
一、索引簡介
索引通常能夠極大的提高查詢的效率,如果沒有索引,MongoDB在讀取資料時必須掃描集合中的每個檔案并選取那些符合查詢條件的記錄,
1.1 概念
索引最常用的比喻就是書籍的目錄,查詢索引就像查詢一本書的目錄,本質上目錄是將書中一小部分內容資訊(比如題目)和內容的位置資訊(頁碼)共同構成,而由于資訊量小(只有題目),所以我們可以很快找到我們想要的資訊片段,再根據頁碼找到相應的內容,同樣索引也是只保留某個域的一部分資訊(建立了索引的field的資訊),以及對應的檔案的位置資訊,
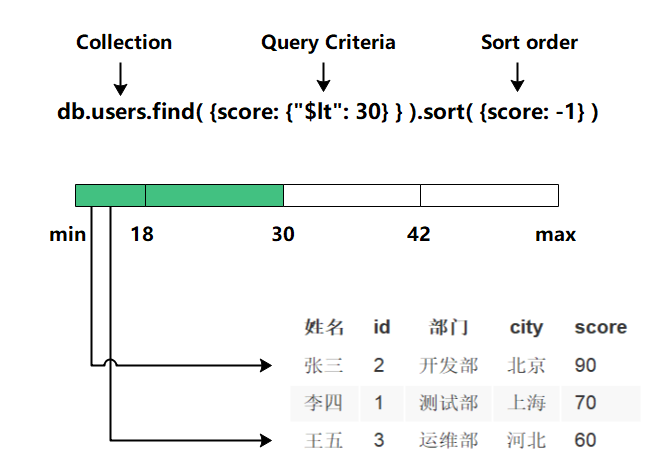
假設我們有如下檔案(每行的資料在MongoDB中是存在于一個Document當中)
| 姓名 | id | 部門 | city | score |
|---|---|---|---|---|
| 張三 | 2 | 開發部 | 北京 | 90 |
| 李四 | 1 | 測驗部 | 上海 | 70 |
| 王五 | 3 | 運維部 | 河北 | 60 |
1.2 索引的作用
假如我們想找id為2的document(即張三的記錄),如果沒有索引,我們就需要掃描整個資料表,然后找出所有id為2的document,當資料表中有大量documents的時候,這個查詢時間就會很長(從磁盤上查找資料還涉及大量的IO操作),
此時建立索引后會有什么變化呢?MongoDB會將id資料拿出來建立索引資料,如下:
| 索引值 | 位置 |
|---|---|
| 1 | 第二行 |
| 2 | 第一行 |
| 3 | 第三行 |
此時,即可根據索引值快速得到原始資料的具體位置,從而獲取完整的原始資料,
1.3 索引的作業原理
這樣我們就可以通過掃描這個小表找到document對應的位置,
查找程序示意圖如下:
索引為什么這么快:
為什么這樣速度會快呢?這主要有幾方面的因素
- 索引資料通過B樹來存盤,從而使得搜索的時間復雜度為O(logdN)級別的(d是B樹的度, 通常d的值比較大,比如大于100),比原先O(N)的復雜度大幅下降,這個差距是驚人的,
- 索引本身是在高速快取當中,相比磁盤IO操作會有大幅的性能提升,(需要注意的是,有的時候資料量非常大的時候,索引資料也會非常大,當大到超出記憶體容量的時候,會導致部分索引資料存盤在磁盤上,這會導致磁盤IO的開銷大幅增加,從而影響性能,所以務必要保證有足夠的記憶體能容下所有的索引資料)
當然,事物總有其兩面性,在提升查詢速度的同時,由于要建立索引,所以寫入操作時就需要額外的添加索引的操作,這必然會影響寫入的性能,所以當有大量寫操作而讀操作比較少的時候,且對讀操作性能不需要考慮的時候,就不適合建立索引,當然,目前大多數互聯網應用都是讀操作遠大于寫操作,因此建立索引很多時候是非常劃算和必要的操作,
二、索引的優化
2.1 執行計劃
MongoDB中的
explain()函式可以幫助我們查看查詢相關的資訊,這有助于我們快速查找到搜索瓶頸進而解決它,我們接下來就看看explain()的一些用法及其查詢結果的含義,
2.1.1 基本用法
先來看一個基本用法:
db.zips.find({"pop":99999}).explain()
直接跟在find()函式后面,表示查看find()函式的執行計劃,結果如下:
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "zips-db.zips",
"indexFilterSet" : false,
"parsedQuery" : {
"pop" : {
"$eq" : 99999
}
},
"queryHash" : "891A44E4",
"planCacheKey" : "2D13A19E",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "linux30",
"port" : 27017,
"version" : "4.4.12",
"gitVersion" : "51475a8c4d9856eb1461137e7539a0a763cc85dc"
},
"ok" : 1
}
回傳結果包含兩大塊資訊,一個是 queryPlanner,即查詢計劃,還有一個是 serverInfo,即MongoDB服務的一些資訊,
2.1.2 引數解釋
那么這里涉及到的引數比較多,我們來一一看一下:
| 引數 | 含義 |
|---|---|
| plannerVersion | 查詢計劃版本 |
| namespace | 要查詢的集合 |
| indexFilterSet | 是否使用索引 |
| parsedQuery | 查詢條件,此處為x=1 |
| winningPlan | 最佳執行計劃 |
| stage | 查詢方式,常見的有COLLSCAN/全表掃描、IXSCAN/索引掃描、FETCH/根據索引去檢索檔案、SHARD_MERGE/合并分片結果、IDHACK/針對_id進行查詢 |
| filter | 過濾條件 |
| direction | 搜索方向 |
| rejectedPlans | 拒絕的執行計劃 |
| serverInfo | MongoDB服務器資訊 |
2.1.3 添加引數
explain()也接收不同的引數,通過設定不同引數我們可以查看更詳細的查詢計劃,
- queryPlanner
是默認引數,添加queryPlanner引數的查詢結果就是我們勺ò復到的查詢結果,這里不再贅述,
- executionStats
會回傳最佳執行計劃的一些統計資訊,如下:
db.zips.find({"pop":99999}).explain("executionStats")
我們發現增加了一個executionStats的欄位列的資訊
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "zips-db.zips",
"indexFilterSet" : false,
"parsedQuery" : {
"pop" : {
"$eq" : 99999
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
}
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 0,
"executionTimeMillis" : 1,
"totalKeysExamined" : 0,
"totalDocsExamined" : 0,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"docsExamined" : 0,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 1,
"advanced" : 0,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"keyPattern" : {
"pop" : 1
},
"indexName" : "pop_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"pop" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : true,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"pop" : [
"[99999.0, 99999.0]"
]
},
"keysExamined" : 0,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
},
"serverInfo" : {
"host" : "linux30",
"port" : 27017,
"version" : "4.4.12",
"gitVersion" : "51475a8c4d9856eb1461137e7539a0a763cc85dc"
},
"ok" : 1
}
這里除了我們上文介紹到的一些引數之外,還多了executionStats引數,含義如下:
| 引數 | 含義 |
|---|---|
| executionSuccess | 是否執行成功 |
| nReturned | 回傳的結果數 |
| executionTimeMillis | 執行耗時 |
| totalKeysExamined | 索引掃描次數 |
| totalDocsExamined | 檔案掃描次數 |
| executionStages | 這個分類下描述執行的狀態 |
| stage | 掃描方式,具體可選值與上文的相同 |
| nReturned | 查詢結果數量 |
| executionTimeMillisEstimate | 預估耗時 |
| works | 作業單元數,一個查詢會分解成小的作業單元 |
| advanced | 優先回傳的結果數 |
| docsExamined | 檔案檢查數目,與totalDocsExamined一致 |
allPlansExecution:用來獲取所有執行計劃,結果引數基本與上文相同,
2.2 慢查詢
在MySQL中,慢查詢日志是經常作為我們優化查詢的依據,那在MongoDB中是否有類似的功能呢?答案是肯定的,那就是開啟Profiling功能,該工具在運行的實體上收集有關MongoDB的寫操作,游標,資料庫命令等,可以在資料庫級別開啟該工具,也可以在實體級別開啟,該工具會把收集到的所有都寫入到system.profile集合中,該集合是一個capped collection,
2.2.1 慢查詢分析流程
慢查詢日志一般作為優化步驟里的第一步,通過慢查詢日志,定位每一條陳述句的查詢時間,比如超過了200ms,那么查詢超過200ms的陳述句需要優化,然后它通過 explain() 決議影響行數是不是過大,所以導致查詢陳述句超過200ms,
所以優化步驟一般就是:
- 用慢查詢日志(system.profile)找到超過200ms的陳述句
- 然后再通過explain()決議影響行數,分析為什么超過200ms
- 決定是不是需要添加索引
2.2.2 開啟慢查詢
Profiling級別
0:關閉,不收集任何資料,
1:收集慢查詢資料,默認是100毫秒,
2:收集所有資料
資料庫設定
登錄需要開啟慢查詢的資料庫
use zips-db
查看慢查詢狀態
db.getProfilingStatus()
設定慢查詢級別
db.setProfilingLevel(2)
如果不需要收集所有慢日志,只需要收集小于100ms的慢日志可以使用如下命令
db.setProfilingLevel(1,200)
注意:
- 以上操作要是在test集合下面的話,只對該集合里的操作有效,要是需要對整個實體有效,則需要在所有的集合下設定或在開啟的時候開啟引數,
- 每次設定之后回傳給你的結果是修改之前的狀態(包括級別、時間引數),
全域設定
在mongoDB啟動的時候加入如下引數
mongod --profile=1 --slowms=200
或在組態檔里添加2行:
profile = 1
slowms = 200
這樣就可以針對所有資料庫進行監控慢日志了
關閉Profiling
使用如下命令可以關閉慢日志
db.setProfilingLevel(0)
2.2.3 Profile 效率
Profiling功能肯定是會影響效率的,但是不太嚴重,原因是其使用的system.profile 來記錄,而system.profile 是一個capped collection, 這種collection 在操作上有一些限制和特點,但是效率更高,
2.2.4 慢查詢分析
通過 db.system.profile.find() 查看當前所有的慢查詢日志
db.system.profile.find()
引數含義:
{
"op" : "query", #操作型別,有insert、query、update、remove、getmore、command
"ns" : "onroad.route_model", #操作的集合
"query" : {
"$query" : {
"user_id" : 314436841,
"data_time" : {
"$gte" : 1436198400
}
},
"$orderby" : {
"data_time" : 1
}
},
"ntoskip" : 0, #指定跳過skip()方法 的檔案的數量,
"nscanned" : 2, #為了執行該操作,MongoDB在 index 中瀏覽的檔案數, 一般來說,如果 nscanned 值高于 nreturned 的值,說明資料庫為了找到目標檔案掃描了很多檔案,這時可以考慮創建索引來提高效率,
"nscannedObjects" : 1, #為了執行該操作,MongoDB在 collection中瀏覽的檔案數,
"keyUpdates" : 0, #索引更新的數量,改變一個索引鍵帶有一個小的性能開銷,因為資料庫必須洗掉舊的key,并插入一個新的key到B-樹索引
"numYield" : 1, #該操作為了使其他操作完成而放棄的次數,通常來說,當他們需要訪問還沒有完全讀入記憶體中的資料時,操作將放棄,這使得在MongoDB為了放棄操作進行資料讀取的同時,還有資料在記憶體中的其他操作可以完成
"lockStats" : { #鎖資訊,R:全域讀鎖;W:全域寫鎖;r:特定資料庫的讀鎖;w:特定資料庫的寫鎖
"timeLockedMicros" : { #該操作獲取一個級鎖花費的時間,對于請求多個鎖的操作,比如對 local 資料庫鎖來更新 oplog ,該值比該操作的總長要長(即 millis )
"r" : NumberLong(1089485),
"w" : NumberLong(0)
},
"timeAcquiringMicros" : { #該操作等待獲取一個級鎖花費的時間,
"r" : NumberLong(102),
"w" : NumberLong(2)
}
},
"nreturned" : 1, // 回傳的檔案數量
"responseLength" : 1669, // 回傳位元組長度,如果這個數字很大,考慮值回傳所需欄位
"millis" : 544, #消耗的時間(毫秒)
"execStats" : { #一個檔案,其中包含執行 查詢 的操作,對于其他操作,這個值是一個空檔案, system.profile.execStats 顯示了就像樹一樣的統計結構,每個節點提供了在執行階段的查詢操作情況,
"type" : "LIMIT", ##使用limit限制回傳數
"works" : 2,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 1, #是否為檔案結束符
"children" : [
{
"type" : "FETCH", #根據索引去檢索指定document
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"alreadyHasObj" : 0,
"forcedFetches" : 0,
"matchTested" : 0,
"children" : [
{
"type" : "IXSCAN", #掃描索引鍵
"works" : 1,
"yields" : 1,
"unyields" : 1,
"invalidates" : 0,
"advanced" : 1,
"needTime" : 0,
"needFetch" : 0,
"isEOF" : 0,
"keyPattern" : "{ user_id: 1.0, data_time: -1.0 }",
"boundsVerbose" : "field #0['user_id']: [314436841, 314436841], field #1['data_time']: [1436198400, inf.0]",
"isMultiKey" : 0,
"yieldMovedCursor" : 0,
"dupsTested" : 0,
"dupsDropped" : 0,
"seenInvalidated" : 0,
"matchTested" : 0,
"keysExamined" : 2,
"children" : [ ]
}
]
}
]
},
"ts" : ISODate("2015-10-15T07:41:03.061Z"), #該命令在何時執行
"client" : "10.10.86.171", #鏈接ip或則主機
"allUsers" : [
{
"user" : "martin_v8",
"db" : "onroad"
}
],
"user" : "martin_v8@onroad"
}
分析:
如果發現 millis 值比較大,那么就需要作優化,
- 如果nscanned數很大,或者接近記錄總數(檔案數),那么可能沒有用到索引查詢,而是全表掃描,
- 如果 nscanned 值高于 nreturned 的值,說明資料庫為了找到目標檔案掃描了很多檔案,這時可以考慮創建索引來提高效率,
system.profile補充:
‘type’的回傳引數說明
COLLSCAN #全表掃描
IXSCAN #索引掃描
FETCH #根據索引去檢索指定document
SHARD_MERGE #將各個分片回傳資料進行merge
SORT #表明在記憶體中進行了排序(與老版本的scanAndOrder:true一致)
LIMIT #使用limit限制回傳數
SKIP #使用skip進行跳過
IDHACK #針對_id進行查詢
SHARDING_FILTER #通過mongos對分片資料進行查詢
COUNT #利用db.coll.explain().count()之類進行count運算
COUNTSCAN #count不使用Index進行count時的stage回傳
COUNT_SCAN #count使用了Index進行count時的stage回傳
SUBPLA #未使用到索引的$or查詢的stage回傳
TEXT #使用全文索引進行查詢時候的stage回傳
PROJECTION #限定回傳欄位時候stage的回傳
對于普通查詢,我們最希望看到的組合有這些
Fetch+IDHACK
Fetch+ixscan
Limit+(Fetch+ixscan)
PROJECTION+ixscan
SHARDING_FILTER+ixscan
不希望看到包含如下的type
COLLSCAN(全表掃),SORT(使用sort但是無index),不合理的SKIP,SUBPLA(未用到index的$or)
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/513006.html
標籤:其他
下一篇:分治的理解