Redis介紹
1.Redis 是一個基于記憶體的高性能 key-value 資料庫,是完全開源免費的,用C語言撰寫的,遵守BSD協議
2.Redis 特點:
1)Redis 是基于記憶體操作的,吞吐量非常高,可以在 1s內完成十萬次讀寫操作
2)Redis 的讀寫模塊是單執行緒,每個操作都具原子性
3)Redis 支持資料的持久化,可以將記憶體中的資料保存在磁盤中,重啟可以再次加載,但可能會有極短時間內資料丟失
4)Redis 支持多種資料結構,String,list,set,zset,hash等
針對五種資料結構的介紹【針對場景部分,有些并不適用,但是用于拓展視野】
1.字串String(用的多)
1)常用操作
【1】單值操作
SET key value //存入字串鍵值對 GET key //獲取一個字串鍵值 SETNX key value //存入一個不存在的字串鍵值對,有點類似原子操作,如果沒有才給存入,有則失敗 DEL key [key ...] //洗掉一個鍵 EXPIRE key seconds //設定一個鍵的過期時間(秒)
【2】批量操作
MSET key value [key value ...] //批量存盤字串鍵值對 MGET key [key ...] //批量獲取字串鍵值
【3】原子操作
INCR key //將key中儲存的數字值加1 DECR key //將key中儲存的數字值減1 INCRBY key increment //將key所儲存的值加上increment DECRBY key decrement //將key所儲存的值減去decrement
2)應用場景
【1】單值快取
SET key value
GET key
【2】物件快取
//這兩種情況要區分,你對這個物件的操作是整體多還是屬性值多,因為java中使用的話物件的資料型別需要序列化【存盤和取出都要】 //而且分開存的話有助于在不同地方使用不同屬性值,但是卻要取出整個物件的局面,(雖然分開存消耗記憶體更多,但是從傳輸角度來想,有可能消耗更小,但都是分場景的) 1) SET user:1 value(json格式資料) 2) MSET user:1:name zhuge user:1:balance 1888 //針對物件的值分開存盤的批量操作 MGET user:1:name user:1:balance
【3】分布式鎖實作(下面僅僅是示例,這個實作其實要考慮的問題很多,可查看 Redis高并發分布式鎖詳解 )
SETNX product:10001 true //回傳1代表獲取鎖成功 SETNX product:10001 true //回傳0代表獲取鎖失敗 ,,,執行業務操作 DEL product:10001 //執行完業務釋放鎖 SET product:10001 true ex 10 nx //防止程式意外終止導致死鎖
【4】計數器
INCR article:readcount:{文章id}
GET article:readcount:{文章id}
【5】實作分布式session共享(可查看 分布式Session的實作詳解 )
spring session + redis實作session共享
【6】分布式全域ID
INCRBY orderId 1000 //redis批量生成序列號提升性能
2.哈希hash
1)常用操作
【1】單值操作
HSET key field value //存盤一個哈希表key的鍵值 HGET key field //獲取哈希表key對應的field鍵值 HSETNX key field value //存盤一個不存在的哈希表key的鍵值
【2】批量操作
HMSET key field value [field value ...] //在一個哈希表key中存盤多個鍵值對 HMGET key field [field ...] //批量獲取哈希表key中多個field鍵值 HDEL key field [field ...] //洗掉哈希表key中的field鍵值 HLEN key //回傳哈希表key中field的數量 HGETALL key //回傳哈希表key中所有的鍵值
【3】原子操作
HINCRBY key field increment //為哈希表key中field鍵的值加上增量increment
2)應用場景
【1】物件快取(由于redis設定過期時間只針對頂級key型別,而不支持對hash型別內部,故塞得多了容易造成bigKey問題)
HMSET user {userId}:name zhuge {userId}:balance 1888
HMSET user 1:name zhuge 1:balance 1888
HMGET user 1:name 1:balance
【2】電商購物車
1)以用戶id為key //以用戶ID為key,避免多個用戶存盤在一個hash里面(避免bigKey)//針對未登錄的可以構建虛擬ID,對登錄時的資料進行合并 2)商品id為field 3)商品數量為value 4)可以針對key設定過期時間 //設定過期時間可以在不用的時候,redis自己回收 購物車操作 hset cart:1001 10088 1 //添加商品 hincrby cart:1001 10088 1 //增加數量 hlen cart:1001 //商品總數 hdel cart:1001 10088 //洗掉商品 hgetall cart:1001 //獲取購物車所有商品
3)優缺點
優點 1)同類資料歸類整合儲存,方便資料管理 2)相比string操作消耗記憶體與cpu更小 3)相比string儲存更節省空間 缺點 1)過期功能不能使用在field上,只能用在key上,//(這也是容易造成bigKey問題的本質,設定過期時間是為了讓redis自己去回收,設定不了就只能靠自己去回收,不回收容易造成記憶體擠爆,也容易出現阻塞請求的情況) 2)Redis集群架構下不適合大規模使用,//(因為構建集群的本質是平攤請求和資料,提高處理量和扛并發,如果hash的值會被存盤在某個節點中,如果值很大,那么容易出現請求傾斜,那么這個結點容易被打掛)
3.串列list(用的多)
1)常用操作
LPUSH key value [value ...] //將一個或多個值value插入到key串列的表頭(最左邊) RPUSH key value [value ...] //將一個或多個值value插入到key串列的表尾(最右邊) LPOP key //移除并回傳key串列的頭元素 RPOP key //移除并回傳key串列的尾元素 LRANGE key start stop //回傳串列key中指定區間內的元素,區間以偏移量start和stop指定 BLPOP key [key ...] timeout //從key串列表頭彈出一個元素,若串列中沒有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待 BRPOP key [key ...] timeout //從key串列表尾彈出一個元素,若串列中沒有元素,阻塞等待 timeout秒,如果timeout=0,一直阻塞等待
2)應用場景
【1】常用資料結構(應對分布式下某些資料結構的要求)
Stack(堆疊) = LPUSH + LPOP Queue(佇列)= LPUSH + RPOP Blocking MQ(阻塞佇列)= LPUSH + BRPOP
【2】微博訊息和微信公號訊息(這種更多體現在即時通訊軟體上面)
你關注了A,B等大V 1)A發微博,訊息ID為10018 LPUSH msg:{你-ID} 10018 2)B發微博,訊息ID為10086 LPUSH msg:{你-ID} 10086 3)查看最新微博訊息 LRANGE msg:{你-ID} 0 4
4.集合set(比較重要)
1)常用操作
SADD key member [member ...] //往集合key中存入元素,元素存在則忽略,若key不存在則新建 SREM key member [member ...] //從集合key中洗掉元素 SMEMBERS key //獲取集合key中所有元素 SCARD key //獲取集合key的元素個數 SISMEMBER key member //判斷member元素是否存在于集合key中 SRANDMEMBER key [count] //從集合key中隨機選出count個元素,元素不從key中洗掉 SPOP key [count] //從集合key中隨機選出count個元素,元素從key中洗掉
2)運算操作
SINTER key [key ...] //交集運算,多個集合共有的元素的集合 SINTERSTORE destination key [key ..] //將交集結果存入新集合destination中 SUNION key [key ..] //并集運算,將元素匯總成一個集合 SUNIONSTORE destination key [key ...] //將并集結果存入新集合destination中 SDIFF key [key ...] //差集運算,相當于第一個集合減去后面多個集合的并集 SDIFFSTORE destination key [key ...] //將差集結果存入新集合destination中
3)應用場景
【1】微信抽獎小程式
1)點擊參與抽獎加入集合 SADD key {userlD} 2)查看參與抽獎所有用戶 SMEMBERS key 3)抽取count名中獎者 SRANDMEMBER key [count] / SPOP key [count]
【2】微信微博點贊,收藏,標簽
1) 點贊 SADD like:{訊息ID} {用戶ID} 2) 取消點贊 SREM like:{訊息ID} {用戶ID} 3) 檢查用戶是否點過贊 SISMEMBER like:{訊息ID} {用戶ID} 4) 獲取點贊的用戶串列 SMEMBERS like:{訊息ID} 5) 獲取點贊用戶數 SCARD like:{訊息ID}
【3】集合操作實作微博微信關注模型
1) A關注的人: ASet-> {C, D} 2) B關注的人: BSet--> {A, E, C, D} 3) C關注的人: CSet-> {A, B, E, D, F) //重點通過A與關注他的B【但A沒有關注B】 4) A,B共同關注: SINTER ASet BSet--> {C, D} 5) A關注的人也關注他(B): SISMEMBER CSet B SISMEMBER DSet B 6) A可能認識的人: SDIFF BSet ASet->{A, E}
【4】集合操作實作電商商品篩選
SADD brand:huawei P40 SADD brand:xiaomi mi-10 SADD brand:iPhone iphone12 SADD os:android P40 mi-10 SADD cpu:brand:intel P40 mi-10 SADD ram:8G P40 mi-10 iphone12 SINTER os:android cpu:brand:intel ram:8G ? {P40,mi-10}
5.有序集合zset
1)常用操作
ZADD key score member [[score member]…] //往有序集合key中加入帶分值元素 ZREM key member [member …] //從有序集合key中洗掉元素 ZSCORE key member //回傳有序集合key中元素member的分值 ZINCRBY key increment member //為有序集合key中元素member的分值加上increment ZCARD key //回傳有序集合key中元素個數 ZRANGE key start stop [WITHSCORES] //正序獲取有序集合key從start下標到stop下標的元素,WITHSCORES引數的作用:就是查詢結果帶上分數 ZREVRANGE key start stop [WITHSCORES] //倒序獲取有序集合key從start下標到stop下標的元素
2)集合操作
ZUNIONSTORE destkey numkeys key [key ...] //并集計算 ZINTERSTORE destkey numkeys key [key ...] //交集計算
3)應用場景
【1】Zset集合操作實作排行榜
1)點擊新聞 ZINCRBY hotNews:20190819 1 守護香港ID //針對單條資料,集合名,瀏覽次數,文章ID 2)展示當日排行前十 ZREVRANGE hotNews:20190819 0 9 WITHSCORES 3)七日搜索榜單計算 ZUNIONSTORE hotNews:20190813-20190819 7 hotNews:20190813 hotNews:20190814... hotNews:20190819 4)展示七日排行前十 ZREVRANGE hotNews:20190813-20190819 0 9 WITHSCORES
針對Redis的探索
1)Redis是單執行緒嗎?
1.Redis并不是真正意義上的單執行緒,Redis的單執行緒主要是指Redis的網路IO和鍵值對讀寫是由一個執行緒來完成的,這也是 Redis 對外提供鍵值存盤服務的主要流程,
2.但 Redis 的其他功能,比如持久化、異步洗掉、集群資料同步等,其實是由額外的執行緒執行的,
2)Redis 單執行緒為什么還能這么快?
1.因為它所有的資料都在記憶體中,所有的運算都是記憶體級別的運算,而且單執行緒避免了多執行緒的切換性能損耗問題,正因為 Redis 是單執行緒,所以要小心使用 Redis 指令,對于那些耗時的指令(比如keys),一定要謹慎使用,一不小心就可能會導致 Redis 卡頓,
2.展示
【1】keys:全量遍歷鍵,用來列出所有滿足特定正則字串規則的key,當redis資料量比較大時,性能比較差,要避免使用
keys * //展示全部key值 keys ab*c //展示全部符合正則匹配的key值
【2】scan:漸進式遍歷鍵,(常用這種替代keys指令)
SCAN cursor [MATCH pattern] [COUNT count] 示例:SCAN 0 MATCH test*key COUNT 100
說明:scan 引數提供了三個引數,第一個是 cursor 整數值(hash桶的索引值),第二個是 key 的正則模式,第三個是一次遍歷的key的數量(參考值,底層遍歷的數量不一定),并不是符合條件的結果數量,第一次遍歷時,cursor 值為 0,然后將回傳結果中第一個整數值作為下一次遍歷的 cursor,一直遍歷到回傳的 cursor 值為 0 時結束,
注意:但是scan并非完美無瑕, 如果在scan的程序中如果有鍵的變化(增加、 洗掉、 修改) ,那么遍歷效果可能會碰到如下問題: 新增的鍵可能沒有遍歷到, 遍歷出了重復的鍵等情況, 也就是說scan并不能保證完整的遍歷出來所有的鍵, 這些是我們在開發時需要考慮的,
示例展示:
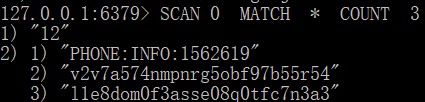
示例分析:
這個和底層實作有關,Redis的底層相當于一個HashMap(將資料散列存盤到key中存盤一樣),scan 每次去遍歷的時候會去遍歷其中存盤資料的一個key值,一次最多拿三個,并且回傳下次的游標,便于下次獲取,
如果一共有36個資料分別散落于4個key為key1,key2,key3,key4中,其中key1有8個資料,key2有7個,key3有10個,key4有11個,那么先去掃描key1的槽,
第三次拿只會拿到2個資料,然后key1槽掃描完就不會再掃描了,而會去掃描key2的槽,按此邏輯走完全部的槽,這也是為什么我們需要在開發的時候注意的,
3)Redis 單執行緒如何處理那么多的并發客戶端連接?
1.Redis的IO多路復用:redis利用epoll來實作IO多路復用,將連接資訊和事件放到佇列中,依次放到檔案事件分派器,事件分派器將事件分發給事件處理器,
2.連接數是存在限制的:
# 查看redis支持的最大連接數,在redis.conf檔案中可修改,# maxclients 10000 127.0.0.1:6379> CONFIG GET maxclients ##1) "maxclients" ##2) "10000"
4)Redis 真的可以在 1s內完成十萬次讀寫操作嗎?
其實不是的,這個與當前的服務器有關,大多數應該是幾萬,Redis 自帶了一個叫 redis-benchmark 的工具(放在Redis的src目錄下)來模擬 N 個客戶端同時發出 M 個請求:
[root@node1 bin]# redis-benchmark --help Usage: redis-benchmark [-h <host>] [-p <port>] [-c <clients>] [-n <requests]> [-k <boolean>] -h <hostname> 指定服務器主機名 (默認 127.0.0.1) -p <port> 指定服務器埠 (默認 6379) -s <socket> 指定服務器 socket -a <password> 指定redis密碼 -c <clients> 指定并發連接數 (默認 50) -n <requests> 指定請求數 (默認 100000) -d <size> SET/GET 命令的值bytes單位 默認是2 --dbnum <db> 指定redis的某個資料庫,默認是0資料庫 -k <boolean> 指定是否保持連接 1是保持連接 0是重新連接,默認為 1 -r <keyspacelen> 指定get/set的隨機值的范圍, -P <numreq> 管道請求測驗,默認0沒有管道測驗 -e 如果有錯誤,輸出到標準輸出上, -q 靜默模式,只顯示query/秒的值 --csv 指定輸出結果到csv檔案中 -l 生成回圈,永久執行測驗 -t <tests> 僅運行以逗號分隔的測驗命令串列
理解Redis對Lua腳本的操作
1.介紹
1)Redis在2.6推出了腳本功能,允許開發者使用Lua語言撰寫腳本傳到Redis中執行,使用腳本的好處如下:
【1】減少網路開銷:本來5次網路請求的操作,可以用一個請求完成,原先5次請求的邏輯放在redis服務器上完成,使用腳本,減少了網路往返時延,與管道類似,
【2】原子操作:Redis會將整個腳本作為一個整體執行,中間不會被其他命令插入,管道不是原子的,不過redis的批量操作命令(類似mset)是原子的,
【3】替代redis的事務功能:redis自帶的事務功能很雞肋,而redis的lua腳本幾乎實作了常規的事務功能,官方推薦如果要使用redis的事務功能可以用redis lua替代,
2.簡單使用
1)從Redis2.6.0版本開始,通過內置的Lua解釋器,可以使用EVAL命令對Lua腳本進行求值,EVAL命令的格式如下:
示例代碼
格式:EVAL script numkeys key [key ...] arg [arg ...]
示例:eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
示例結果【展示了如何進行傳參】

示例說明
【1】script引數是一段Lua腳本程式,它會被運行在Redis服務器背景關系中,這段腳本不必定義為一個Lua函式,numkeys引數用于指定鍵名引數的個數,
【2】鍵名引數 key [key ...] 從EVAL的第三個引數開始算起,表示在腳本中所用到的那些Redis鍵(key),這些鍵名引數可以在 Lua中通過全域變數KEYS陣列,用1為基址的形式訪問( KEYS[1] , KEYS[2] ,以此類推),
【3】在命令的最后,那些不是鍵名引數的附加引數 arg [arg ...] ,可以在Lua中通過全域變數ARGV陣列訪問,訪問的形式和KEYS變數類似( ARGV[1] 、 ARGV[2] ,諸如此類),
【4】其中 "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 是被求值的Lua腳本,數字2指定了鍵名引數的數量, key1和key2是鍵名引數,分別使用 KEYS[1] 和 KEYS[2] 訪問,而最后的 first 和 second 則是附加引數,可以通過 ARGV[1] 和 ARGV[2] 訪問它們,
2)在 Lua 腳本中,可以使用redis.call()函式來執行Redis命令(使用Jedis呼叫):
jedis.set("product_stock_10016", "15"); //初始化商品10016的庫存
String script = " local count = redis.call('get', KEYS[1]) " +
" local a = tonumber(count) " +
" local b = tonumber(ARGV[1]) " +
" if a >= b then " +
" redis.call('set', KEYS[1], a-b) " +
" return 1 " +
" end " +
" return 0 ";
Object obj = jedis.eval(script, Arrays.asList("product_stock_10016"), Arrays.asList("10"));
System.out.println(obj);
注意:不要在Lua腳本中出現死回圈和耗時的運算,否則redis會阻塞,將不接受其他的命令, 所以使用時要注意不能出現死回圈、耗時的運算,redis是單行程、單執行緒執行腳本,管道不會阻塞redis,
Redis快取設計中存在的問題
1.快取穿透
1)說明:
【1】快取穿透是指查詢一個根本不存在的資料, 快取層和存盤層都不會命中, 通常出于容錯的考慮, 如果從存盤層查不到資料則不寫入快取層,
【2】快取穿透將導致不存在的資料每次請求都要到存盤層去查詢, 失去了快取保護后端存盤的意義,
【3】造成快取穿透的基本原因有兩個:
第一, 自身業務代碼或者資料出現問題,
第二, 一些惡意攻擊、 爬蟲等造成大量空命中,
2)處理:
【1】快取空物件
//主體邏輯 product = productDao.get(productId); if (product != null) { redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS); } else { redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); } //空快取的過期時間獲取,這個時間不宜過大,一分鐘左右即可,時間過大容易快取大量空資料,消耗Redis存盤資源, //時間過小容易很快過期,但是我們可以進行讀延期,你一直查,我們一直延期,你不查了,過一段時間就會失效 private Integer genEmptyCacheTimeout() { return 60 + new Random().nextInt(30); }
【2】布隆過濾器
1.布隆過濾器介紹
1)對于惡意攻擊,向服務器請求大量不存在的資料造成的快取穿透,還可以用布隆過濾器先做一次過濾,對于不存在的資料布隆過濾器一般都能夠過濾掉,不讓請求再往后端發送,當布隆過濾器說某個值存在時,這個值可能不存在;當它說不存在時,那就肯定不存在,
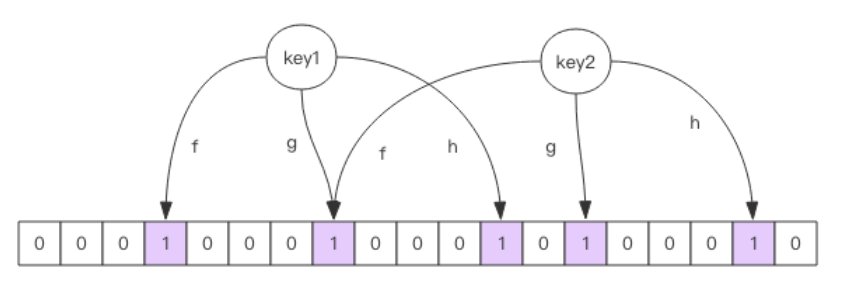
2)布隆過濾器就是一個大型的位陣列和幾個不一樣的無偏 hash 函式,所謂無偏就是能夠把元素的 hash 值算得比較均勻,
3)向布隆過濾器中添加 key 時,會使用多個 hash 函式對 key 進行 hash 算得一個整數索引值然后對位陣列長度進行取模運算得到一個位置,每個 hash 函式都會算得一個不同的位置,再把位陣列的這幾個位置都置為 1 就完成了 add 操作,
4)向布隆過濾器詢問 key 是否存在時,跟 add 一樣,也會把 hash 的幾個位置都算出來,看看位陣列中這幾個位置是否都為 1,只要有一個位為 0,那么說明布隆過濾器中這個key 不存在,如果都是 1,這并不能說明這個 key 就一定存在,只是極有可能存在,因為這些位被置為 1 可能是因為其它的 key 存在所致,如果這個位陣列長度比較大,存在概率就會很大,如果這個位陣列長度比較小,存在概率就會降低,
5)這種方法適用于資料命中不高、 資料相對固定、 實時性低(通常是資料集較大) 的應用場景, 代碼維護較為復雜, 但是快取空間占用很少,
2.圖示
3.用redisson實作布隆過濾器
1)引入依賴:
<dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>3.6.5</version> </dependency>
2)示例偽代碼:
public class RedissonBloomFilter { public static void main(String[] args) { Config config = new Config(); config.useSingleServer().setAddress("redis://localhost:6379"); //構造Redisson RedissonClient redisson = Redisson.create(config); RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList"); //初始化布隆過濾器:預計元素為100000000L,誤差率為3%,根據這兩個引數會計算出底層的bit陣列大小 bloomFilter.tryInit(100000000L,0.03); //將zhuge插入到布隆過濾器中 bloomFilter.add("abc"); //判斷下面號碼是否在布隆過濾器中 System.out.println(bloomFilter.contains("bcd"));//false System.out.println(bloomFilter.contains("cde"));//false System.out.println(bloomFilter.contains("abc"));//true } }
3)使用布隆過濾器需要把所有資料提前放入布隆過濾器,并且在增加資料時也要往布隆過濾器里放,布隆過濾器快取過濾偽代碼:
//初始化布隆過濾器 RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList"); //初始化布隆過濾器:預計元素為100000000L,誤差率為3% bloomFilter.tryInit(100000000L,0.03); //把所有資料存入布隆過濾器 void init(){ for (String key: keys) { bloomFilter.put(key); } } String get(String key) { // 從布隆過濾器這一級快取判斷下key是否存在 Boolean exist = bloomFilter.contains(key); if(!exist){ return ""; } // 從快取中獲取資料 String cacheValue = cache.get(key); // 快取為空 if (StringUtils.isBlank(cacheValue)) { // 從存盤中獲取 String storageValue = storage.get(key); cache.set(key, storageValue); // 如果存盤資料為空, 需要設定一個過期時間(300秒) if (storageValue == null) { cache.expire(key, 60 * 5); } return storageValue; } else { // 快取非空 return cacheValue; } }
3.注意:布隆過濾器不能洗掉資料,如果要洗掉得重新初始化資料,
2.快取失效(擊穿)
1)說明:由于大批量快取在同一時間失效可能導致大量請求同時穿透快取直達資料庫,可能會造成資料庫瞬間壓力過大甚至掛掉,對于這種情況我們在批量增加快取時最好將這一批資料的快取過期時間設定為一個時間段內的不同時間,造成的原因是:我們為了便捷,提供了批量生產與批量修改操作,那么容易出現設定的過期時間一直問題,
2)處理:
【1】同一獲取過期時間的入口,針對獲取過期時間采取添加隨機時間錯開時間段,
public static final Integer PRODUCT_CACHE_TIMEOUT = 60 * 60 * 24; //設定為1天或者更少,這種一般要考慮凌晨時期的空窗期(沒人使用) private Integer genProductCacheTimeout() { //這對過期時間添加隨機時間 return PRODUCT_CACHE_TIMEOUT + new Random().nextInt(5) * 60 * 60; }
【2】對于獲取資料步驟,要對快取增加讀延期
public static final String EMPTY_CACHE = "{}"; private Product getProductFromCache(String productCacheKey) { String productStr = redisUtil.get(productCacheKey); if (!StringUtils.isEmpty(productStr)) { if (EMPTY_CACHE.equals(productStr)) { redisUtil.expire(productCacheKey, genEmptyCacheTimeout(), TimeUnit.SECONDS); //讀延期,延長過期時間 return null; } product = JSON.parseObject(productStr, Product.class); redisUtil.expire(productCacheKey, genProductCacheTimeout(), TimeUnit.SECONDS); //讀延期,延長過期時間 } return product; }
3.快取雪崩
1)介紹:
【1】快取雪崩指的是快取層支撐不住或宕掉后, 流量直接打向后端存盤層,
【2】由于快取層承載著大量請求, 有效地保護了存盤層, 但是如果快取層由于某些原因不能提供服務(比如超大并發過來,快取層支撐不住,或者由于快取設計不好,類似大量請求訪問bigkey,導致快取能支撐的并發急劇下降), 于是大量請求都會打到存盤層, 存盤層的呼叫量會暴增, 造成存盤層也會級聯宕機的情況,
【3】總的來說,就是Redis配置中存在 maxclients 10000 屬性值限制(設定能連上redis的最大客戶端連接數量,默認是10000個客戶端連接,由于redis不區分連接是客戶端連接還是內部打開檔案或者和slave連接等,所以maxclients最小建議設定到32,如果超過了maxclients,redis會給新的連接發送’max number of clients reached’,并關閉連接,)
2)處理:
【1】保證快取層服務高可用性,比如使用Redis Sentinel或Redis Cluster,(即使用集群增加雪崩的上限,增加雪崩的難度)
【2】依賴隔離組件為后端限流熔斷并降級,比如使用Sentinel或Hystrix限流降級組件(最好結合 redis-benchmark 的工具,壓測部署在服務器上集群能抗住多少并發),比如服務降級,我們可以針對不同的資料采取不同的處理方式,當業務應用訪問的是非核心資料(例如電商商品屬性,用戶資訊等)時,暫時停止從快取中查詢這些資料,而是直接回傳預定義的默認降級資訊、空值或是錯誤提示資訊;當業務應用訪問的是核心資料(例如電商商品庫存)時,仍然允許查詢快取,如果快取缺失,也可以繼續通過資料庫讀取,
【3】提前演練, 在專案上線前, 演練快取層宕掉后, 應用以及后端的負載情況以及可能出現的問題, 在此基礎上做一些預案設定,
4.熱點快取key重建優化
1)介紹:
【1】使用“快取+過期時間”的策略既可以加速資料讀寫, 又保證資料的定期更新, 這種模式基本能夠滿足絕大部分需求, 但是有兩個問題如果同時出現, 可能就會對應用造成致命的危害:
1.當前key是一個熱點key(例如一個熱門的娛樂新聞),并發量非常大,
2.重建快取不能在短時間完成, 可能是一個復雜計算, 例如復雜的SQL、 多次IO、 多個依賴等,
【2】在快取失效的瞬間, 有大量執行緒來重建快取, 造成后端負載加大, 甚至可能會讓應用崩潰,
2)處理(主要就是要避免大量執行緒同時重建快取):
【1】利用互斥鎖來解決,此方法只允許一個執行緒重建快取, 其他執行緒等待重建快取的執行緒執行完, 重新從快取獲取資料即可,
【2】采用DCL【雙重檢查鎖(double-checked locking)】,可以在完成重建后加快回傳速度,
【3】代碼展示:
product = getProductFromCache(productCacheKey); if (product != null) { return product; } //DCL RLock hotCacheLock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE_PREFIX + productId); hotCacheLock.lock(); try { product = getProductFromCache(productCacheKey); if (product != null) { return product; } product = productDao.get(productId); if (product != null) { redisUtil.set(productCacheKey, JSON.toJSONString(product),genProductCacheTimeout(), TimeUnit.SECONDS); } else { redisUtil.set(productCacheKey, EMPTY_CACHE, genEmptyCacheTimeout(), TimeUnit.SECONDS); } } finally { hotCacheLock.unlock(); } return product;
5.快取與資料庫雙寫不一致
1)介紹:在大并發下,同時操作資料庫與快取會存在資料不一致性問題【這種采用雙刪是解決不了的】
【1】雙寫不一致情況
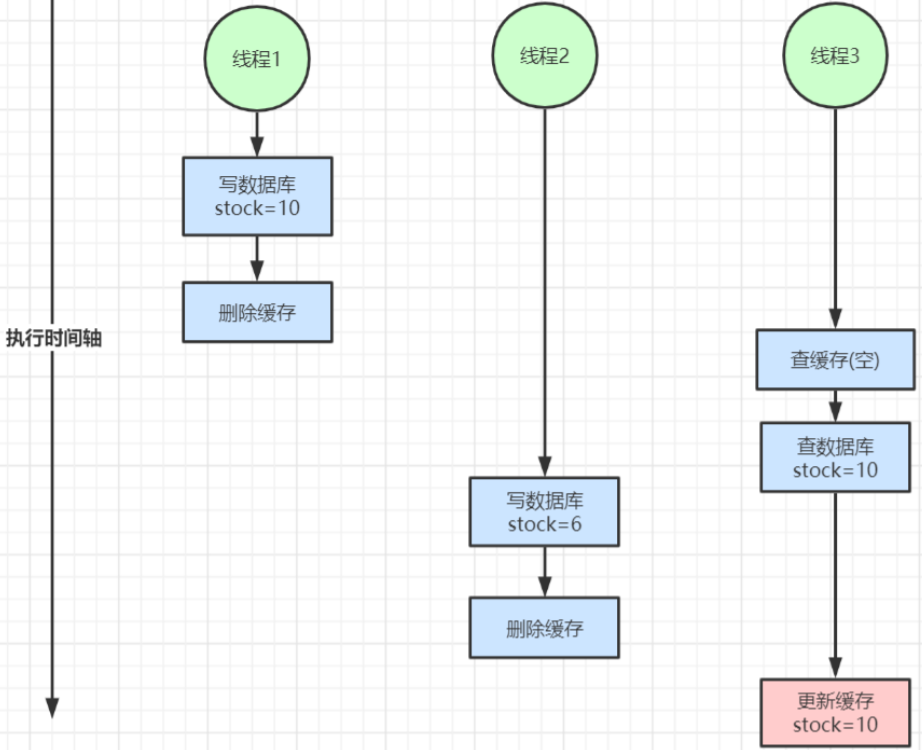
【2】讀寫并發不一致
2)處理:
【1】對于并發幾率很小的資料(如個人維度的訂單資料、用戶資料等),這種幾乎不用考慮這個問題,很少會發生快取不一致,可以給快取資料加上過期時間,每隔一段時間觸發讀的主動更新即可,
【2】就算并發很高,如果業務上能容忍短時間的快取資料不一致(如商品名稱,商品分類選單等),快取加上過期時間依然可以解決大部分業務對于快取的要求,
【3】如果不能容忍快取資料不一致,可以通過加分布式讀寫鎖保證并發讀寫或寫寫的時候按順序排好隊,讀讀的時候相當于無鎖,
【4】也可以用阿里開源的canal通過監聽資料庫的binlog日志及時的去修改快取,但是引入了新的中間件,增加了系統的復雜度,
6.總結
【1】以上都是針對讀多寫少的情況加入快取提高性能,如果寫多讀多的情況又不能容忍快取資料不一致,那就沒必要加快取了,可以直接操作資料庫,
【2】如果資料庫抗不住壓力,還可以把快取作為資料讀寫的主存盤,異步將資料同步到資料庫,資料庫只是作為資料的備份,
【3】放入快取的資料應該是對實時性、一致性要求不是很高的資料,
【4】不要為了用快取,同時又要保證絕對的一致性做大量的過度設計和控制,增加系統復雜性!(如延遲雙刪加上休眠時間,這就很不可取)
查看redis服務運行資訊
1.Info:查看redis服務運行資訊,分為 9 大塊,每個塊都有非常多的引數,這 9 個塊分別是:
1.Server 服務器運行的環境引數
2.Clients 客戶端相關資訊
3.Memory 服務器運行記憶體統計資料
4.Persistence 持久化資訊
5.Stats 通用統計資料
6.Replication 主從復制相關資訊
7.CPU CPU 使用情況
8.Cluster 集群資訊
9.KeySpace 鍵值對統計數量資訊
2.示例
3.核心引數說明
connected_clients:2 # 正在連接的客戶端數量 instantaneous_ops_per_sec:789 # 每秒執行多少次指令 used_memory:929864 # Redis分配的記憶體總量(byte),包含redis行程內部的開銷和資料占用的記憶體 used_memory_human:908.07K # Redis分配的記憶體總量(Kb,human會展示出單位) used_memory_rss_human:2.28M # 向作業系統申請的記憶體大小(Mb)(這個值一般是大于used_memory的,因為Redis的記憶體分配策略會產生記憶體碎片) used_memory_peak:929864 # redis的記憶體消耗峰值(byte) used_memory_peak_human:908.07K # redis的記憶體消耗峰值(KB) maxmemory:0 # 配置中設定的最大可使用記憶體值(byte),默認0,不限制,一般配置為機器物理記憶體的百分之七八十,需要留一部分給作業系統 maxmemory_human:0B # 配置中設定的最大可使用記憶體值 maxmemory_policy:noeviction # 當達到maxmemory時的淘汰策略
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/510863.html
標籤:其他
上一篇:Spring 5