Bloom Filter概念和實作原理
背景
我們在判斷某一個元素是否在某個集合里面時,一般是將集合里面的所有元素都保存下來,然后直接讀取磁盤上的資料再進行判斷,但是如果資料量很大,此時讀取速度就會降低,這時我們可以將資料提前存盤到記憶體中,記憶體讀取速度會快很多,但是資料量在逐漸增大時,記憶體的開銷也在逐漸增大,檢索的時間也會變長,此時,在資料量特別大的情況下,需要一個時間和空間上都具有優勢的資料結構,
介紹
Bloom Filter是由Howard Bloom在1970年提出的二進制向量資料結構,它具有較好的時間和空間效率,用來檢測一個元素是否在某個集合中,但是缺點是,有一定的錯誤率和洗掉困難,
原理
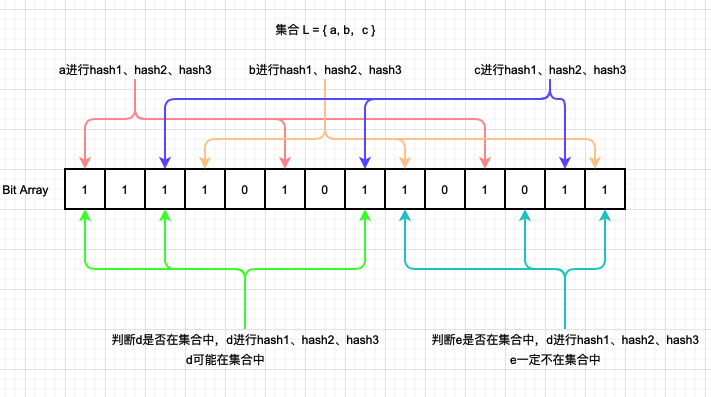
Bloom Filter判斷某一個元素是否在集合中時,會將集合中的每一個元素都通過K個不同的Hash函式映射到一個bit陣列里面的K個點,每個點設定為1,此時檢索一個元素時,只需要將該元素同樣進行K個不同的Hash函式,求得K個點位,如果這K個點位全部是1,則代表元素可能在集合里面,如果有一個為0,則代表元素不在集合里面,
公式
-
Bit陣列大小的計算
需要根據預估的資料量n以及錯誤率p來計算Bit陣列的大小m:
\[m=- \frac {n \ln {p}} {(\ln {2})^2} \] -
Hash函式個數k計算
根據預估的資料量n和已經求得的Bit陣列長度m,可以計算出Hash函式的個數k:
\[k=\frac {m} {n} \ln {2} \]
代碼實作
/**
* All rights Reserved, Designed By monkey.blog.xpyvip.top
*
* @version V1.0
* @Package PACKAGE_NAME
* @Description:
* @Author: xpy
* @Date: Created in 2022年10月09日 4:42 下午
*/
public class Test {
public static void main(String[] args) {
System.out.println(calNumOfBits(3,0.1));
System.out.println(calNumOfHashFuns(3, 14));
}
/**
* 計算bit陣列大小m
* @param n 預估的資料量
* @param p 錯誤率 在0-1之間 0<p<1
* @return
*/
private static long calNumOfBits(long n, double p){
if(p == 0){
p = Double.MIN_VALUE;
}
return (long) (-n * Math.log(p) / (Math.log(2) * Math.log(2)));
}
/**
* 計算最佳需要多少個hash函式,即k值
* @param n 預估的資料量
* @param m bit陣列大小m
* @return
*/
private static int calNumOfHashFuns(long n, long m){
return Math.max(1, (int) Math.round((double) m / n * Math.log(2)));
}
}
實際Bloom Filter使用
-
使用hutool里面的Bloom Filter
/** * All rights Reserved, Designed By monkey.blog.xpyvip.top * * @version V1.0 * @Package PACKAGE_NAME * @Description: * @Author: xpy * @Date: Created in 2022年10月09日 4:42 下午 */ public class Test { public static void main(String[] args) { BitMapBloomFilter bitMapBloomFilter = new BitMapBloomFilter(8); bitMapBloomFilter.add("test123"); bitMapBloomFilter.add("tset123456"); System.out.println(bitMapBloomFilter.contains("test123")); System.out.println(bitMapBloomFilter.contains("test12")); } } -
使用Google的guava包
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnels; import java.nio.charset.Charset; /** * All rights Reserved, Designed By monkey.blog.xpyvip.top * * @version V1.0 * @Package PACKAGE_NAME * @Description: * @Author: xpy * @Date: Created in 2022年10月09日 4:42 下午 */ public class Test { public static void main(String[] args) { // 設定預估的資料量在1000000,錯誤率在0.01 BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), 1000000, 0.01); bloomFilter.put("test123"); bloomFilter.put("test123456"); bloomFilter.put("tset123456"); System.out.println(bloomFilter.mightContain("test123456")); System.out.println(bloomFilter.mightContain("tset12")); } }
擴展
-
錯誤率
Bloom Filter存在判斷錯誤的情況,適用于允許存在判斷錯誤的場景,
-
不允許洗掉
洗掉其中某一個元素,需要將該元素對應的bit位設定為0,但是很可能有其他元素對應,所以不能洗掉,設定為0,
原文鏈接:https://monkey.blog.xpyvip.top/archives/bloomfilter-gai-nian-he-shi-xian-yuan-li
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/517499.html
標籤:Java
上一篇:Nacos集群搭建