記錄第一次搭建Hadoop集群,
使用版本:
- Ubuntu:ubuntu-20.04.5-desktop-amd64.iso
- Hadoop:hadoop-2.7.5.tar.gz
對vim 的基本命令:
- 進入編輯狀態:insert
- 洗掉:delete
- 退出編輯狀態:ctrl+[
- 進入保存狀態:ctrl+]
- 保存并退出:" :wq " 注意先輸入英文狀態下冒號
- 不保存退出:" :q! " 同上
準備虛擬機
網上教程很多,可以隨便參考一個,搭建自己的Ubuntu虛擬機,然后使用克隆,一共準備三臺虛擬機
修改主機名

用戶名@主機名
克隆的三臺服務器用戶名主機名都是相同的,我們需要修改其主機名,可以分別設定為master、slave01、slave02.(隨意即可,我的是serendipity、slave01、slave02,方便起見,后面都采用我自己的命名方法)
sudo vim /etc/hostname
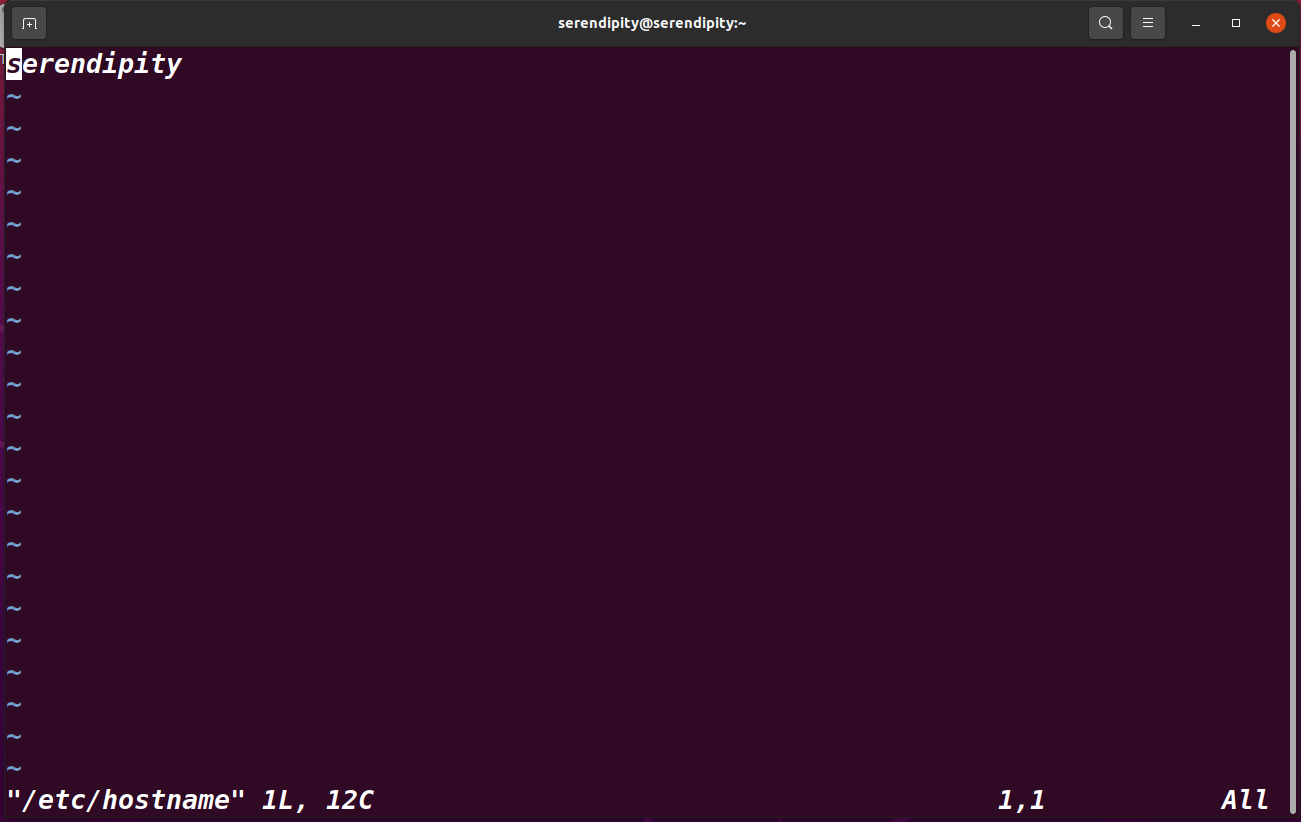
第一行就是本機主機名資訊,將三臺主機分別修改為對應的serendipity、slave01、slave02,進行保存,對虛擬機重啟后即可生效,
ping 通三臺主機
首先記錄三臺主機的ip地址,(可以自己設定靜態ip,也可直接進行操作)
ifconfig
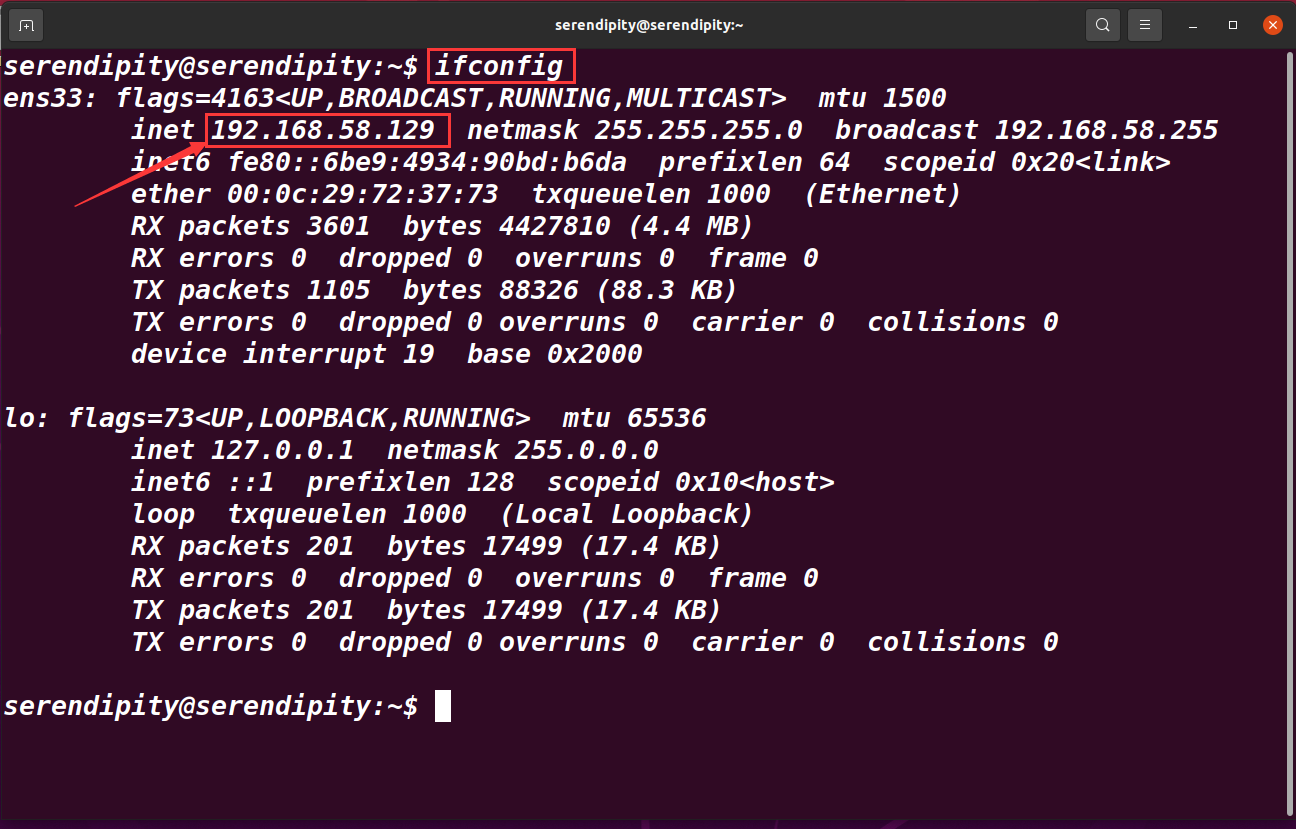
記錄三臺主機
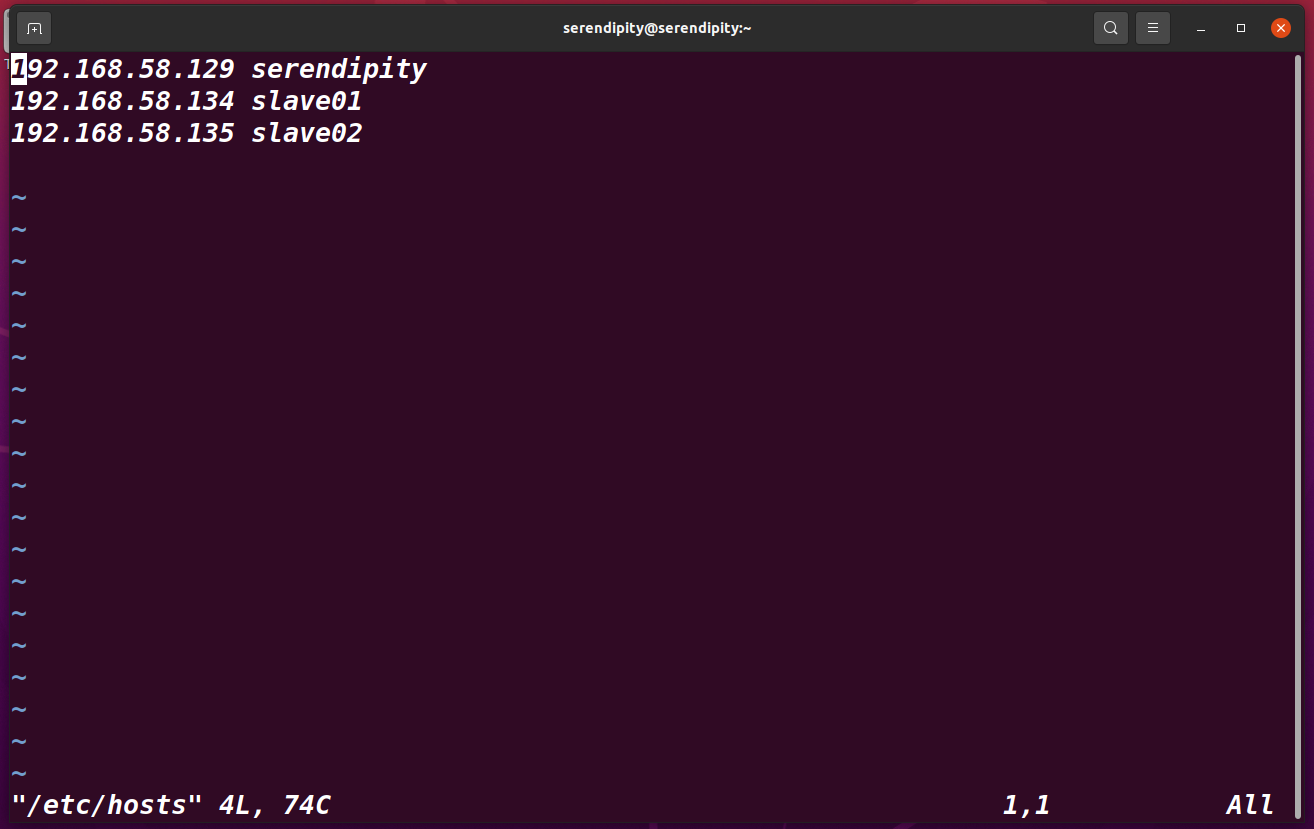
192.168.58.129 serendipity
192.168.58.134 slave01
192.168.58.135 slave02
分別三臺主機,設定節點IP映射
sudo vim /etc/hosts
本來上面一串東西,可以都刪掉,
ping 測驗
ping IP地址
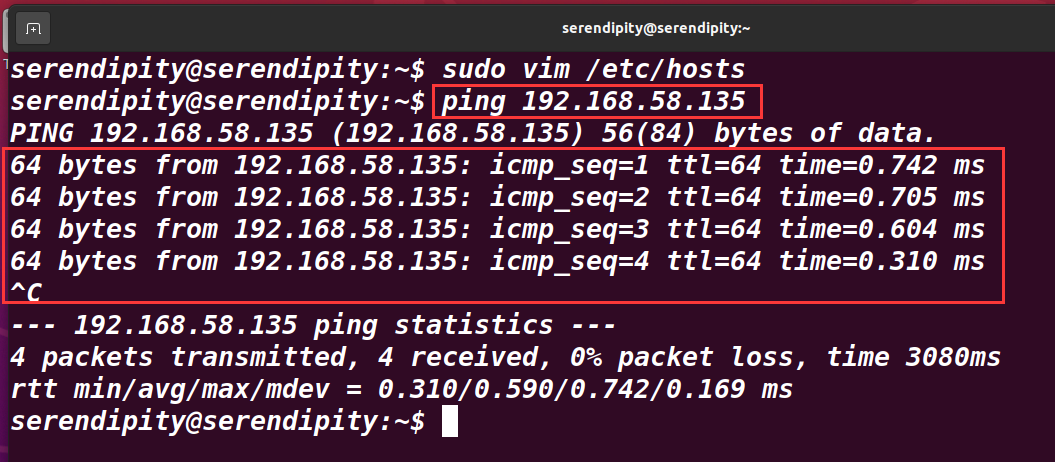
出現下面矩形框,便是成功,分別再三臺主機進行測驗
ssh免密
基礎準備
安裝ssh
sudo apt-get install openssh-server #安裝服務,一路回車
sudo /etc/init.d/ssh restart #啟動服務
sudo ufw disable #關閉防火墻,不然后面會出現很多奇妙的bug
查看是否開通ssh服務
ps -e | grep ssh

如上即可:
設定免密登錄
-
再serendipity節點生成SSH公鑰
cd ~/.ssh # 如果沒有該目錄,先執行一次ssh localhost rm ./id_rsa* # 洗掉之前生成的公匙(如果有) ssh-keygen -t rsa # 一直按回車就可以 -
讓 serensipity可以免密ssh本機
cat ./id_rsa.pub >> ./authorized_keys -
完成后可以驗證一下
ssh serendipity
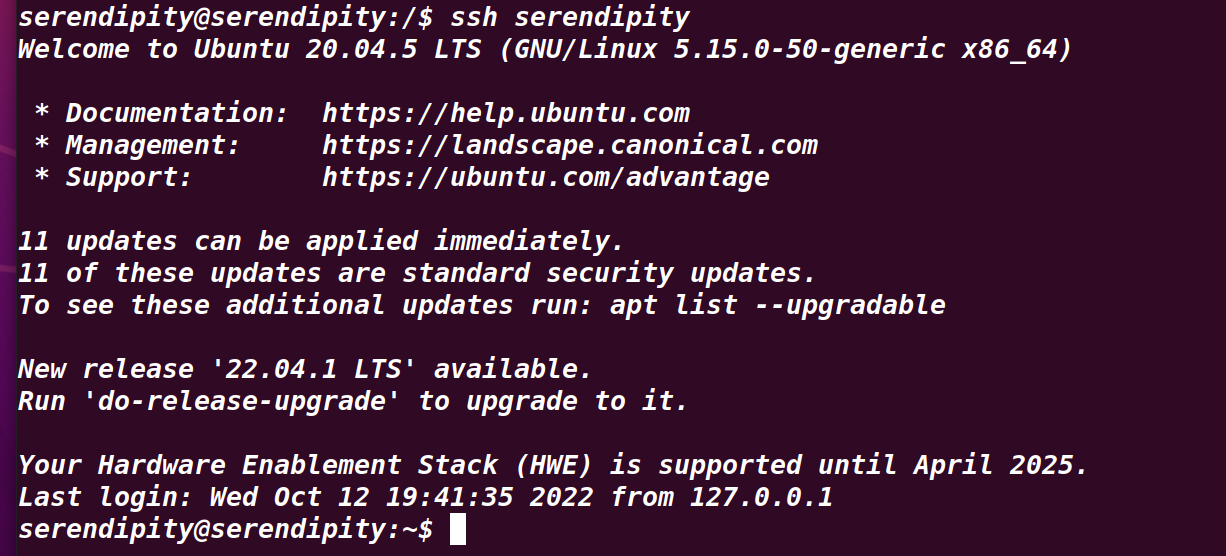
不需輸入密碼即為成功,輸入exit回傳原終端
-
將serendipity節點將公鑰傳輸到slave01節點,需要密碼就將密碼輸入即可,@前后就是你的終端顯式的東西,用戶名@主機名
scp ~/.ssh/id_rsa.pub serendipity@slave01:/home/serendipity -
再slave01節點將公鑰加入授權
mkdir ~/.ssh # 如果不存在該檔案夾需先創建,若已存在則忽略 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys rm ~/id_rsa.pub # 用完就可以刪掉了 -
slave02也重復上述節點,主機節點可以免密登錄兩個節點即可
安裝配置Hadoop
建議使用推薦的版本,高版本的可能組態檔與下列描述有所出入,
下載地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.5/
jdk8
先去安裝一下jdk8.
下載安裝
建議再外部主機下載,虛擬機下載網路很慢,下載結束后使用Xftp 或者只用Vmware 安裝VMware tools后直接拖拽入虛擬機,
將軟體再一個合適的目錄解壓,(作為linux小白,不太懂 local 、opt的作用啥的,就自己建了一個hadoop檔案夾)
進入壓縮包所在檔案目錄內,執行解壓命令
tar -zxvf hadoop-2.7.5.tar.gz
或者后等待解壓完成,完成后會再同級目錄下創建名為hadoop-2.7.5檔案夾,
將其修改檔案夾名為 hadoop,這就是hadoop安裝目錄
mv hadoop-2.7.5 hadoop
進入安裝目錄,查看安裝檔案,如圖所示
修改組態檔,進入安裝目錄內的 etc 下的 hadoop 檔案夾
cd etc/hadoop/

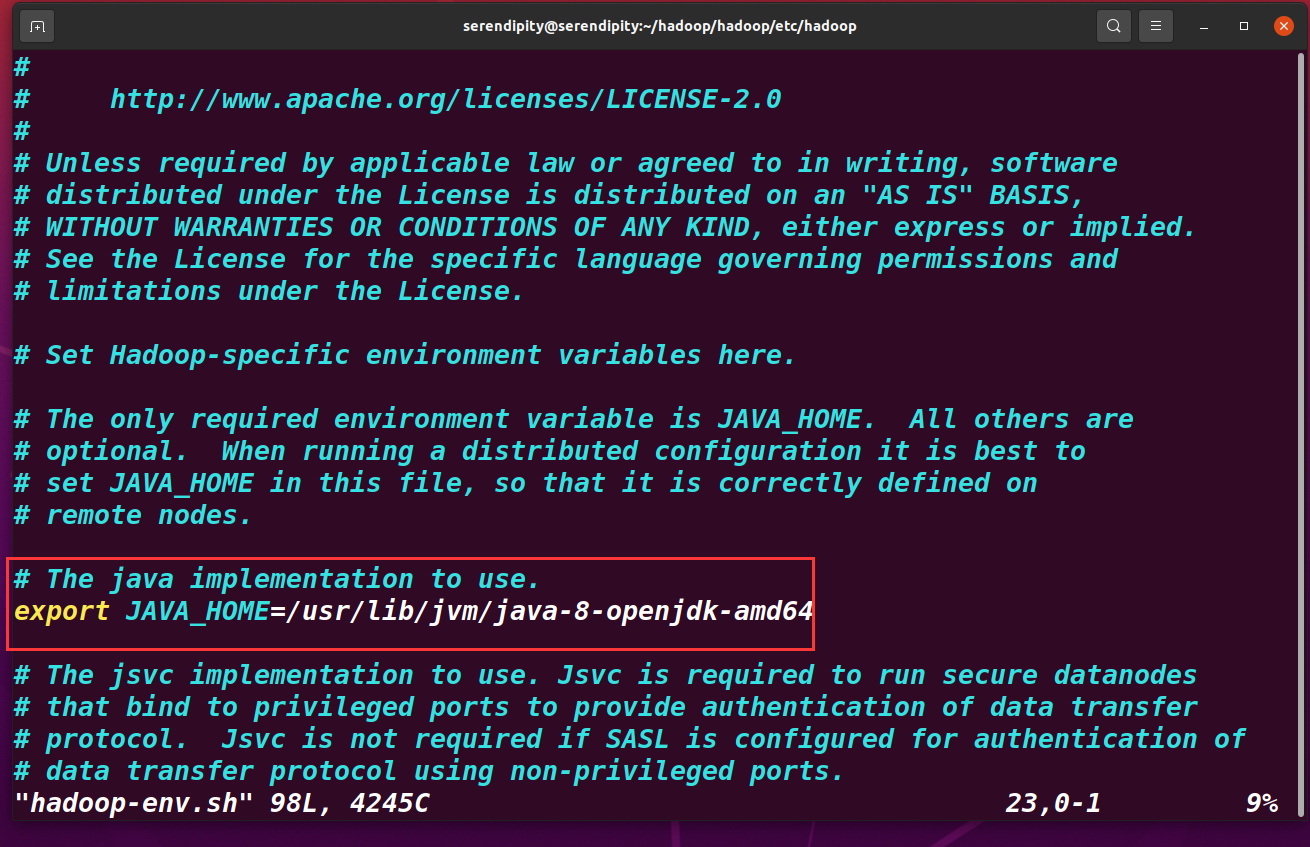
hadoop-env.sh
sudo vim hadoop-env.sh
再檔案較前地方有
export JAVA_HOME=${JAVA_HOME}
等號后面修改為 你的 JDK 安裝目錄,
yarn-env.sh
sudo vim yarn-env.sh
再較前面,有個
#export JAVA_HOME=/home/y/libexec/jdk1.6.0
將# 去掉,后面改為你的java安裝目錄
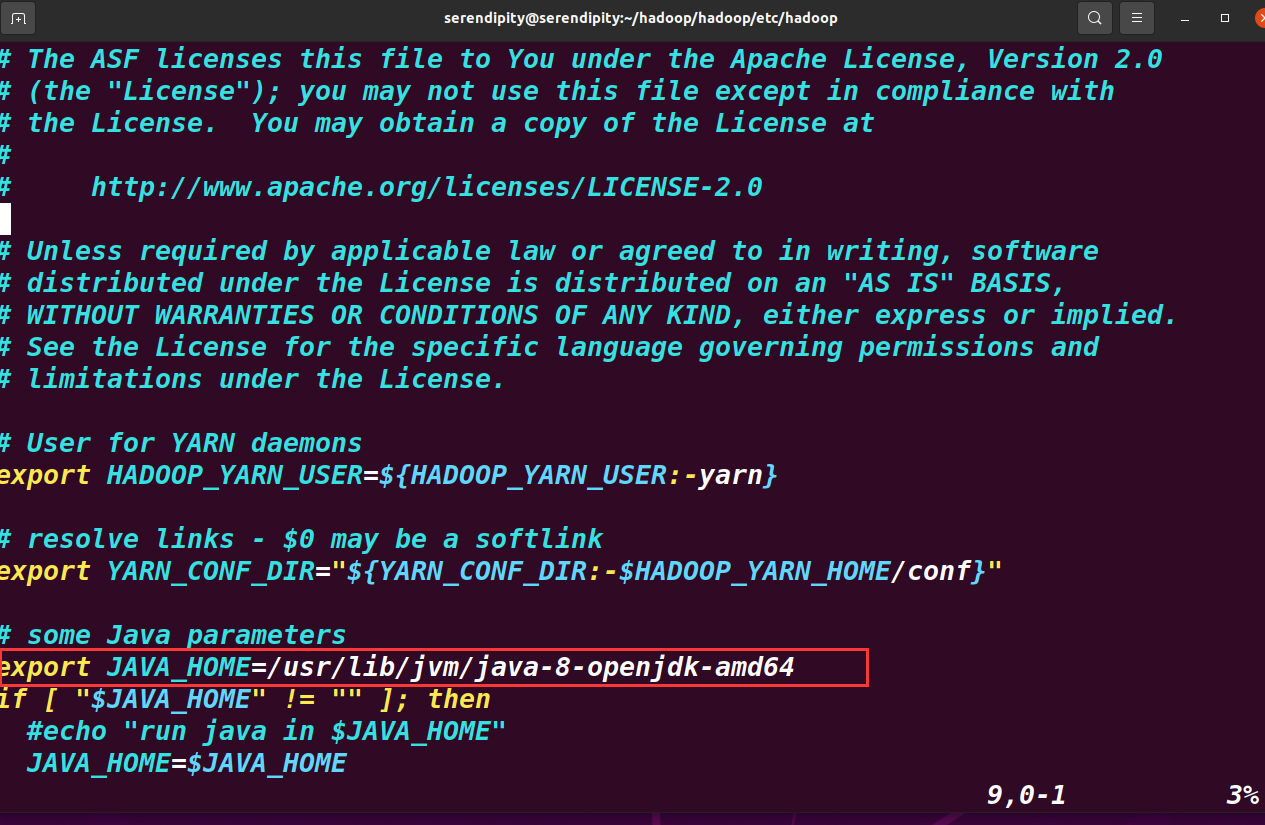
核心組件 core-site.xml
設定namenode的地址、指定使用Hadoop時臨時檔案的存放路徑等資訊
sudo vim core-site.xml
再configuration內部添加如下資訊
<property>
<name>fs.defaultFS</name>
<value>hdfs://serendipity:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/serendipity/hadoop/hadoopdata</value>
</property>
其中,hdfs://serendipity:9000 中 serendipity是主機名,可以修改為自己的主機名
/home/serendipity/hadoop/hadoopdata是指定存放資料資訊的檔案夾,可以自己創建一個檔案夾,將其全路徑放在這里,
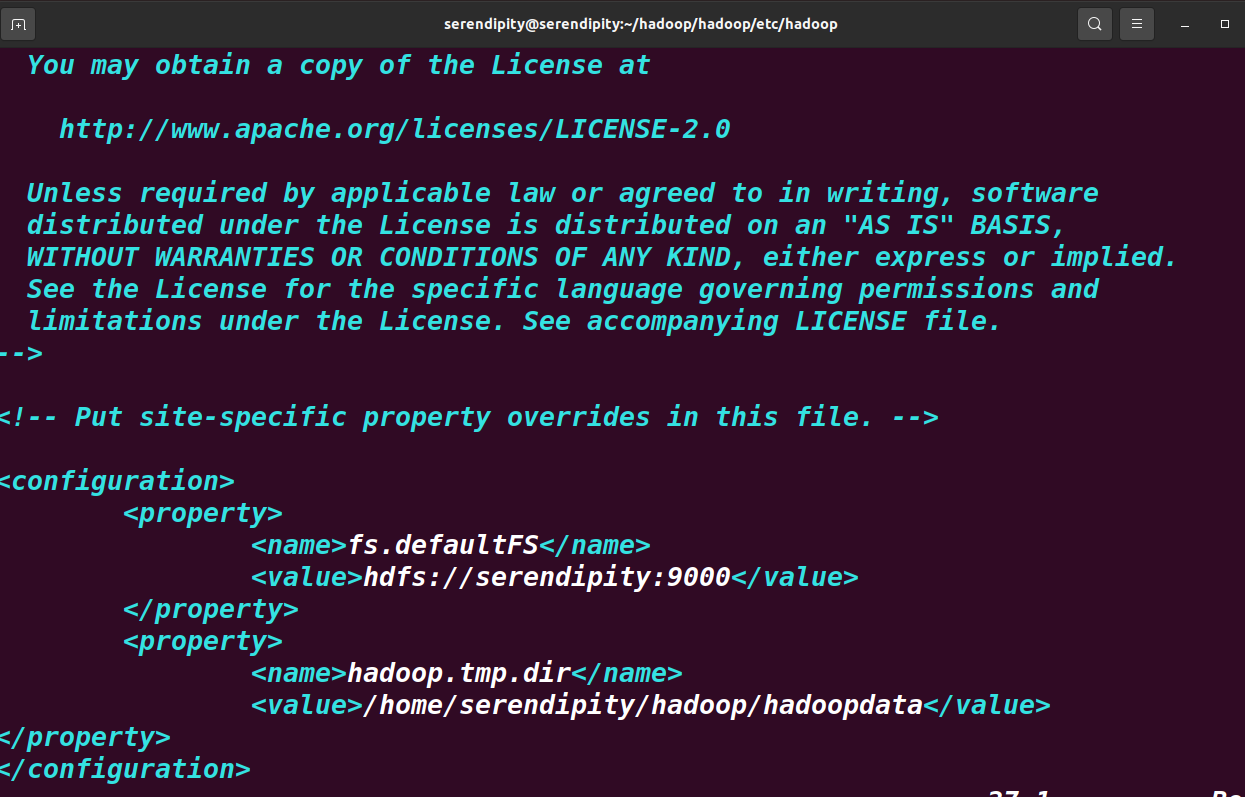
檔案系統 hdfs-site.xml
配置分布式檔案系統HDFS的屬性,包括指定HDFS保存資料的副本數了,指定HDFS中NameNode、DataNode節點的存盤位置
sudo vim hdfs-site.xml
將下面資訊加入configuration內部
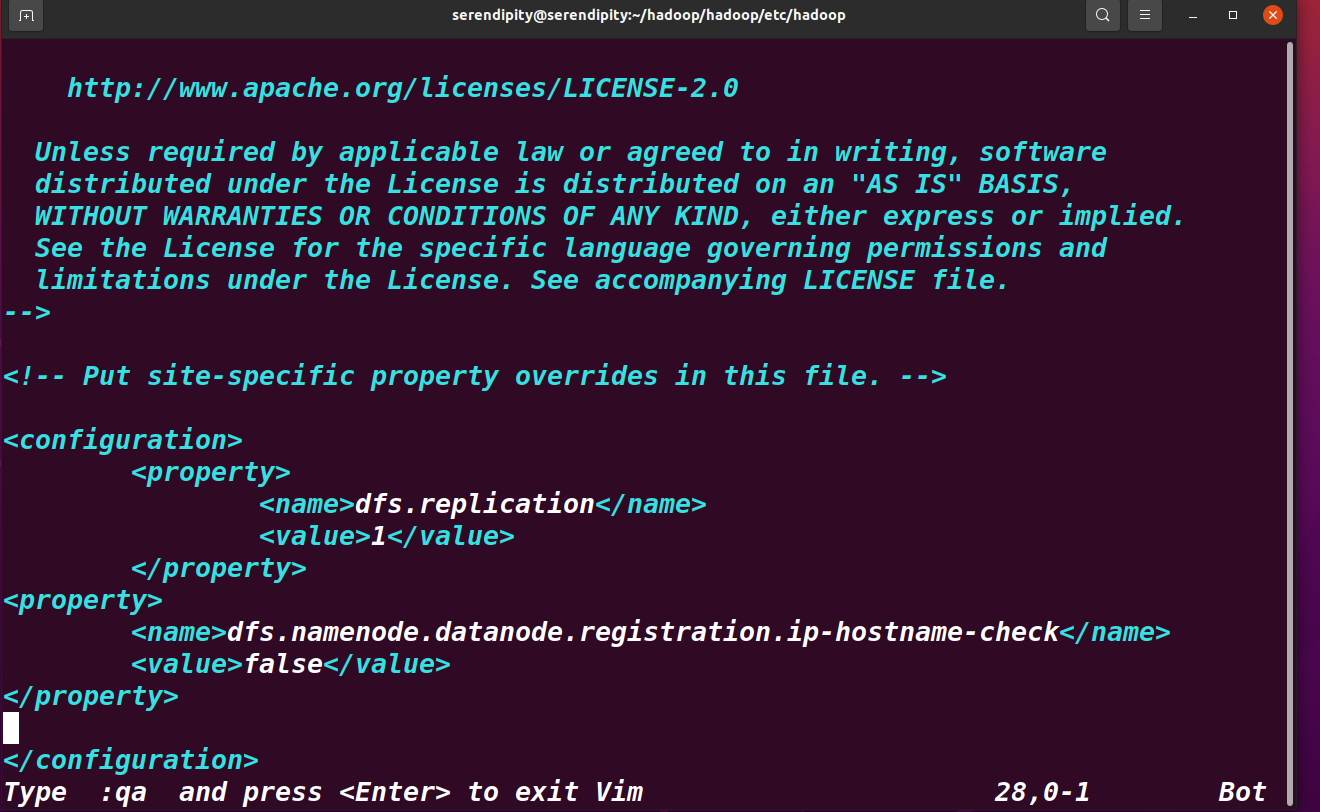
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
dfs.replication 為執行副本數量
檔案系統 yarn-site.xml
yarn是mapreduce的調度框架,
sudo vim yarn-site.xml
將下列資訊加入configuration內部,資訊不用改,直接抄
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>serendipity:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>serendipity:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>serendipity:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>serendipity:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>serendipity:18088</value>
</property>
計算框架 mapred-site.xml
使用cp命令將 mapred-site.xml.template 復制一份為 mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
打開 mapred-site.xml 檔案
sudo vim mapred-site.xml
將下列資訊加入configuration內部
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
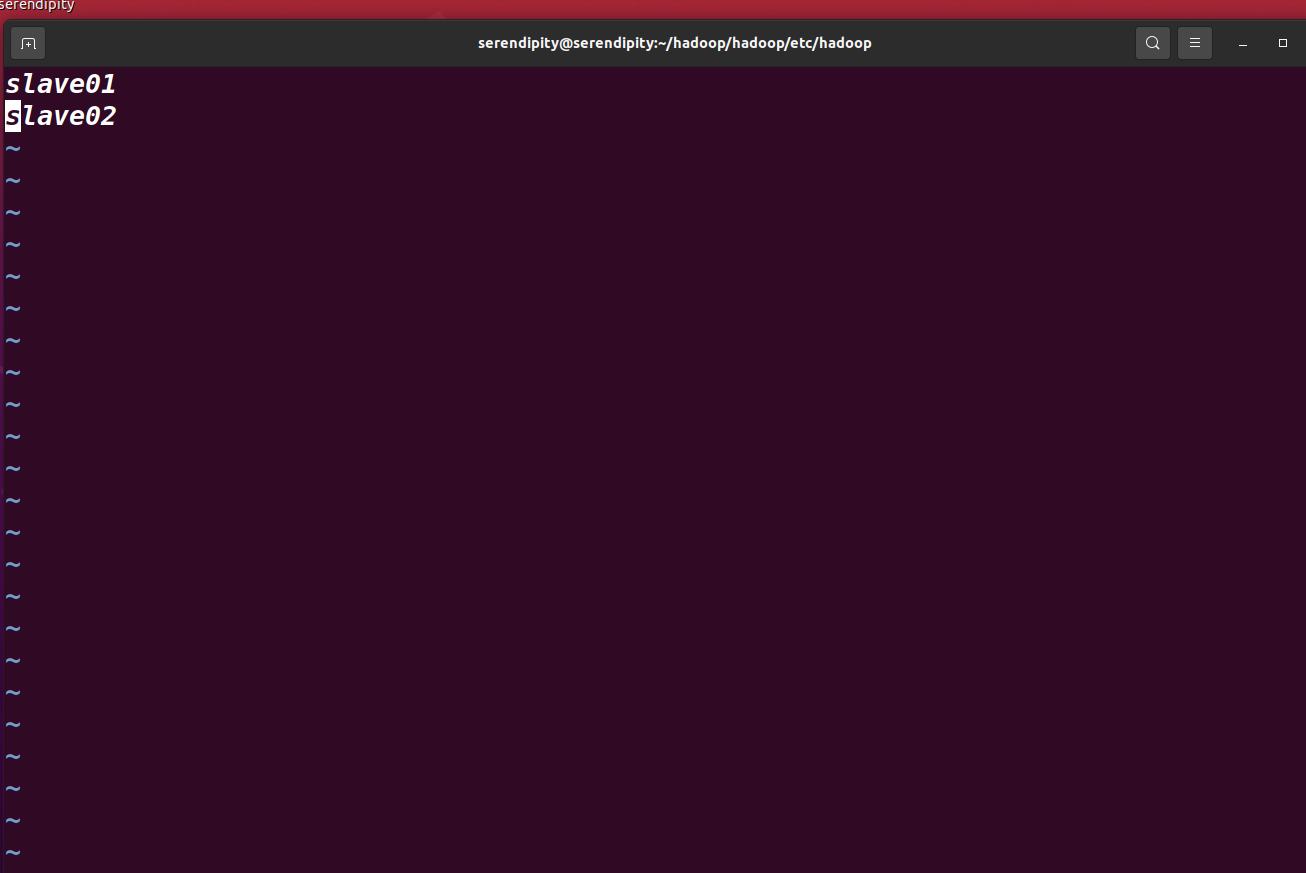
slaves
配置啟動的從機
sudo vim slaves
再內部鍵入你需要啟動的從機的主機名,我只有兩個從機,slave01,slave02.所以就寫了這兩個
將配置的所有hadoop資訊復制到從機
scp -r hadoop/hadoop serendipity@slave01:/home/serendipity/hadoop/hadoop
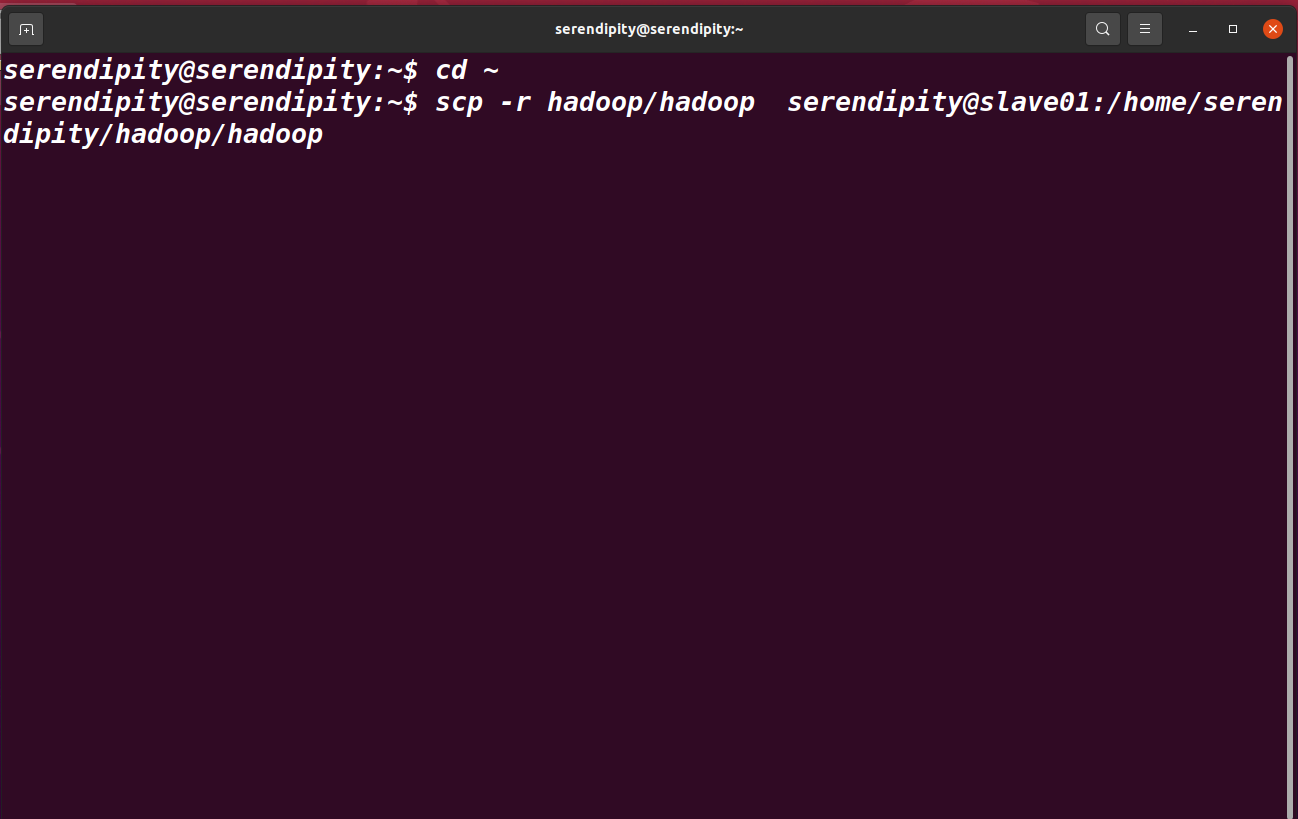
不確定的話,可以將上述安裝配置Hadoop的流程,再從機上全部重復一遍,都是一樣的操作,
配置環境變數
打開 etc/profile檔案
sudo vim /etc/profile
將下面代碼追加到檔案末尾
export HADOOP_HOME=/home/serendipity/hadoop/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP/sbin
執行命令,激活配置
source /etc/profile
至此,Hadoop安裝與配置完畢,
啟動Hadoop集群
格式化檔案系統
hdfs namenode -format
啟動Hadoop集群
將路徑切到hadoop安裝目錄
cd hadoop/hadoop
啟動集群
sbin/start-all.sh
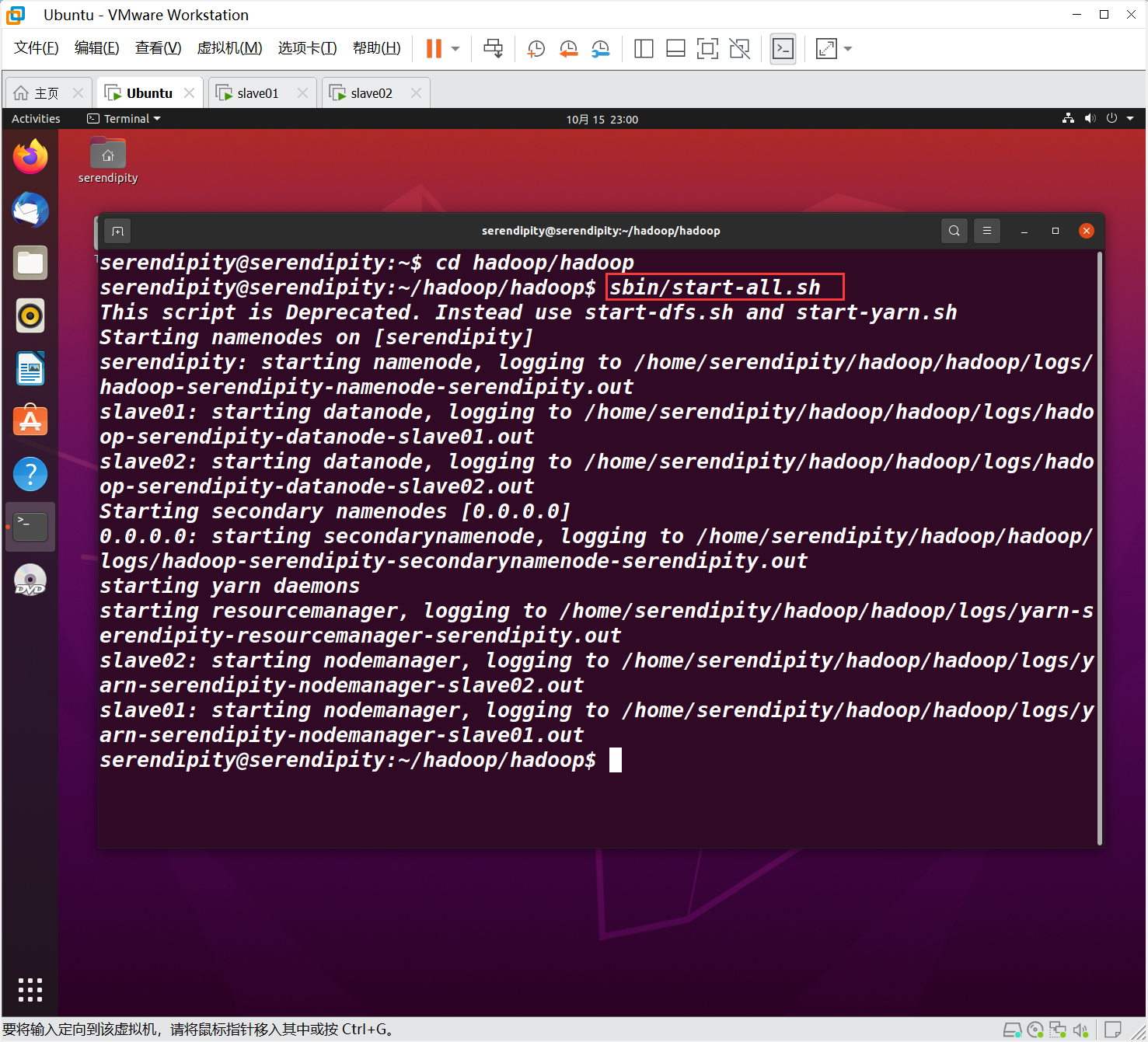
查看Hadoop是否正常啟動
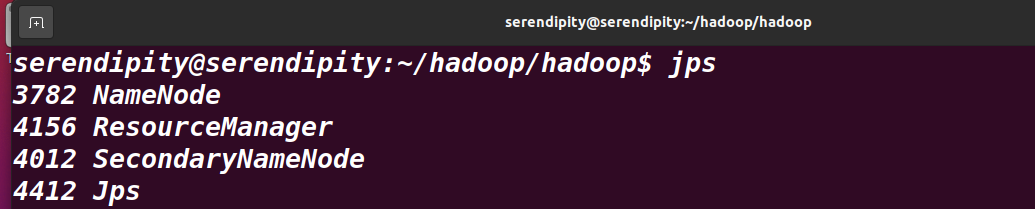
在serendipity 執行 jps命令
jps # 查看java行程:java process status??? 可能吧 不知道,
在slave01、slave02執行jps命令
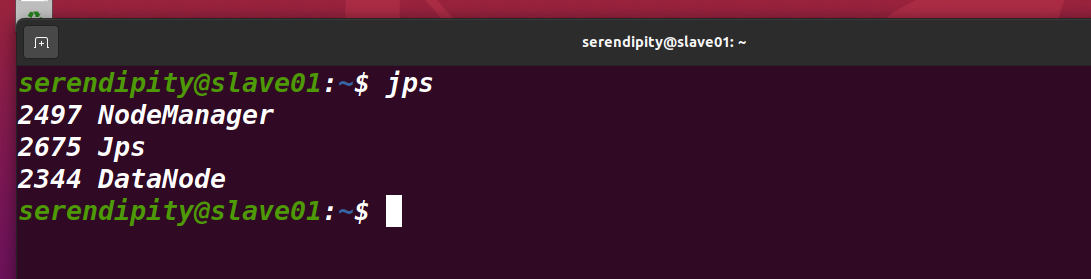
分別如圖所示,即Hadoop集群節點已正式啟動
在serendipity 查看集群資訊
bin/hadoop dfsadmin -report
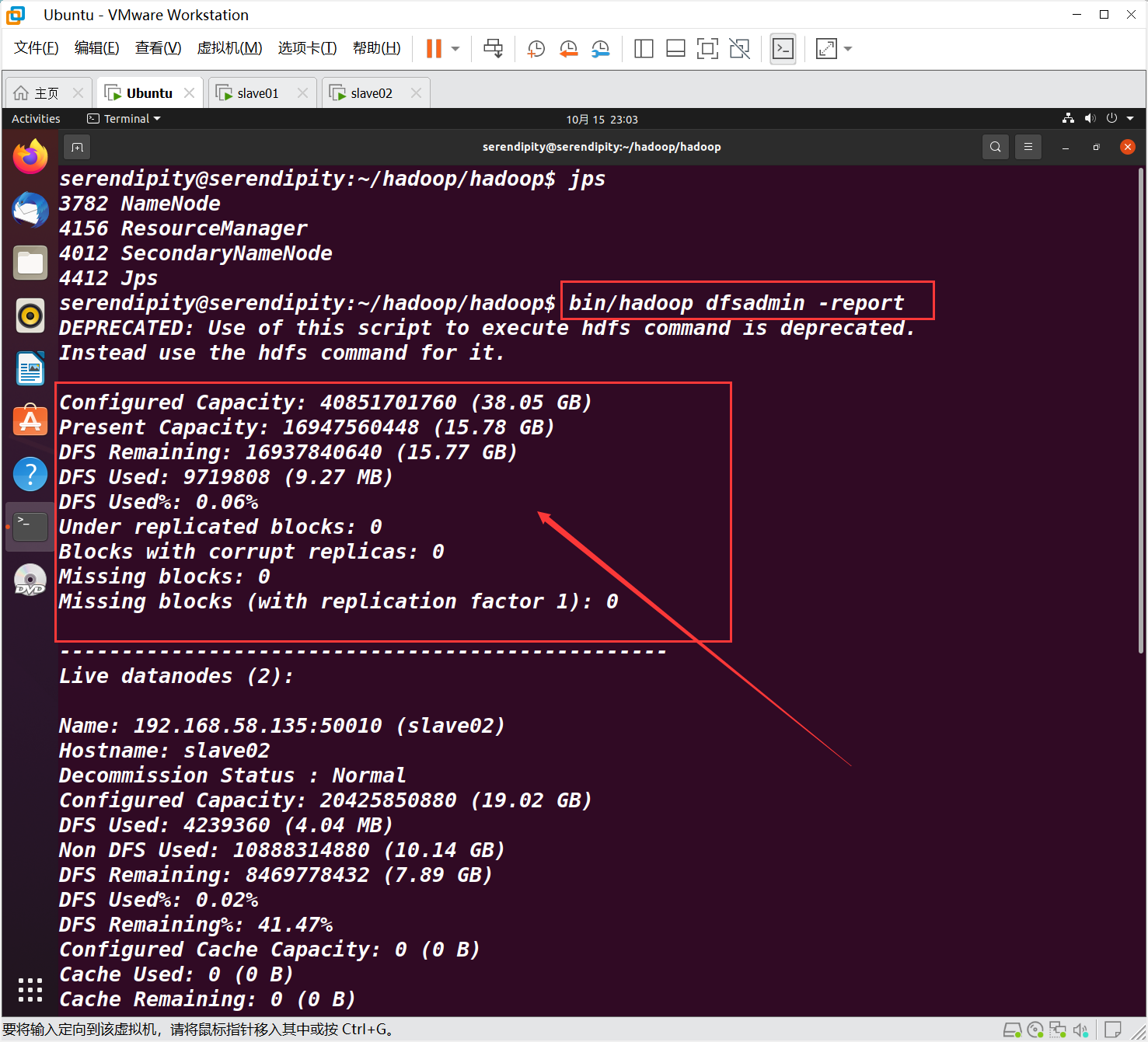
箭頭所指區域不全為0 即為正常,
使用web查看集群是否正常,在瀏覽器地址欄輸入:http://serendipity:50070,檢查namenode和datanode是否正常
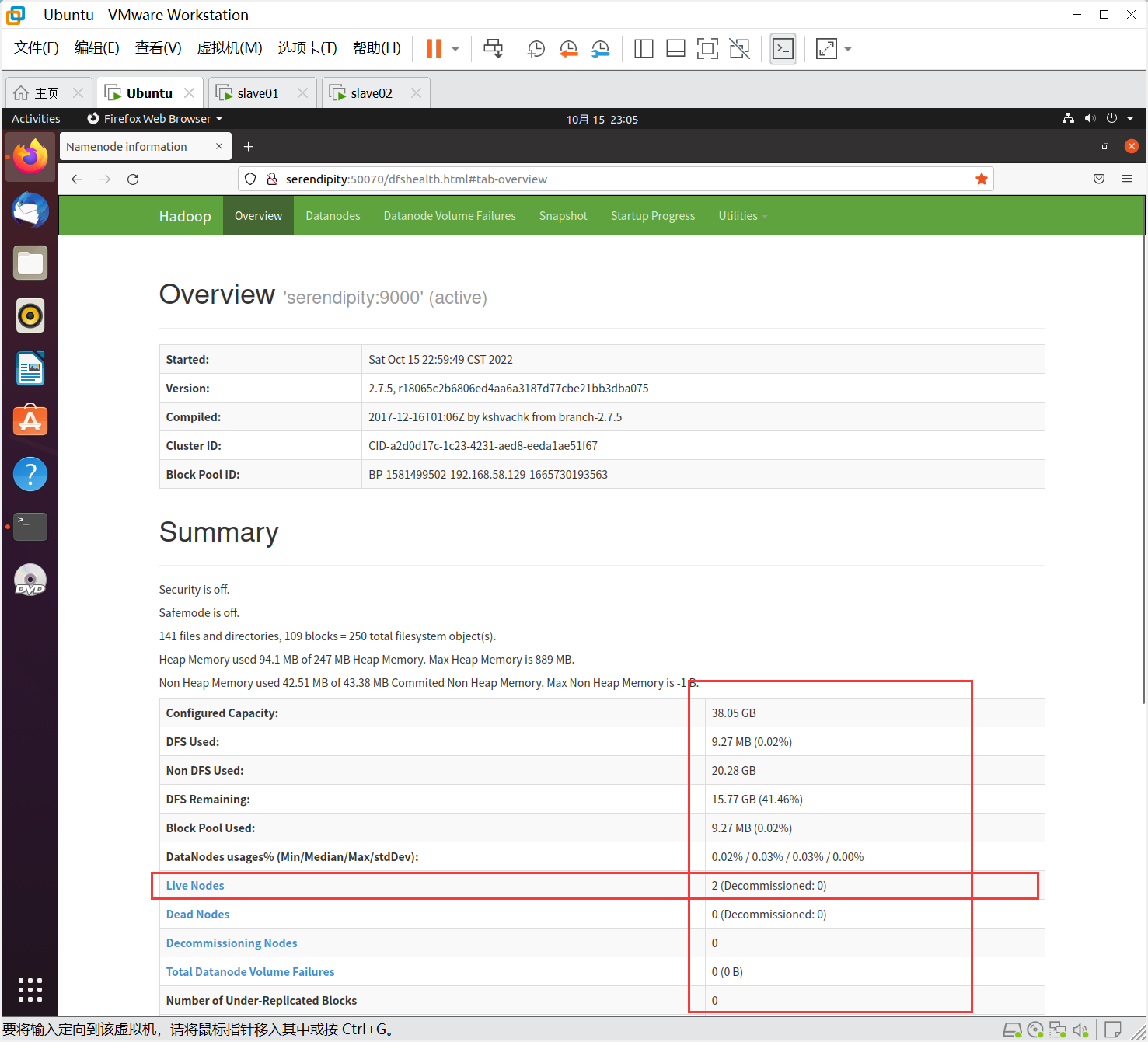
全為0,即集群不是正常狀態,尤其是live Nodes節點,一般有幾個機器有datanode節點,這里就應該是幾,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/514274.html
標籤:Java
下一篇:結合springboot條件注入@ConditionalOnProperty以及@ConfigurationProperties來重構優化代碼