寫了一個GK2A衛星資料爬取的程式,本身不難,記錄下小知識,
根據URL下載檔案,有些需要cookie,大檔案下載防止檔案損壞
headers = {
"Content-Type": ContentType,
"User-Agent": UA,
"Cookie": cookie
}
response = requests.get(uri, headers = headers,stream=True)
with open(the_file_path, "wb") as fp:
for chunk in response.iter_content(chunk_size=1024*2):
if chunk:
fp.write(chunk)
下載zip包,zip包解壓
zipname = f"{static_uri_path[flag]}_{type}.zip"#壓縮包名
the_file_path = os.path.join(file_path, zipname)#壓縮檔案地址
the_file_URL = f"{first_URL}{static_uri_path[flag]}&fileName={static_uri_path[flag]}.zip"#要下載的連接
try:
request_file(the_file_URL, cookie, the_file_path)#下載函式
print(the_file_URL, the_file_path)
#以下是zip操作
zip_file = zipfile.ZipFile(the_file_path)#對壓縮包地址操作
zip_list = zip_file.namelist() # 得到壓縮包里所有的檔案
for f in zip_list:
zip_file.extract(f, file_path) # 回圈解壓檔案到指定目錄
zip_file.close() # 關閉檔案,必須有,釋放記憶體
except Exception as exc:
print("下載與解壓錯誤", exc)
清理空白檔案夾和壓縮包
def dir_arrange(file_path):
"""
整理檔案到指定目錄
并洗掉空白檔案夾
"""
dirpath = rf"{file_path}\work\00" #要洗掉的檔案路徑
filelist = os.listdir(dirpath)
allfile = []
for file in filelist:
allfile.append(dirpath + '/' + file)
for file in allfile:
shutil.move(file,file_path) #把檔案夾內檔案移走
os.removedirs(dirpath)
print("已洗掉空白檔案夾!")
for files in os.listdir(file_path):
if files.endswith(".zip"):
os.remove(os.path.join(file_path, files))#洗掉zip檔案
print("已洗掉zip檔案!")
用正則運算式的方式提取cookie,正則的方式應用廣泛
import re
SCOUTER = re.split('[,;]',response.headers['Set-Cookie'])[2].strip()#正則提取,通過,;進行分隔,并去空格也可以用split連寫,達成同樣效果
remberuser = response.headers['Set-Cookie'].split(";")[3].split(",")[1].strip()
已經下載的檔案排列順序會按照0,1,10,11,19,2,20,21的順序,不滿足需求,需要排序
contents = show_files(traversal_file, []) # 回圈列印show_files函式回傳的檔案名串列
contents.sort(key=lambda x: int(re.split('[._]',x)[3]))#按照數字順序排序,re部分是正則運算式寫法,整個int()內是檔案名的數字部分即可
運用tqdm,實作等待時間讀條
import tqdm
for i in tqdm(range(120),desc='等待快取中'):#共120秒
time.sleep(1)#每1秒走一次對于檔案,tqdm下載時的進度顯示
from tqdm import tqdm
import requests
url='https://dldir1.qq.com/qqtv/TencentVideo11.14.4043.0.exe'
response=requests.get(url,stream=True) # 設stream流傳輸方式為真
print(response.headers) # 列印查看基本頭資訊
data_size=round(int(response.headers['Content-Length'])/1024/1024) # 位元組/1024/1024=MB,加上round上取整可以避免一種報錯
with open('測驗.exe','wb') as f:#測驗.exe是路徑下要命名的檔案
for data in tqdm(iterable=response.iter_content(1024*1024),total=data_size,desc='正在下載',unit='MB'):
f.write(data)
"""
將iter_content(chunk_size)->chunk_size理解為一個串列的容量,
而iterable=response.iter_content(1024*1024)理解為分割字串的函式,
將response.content分割為每個元素的長度是1024*1024大小的串列,在對每個部分進行下載,
這只是助于理解chunk_size的一個方法
而response.iter_content 是流傳輸(簡單說就是邊下載邊寫入磁盤),如果將chunk_size設定的很小,意味著每次
下載和存在很小的一部分,下載的速度也會很慢,如果設定的很大,則進度條的進度會錯亂,因此我們在確定chunk_size
大小的時候應該對應檔案大小,data_size除以多少,chunk_size就乘以多少,才能使進度條對應,
"""
一種從json格式中提取檔案串列的簡潔寫法
data_list = response.json()
filesize_list = [data["fileSize"] for data in data_list["data"]]#把data中的所有fileSize資料存入到串列中進階寫法
page_uri_list = [[data["picPath1"], data["videoPath1"], data["address"] ] for data in data_list] #從Json中讀取三種資料,以元組的形式保存進串列
static_uri_path.extend(page_uri_list)#在while回圈中,合并到一個整體串列中
for index, (img_uri, video_uri, address) in enumerate(static_uri_path , start=index_):
#static_uri_path中有三個元素,分別讀取
#加入index序列回圈
#start可以設定初始值
if img_uri is not None :
abs_img_path = os.path.join(imgs_path, f"{d_date.split('-')[0]}_{d_date.split('-')[1]}_{d_date.split('-')[2]}_{index}.jpeg")
request_file(img_uri, abs_img_path)
print(abs_img_path)
if video_uri is not None and IS_VIDEO:
abs_video_path = os.path.join(videos_path, f"{d_date.split('-')[0]}_{d_date.split('-')[1]}_{d_date.split('-')[2]}_{index}.mp4")
request_file(video_uri, abs_video_path)
Xpath路徑讀取的一些相關操作
headers = {
"Cookie": abs_cookies,
"User-Agent": UA
}
response = requests.get(f"http://219.239.221.20:8088/cffm20/Monitoring/Details/{imageId}", headers=headers).text
tree = etree.HTML(response)
mar_b_10_div = tree.xpath('//div[@]/div[@]')
#選取所有div元素,是擁有"pad_15 jbxx_section"class屬性的div元素中的擁有"clearfix mar_b_10"class屬性的所有div元素
img_url = mar_b_10_div[1].xpath("./div[2]/a/@href")[0]#最后這個[0],加的話是讀取串列中元素,不加的話是個串列
txt_url = mar_b_10_div[2].xpath("./div[2]/a/@href")[0]
#./是當前目錄,當前目錄下第2個div元素,div中的a元素,然后選取a元素中所有的href屬性
clearfix_mar_b_10_div = tree.xpath('//div[@class= "pad_15 tpxx_section"]/div[@class = "clearfix mar_b_10"]')
file_date = clearfix_mar_b_10_div[3].xpath("./div[2]/text()")[0] #text()可以獲得><之間的標簽,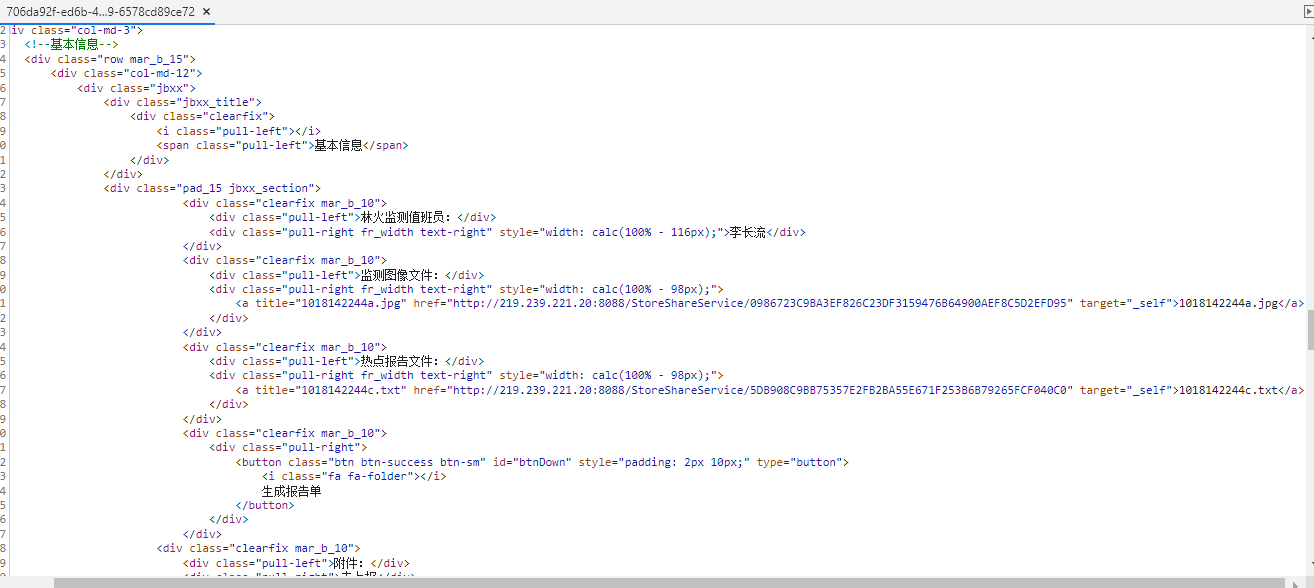

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/517521.html
標籤:Python
上一篇:編程思想