目錄
- 一、爬蟲是什么
- 二、爬蟲的基本流程
- 三、請求與回應
- 四、總結
一、爬蟲是什么
1、瀏覽器獲取資料的方式
瀏覽器提交請求->下載網頁代碼->決議/渲染成頁面
2、爬蟲獲取資料的方式
模擬瀏覽器發送請求->下載網頁代碼->只提取有用的資料->存放于資料庫或檔案中
二、爬蟲的基本流程
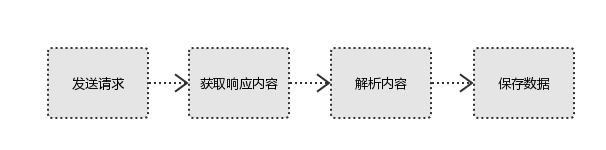
1、發起請求
模擬瀏覽器發送請求(requests,selenium),Request包含請求地址(瀏覽器除錯/抓包工具 分析請求地址),請求頭,請求體,請求方法
2、拿到回應
如果服務器能正常回應,則會得到一個Response
Response包含:html,json,圖片,視頻等
3、決議內容
決議html資料:正則運算式,第三方決議庫如Beautifulsoup,pyquery等(bs4或xpath決議)
決議json資料:json模塊
決議二進制資料:以b的方式寫入檔案
加密的未知格式:需要解密
4、保存資料
檔案或資料庫:redis, MySQL, Mongodb(json格式資料)
# 性能更高的爬蟲
利用多執行緒,多行程,協程,scrapy框架處理了性能
只針對與python語言的cpython解釋器(GIL:同一時刻只能由一個執行緒在執行)
-io密集型:用執行緒
-計算密集型:用行程
三、請求與回應
# http協議:http://www.cnblogs.com/linhaifeng/articles/8243379.html
http://www.cnblogs.com/linhaifeng/p/6266327.html
# Request
1、請求方式:
常用的請求方式:GET,POST
其他請求方式:HEAD,PUT,DELETE,OPTHONS
post與get請求最終都會拼接成這種形式:k1=xxx&k2=yyy&k3=zzz
post請求的引數放在請求體內,可用瀏覽器查看,存放于form data內;get請求的引數直接放在url后
2、請求url
url全稱統一資源定位符,如一個網頁檔案,一張圖片,一個視頻等都可以用url唯一來確定
url編碼:https://www.baidu.com/s?wd=圖片,“圖片”會被編碼
解決中文引數編碼問題:
from urllib.parse import quote
quote("圖片", "utf-8")
網頁的加載程序是:
加載一個網頁,通常都是先加載document檔案,
在決議document檔案的時候,遇到鏈接,則針對超鏈接發起下載圖片的請求
3、請求頭
User-agent:請求頭中如果沒有user-agent客戶端型別,服務端可能將你當做一個非法用戶
referer:大型網站通常都會根據該引數判斷請求的來源,也用做圖片防盜鏈
cookie: 用來保存登錄資訊
Connection: Keep-Alive 瀏覽器1.1版本后,多次請求用一個socket鏈接,不然每次請求都要三次握手、四次揮手,消耗服務器性能
自定制欄位
4、請求體
如果是get方式,請求體沒有內容
如果是post方式,編碼格式:json,urlencoded,formdata
ps:
1、登錄視窗,檔案上傳等,資訊都會被附加到請求體內
2、登錄,輸入錯誤的用戶名密碼,然后提交,就可以看到post(分析url,formdata),正確登錄后頁面通常會跳轉,無法捕捉到post
------------------------------------------------------------
# Rsponse
回應首行(狀態碼),回應頭:(cookie,回應的編碼格式), 回應體(html格式,前后端分離回傳json格式,還需要js把資料渲染到頁面)
preview就是網頁源代碼,最主要的部分,包含了請求資源的內容,如網頁html、圖片、二進制資料等
四、總結
1、總結爬蟲流程:
爬取--->決議--->存盤
2、爬蟲所需工具:
請求庫:requests,selenium
決議庫:正則,beautifulsoup,pyquery
存盤庫:檔案,MySQL,Mongodb,Redis
3、爬蟲常用框架:
scrapy
補充:爬蟲協議(txt,上面寫了哪些路徑允許你爬還是不允許你爬)
www.baidu.com/robots.txt
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/509411.html
標籤:Python