一、Scrapy 介紹
Scrapy是一個Python撰寫的開源和協作的框架,起初是用于網路頁面抓取所設計的,使用它可以快速、簡單、可擴展的方式從網站中提取所需的資料,
Scrapy也是通用的網路爬蟲框架,爬蟲界的django(設計原則很像),可用于資料挖掘、監測和自動化測驗、也可以應用在獲取api所回傳資料,
Scrapy是基于twisted框架開發而來,twisted是事件驅動python網路框架,因此scrapy使用的是非阻塞(異步)的代碼來實作并發,可以發一堆請求出去(異步,不用等待),誰先回來就處理誰(事件驅動,發生變化再處理),整體架構如下圖
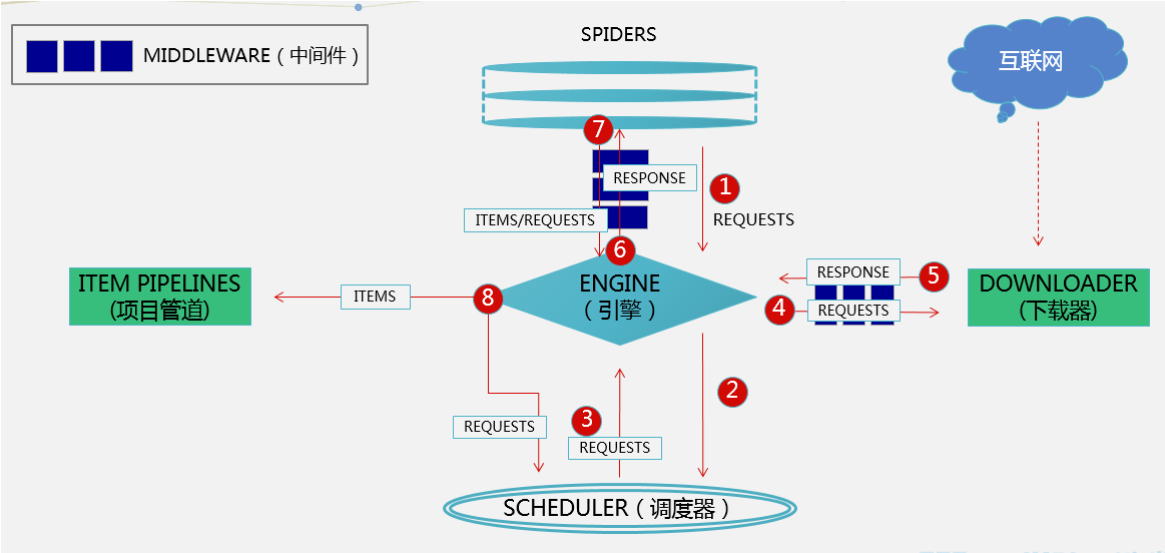
二、Scrapy 執行流程
五大組件
1、引擎(EGINE)
大總管,負責控制系統所有組件之間的資料流向,并在某些動作發生時觸發事件
2、調度器(SCHEDULER)
由它來決定下一個要抓取的網址是什么,同時去除重復的網址(scrapy框架用的集合)
# 通過配置來實作這一堆請求按深度優先(一條url爬到底),還是廣度優先(都先爬第一層,再往下爬)
# 先進先出(佇列)-->第一層請求從調度器出去,爬蟲決議后發出第二層請求,但要在佇列等先進的其他第一層請求出去,因此需要把第一層先爬完,這是廣度優先
# 后進先出(堆疊)-->出去的第一層經決議,發出第二層請求,進入調度器,它又先出去,一條線把它爬完,才能爬其他url請求,這是深度優先
3、下載器(DOWLOADER):用于下載網頁內容, 并將網頁內容回傳給EGINE,下載器是建立在twisted這個高效的異步模型上的
# 下載器前有一個下載中間件:用來攔截,這里就是包裝requests物件的地方(加頭、加代理)
4、爬蟲(SPIDERS):開發人員自定義的類,用來決議responses,并且提取items物件(決議出來的內容),或者發送新的請求request(決議出要繼續爬取的url)
5、專案管道(ITEM PIPLINES):在items被提取后負責處理它們,主要包括清洗(剔除掉不需要的資料)、驗證、持久化(比如存到資料庫、檔案、redis)等操作
兩大中間件
1、爬蟲中間件:位于EGINE和SPIDERS之間,主要處理SPIDERS的輸入(responses)和輸出(requests),還包括items物件,處理的東西過多就需要先判斷是哪個物件,用的很少
2、下載中間件:引擎和下載器之間,主要用來處理引擎傳到下載器的請求request, 從下載器傳到引擎的回應response;
可以處理加代理,加頭,集成selenium; 它用的不是requests模塊發請求,用的底層的urllib模塊,因此不能執行js;
框架的靈活就在于,你可以在下載中間件自己集成selenium,攔截后走你的下載方式,拿到資料再包裝成response物件回傳;
# 開發者只需要在固定的位置寫固定的代碼即可(寫的最多的spider)
三、安裝
#1 pip3 install scrapy(mac,linux可以直接下載)
#2 windows上(主要是tweited裝不上)
解決方法
1、pip3 install wheel #安裝后,便支持通過wheel檔案安裝軟體,wheel檔案官網:https://www.lfd.uci.edu/~gohlke/pythonlibs
2、pip3 install lxml
3、pip3 install pyopenssl
4、下載并安裝pywin32:它是windows上的exe執行檔案
https://sourceforge.net/projects/pywin32/files/pywin32/
5、下載twisted的wheel檔案:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
6、執行pip3 install 下載目錄\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
7、pip3 install scrapy
# 3 裝完后就有scrapy命令,命令視窗輸入
-D:\Python39\Scripts\scrapy.exe 此檔案用于創建專案(相當于安裝完django有個django-admin.exe)
四、scrapy 創建專案,創建爬蟲,運行爬蟲
1 創建scrapy專案
# pycharm不支持創建scrapy,只能用命令來創建專案
scrapy startproject 專案名
eg: scrapy startproject firstscrapy (cmd先cd到專案創建的目錄上再執行命令)
-專案創建后會生成firstscray檔案夾,用pycharm打開,類似django專案的目錄結構
2 創建爬蟲
# 先cd到創建的scrapy專案中, eg: 在firstscrapy專案路徑下執行命令
scrapy genspider 爬蟲名 爬取地址 # 相當于django創建app, python manage.py startapp app01
scrapy genspider chouti dig.chouti.com # 地址一開始寫錯了,后面可以修改
一執行就會在spider檔案夾下創建出一個py檔案,名字叫chouti,爬蟲就是一個個的py檔案
執行命令-->生成py檔案-->里面包含了初始代碼,因此直接拷貝py檔案改下里面的代碼(爬蟲名、地址),就相當于創建一個新的爬蟲,新的py檔案,django的app也可以這樣操作
3 運行爬蟲
方式一:通過命令啟動爬蟲
scrapy crawl chouti # 帶運行日志
scrapy crawl chouti --nolog # 不帶日志
方式二:支持右鍵執行爬蟲
# 在專案路徑下新建一個main.py,跟spiders檔案夾同一級
from scrapy.cmdline import execute
execute(['scrapy','crawl','chouti','--nolog']) --->右鍵運行main.py檔案
execute(['scrapy','crawl','baidu'])
# scrapy框架中,當一個爬蟲執行完畢后,會直接退出程式,而不是繼續執行后面代碼
# 用scrapy.cmdline.execute并不能同時運行多個爬蟲
注意:框架用了例外捕獲,如果不帶日志,有例外不會拋到控制臺
scrapy框架爬網頁會先去讀robots.txt協議,如果網站不讓爬,它就不爬了
可以在settings.py中,ROBOTSTXT_OBEY = True 改為False,不遵循它的協議
# 可以幾個爬蟲同時執行,它是異步框架,里面開的多執行緒
# 如果是同步,你放再多,也只能排隊一個個爬,前面的IO阻塞,后面也都等著
# 異步的優勢在于,前面的IO阻塞了,后面的不會等,繼續執行起走,誰的請求回來就處理誰
五、scrapy專案目錄
firstscrapy # 專案名字
firstscrapy # 包,存放專案py檔案
-spiders # 所有的爬蟲檔案放在里面
-baidu.py # 一個個的爬蟲(以后基本上都在這寫東西)
-chouti.py
-middlewares.py # 中間件(爬蟲,下載中間件都寫在這)
-pipelines.py # 持久化相關寫在這(處理items.py中類的物件)
-main.py # 自己建的py檔案,執行爬蟲
-items.py # 一個一個的類(類似django中的models)
-settings.py # 組態檔
scrapy.cfg # 上線相關
六、settings介紹
1 默認情況,scrapy會去遵循爬蟲協議
2 修改組態檔引數,強行爬取,不遵循協議 ROBOTSTXT_OBEY = False
3 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
4 LOG_LEVEL='ERROR' 日志等級配置為error,info資訊不列印,可以帶上日志運行
七、scrapy的資料決議(重點)
1 spiders爬蟲
爬蟲決議示例
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
# 爬蟲類中定義了start_urls, 配了地址
# 一啟動會呼叫Spider類中start_requests方法--->從start_urls回圈出url,包裝成requests物件回傳
# 進入調度后,走到下載器--->下載回來的responses物件回傳到爬蟲,呼叫parse方法進行決議
---------------------------------------
如果決議出一個網址,想繼續爬取這個網址,需要呼叫Requset類傳入url,生成requests物件并回傳,它會繼續走scrapy框架的流程
from scrapy.http import Request
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
return Request('http:www.chouti.com/article.html/')
# return Request('http:www.baidu.com/', dont_filter=True) 決議出來的百度的域不能爬,需要設定dont_filter
# 先爬dig.chouti.com,如果決議出http:www.chouti.com/article.html這個地址,要繼續爬
# 呼叫Request類,生成物件并回傳-->調度器-->下載器-->回傳response物件-->爬蟲,呼叫parse繼續決議
# allowed_domains設定了只能在某個域下爬,如果決議出來其他域就不能爬,dont_filter引數可以讓繼續爬其他域
2 決議方案一:自己用第三方決議,用bs4,lxml
bs4決議
from bs4 import BeautifulSoup
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['dig.chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response, *args, **kwargs):
print(response.text)
soup=BeautifulSoup(response.text, 'lxml')
div_list=soup.find_all(class_='link-title')
for div in div_list:
print(div.text)
3 決議方案二:scrapy框架自帶的決議
css或xpath決議
xpath決議:
# 取到所有link-title類的標簽物件
response.xpath('//a[contains(@class,"link-title")]')
# 取到所有link-title類的標簽的html(doc)檔案
response.xpath('//a[contains(@class,"link-title")]').extract()
# 取到所有link-title類的標簽的文本
response.xpath('//a[contains(@class,"link-title")]/text()').extract()
# 取到所有link-title類的標簽的href屬性
response.xpath('//a[contains(@class,"link-title")]/@href').extract()
css決議:
# 取到所有link-title類的標簽物件
response.css('.link-title')
# 取到所有link-title類的標簽的html(doc)檔案
response.css('.link-title').extract()
# 取到所有link-title類的標簽的文本
response.css('.link-title::text').extract()
# 取到所有link-title類的標簽的href屬性
response.css('.link-title::attr(href)').extract()
# extract()取出的內容放在串列里,即使取一個也放在串列,extract_first()取串列的第一個元素
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/509494.html
標籤:其他
上一篇:創建一個Django專案總結