我在隨機生成的時間戳中發現了一個奇怪的情況。我有一個生成人工日志資料的應用程式,我希望能夠定義時間范圍。因此我寫了一個這樣的函式:
# imports
from datetime import datetime
import time
from random import choice
timestamps = []
timerange_in_days = 14 # how many days back from today should my timestamps cover?
entries = 10000 # how many timestamps?
for _ in range(entries):
last_midnight = (int(time.time() // 86400)) * 86400 # find date border
days = range(1, timerange_in_days 1) # set the range
timestamp = last_midnight - (choice(days) * choice(range(1, 25)) * 3600) # create the timestamp
timestamp = datetime.fromtimestamp(timestamp).isoformat(timespec='milliseconds') # format it
timestamps.append(timestamp)
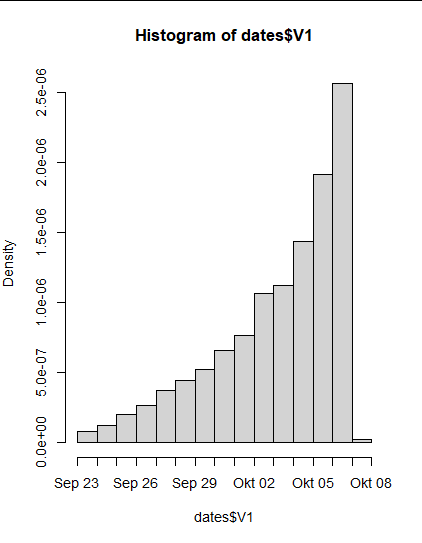
然后我將它寫入一個檔案并在 R 中繪制,因為我無法在 python 中快速將其可視化。我按天和按小時繪制了一個直方圖,10 月 8 日的小條來自未調整的時區,這意味著它一直持續到第二天凌晨 2 點。
with open(r'/path/to/file/dates.txt', 'w') as myfile:
for item in timestamps:
my
file.write("%s\n" % item)
# in R
path <- "path/to/file"
dates <- data.table::fread(file.path(path, "dates.txt")) # recognizes as POSIXct automatically
hist(dates$V1, "days")
hist(dates$V1, "hours")
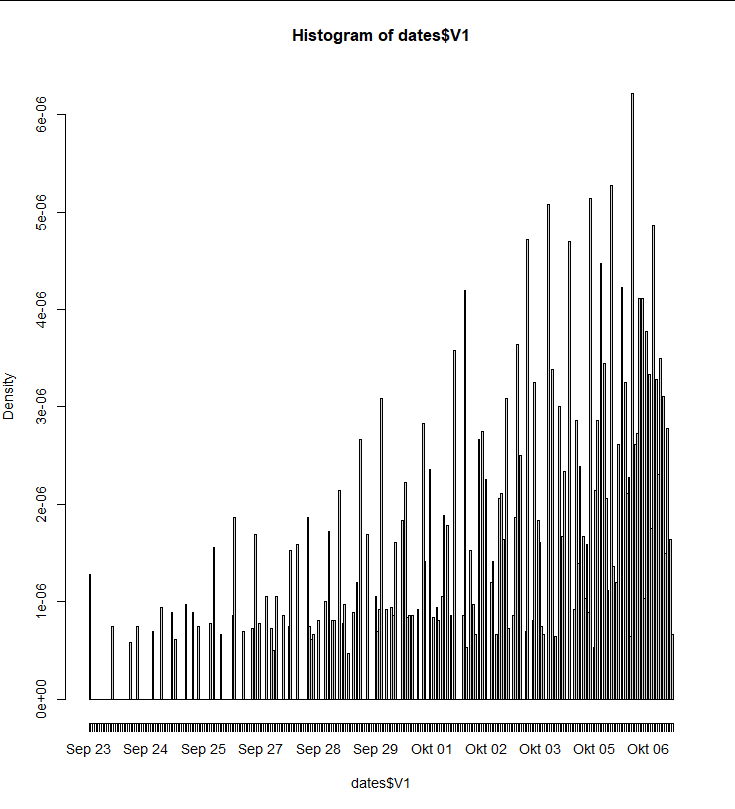
但我的問題是,為什么“現在”周圍的時間戳更頻繁?我希望它們在日子里平均分布
uj5u.com熱心網友回復:
重新思考你的邏輯。choice(days) * choice(range(1, 25))表示隨機選擇一天,然后將其乘以 1-24 之間的隨機小時數。這意味著您的“天數”會乘以平均約 12 小時,因此它們中的大多數都更接近 last_midnight。
一個更好的方法是
timestamp = last_midnight - (random() * timerange_in_days * 24 *3600) # create the timestamp
由于 random() 給出了 0 和 1 之間的浮點數,因此您可以獲得最早和最晚時期之間的整個范圍。
此外,您不需要last_midnight在回圈內部計算,只需在進入回圈之前執行一次。
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/512087.html