冒泡排序
優點:寫起來簡單
缺點:運算量過大每兩個之間就要比較一次
冒泡排序在一組需要排序的陣列中,對兩兩資料順序與要求順序相反時,交換資料,使大的資料往后移,每趟排序將最大的數放在最后的位置上
如下圖:
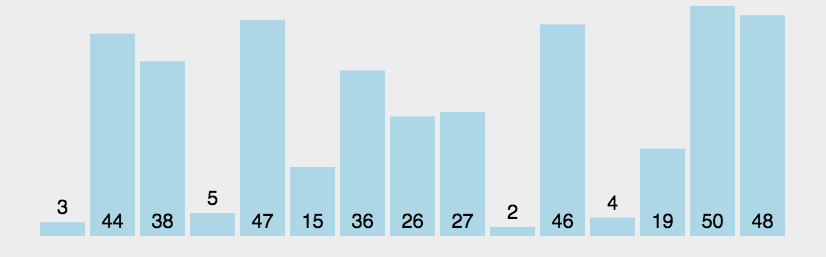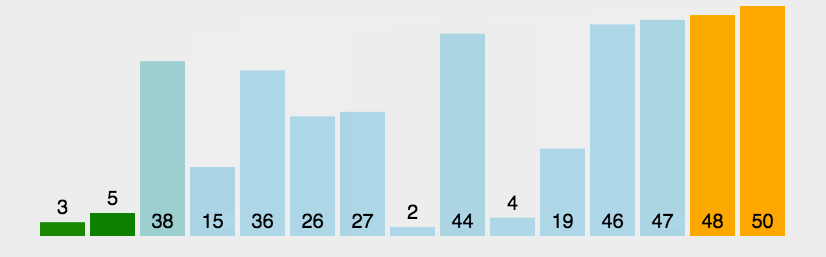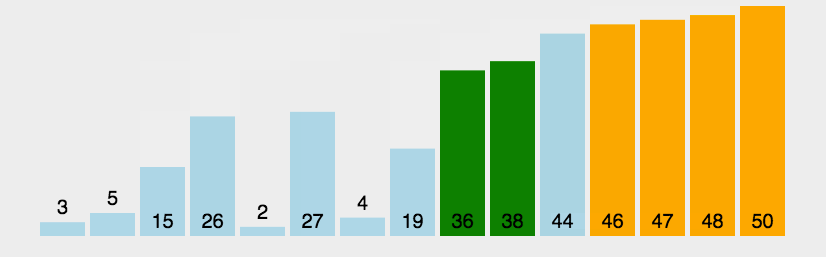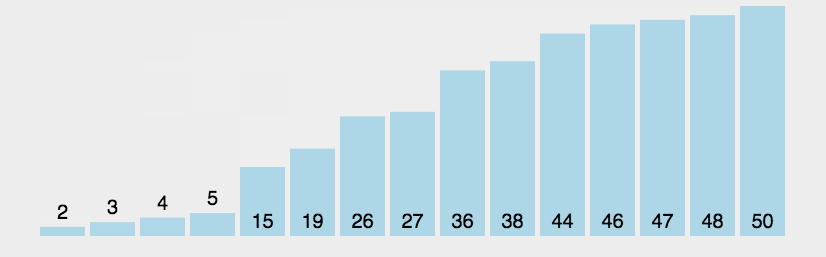
#include<stdio.h>
#define ARR_LEN 255 /*陣列長度上限*/
void bubble_Sort(int *arr, int len)
{
int i, j,temp;
for (i = 0; i < len - 1;i++) /* 外回圈為排序趟數,len個數進行len-1趟 */
{
for(j = 0; j < len-1-i; j++) /* 內回圈為每趟比較的次數,第i趟比較len-i次 */
{
if (arr[j] > arr[j + 1]) /* 相鄰元素比較,若逆序則交換(升序為左大于右,降序反之)*/
{
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main()
{
int len = 0;
int arr[ARR_LEN] = {0};
printf("please input arr len:");
scanf("%d",&len);
printf("please input arr member......\n");
for(int j = 0;j < len;j++)
{
scanf("%d",&arr[j]);
}
puts("");
printf("sort after is ......\n");
bubble_Sort(arr,len);
for(int j = 0;j < len;j++)
{
printf("%d ",arr[j]);
}
putchar('\n');
return 0;
}
如上是一種最簡單的實作方式,需要注意的可能是i, j的邊界問題,這種方式固定回圈次數,肯定可以解決各種情況,不過演算法的目的是為了提升效率,根據冒泡排序的程序圖可以看出這個演算法至少可以從兩點進行優化:
對于外層回圈,如果當前序列已經有序,即不再進行交換,應該不再進行接下來的回圈直接跳出,
對于內層回圈后面最大值已經有序的情況下應該不再進行回圈,
優化代碼實作:
#include <stdio.h>
#define ARR_LEN 255 /*陣列長度上限*/
void bubble_Sort(int *arr, int len)
{
int i, flag, temp;
do
{
flag = 0;
for (i = 0; i < len - 1; i++)
{
if (arr[i] > arr[i + 1])
{
temp = arr[i];
arr[i] = arr[i + 1];
arr[i + 1] = temp;
flag = i + 1;
}
}
len = flag;
}while (flag);
}
int main()
{
int len = 0;
int arr[ARR_LEN] = {0};
printf("please input arr len:");
scanf("%d", &len);
printf("please input arr member......\n");
for (int j = 0; j < len; j++)
{
scanf("%d", &arr[j]);
}
puts("");
printf("sort after is ......\n");
bubble_Sort(arr, len);
for (int j = 0; j < len; j++)
{
printf("%d ", arr[j]);
}
putchar('\n');
return 0;
}
如上,當nflag為0時,說明本次回圈沒有發生交換,序列已經有序不用再回圈,如果nflag>0則記錄了最后一次發生交換的位置,該位置以后的序列都是有序的,回圈不再往后進行,
選擇排序-簡單選擇排序
這種方法其實和冒泡的差別不大,只是減少了交換的次數,對冒泡進行了優化,
選擇排序是最簡單的一種基于O(n2)時間復雜度的排序演算法,基本思想是從i=0位置開始到i=n-1每次通過內回圈找出i位置到n-1位置的最小(大)值,
void selectSort(int arr[], int n)
{
int i, j , minValue, tmp;
for(i = 0; i < n-1; i++)
{
minValue = https://www.cnblogs.com/wren/p/i;
for(j = i + 1; j < n; j++)
{
if(arr[minValue] > arr[j])
{
minValue = j;
}
}
if(minValue != i)
{
tmp = arr[i];
arr[i] = arr[minValue];
arr[minValue] = tmp;
}
}
}
void printArray(int arr[], int n)
{
int i;
for(i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void main()
{
int arr[10] = {2,5,6,4,3,7,9,8,1,0};
printArray(arr, 10);
selectSort(arr, 10);
printArray(arr, 10);
return;
}
#include <stdio.h>
void choose_sort(int *arr, int n);
void show(int *arr, int n);
int main()
{
int arr[10] = {10, 8, 3, 15, 18, 16, 11, 9, 7, 6};
/*選擇排序*/
choose_sort(arr, 10);
show(arr, 10);
return 0;
}
void choose_sort(int *arr, int n)
{
int i = 0;
int j = 0;
int index = 0;
int swap = 0;
for(i = 0; i < n; i++) {
index = i;
for(j = i; j <n; j++ ) {
if(arr[index] > arr[j]) {
index = j;
}
}
swap = arr[i];
arr[i] = arr[index];
arr[index] = swap;
}
}
void show(int *arr, int n)
{
int i = 0;
for(i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
如實作所示,簡單的選擇排序復雜度固定為O(n2),每次內回圈找出沒有排序數列中的最小值,然后跟當前資料進行交換,由于選擇排序通過查找最值的方式排序,回圈次數幾乎是固定的,一種優化方式是每次回圈同時查找最大值和最小值可以是回圈次數減少為(n/2),只是在回圈中添加了記錄最大值的操作,原理一樣,本文不再對該方法進行實作,
插入排序-簡單插入排序
優點:插入排序在陣列量較小,資料較為整齊時速度較快
缺點:不穩定,若是出現較小的數字在靠后的位置,則會增加運算的復雜性(所以出現了希爾(shell)排序
插入排序是將一個記錄插入到已經有序的序列中,得到一個新的元素加一的有序序列,實作上即將第一個元素看成一個有序的序列,從第二個元素開始逐個插入得到一個完整的有序序列,插入程序如下:
#include <stdio.h>
void insert_sort(int *arr, int num, int n);
int main()
{
int arr[10] = {1, 2, 4, 6, 8, 9, 12, 15, 19};
insert_sort(arr, 20, 9);
int i = 0;
for(i = 0; i < 10; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
void insert_sort(int *arr, int num, int n)
{
int i = 0;
int index = 0;
for(i = 0; i < n; i++) {
if(arr[i] > num) {
index = i;
break;
}
}
if(i == n) {
arr[i] = num;
}
else {
for(i = n; i >= index; i--) {
arr[i + 1] = arr[i];
}
arr[index] = num;
}
}
如上,前面提到選擇排序不管什么情況下都是固定為O(n2)的演算法,插入演算法雖然也是O(n2)的演算法,不過可以看出,在已經有序的情況下,插入可以直接跳出回圈,在極端情況下(完全有序)插入排序可以是O(n)的演算法,不過在實際完全亂序的測驗用例中,與本文中的選擇排序相比,相同序列的情況下發現插入排序運行的時間比選擇排序長,這是因為選擇排序每次外回圈只與選擇的最值進行交換,而插入排序則需要不停與相鄰元素交換知道合適的位置,交換的三次賦值操作同樣影響運行時間,因此下面對這一點進行優化:
優化后實作:
void insertSort_1(int arr[], int n)
{
int i, j, tmp, elem;
for(i = 1; i < n; i++)
{
elem = arr[i];
for(j = i; j > 0; j--)
{
if(elem < arr[j-1])
{
arr[j] = arr[j-1];
}
else
{
break;
}
}
arr[j] = elem;
}
return;
}
優化代碼將需要插入的值快取下來,將插入位置之后的元素向后移一位,將交換的三次賦值改為一次賦值,減少執行時間,
插入排序-希爾排序
按照一定的間隔進行插入排序(優化了插入排序)
希爾排序的基本思想是先取一個小于n的整數d1作為第一個增量,把全部元素分組,所有距離為d1的倍數的記錄放在同一個組中,先在各組內進行直接插入排序;然后,取第二個增量d2 < d1重復上述的分組和排序,直至所取的增量 =1( < …< d2 < d1),即所有記錄放在同一組中進行直接插入排序為止,希爾排序主要是根據插入排序的一下兩種性質對插入排序進行改進:
插入排序在對幾乎已經排好序的資料操作時,效率高,即可以達到線性排序的效率,
但插入排序一般來說是低效的,因為插入排序每次只能將資料移動一位!!!!
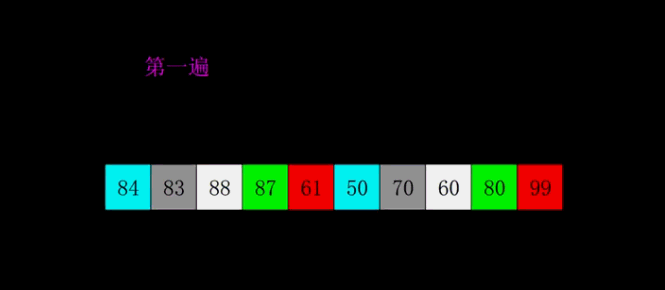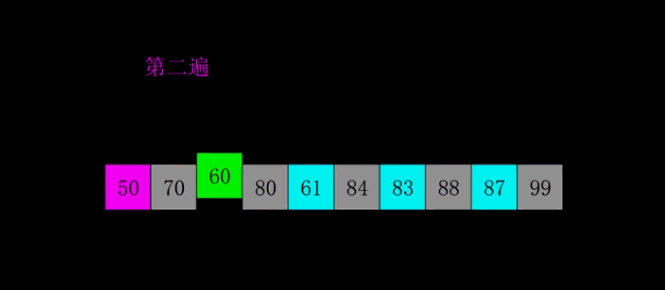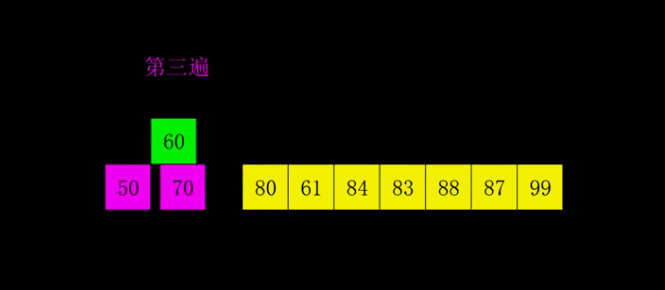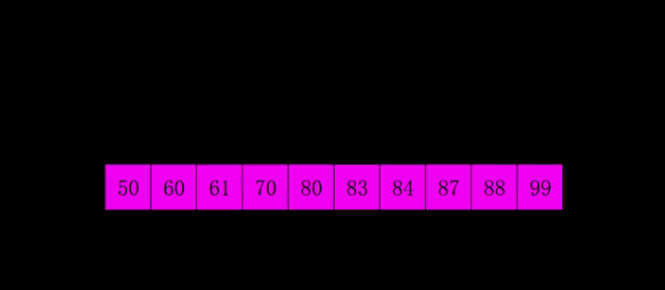
排序程序如下:
void shellSort(int arr[], int n)
{
int i, j, elem;
int k = n / 2;
while (k >= 1)
{
for (i = k; i < n; i++)
{
elem = arr[i];
for (j = i; j >= k; j -= k)
{
if (elem < arr[j - k])
{
arr[j] = arr[j - k];
}
else
{
break;
}
}
arr[j] = elem;
}
k = k / 2;
}
}
void printArray(int arr[], int n)
{
int i;
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return;
}
void main()
{
int arr[10] = {2, 5, 6, 4, 3, 7, 9, 8, 1, 0};
printArray(arr, 10);
shellSort(arr, 10);
printArray(arr, 10);
return;
}
歸并排序
歸并排序是基于歸并操作的一種排序演算法,歸并操作的原理就是將一組有序的子序列合并成一個完整的有序序列,即首先需要把一個序列分成多個有序的子序列,通過分解到每個子序列只有一個元素時,每個子序列都是有序的,在通過歸并各個子序列得到一個完整的序列,
合并程序:
把序列中每個單獨元素看作一個有序序列,每兩個單獨序列歸并為一個具有兩個元素的有序序列,每兩個有兩個元素的序列歸并為一個四個元素的序列依次類推,兩個序列歸并為一個序列的方式:因為兩個子序列都是有序的(假設由小到大),所有每個子序列最左邊都是序列中最小的值,整個序列最小值只需要比較兩個序列最左邊的值,所以歸并的程序不停取子序列最左邊值中的最小值放到新的序列中,兩個子序列值取完后就得到一個有序的完整序列,
歸并的演算法實作:
#include <stdio.h>
void merge(int arr[], int l, int mid, int r)
{
int len, i, pl, pr;
int *tmp = NULL;
len = r - l + 1;
tmp = (int *)malloc(len * sizeof(int)); //申請存放完整序列記憶體
memset(tmp, 0x0, len * sizeof(int));
pl = l;
pr = mid + 1;
i = 0;
while (pl <= mid && pr <= r) //兩個子序列都有值,比較最小值
{
if (arr[pl] < arr[pr])
{
tmp[i++] = arr[pl++];
}
else
{
tmp[i++] = arr[pr++];
}
}
while (pl <= mid) //左邊子序列還有值,直接拷貝到新序列中
{
tmp[i++] = arr[pl++];
}
while (pr <= r) //右邊子序列還有值
{
tmp[i++] = arr[pr++];
}
for (i = 0; i < len; i++)
{
arr[i + l] = tmp[i];
}
free(tmp);
return;
}
歸并的迭代演算法:
迭代演算法如上面所說,從單個元素開始合并,子序列長度不停增加直到得到一個長度為n的完整序列,
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void merge(int arr[], int l, int mid, int r)
{
int len, i, pl, pr;
int *tmp = NULL;
len = r - l + 1;
tmp = (int *)malloc(len * sizeof(int)); //申請存放完整序列記憶體
memset(tmp, 0x0, len * sizeof(int));
pl = l;
pr = mid + 1;
i = 0;
while (pl <= mid && pr <= r) //兩個子序列都有值,比較最小值
{
if (arr[pl] < arr[pr])
{
tmp[i++] = arr[pl++];
}
else
{
tmp[i++] = arr[pr++];
}
}
while (pl <= mid) //左邊子序列還有值,直接拷貝到新序列中
{
tmp[i++] = arr[pl++];
}
while (pr <= r) //右邊子序列還有值
{
tmp[i++] = arr[pr++];
}
for (i = 0; i < len; i++)
{
arr[i + l] = tmp[i];
}
free(tmp);
return;
}
int min(int x, int y)
{
return (x > y) ? y : x;
}
void mergeSortBu(int arr[], int n)
{
int sz, i, mid, l, r;
for (sz = 1; sz < n; sz += sz)
{
for (i = 0; i < n - sz; i += 2 * sz)
{
l = i;
r = i + sz + sz;
mid = i + sz - 1;
merge(arr, l, mid, min(r - 1, n - 1));
}
}
return;
}
void printArray(int arr[], int n)
{
int i;
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return;
}
void main()
{
int arr[10] = {2, 5, 6, 4, 3, 7, 9, 8, 1, 0};
printArray(arr, 10);
mergeSortBu(arr, 10);
printArray(arr, 10);
return;
}
另一種是通過遞回的方式,遞回方式可以理解為至頂向下的操作,即先將完整序列不停分解為子序列,然后在將子序列歸并為完整序列,
遞回演算法實作:
void mergeSort(int arr[], int l, int r)
{
if(l >= r)
{
return;
}
int mid = (l + r)/2;
mergeSort(arr, l, mid);
mergeSort(arr, mid+1, r);
merge(arr, l, mid, r);
return;
}
對于歸并演算法大家可以考慮到由于子序列都是有序的,所有如果左邊序列的最大值都比右邊序列的最小值小,那么整個序列就是有序的,不需要進行merge操作,因此可以在每次merge操作加一個if(arr[mid] > arr[mid+1])判斷進行優化,這種優化對于近乎有序的序列非常有效果,不過對于一般的情況會有一次判斷的額外開銷,可以根據具體情況處理,
快速排序
優點:運行速度較快
缺點:不穩定,在一些情況下可能會較慢(但肯定比冒泡快很多)
快速排序跟歸并排序類似屬于分治法的一種,基本思想是通過一趟排序將要排序的資料分割成獨立的兩部分,其中一部分的所有資料都比另外一部分的所有資料都要小,然后再按此方法對這兩部分資料分別進行快速排序,整個排序程序可以遞回進行,以此達到整個資料變成有序序列,
排序程序如圖:
因此,快速排序每次排序將一個序列分為兩部分,左邊部分都小于等于右邊部分,然后在遞回對左右兩部分進行快速排序直到每部分元素個數為1時則整個序列都是有序的,因此快速排序主要問題在怎樣將一個序列分成兩部分,其中一部分所有元素都小于另一部分,對于這一塊操作我們叫做partition,原理是先選取序列中的一個元素做參考量,比它小的都放在序列左邊,比它大的都放在序列右邊,
演算法實作 (快速排序-單路快排) :

如上:我們選取第一個元素v作為參考量及arr[l],定義j變數為兩部分分割哨兵,變數i從l+1開始遍歷每個變數,如果當前變數e > v則i++檢測下一個元素,如果當前變數e < v 則e與arr[j+1]交換,可以看到arr[j+1]由交換前大于v變成小于v arr[i]變成大于v,同時對i++,j++,始終保持:arr[l+1….j] < v, arr[j+1….i-1] > v
代碼實作:
#include <stdio.h>
void printArray(int arr[], int n)
{
int i;
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return;
}
void swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
return;
}
//arr[l+1...j] < arr[l], arr[j+1,..i)>arr[l]static int partition(int arr[], int l, int r)
{
int i, j;
i = l + 1;
j = l;
while (i <= r)
{
if (arr[i] > arr[l])
{
i++;
}
else
{
swap(&arr[j + 1], &arr[i]);
i++;
j++;
}
}
swap(&arr[l], &arr[j]);
return j;
}
static void _quickSort(int arr[], int l, int r)
{
int key;
if (l >= r)
{
return;
}
key = partition(arr, l, r);
_quickSort(arr, l, key - 1);
_quickSort(arr, key + 1, r);
}
void quickSort(int arr[], int n)
{
_quickSort(arr, 0, n - 1);
return;
}
void main()
{
int arr[10] = {1, 5, 9, 8, 7, 6, 3, 4, 0, 2};
printArray(arr, 10);
quickSort(arr, 10);
printArray(arr, 10);
}
因為有變數i從左到右依次遍歷序列元素,所有這種方式叫單路快排,不過細心的同學可以發現我們忽略了考慮e等于v的情況,這種快排方式一大缺點就是對于高重復率的序列即大量e等于v的情況會退化為O(n2)演算法,原因在大量e等于v的情況劃分情況會如下圖兩種情況:

解決這種問題的一另種方法: 快速排序-兩路快排:
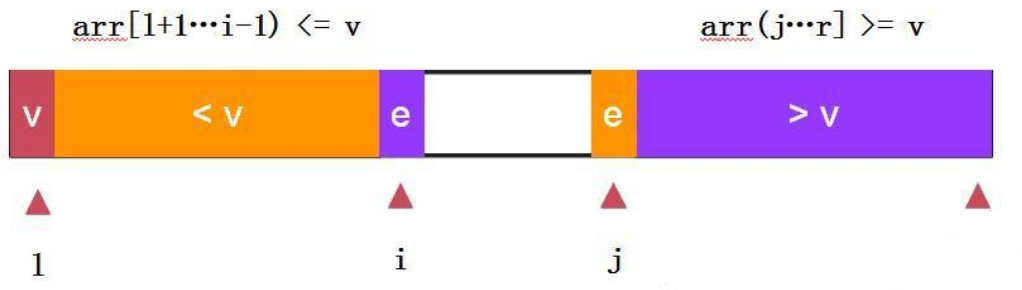
兩路快排通過i和j同時向中間遍歷元素,e==v的元素分布在左右兩個部分,不至于在多重復元素時劃分嚴重失衡,依舊去第一個元素arr[l]為參考量,始終保持arr[l+1….i) =arr[l]原則,
代碼實作:
//arr[l+1....i) <=arr[l], arr(j...r] >=arr[l]static int partition2(int arr[], int l, int r)
{
int i, j;
= l + 1;
j = r;
while (i <= j)
{
while (i <= j && arr[j] > arr[l]) /*注意arr[j] >arr[l] 不是arr[j] >= arr[l]*/
{
j--;
}
while (i <= j && arr[i] < arr[l])
{
i++;
}
if (i < j)
{
swap(&arr[i], &arr[j]);
i++;
j--;
}
}
swap(&arr[j], &arr[l]);
return j;
}
針對重復元素比較多的情況還有一種實作方式: 快速排序-三路快排:
三路快排是在兩路快排的基礎上對e==v的情況做單獨的處理,對于重復元素非常多的情況優勢很大:
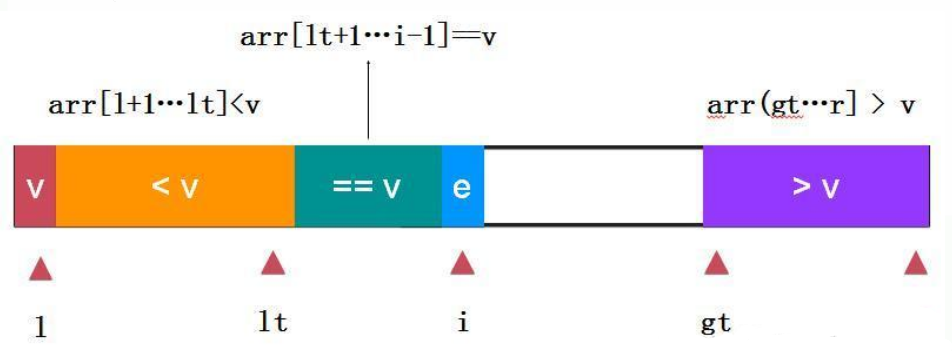
如上:取arr[l]為參考量,定義變數lt為小于v和等于v的分割點,變數i為遍歷指標,gt為大于v和未遍歷元素分割點,gt指向未遍歷元素,邊界條件跟個人定義有關本文始終保持arr[l+1…lt] < v,arr[lt+1….i-1],arr(gt…..r]>v的狀態,
代碼實作:
#include <stdio.h>
void printArray(int arr[], int n)
{
int i;
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return;
}
void swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
return;
}
static void _quickSort3(int arr[], int l, int r)
{
int i, lt, gt;
if (l >= r)
{
return;
}
i = l + 1;
lt = l;
gt = r;
while (i <= gt)
{
if (arr[i] < arr[l])
{
swap(&arr[lt + 1], &arr[i]);
lt++;
i++;
}
else if (arr[i] > arr[l])
{
swap(&arr[i], &arr[gt]);
gt--;
}
else
{
i++;
}
}
swap(&arr[l], &arr[gt]);
_quickSort3(arr, l, lt);
_quickSort3(arr, gt + 1, r);
return;
}
void quickSort(int arr[], int n)
{
_quickSort3(arr, 0, n - 1);
return;
}
void main()
{
int arr[10] = {1, 5, 9, 8, 7, 6, 3, 4, 0, 2};
printArray(arr, 10);
quickSort(arr, 10);
printArray(arr, 10);
}
三路快排在重復率比較高的情況下比前兩種有較大優勢,但就完全隨機情況略差于兩路快排,可以根據具體情況進行合理選擇,另外本文在選取參考值時為了方便一直選擇第一個元素為參考值,這種方式對于近乎有序的序列演算法會退化到O(n2),因此一般選取參考值可以隨機選擇參考值或者其他選擇參考值的方法然后再與arr[l]交換,依舊可以使用相同的演算法,
堆排序
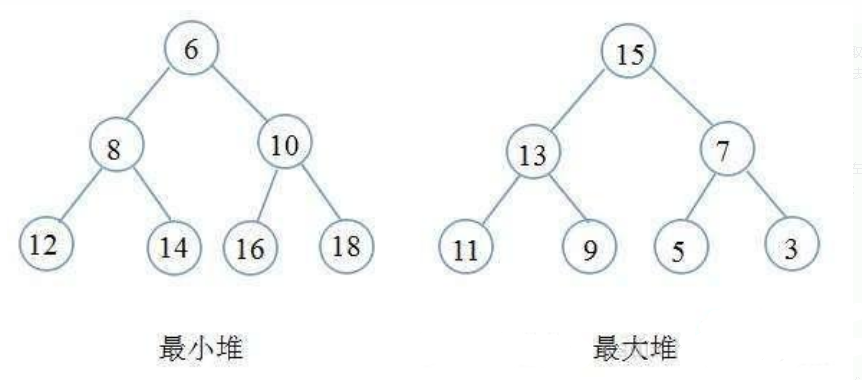
堆其實一種樹形結構,以二叉堆為例,是一顆完全二叉樹(即除最后一層外每個節點都有兩個子節點,且非滿的二叉樹葉節點都在最后一層的左邊位置),二叉樹滿足每個節點都大于等于他的子節點(大頂堆)或者每個節點都小于等于他的子節點(小頂堆),根據堆的定義可以得到堆滿足頂點一定是整個序列的最大值(大頂堆)或者最小值(小頂堆),
如下圖:
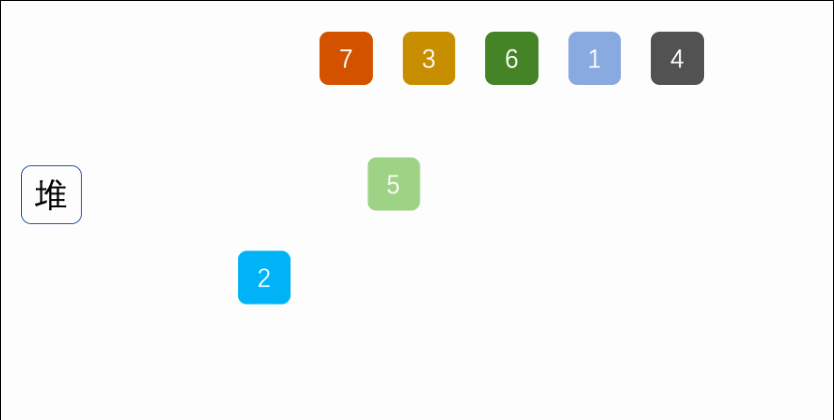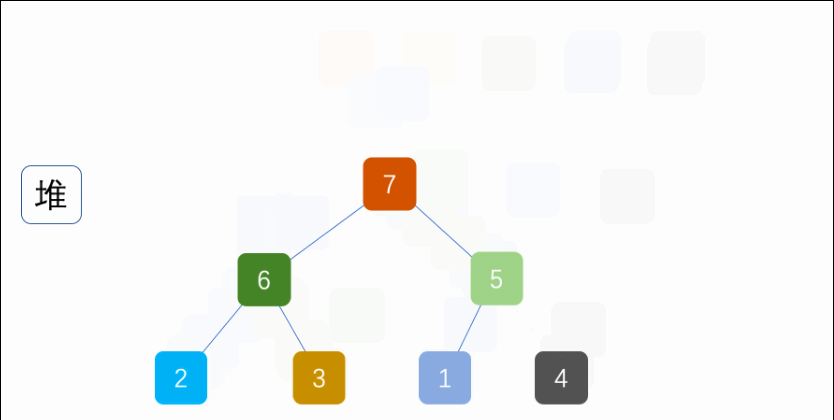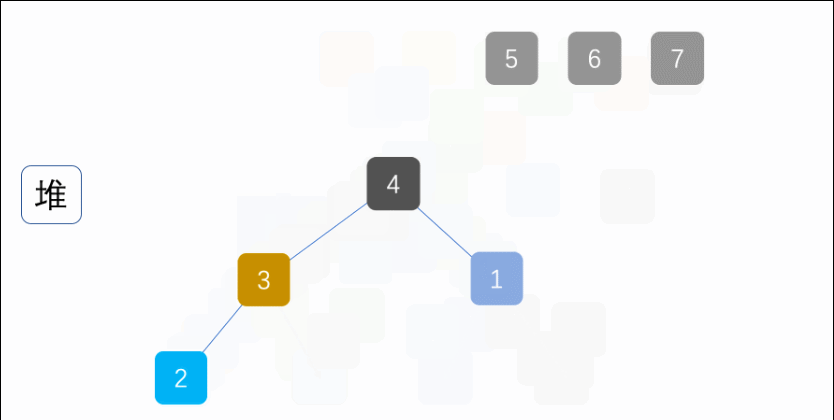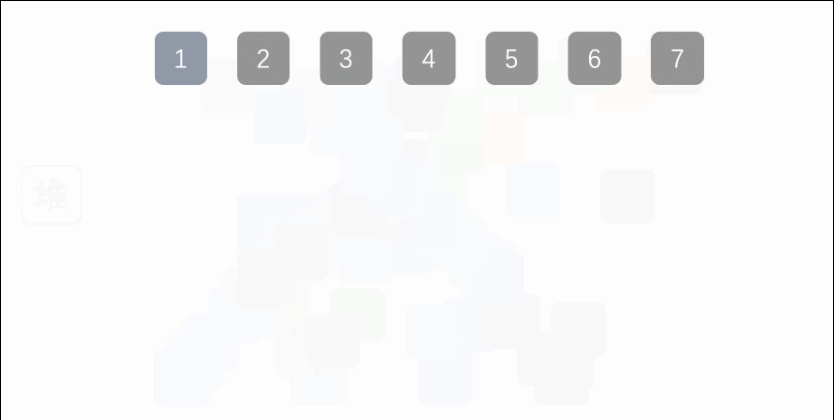
堆排序就是一種基于堆得選擇排序,先將需要排序的序列構建成堆,在每次選取堆頂點的最大值和最小值知道完成整個堆的遍歷,用陣串列示堆:
二叉堆作為樹的一種,通常用結構體表示,為了排序的方便,我們通常使用陣列來表示堆,如下圖:
將一個堆按圖中的方式按層編號可以得到如下結論:
-
節點的父節點編號滿足parent(i) = i/2
-
節點的左孩子編號滿足 left child (i) = 2*i
-
節點右孩子滿足 right child (i) = 2*i + 1
由于陣列編號是從0開始對上面結論修改得到:
parent(i) = (i-1)/2
left child (i) = 2*i + 1
right child (i) = 2*i + 2
堆的兩種操作方式:
根據堆的主要性質(父節點大于兩個子節點或者小于兩個子節點),可以得到堆的兩種主要操作方式,以大頂堆為例:
-
如果子節點大于父節點將子節點上移(shift up)
-
如果父節點小于兩個子節點中的最大值則父節點下移(shift down) shift up:
-
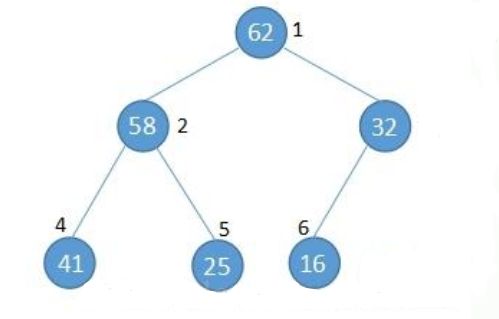
如果往已經建好的堆中添加一個元素,如下圖,此時不再滿足堆的性質,堆遭到破壞,就需要執行shift up 操作將添加的元素上移調整直到滿足堆的性質,
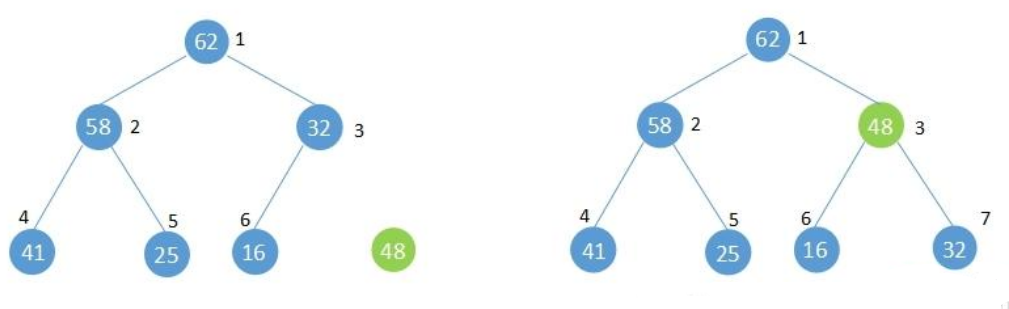
調整堆的方法:
7號位新增元素48與其父節點[i/2]=3比較大于父節點的32不滿足堆性質,將其與父節點交換,
此時新增元素在3號位,再與3號位父節點[i/2]=1比較,小于1號位的62滿足堆性質,不再交換,如果此步驟依舊不滿足堆性質則重復1步驟直到滿足堆的性質或者到根節點,
堆調整完成,
代碼中基于陣列實作,陣列下表從0開始,父子節點關系如用陣串列示堆
代碼實作:
/*parent(i) = (i-1)/2
left child (i) = 2*i + 1
right child (i) = 2*i + 2*/
void swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
return;
}
void shiftUp(int arr[], int n, int k)
{
while ((k - 1) / 2 >= 0 && arr[k] > arr[(k - 1) / 2])
{
swap(&arr[k], &arr[(k - 1) / 2]);
k = (k - 1) / 2;
}
return;
}
shift down: 與shift up相反,如果從一個建好的堆中洗掉一個元素,此時不再滿足堆的性質,此時應該怎樣來調整堆呢?

如上圖,將堆中根節點元素62洗掉調整堆的步驟為:
-
將最后一個元素移到洗掉節點的位置
-
與洗掉節點兩個子節點中較大的子節點比較,如果節點小于較大的子節點,與子節點交換,否則滿足堆性質,完成調整,
-
重復步驟2,直到滿足堆性質或者已經為葉節點,
-
完成堆調整
代碼實作:
void shiftDown(int arr[], int n, int k)
{
int j = 0;
while (2 * k + 1 < n)
{
j = 2 * k + 1; //標記兩個子節點較大的節點,初始為左節點
if (j + 1 < n && arr[j] < arr[j + 1])
{
j++;
}
if (arr[k] < arr[j])
{
swap(&arr[k], &arr[j]);
k = j;
}
else
{
break;
}
}
return;
}
知道了上面兩種堆的操作后,堆排序的程序就非常簡單了
首先將待排序序列建成堆,由于最后一層即葉節點沒有子節點所以可以看成滿足堆性質的節點,第一個可能出現不滿足堆性質的節點在第一個父節點的位置,假設最后一個葉子節點為(n - 1) 則第一個父節點位置為(n-1-1)/2,只需要依次對第一個父節點之前的節點執行shift down操作到根節點后建堆完成,
建堆完成后(以大頂堆為例)第一個元素arr[0]必定為序列中最大值,將最大值提取出來(與陣列最后一個元素交換),此時堆不再滿足堆性質,再對根節點進行shift down操作,依次回圈直到根節點,排序完成,
代碼實作:
#include <stdio.h>
/*
parent(i) = (i-1)/2
left child (i) = 2*i + 1
right child (i) = 2*i + 2
*/
void swap(int *a, int *b)
{
int tmp;
tmp = *a;
*a = *b;
*b = tmp;
return;
}
void shiftUp(int arr[], int n, int k)
{
while ((k - 1) / 2 >= 0 && arr[k] > arr[(k - 1) / 2])
{
swap(&arr[k], &arr[(k - 1) / 2]);
k = (k - 1) / 2;
}
return;
}
void shiftDown(int arr[], int n, int k)
{
int j = 0;
while (2 * k + 1 < n)
{
j = 2 * k + 1;
if (j + 1 < n && arr[j] < arr[j + 1])
{
j++;
}
if (arr[k] < arr[j])
{
swap(&arr[k], &arr[j]);
k = j;
}
else
{
break;
}
}
return;
}
void heapSort(int arr[], int n)
{
int i = 0;
for (i = (n - 1 - 1) / 2; i >= 0; i--)
{
shiftDown(arr, n, i);
}
for (i = n - 1; i > 0; i--)
{
swap(&arr[0], &arr[i]);
shiftDown(arr, i, 0);
}
return;
}
void printArray(int arr[], int n)
{
int i;
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
return;
}
void main()
{
int arr[10] = {1, 5, 9, 8, 7, 6, 3, 4, 0, 2};
printArray(arr, 10);
heapSort(arr, 10);
printArray(arr, 10);
}
基數排序
基數排序(radix sort)屬于“分配式排序”(distribution sort),又稱“桶子法”(bucket sort)或bin sort,顧名思義,它是透過鍵值的部份資訊, 將要排序的元素分配至某些“桶”中,藉以達到排序的作用,基數排序法是屬于穩定性的排序,其時間復雜度為O (nlog(r)m),其中r為所采取的基 數,而m為堆數,在某些時候,基數排序法的效率高于其它的穩定性排序法,

第一步
以LSD為例,假設原來有一串數值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根據個位數的數值,在走訪數值時將它們分配至編號0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
第二步
接下來將這些桶子中的數值重新串接起來,成為以下的數列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接著再進行一次分配,這次是根據十位數來分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
第三步
接下來將這些桶子中的數值重新串接起來,成為以下的數列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
這時候整個數列已經排序完畢;如果排序的物件有三位數以上,則持續進行以上的動作直至最高位數為止,
LSD的基數排序適用于位數小的數列,如果位數多的話,使用MSD的效率會比較好,MSD的方式與LSD相反,是由高位數為基底開始進行分配,但在分配之后并不馬上合并回一個陣列中,而是在每個“桶子”中建立“子桶”,將每個桶子中的數值按照下一數位的值分配到“子桶”中,在進行完最低位數的分配后再合并回單一的陣列中,
#include <math.h>
#include<stdio.h>
testBS()
{
int a[] = {2, 343, 342, 1, 123, 43, 4343, 433, 687, 654, 3};
int *a_p = a;
//計算陣列長度
int size = sizeof(a) / sizeof(int);
//基數排序
bucketSort3(a_p, size);
//列印排序后結果
int i;
for (i = 0; i < size; i++)
{
printf("%d\n", a[i]);
}
int t;
scanf("%d", t);
}
//基數排序
void bucketSort3(int *p, int n)
{
//獲取陣列中的最大數
int maxNum = findMaxNum(p, n);
//獲取最大數的位數,次數也是再分配的次數,
int loopTimes = getLoopTimes(maxNum);
int i;
//對每一位進行桶分配
for (i = 1; i <= loopTimes; i++)
{
sort2(p, n, i);
}
}
//獲取數字的位數
int getLoopTimes(int num)
{
int count = 1;
int temp = num / 10;
while (temp != 0)
{
count++;
temp = temp / 10;
}
return count;
}
//查詢陣列中的最大數
int findMaxNum(int *p, int n)
{
int i;
int max = 0;
for (i = 0; i < n; i++)
{
if (*(p + i) > max)
{
max = * (p + i);
}
}
return max;
}
//將數字分配到各自的桶中,然后按照桶的順序輸出排序結果
void sort2(int *p, int n, int loop)
{
//建立一組桶此處的20是預設的根據實際數情況修改
int buckets[10][20] = {};
//求桶的index的除數
//如798個位桶index=(798/1)%10=8
//十位桶index=(798/10)%10=9
//百位桶index=(798/100)%10=7
//tempNum為上式中的1、10、100
int tempNum = (int)pow(10, loop - 1);
int i, j;
for (i = 0; i < n; i++)
{
int row_index = (*(p + i) / tempNum) % 10;
for (j = 0; j < 20; j++)
{
if (buckets[row_index][j] == NULL)
{
buckets[row_index][j] = * (p + i);
break;
}
}
}
//將桶中的數,倒回到原有陣列中
int k = 0;
for (i = 0; i < 10; i++)
{
for (j = 0; j < 20; j++)
{
if (buckets[i][j] != NULL)
{
*(p + k) = buckets[i][j];
buckets[i][j] = NULL;
k++;
}
}
}
}
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/510654.html
標籤:C
上一篇:驅動開發:內核字串拷貝與比較