock.annotation.WormholeMock)")
public void pointCut() {
}
/**
* 環繞通知
*
* @param point
* @return
* @throws Throwable
*/
@Around("pointCut()")
public Object section(ProceedingJoinPoint point) throws Throwable {
WormholeContext wormholeContext = WormholeContextHolder.getContext();
Object[] parameter = point.getArgs();
//如果沒有wormholeContext 就執行正常方法
if (null == wormholeContext) {
return point.proceed(parameter);
}
//如果存在就執行MOCK方法
WormholeMock wormholeMock = WormholeMockUtils.getMethodAnnotation(point, WormholeMock.class);
if (null != wormholeMock) {
//獲取到 Mock 回呼類
WormholeMockCallback wormholeMockCallback = WormholeMockUtils.getWormholeMockCallback(wormholeMock);
if (null != wormholeMockCallback) {
return wormholeMockCallback.handelMockData(parameter);
}
}
return null;
}
}
6.3.1.2 使用方式
在具體方法上面加上注解就可以使用了
@Override
//加入注解進行MOCK測驗攔截 設定最大耗時
@WormholeMock(maxDelayTime = 10, minDelayTime = 2)
public boolean send(NotifyVO notifyVO) {
logger.info("開始發送短信通知.....");
try {
//模擬發送短信耗時
Thread.sleep(5);
} catch (InterruptedException e) {
}
return true;
}
6.4 零侵入方案
如果開發的中間件需要各個微服務大量改造,對開發人員來說就是一個災難,所以這里采用零侵入的springboot starter 來解決
6.4.1 自動裝配
使用微服務得
@Conditional來完成配置得自動裝配,這里用MVC得配置來演示自動裝配,其他得都是類似這樣可以最大限度的優化代碼并提高很高的可擴展性,
/**
* MVC 自動裝配
*/
@Configuration
//當DispatcherServlet存在時該配置類才會被執行到
@ConditionalOnClass(org.springframework.web.servlet.DispatcherServlet.class)
public class WormholeMVCAutoConfiguration {
@ConditionalOnClass
@Bean
public WormholeMVCConfiguration wormholeMVCConfiguration() {
return new WormholeMVCConfiguration();
}
}
6.4.1.1 Conditional 簡介
@Conditional表示僅當所有指定條件都匹配時,組件才有資格注冊 , 該@Conditional注釋可以在以下任一方式使用:
- 作為任何@Bean方法的方法級注釋
- 作為任何類的直接或間接注釋的型別級別注釋 @Component,包括@Configuration類
- 作為元注釋,目的是組成自定義構造型注釋
6.4.1.2 Conditional派生注解
@Conditional派生了很多注解,下面給個表格列舉一下派生注解的用法
| @Conditional派生注解 | 作用(都是判斷是否符合指定的條件) |
|---|---|
| @ConditionalOnJava | 系統的java版本是否符合要求 |
| @ConditionalOnBean | 有指定的Bean類 |
| @ConditionalOnMissingBean | 沒有指定的bean類 |
| @ConditionalOnExpression | 符合指定的SpEL運算式 |
| @ConditionalOnClass | 有指定的類 |
| @ConditionalOnMissingClass | 沒有指定的類 |
| @ConditionalOnSingleCandidate | 容器只有一個指定的bean,或者這個bean是首選bean |
| @ConditionalOnProperty | 指定的property屬性有指定的值 |
| @ConditionalOnResource | 路徑下存在指定的資源 |
| @ConditionalOnWebApplication | 系統環境是web環境 |
| @ConditionalOnNotWebApplication | 系統環境不是web環境 |
| @ConditionalOnjndi | JNDI存在指定的項 |
6.4.2 SpringBoot starter
? 和自動裝配一樣,Spring Boot Starter的目的也是簡化配置,而Spring Boot Starter解決的是依賴管理配置復雜的問題,有了它,當我需要構建一個Web應用程式時,不必再遍歷所有的依賴包,一個一個地添加到專案的依賴管理中,而是只需要一個配置spring-boot-starter-web,
6.4.2.1 使用規范
? 在 Spring Boot starter 開發規范中,專案中會有一個空的名為 xxx-spring-boot-starter 的專案,這個專案主要靠 pom.xml 將所有需要的依賴引入進來,同時專案還會有一個 xxx-spring-boot-autoconfigure 專案,這個專案主要寫帶 @Configuration 注解的配置類,在這個類或者類中帶 @Bean 的方法上,
6.4.2.2 專案使用
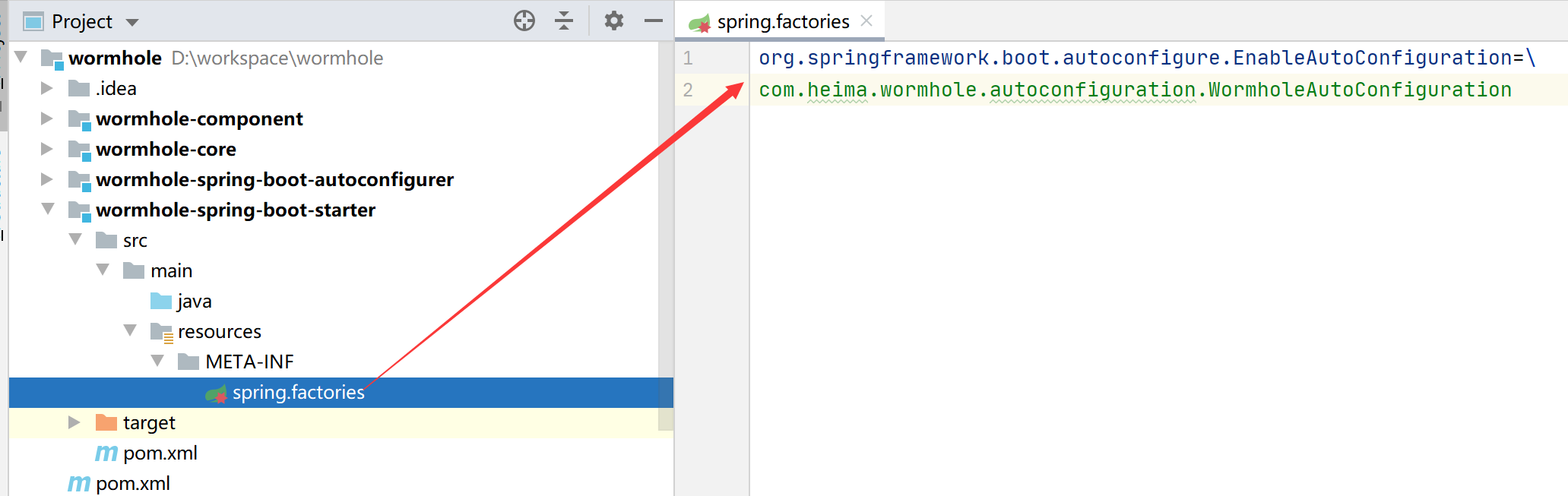
在 xxx-spring-boot-starter的專案下的resources檔案夾下面新建一個META-INF檔案,并在下面創建spring.factories檔案,將我們的自動配置類配置進去
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.heima.wormhole.autoconfiguration.WormholeAutoConfiguration
6.5 服務監控方案
6.5.1 skywalking簡介
? Skywalking 是一個APM系統,即應用性能監控系統,為微服務架構和云原生架構系統設計,它通過探針自動收集所需的指標,并進行分布式追蹤,通過這些呼叫鏈路以及指標,Skywalking APM會感知應用間關系和服務間關系,并進行相應的指標統計,目前支持鏈路追蹤和監控應用組件如下,基本涵蓋主流框架和容器,如國產PRC Dubbo和motan等,國際化的spring boot,spring cloud都支持了
? SkyWalking是分布式系統的應用程式性能監視工具,專為微服務、云原生架構和基于容器(Docker、K8S、Mesos)架構而設計
? SkyWalking是觀察性分析平臺和應用性能管理系統,提供分布式追蹤、服務網格遙測分析、度量聚合和可視化一體化解決方案
6.5.1.1 SkyWalking組件
-
Skywalking Agent: 采集
tracing(呼叫鏈資料)和metric(指標)資訊并上報,上報通過HTTP或者gRPC方式發送資料到Skywalking Collector -
Skywalking Collector : 鏈路資料收集器,對agent傳過來的
tracing和metric資料進行整合分析通過Analysis Core模塊處理并落入相關的資料存盤中,同時會通過Query Core模塊進行二次統計和監控告警 -
Storage: Skywalking的存盤,支持以
ElasticSearch、Mysql、TiDB、H2等作為存盤介質進行資料存盤 -
UI: Web可視化平臺,用來展示落地的資料,目前官方采納了RocketBot作為SkyWalking的主UI
6.5.2 配置SkyWalking
6.5.2.1 下載SkyWalking
? 下載SkyWalking的壓縮包,解壓后將壓縮包里面的agent檔案夾放進本地磁盤,探針包含整個目錄,請不要改變目錄結構,
6.5.2.2 Agent配置
? 通過了解配置,可以對一個組件功能有一個大致的了解,解壓開skywalking的壓縮包,在agent/config檔案夾中可以看到agent的組態檔,從skywalking支持環境變數配置加載,在啟動的時候優先讀取環境變數中的相關配置,
| skywalking配置名稱 | 描述 |
|---|---|
| agent.namespace | 跨行程鏈路中的header,不同的namespace會導致跨行程的鏈路中斷 |
| agent.service_name | 一個服務(專案)的唯一標識,這個欄位決定了在sw的UI上的關于service的展示名稱 |
| agent.sample_n_per_3_secs | 客戶端采樣率,0或者負數標識禁用,默認-1 |
| agent.authentication | 與collector進行通信的安全認證,需要同collector中配置相同 |
| agent.ignore_suffix | 忽略特定請求后綴的trace |
| collecttor.backend_service | agent需要同collector進行資料傳輸的IP和埠 |
| logging.level | agent記錄日志級別 |
skywalking agent使用javaagent無侵入式的配合collector實作對分布式系統的追蹤和相關資料的背景關系傳遞,
6.5.2.3 配置探針
配置SpringBoot啟動引數,需要填寫如下的運行引數,代碼放在后面,需要的自己粘貼,
-javaagent:D:/data/skywalking/agent/skywalking-agent.jar
-Dskywalking.agent.service_name=storage-server
-Dskywalking.collector.backend_service=172.18.0.50:11800
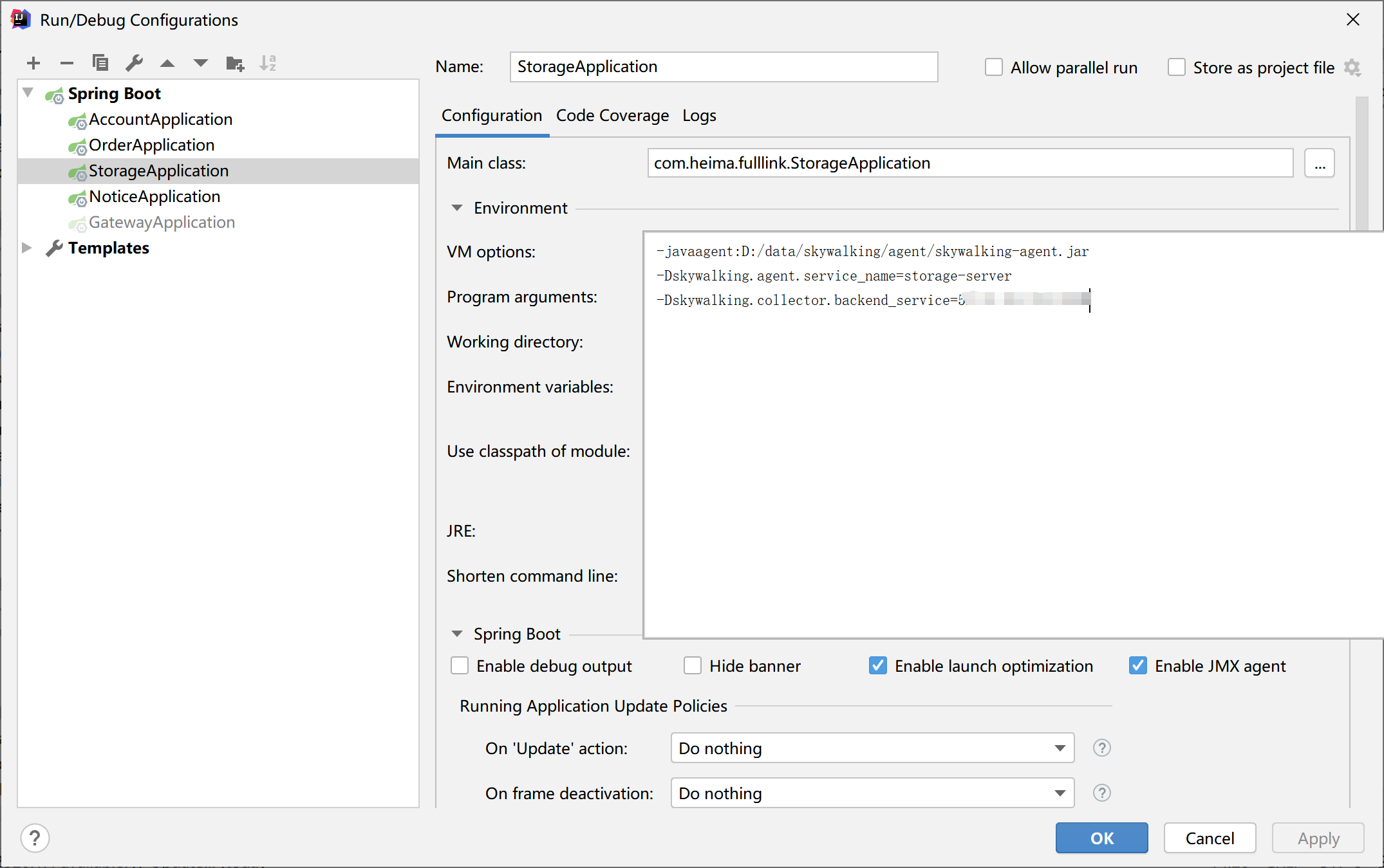
- javaagent:復制的agent目錄下探針的jar包路徑
- skywalking.agent.service_name:需要在skywalking顯示的服務名稱
- skywalking.collector.backend_service:skywalking服務端地址默認是11800
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/508066.html
標籤:其他
上一篇:MyBatis(十):日志