一、爬取目標
您好,我是@馬哥python說,今天繼續分享爬蟲案例,
爬取網站:雪球網的滬深股市行情資料
具體選單:雪球網 > 行情中心 > 滬深股市 > 滬深一覽
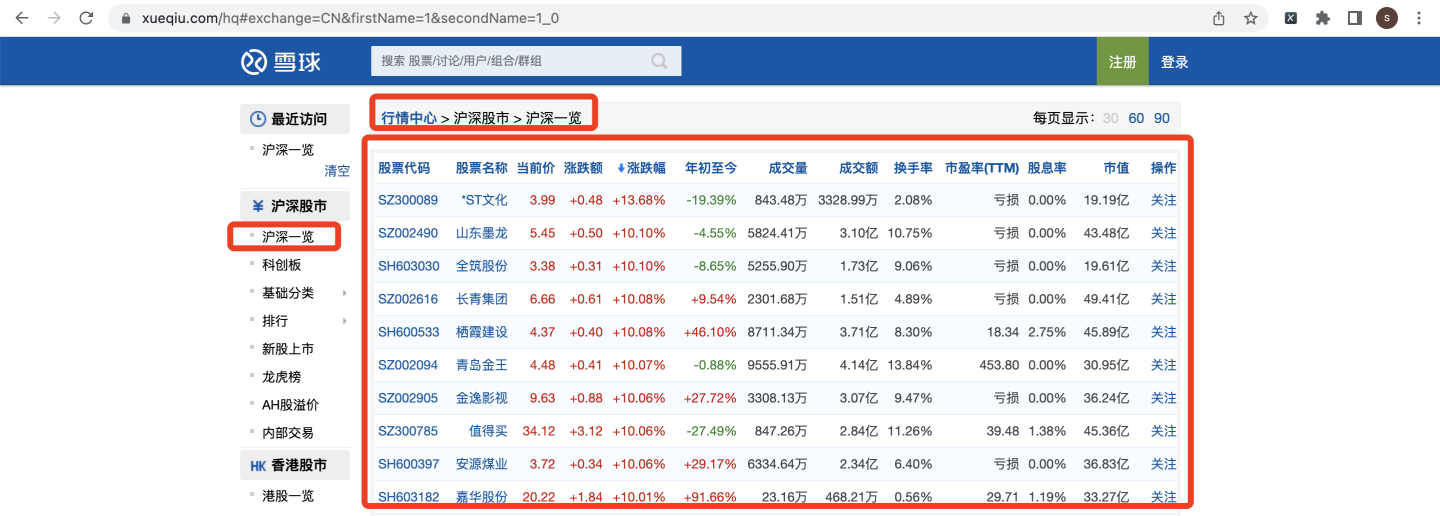
爬取欄位,含:
股票代碼,股票名稱,當前價,漲跌額,漲跌幅,年初至今,成交量,成交額,換手率,市盈率,股息率,市值,
二、分析網頁
在網頁中,我們注意到,默認每頁顯示30條:
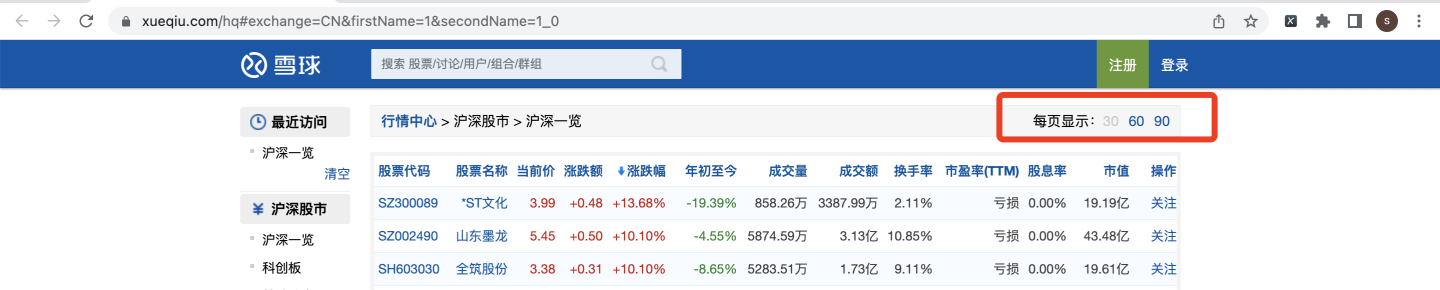
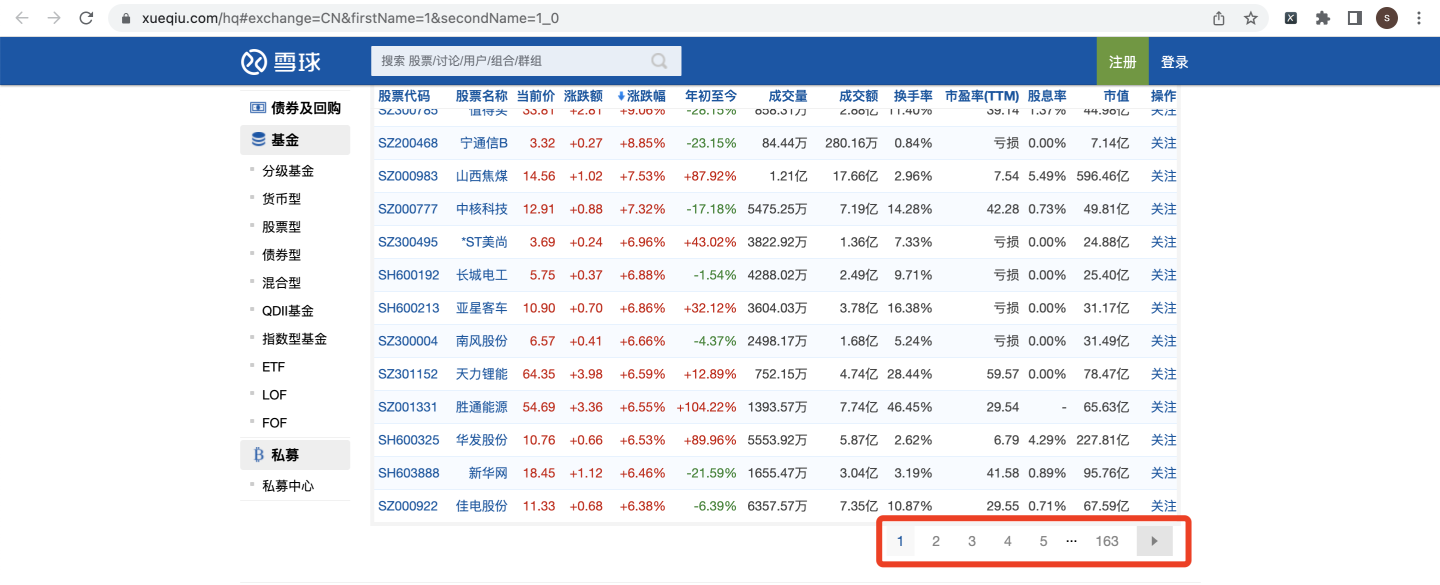
一共163頁:
如果切換到每頁90條,總頁數就會變成55頁:
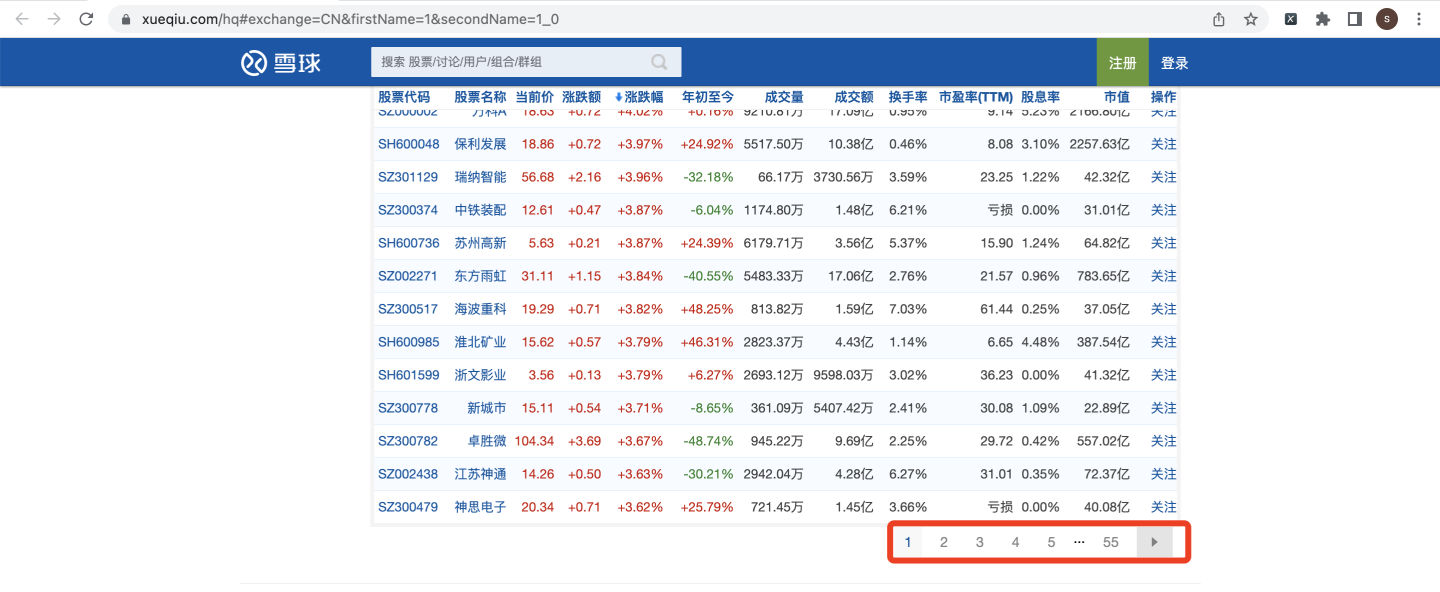
基于盡量少的向頁面發送請求,防止反爬的考慮,選擇每頁90條,
下面,開始分析網頁介面,
按F12,打開chrome瀏覽器的開發者模式,重新重繪網頁,并翻頁3次,發現3個網頁請求:
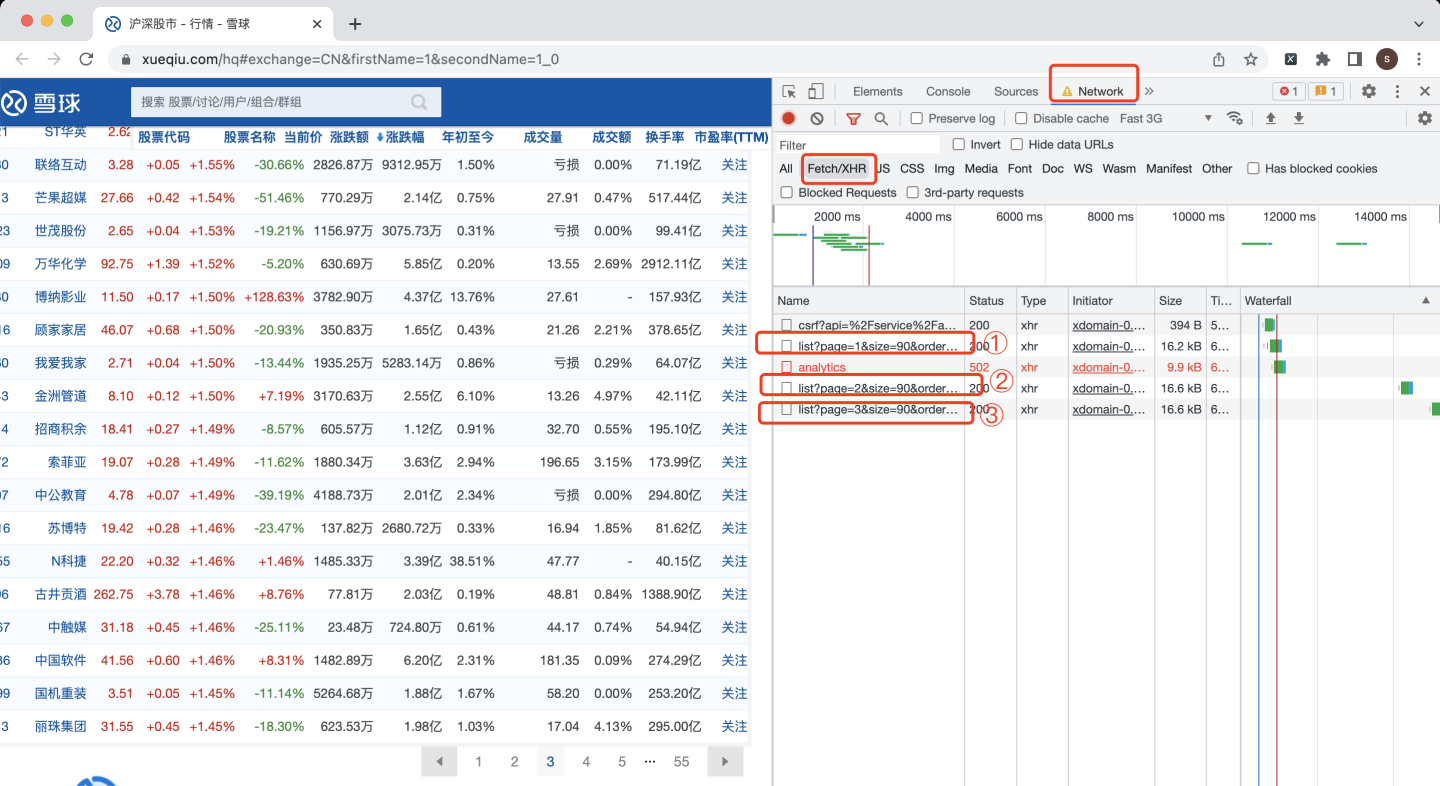
由此推測,這就是目標股票資料,
為了驗證此猜測,打開預覽頁面,展開json資料,找到第0只股票:
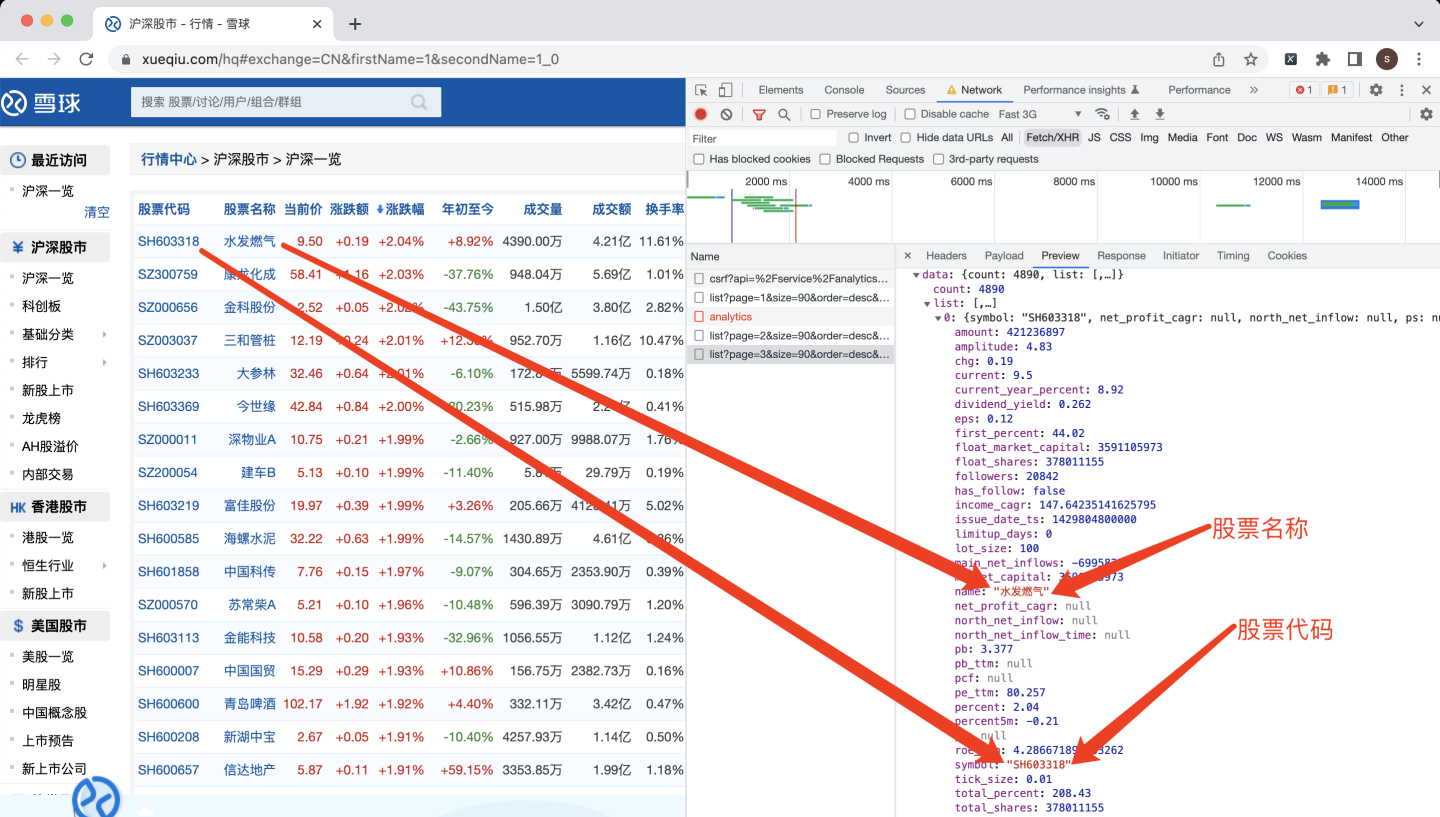
經過和頁面對比,發現資料一致,
下面繼續看網頁請求引數:
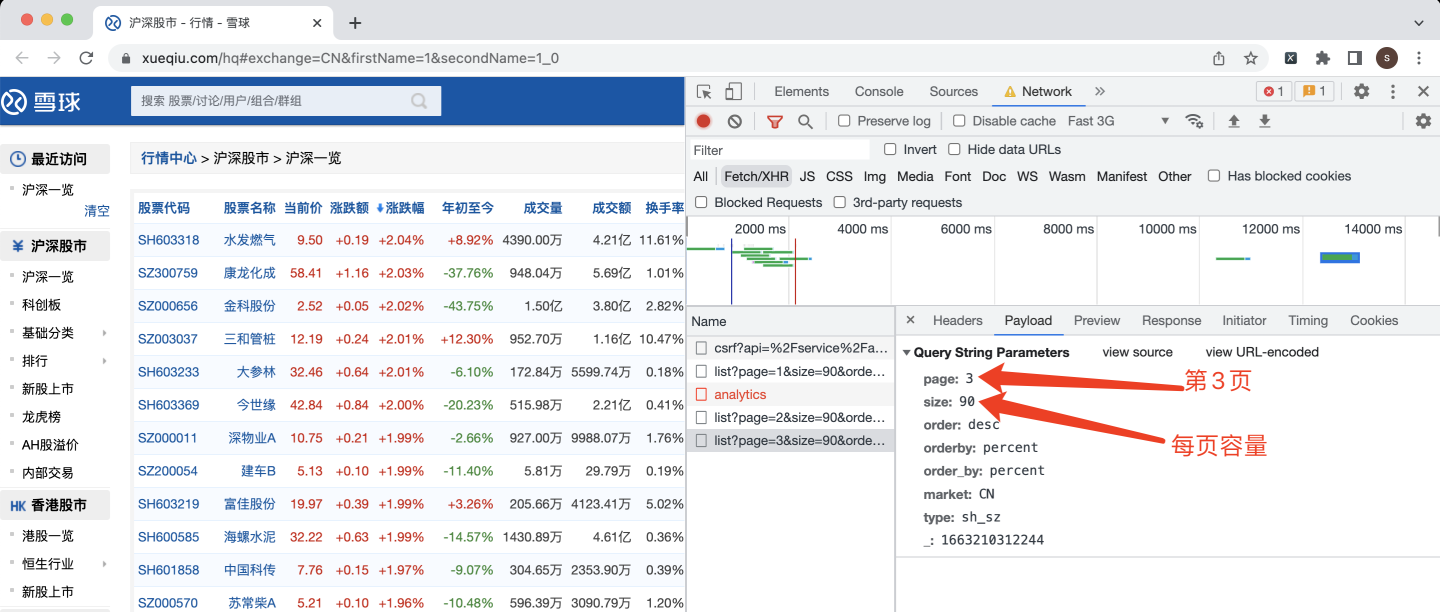
這里每頁容量是90條資料,大膽猜測一下,如果每頁容量指定為5000,只爬取1頁,是不是更省事兒,
雖然大膽猜測,但要小心求證,畢竟一名合格的介面開發者不會這么做,
一般情況下,如果發現用戶請求大于每頁容量,會回傳一個exceed max size或者invalid request之類的error給用戶,但我們不妨試試,,
下面開始開發爬蟲代碼:
三、爬蟲代碼
首先,定義一個請求頭,直接從開發者模式里copy過來:
# 定義字串請求頭
header1 = """
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7
cache-control: no-cache
Connection: keep-alive
Cookie: 換成自己的
Host: xueqiu.com
Referer: https://xueqiu.com/hq
sec-ch-ua: "Google Chrome";v="105", "Not)A;Brand";v="8", "Chromium";v="105"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "macOS"
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
"""
通過copy_headers_dict轉換成dict格式:
# 轉換成dict格式請求頭
header2 = copy_headers_dict(header1)
如此方便!
下面開始發送請求,如上所講,大膽嘗試請求第1頁,頁容量5000條:
# 請求地址
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=1&size=5000&order=desc&orderby=percent&order_by=percent&market=CN&type=sh_sz&_=1663203107799"
# 發送請求
resp = requests.get(url, headers=header2)
查看回應碼及回應資料,真的請求到了!
估計過不了多久,雪球網的程式員小哥哥該被領導請去喝茶了~
下面開始決議json資料:
# 決議json資料
json_data = https://www.cnblogs.com/mashukui/p/resp.json()
data_list = json_data['data']['list']
先定義一些空串列用于存盤資料:
# 定義空串列用于存盤資料
symbol_list = [] # 股票代碼
name_list = [] # 股票名稱
current_list = [] # 當前價
chg_list = [] # 漲跌額
percent_list = [] # 漲跌幅
current_year_percent_list = [] # 年初至今
volume_list = [] # 成交量
amount_list = [] # 成交額
turnover_rate_list = [] # 換手率
pe_ttm_list = [] # 市盈率
dividend_yield_list = [] # 股息率
market_capital_list = [] # 市值
其實,介面里還有更多欄位,這里我只爬取了網頁上有的欄位,
把決議好的欄位資料append到空串列中,以股票代碼和股票名稱為例:
for data in data_list:
symbol_list.append(data['symbol'])
name_list.append(data['name'])
print('已爬取第{}只股票,股票代碼:{},股票名稱:{}'.format(count, data['symbol'], data['name']))
其他欄位同理,不再演示,
最后,把串列資料存入DataFrame資料中:
df = pd.DataFrame(
{
'股票代碼': symbol_list,
'股票名稱': name_list,
'當前價': current_list,
'漲跌額': chg_list,
'漲跌幅': percent_list,
'年初至今': current_year_percent_list,
'成交量': volume_list,
'成交額': amount_list,
'換手率': turnover_rate_list,
'市盈率': pe_ttm_list,
'股息率': dividend_yield_list,
'市值': market_capital_list,
}
)
最后,用to_csv把最終資料落地成csv檔案,大功告成!
四、同步視頻
演示視頻:
https://www.zhihu.com/zvideo/1553775083570802688
我是 馬哥python說,感謝閱讀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/509081.html
標籤:Python