持續創作,加速成長!這是我參與「掘金日新計劃 · 10 月更文挑戰」的第5天,點擊查看活動詳情
思考:HashTable是執行緒安全的,為什么不推薦使用?
HashTable是一個執行緒安全的類,它使用synchronized來鎖住整張Hash表來實作執行緒安全,即每次鎖住整張表讓執行緒獨占,相當于所有執行緒進行讀寫時都去競爭一把鎖,導致效率非常低下,
1 ConcurrentHashMap 1.7
在JDK1.7中ConcurrentHashMap采用了陣列+分段鎖的方式實作,
Segment(分段鎖)-減少鎖的粒度
ConcurrentHashMap中的分段鎖稱為Segment,它即類似于HashMap的結構,即內部擁有一個Entry陣列,陣列中的每個元素又是一個鏈表,同時又是一個ReentrantLock(Segment繼承了ReentrantLock),
1.存盤結構
Java 7 版本 ConcurrentHashMap 的存盤結構如圖:
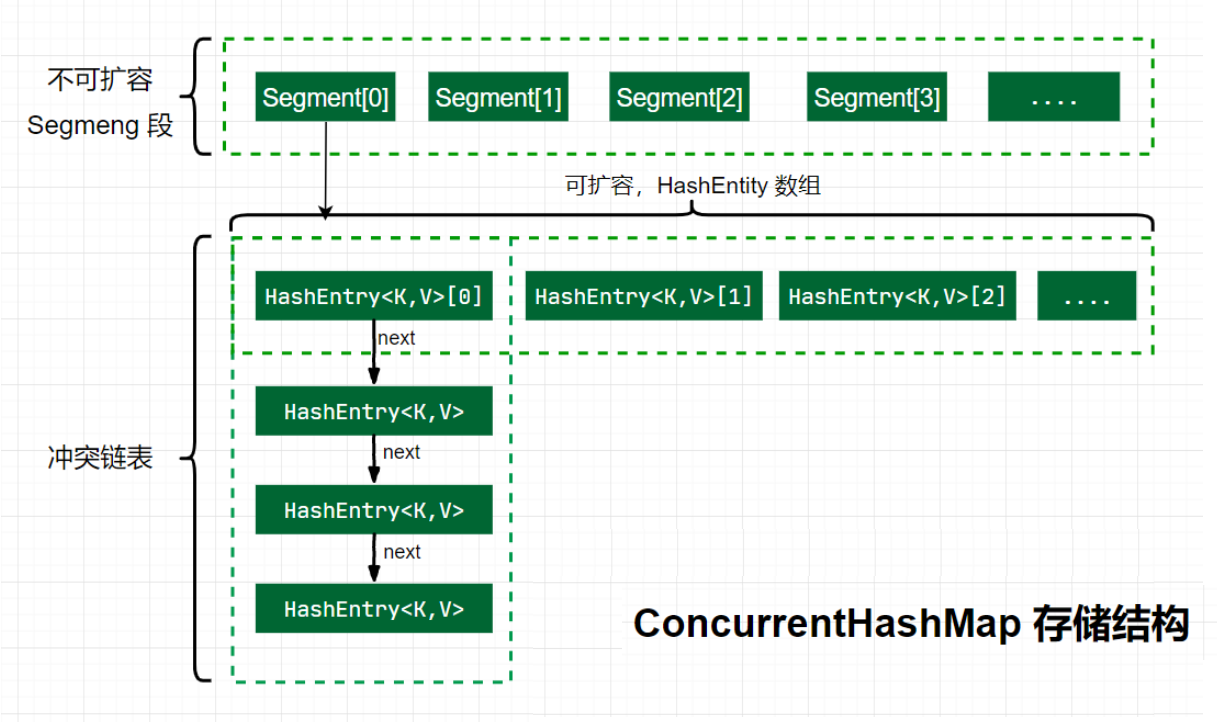
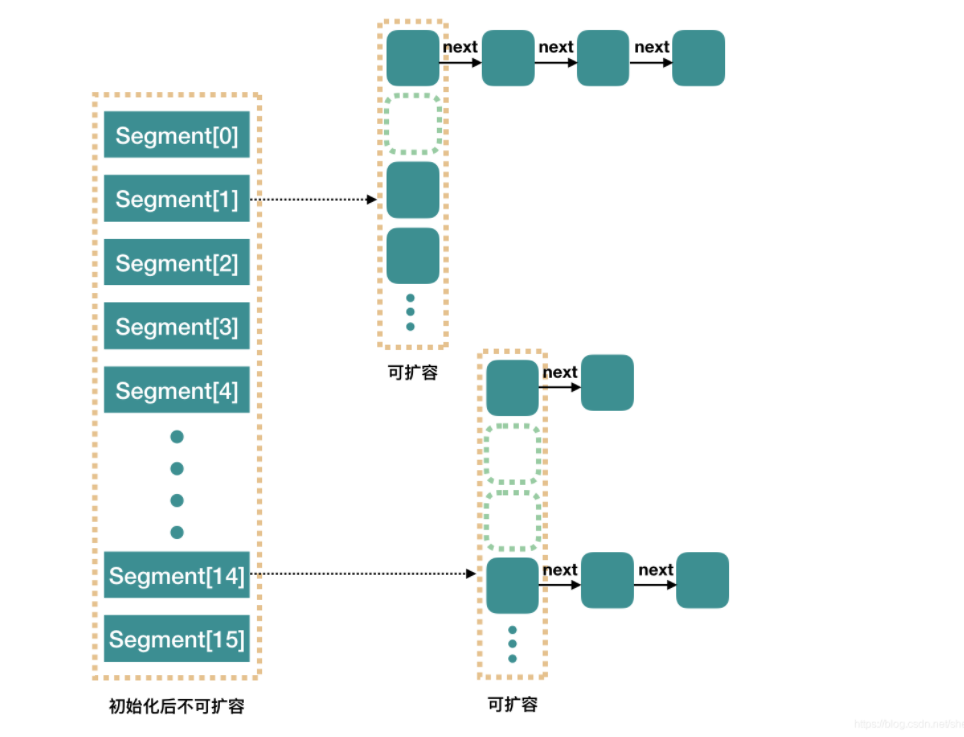
ConcurrnetHashMap 由很多個 Segment 組合,而每一個 Segment 是一個類似于 HashMap 的結構,所以每一個 HashMap 的內部可以進行擴容,但是 Segment 的個數一旦初始化就不能改變,默認 Segment 的個數是 16 個,所以可以認為 ConcurrentHashMap 默認支持最多 16 個執行緒并發,
2. 初始化
通過 ConcurrentHashMap 的無參構造探尋 ConcurrentHashMap 的初始化流程,
/**
* Creates a new, empty map with a default initial capacity (16),
* load factor (0.75) and concurrencyLevel (16).
*/
public ConcurrentHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
}
無參構造中呼叫了有參構造,傳入了三個引數的默認值,他們的值是,
/**
* 默認初始化容量,這個容量指的是Segment 的大小
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默認負載因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 默認并發級別,并發級別指的是Segment桶的個數,默認是16個并發大小
*/
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
Segment下面entryset陣列的大小是用DEFAULT_INITIAL_CAPACITY/DEFAULT_CONCURRENCY_LEVEL求出來的,
接著看下這個有參建構式的內部實作邏輯,
@SuppressWarnings("unchecked")
public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
// 引數校驗
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// 校驗并發級別大小,大于 1<<16,重置為 65536
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
// 2的多少次方
int sshift = 0;//控制segment陣列的大小
int ssize = 1;
// 這個回圈可以找到 concurrencyLevel 之上最近的 2的次方值
while (ssize < concurrencyLevel) {
++sshift;//代表ssize左移的次數
ssize <<= 1;
}
// 記錄段偏移量
this.segmentShift = 32 - sshift;
// 記錄段掩碼
this.segmentMask = ssize - 1;
// 設定容量 判斷初始容量是否超過允許的最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// c = 容量 / ssize ,默認 16 / 16 = 1,這里是計算每個 Segment 中的類似于 HashMap 的容量
//求entrySet陣列的大小,這個地方需要保證entrySet陣列的大小至少可以存盤下initialCapacity的容量,假設initialCapacity為33,ssize為16,那么c=2,所以if陳述句是true,那么c=3,MIN_SEGMENT_TABLE_CAPACITY初始值是2,所以if陳述句成立,那么cap=4,所以每一個segment的容量初始為4,segment為16,16*4>33成立,entrySet陣列的大小也需要是2的冪次方
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
//Segment 中的類似于 HashMap 的容量至少是2或者2的倍數
while (cap < c)
cap <<= 1;
// create segments and segments[0]
// 創建 Segment 陣列,設定 segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
總結一下在 Java 7 中 ConcurrnetHashMap 的初始化邏輯,
- 必要引數校驗,
- 校驗并發級別 concurrencyLevel 大小,如果大于最大值,重置為最大值,無參構造默認值是 16.
- 尋找并發級別 concurrencyLevel 之上最近的 2 的冪次方值,作為初始化容量大小,默認是 16,
- 記錄 segmentShift 偏移量,這個值為【容量 = 2 的N次方】中的 N,在后面 Put 時計算位置時會用到,默認是 32 - sshift = 28.
- 記錄 segmentMask,默認是 ssize - 1 = 16 -1 = 15.
- 初始化 segments[0],默認大小為 2,負載因子 0.75,擴容閥值是 2*0.75=1.5,插入第二個值時才會進行擴容,
- 計算segment陣列容量的大小,
- 計算entrySet陣列的大小,
- 初始化segment陣列,其中生成一個s0物件放在陣列的第0個位置
- 為什么首先需要一個s0存盤到陣列的第一個位置?
因為初始化陣列完成后陣列元素都還是null值,以后每一次添加一個元素的話,需要封裝為entrySet物件,還需要對entrySet陣列的大小重新計算,如果把第一次的計算結果全部存盤到S0中,那么以后的話只需要直接拿來使用即可,不需要重新計算,雖然Segment物件不同,但是物件中屬性內容其實是一樣的,
- Segment陣列的長度第一次已經確定,以后不會在改變,擴容是區域擴容,只對setrySet陣列的容量進行擴容,
3. put
接著上面的初始化引數繼續查看 put 方法原始碼,
/**
* Maps the specified key to the specified value in this table.
* Neither the key nor the value can be null.
*
* <p> The value can be retrieved by calling the <tt>get</tt> method
* with a key that is equal to the original key.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value =https://www.cnblogs.com/jiagooushi/p/= null)
throw new NullPointerException();
int hash = hash(key);
// hash 值無符號右移 28位(初始化時獲得),然后與 segmentMask=15 做與運算
// 其實也就是把高4位與segmentMask(1111)做與運算
// this.segmentMask = ssize - 1;
//對hash值進行右移segmentShift位,計算元素對應segment中陣列下表的位置
//把hash右移segmentShift,相當于只要hash值的高32-segmentShift位,右移的目的是保留了hash值的高位,然后和segmentMask與操作計算元素在segment陣列中的下表
int j = (hash >>> segmentShift) & segmentMask;
//使用unsafe物件獲取陣列中第j個位置的值,后面加上的是偏移量
if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
// 如果查找到的 Segment 為空,初始化
s = ensureSegment(j);
//插入segment物件
return s.put(key, hash, value, false);
}
/**
* Returns the segment for the given index, creating it and
* recording in segment table (via CAS) if not already present.
*
* @param k the index
* @return the segment
*/
@SuppressWarnings("unchecked")
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 判斷 u 位置的 Segment 是否為null
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
// 獲取0號 segment 里的 HashEntry<K,V> 初始化長度
int cap = proto.table.length;
// 獲取0號 segment 里的 hash 表里的擴容負載因子,所有的 segment 的 loadFactor 是相同的
float lf = proto.loadFactor;
// 計算擴容閥值
int threshold = (int)(cap * lf);
// 創建一個 cap 容量的 HashEntry 陣列
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
// 再次檢查 u 位置的 Segment 是否為null,因為這時可能有其他執行緒進行了操作
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 自旋檢查 u 位置的 Segment 是否為null
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 使用CAS 賦值,只會成功一次
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
return seg;
}
上面的原始碼分析了 ConcurrentHashMap 在 put 一個資料時的處理流程,下面梳理下具體流程,
-
計算要 put 的 key 的位置,獲取指定位置的 Segment,
-
如果指定位置的 Segment 為空,則初始化這個 Segment.
初始化 Segment 流程:
- 檢查計算得到的位置的 Segment 是否為null.
- 為 null 繼續初始化,使用 Segment[0] 的容量和負載因子創建一個 HashEntry 陣列,
- 再次檢查計算得到的指定位置的 Segment 是否為null.
- 使用創建的 HashEntry 陣列初始化這個 Segment.
- 自旋判斷計算得到的指定位置的 Segment 是否為null,使用 CAS 在這個位置賦值為 Segment.
-
Segment.put 插入 key,value 值,
上面探究了獲取 Segment 段和初始化 Segment 段的操作,最后一行的 Segment 的 put 方法還沒有查看,繼續分析,
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 獲取 ReentrantLock 獨占鎖,獲取不到,scanAndLockForPut 獲取,
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 計算要put的資料位置
int index = (tab.length - 1) & hash;
// CAS 獲取 index 坐標的值
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 檢查是否 key 已經存在,如果存在,則遍歷鏈表尋找位置,找到后替換 value
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = https://www.cnblogs.com/jiagooushi/p/e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// first 有值沒說明 index 位置已經有值了,有沖突,鏈表頭插法,
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
// 容量大于擴容閥值,小于最大容量,進行擴容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// index 位置賦值 node,node 可能是一個元素,也可能是一個鏈表的表頭
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
由于 Segment 繼承了 ReentrantLock,所以 Segment 內部可以很方便的獲取鎖,put 流程就用到了這個功能,
-
tryLock() 獲取鎖,獲取不到使用
scanAndLockForPut方法繼續獲取, -
計算 put 的資料要放入的 index 位置,然后獲取這個位置上的 HashEntry ,
-
遍歷 put 新元素,為什么要遍歷?因為這里獲取的 HashEntry 可能是一個空元素,也可能是鏈表已存在,所以要區別對待,
如果這個位置上的 HashEntry 不存在:
- 如果當前容量大于擴容閥值,小于最大容量,進行擴容,
- 直接頭插法插入,
如果這個位置上的 HashEntry 存在:
- 判斷鏈表當前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致,一致則替換值
- 不一致,獲取鏈表下一個節點,直到發現相同進行值替換,或者鏈表表里完畢沒有相同的,
- 如果當前容量大于擴容閥值,小于最大容量,進行擴容,
- 直接鏈表頭插法插入,
-
如果要插入的位置之前已經存在,替換后回傳舊值,否則回傳 null.
這里面的第一步中的 scanAndLockForPut 操作這里沒有介紹,這個方法做的操作就是不斷的自旋 tryLock() 獲取鎖,當自旋次數大于指定次數時,使用 lock() 阻塞獲取鎖,在自旋時順表獲取下 hash 位置的 HashEntry,
private HashEntry<K,V> scanAndLockForPut(K key, int hash, V value) {
HashEntry<K,V> first = entryForHash(this, hash);
HashEntry<K,V> e = first;
HashEntry<K,V> node = null;
int retries = -1; // negative while locating node
// 自旋獲取鎖
while (!tryLock()) {
HashEntry<K,V> f; // to recheck first below
if (retries < 0) {
if (e == null) {
if (node == null) // speculatively create node
node = new HashEntry<K,V>(hash, key, value, null);
retries = 0;
}
else if (key.equals(e.key))
retries = 0;
else
e = e.next;
}
else if (++retries > MAX_SCAN_RETRIES) {
// 自旋達到指定次數后,阻塞等到只到獲取到鎖
lock();
break;
}
else if ((retries & 1) == 0 &&
(f = entryForHash(this, hash)) != first) {
e = first = f; // re-traverse if entry changed
retries = -1;
}
}
return node;
}
4. 擴容 rehash
ConcurrentHashMap 的擴容只會擴容到原來的兩倍,老陣列里的資料移動到新的陣列時,位置要么不變,要么變為 index+ oldSize,引數里的 node 會在擴容之后使用鏈表頭插法插入到指定位置,
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
// 老容量
int oldCapacity = oldTable.length;
// 新容量,擴大兩倍
int newCapacity = oldCapacity << 1;
// 新的擴容閥值
threshold = (int)(newCapacity * loadFactor);
// 創建新的陣列
HashEntry<K,V>[] newTable = (HashEntry<K,V>[]) new HashEntry[newCapacity];
// 新的掩碼,默認2擴容后是4,-1是3,二進制就是11,
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
// 遍歷老陣列
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
// 計算新的位置,新的位置只可能是不便或者是老的位置+老的容量,
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
// 如果當前位置還不是鏈表,只是一個元素,直接賦值
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
// 如果是鏈表了
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 新的位置只可能是不便或者是老的位置+老的容量,
// 遍歷結束后,lastRun 后面的元素位置都是相同的
for (HashEntry<K,V> last = next; last != null; last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
// ,lastRun 后面的元素位置都是相同的,直接作為鏈表賦值到新位置,
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
// 遍歷剩余元素,頭插法到指定 k 位置,
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 頭插法插入新的節點
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
有些同學可能會對最后的兩個 for 回圈有疑惑,這里第一個 for 是為了尋找這樣一個節點,這個節點后面的所有 next 節點的新位置都是相同的,然后把這個作為一個鏈表賦值到新位置,第二個 for 回圈是為了把剩余的元素通過頭插法插入到指定位置鏈表,這樣實作的原因可能是基于概率統計,有深入研究的同學可以發表下意見,
5. get
到這里就很簡單了,get 方法只需要兩步即可,
- 計算得到 key 的存放位置,
- 遍歷指定位置查找相同 key 的 value 值,
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 計算得到 key 的存放位置
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
// 如果是鏈表,遍歷查找到相同 key 的 value,
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2 ConcurrentHashMap 1.8
1. 存盤結構
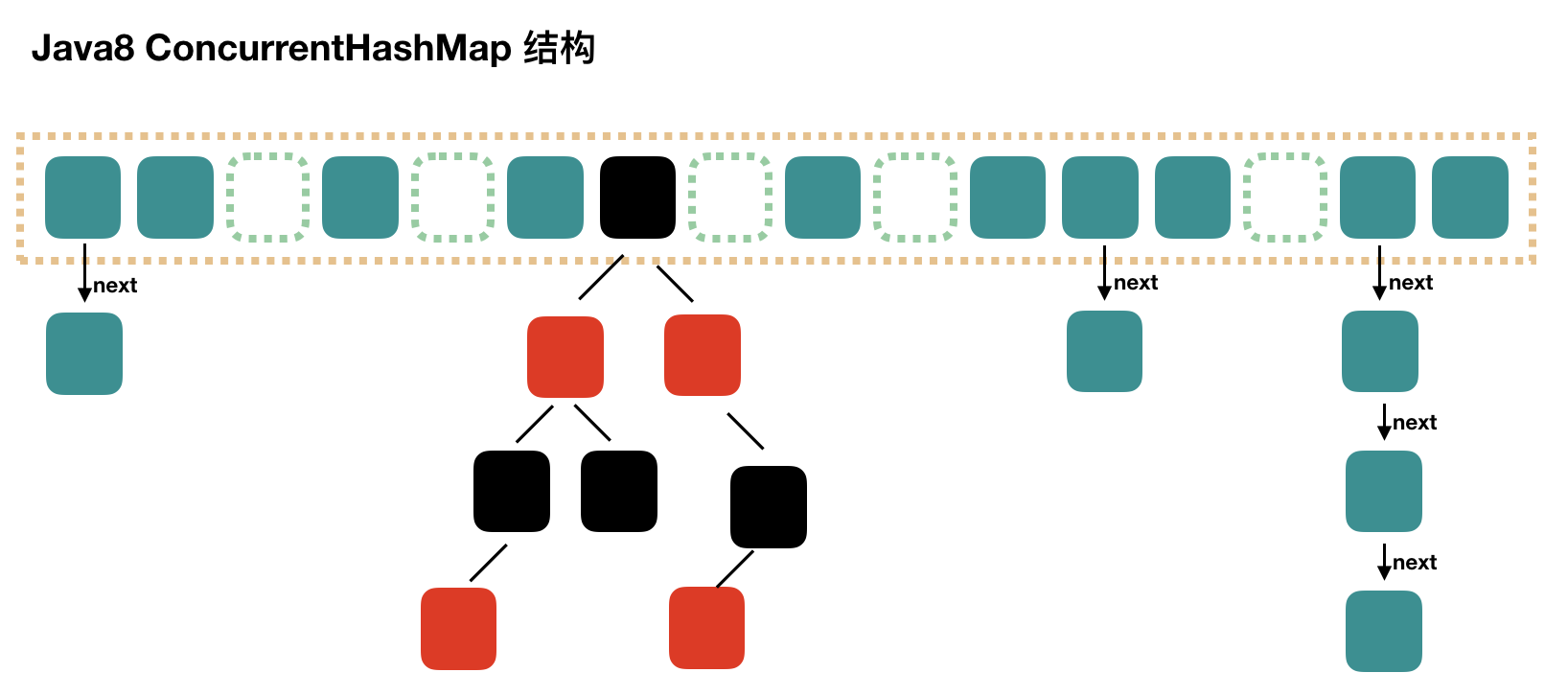
可以發現 Java8 的 ConcurrentHashMap 相對于 Java7 來說變化比較大,不再是之前的 Segment 陣列 + HashEntry 陣列 + 鏈表,而是 Node 陣列 + 鏈表 / 紅黑樹,當沖突鏈表達到一定長度時,鏈表會轉換成紅黑樹,
補充:CAS
CAS(Compare-and-Swap/Exchange),即比較并替換,是一種實作并發常用到的技術,
CAS核心演算法:執行函式:CAS(V,E,N)
V表示準備要被更新的變數 (記憶體的值)
E表示我們提供的 期望的值 (期望的原值)
N表示新值 ,準備更新V的值 (新值)
演算法思路:V是共享變數,我們拿著自己準備的這個E,去跟V去比較,如果E == V ,說明當前沒有其它執行緒在操作,所以,我們把N 這個值 寫入物件的 V 變數中,如果 E != V ,說明我們準備的這個E,已經過時了,所以我們要重新準備一個最新的E ,去跟V 比較,比較成功后才能更新 V的值為N,
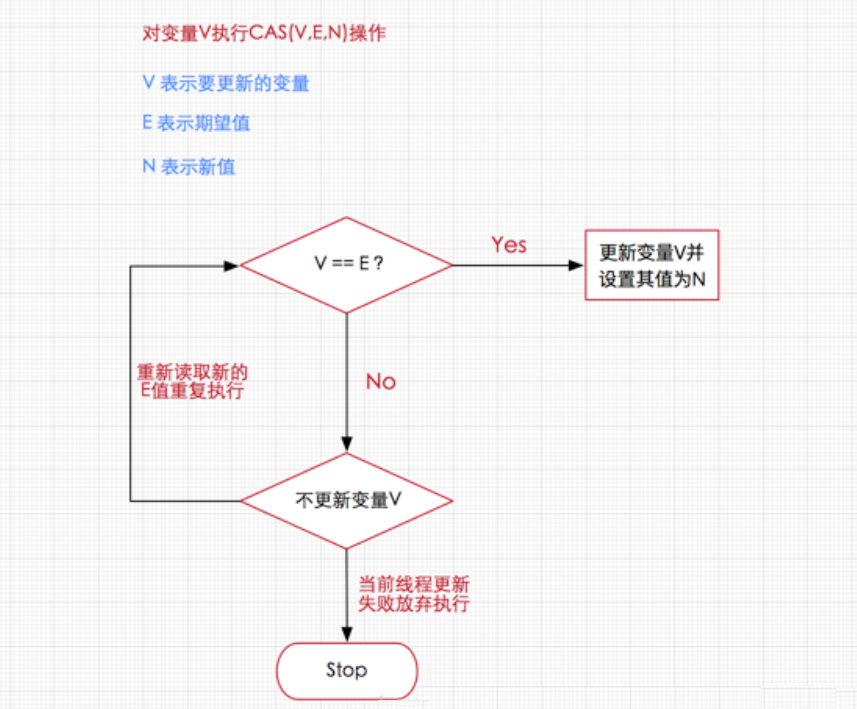
如果多個執行緒同時使用CAS操作一個變數的時候,只有一個執行緒能夠修改成功,其余的執行緒提供的期望值已經與共享變數的值不一樣了,所以均會失敗,
由于CAS操作屬于樂觀派,它總是認為自己能夠操作成功,所以操作失敗的執行緒將會再次發起操作,而不是被OS掛起,所以說,即使CAS操作沒有使用同步鎖,其它執行緒也能夠知道對共享變數的影響,
因為其它執行緒沒有被掛起,并且將會再次發起修改嘗試,所以無鎖操作即CAS操作天生免疫死鎖,
另外一點需要知道的是,CAS是系統原語,CAS操作是一條CPU的原子指令,所以不會有執行緒安全問題,
ABA問題:E和E2對比相同是不能保證百分百保證,其他執行緒沒有在自己執行緒執行計算的程序里搶鎖成功過,有可能其他執行緒操作后新E值和舊E值一樣!
ABA問題解決:在E物件里加個操作次數變數就行,每次判斷時對比兩個,E和操作次數就OK了,因為ABA問題中就算E相同操作次數也絕不相同
2. 初始化 initTable
/**
* Initializes table, using the size recorded in sizeCtl.
*/
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
//如果 sizeCtl < 0 ,說明另外的執行緒執行CAS 成功,正在進行初始化,
if ((sc = sizeCtl) < 0)
// 讓出 CPU 使用權
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
從原始碼中可以發現 ConcurrentHashMap 的初始化是通過自旋和 CAS 操作完成的,里面需要注意的是變數 sizeCtl ,它的值決定著當前的初始化狀態,
- -1 說明正在初始化
- -N 說明有N-1個執行緒正在進行擴容
- 表示 table 初始化大小,如果 table 沒有初始化
- 表示 table 容量,如果 table 已經初始化,
3. put
直接過一遍 put 原始碼,
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
// key 和 value 不能為空
if (key == null || value =https://www.cnblogs.com/jiagooushi/p/= null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node[] tab = table;;) {
// f = 目標位置元素
Node f; int n, i, fh;// fh 后面存放目標位置的元素 hash 值
if (tab == null || (n = tab.length) == 0)
// 陣列桶為空,初始化陣列桶(自旋+CAS)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 桶內為空,CAS 放入,不加鎖,成功了就直接 break 跳出
if (casTabAt(tab, i, null,new Node(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 使用 synchronized 加鎖加入節點
synchronized (f) {
if (tabAt(tab, i) == f) {
// 說明是鏈表
if (fh >= 0) {
binCount = 1;
// 回圈加入新的或者覆寫節點
for (Node e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
// 紅黑樹
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
- 根據 key 計算出 hashcode ,
- 判斷是否需要進行初始化,
- 即為當前 key 定位出的 Node,如果為空表示當前位置可以寫入資料,利用 CAS 嘗試寫入,失敗則自旋保證成功,
- 如果當前位置的
hashcode == MOVED == -1,則需要進行擴容, - 如果都不滿足,則利用 synchronized 鎖寫入資料,
- 如果數量大于
TREEIFY_THRESHOLD則要轉換為紅黑樹,
4. get
get 流程比較簡單,直接過一遍原始碼,
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// key 所在的 hash 位置
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果指定位置元素存在,頭結點hash值相同
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
// key hash 值相等,key值相同,直接回傳元素 value
return e.val;
}
else if (eh < 0)
// 頭結點hash值小于0,說明正在擴容或者是紅黑樹,find查找
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
// 是鏈表,遍歷查找
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
總結一下 get 程序:
- 根據 hash 值計算位置,
- 查找到指定位置,如果頭節點就是要找的,直接回傳它的 value.
- 如果頭節點 hash 值小于 0 ,說明正在擴容或者是紅黑樹,查找之,
- 如果是鏈表,遍歷查找之,
3 總結
Java7 中 ConcurrentHashMap 使用的分段鎖,也就是每一個 Segment 上同時只有一個執行緒可以操作,每一個 Segment 都是一個類似 HashMap 陣列的結構,它可以擴容,它的沖突會轉化為鏈表,但是 Segment 的個數一但初始化就不能改變,
Java8 中的 ConcurrentHashMap 使用的 Synchronized 鎖加 CAS 的機制,結構也由 Java7 中的 Segment 陣列 + HashEntry 陣列 + 鏈表 進化成了 Node 陣列 + 鏈表 / 紅黑樹,Node 是類似于一個 HashEntry 的結構,它的沖突再達到一定大小時會轉化成紅黑樹,在沖突小于一定數量時又退回鏈表,
本文由
傳智教育博學谷教研團隊發布,如果本文對您有幫助,歡迎
關注和點贊;如果您有任何建議也可留言評論或私信,您的支持是我堅持創作的動力,轉載請注明出處!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/516281.html
標籤:Java