0.1、索引
https://waterflow.link/articles/1666449874974
1、字串編碼
在go中rune是一個unicode編碼點,
我們都知道UTF-8將字符編碼為1-4個位元組,比如我們常用的漢字,UTF-8編碼為3個位元組,所以rune也是int32的別名,
type rune = int32
當我們列印一個英文字符hello的時候,我們可以得到s的長度為5,因為英文字母代表1個位元組:
package main
import "fmt"
func main() {
s := "hello"
fmt.Println(len(s)) // 5
}
但是當我們列印嗨的時候,會列印3個位元組,因為使用UTF-8,這個字符會被編碼成3個位元組:
package main
import "fmt"
func main() {
s := "嗨"
fmt.Println(len(s)) // 3
}
所以,我們使用len內置函式輸出的并不是字符數,而是位元組數,
下面看一個有趣的例子,我們都知道漢字符使用3個位元組編碼,分別是0xE5, 0x97, 0xA8,我們運行下面代碼會得到漢字嗨:
package main
import "fmt"
func main() {
s := string([]byte{0xE5, 0x97, 0xA8})
fmt.Println(s) // 嗨
}
所以我們需要知道:
- 字符集是一組字符,而編碼描述了如何將字符集轉換為二進制
- 在 Go 中,字串參考任意位元組的不可變切片
- Go 原始碼使用 UTF-8 編碼, 因此,所有字串文字都是 UTF-8 字串, 但是因為字串可以包含任意位元組,如果它是從其他地方(不是原始碼)獲得的,則不能保證它是基于 UTF-8 編碼的
- 使用 UTF-8,一個 Unicode 字符可以編碼為 1 到 4 個位元組
- 在 Go 中對字串使用 len 回傳位元組數,而不是字符數
2、字串遍歷
我們在開發中經常會用到對字串進行遍歷的場景, 也許我們想對字串中的每個 rune 執行一個操作,或者實作一個自定義函式來搜索特定的子字串, 在這兩種情況下,我們都必須遍歷字串的不同字符, 但往往會得到讓我們意想不到的結果,
我們看下下面的例子,列印一個字串中的不同字符和對應的位置:
package main
import "fmt"
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
}
go run 7.go
字符位置 0: h
字符位置 1: ?
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
我們想要的效果是通過遍歷字串,列印出每個字符的索引,但是我們卻得到了一個特殊的字符?,其實我們想要的是嗨,
但是列印的位元組數是符合我們的預期的,因為嗨是一個中文占用了3個位元組,所以len回傳的是7,
3、字串中的字符數
如果我們想要正確的獲取字串的字符數,可以使用go中的utf8包:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i := range s {
fmt.Printf("字符位置 %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s)) // 獲取字符數
}
go run 7.go
字符位置 0: h
字符位置 1: ?
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
在這個例子中,可以看到,我們確實遍歷了5次,也就是對應字串的5個字符,但是我們獲取到的索引其實是對應每個字符的起始位置,像下面這樣
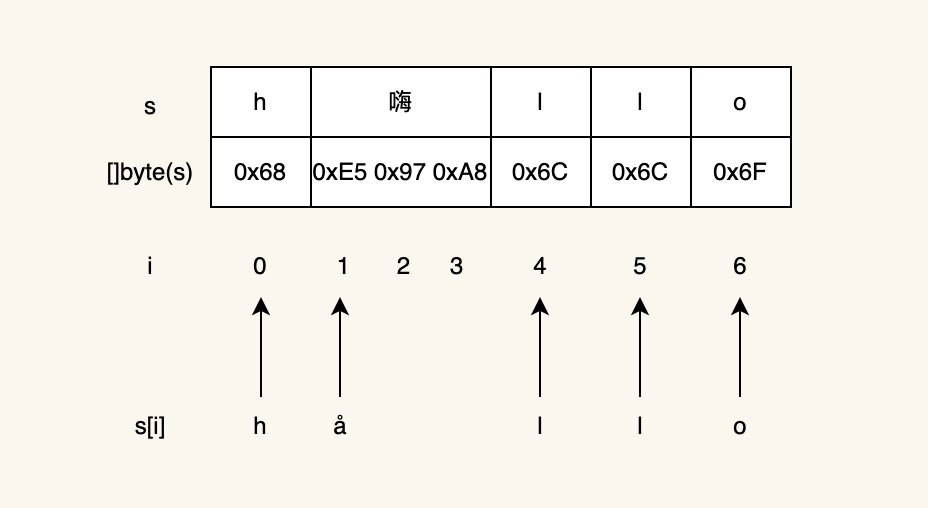
那我們如何列印出正確的結果呢?我們稍微修改下代碼:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
for i, v := range s { // 此處改為獲取v,可以獲取到字符本身
fmt.Printf("字符位置 %d: %c\n", i, v)
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 4: l
字符位置 5: l
字符位置 6: o
len=7
rune len=5
另外一種方法就是把字串轉換成rune切片,這樣也會正確列印結果:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := "h嗨llo"
b := []rune(s)
for i := range b {
fmt.Printf("字符位置 %d: %c\n", i, b[i])
}
fmt.Printf("len=%d\n", len(s))
fmt.Printf(" rune len=%d\n", utf8.RuneCountInString(s))
}
go run 7.go
字符位置 0: h
字符位置 1: 嗨
字符位置 2: l
字符位置 3: l
字符位置 4: o
len=7
rune len=5
下面是rune切片遍歷的程序(中間省略了將位元組轉換為rune的程序,需要遍歷位元組,復雜度為O(n))
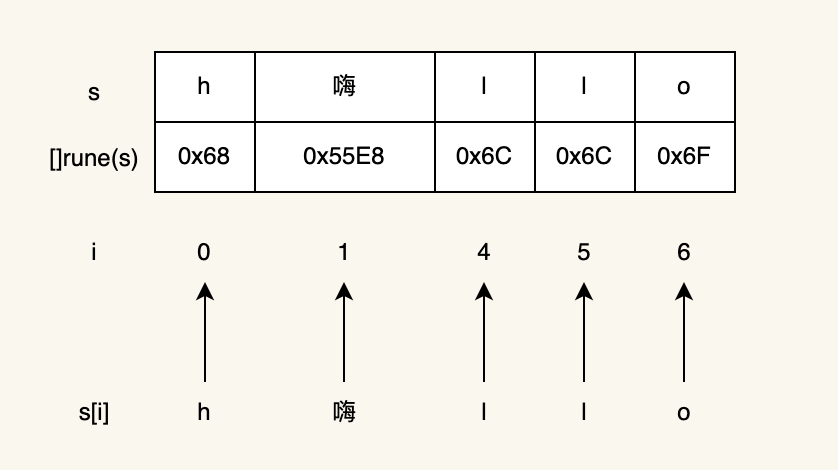
4、字串trim
開發中我們經常會遇到去除字串頭部或者尾部字符的操作,比如我們現在有個字串xohelloxo,現在我們想去除尾部的xo,可能我們會像下面這樣寫:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimRight(s, "xo")
fmt.Println(s)
}
go run 7.go
xohell
可以看到這不是我們期望的結果,我們可以看下TrimRight的作業原理:
- 從右側取出第一個字符o,判斷是否在xo中,在就移除
- 重復步驟1,知道不符合條件
所以就可以解釋通了,當然和它相似的TrimLeft和Trim也是一樣的原理,
如果我們只想洗掉最后xo可以使用TrimSuffix函式:
package main
import (
"fmt"
"strings"
)
func main() {
s := "xohelloxo"
s = strings.TrimSuffix(s, "xo")
fmt.Println(s)
}
go run 7.go
xohello
當然也有對應的從前面洗掉的函式TrimPrefix,
5、字串連接
開發中我們經常會用到連接字串的操作,在go中我們一般有2種方式,
我們先看下+號連接的方式:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
s := ""
for _, value := range values {
s += operate
s += value
}
s = strings.TrimPrefix(s, operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
這種方式的缺點就是,由于字串的不變性,每次+號賦值的時候s不會被更新,而是重新分配記憶體,所以這種方式對性能有很大影響,
還有一種方式就是使用strings.Builder:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
首先,我們創建了一個 strings.Builder 結構, 在每次遍歷中,我們通過呼叫 WriteString 方法構造結果字串,該方法將 value 的內容附加到其內部緩沖區,從而最大限度地減少記憶體復制,
WriteString 的第二個引數回傳的是error,但是error的值會一直為nil, 之所以有第二個error引數是因為我 strings.Builder 實作了 io.StringWriter 介面,它包含一個方法:WriteString(s string) (n int, err error),
我們看下WriteString的內部是什么樣的:
func (b *Builder) WriteString(s string) (int, error) {
b.copyCheck()
b.buf = append(b.buf, s...)
return len(s), nil
}
我們可以看到b.buf是一個位元組切片,而里面的實作是使用了append方法,我們知道如果切片很大,使用append會讓底層陣列不斷擴容,影響代碼執行效率,
我們知道解決這個問題的方法是,如果事先知道切片的大小,我們可以在初始化的時候就分配好切片的容量,
所以上面的字串連接還有一種優化方案:
package main
import (
"fmt"
"strings"
)
func implode(values []string, operate string) string {
total := 0
for i := 0; i < len(values); i++ {
total += len(values[i])
}
total += len(operate) * len(values)
sb := strings.Builder{}
sb.Grow(total) // 這里會重新分配b.buf的長度和容量
for _, value := range values {
_, _ = sb.WriteString(operate)
_, _ = sb.WriteString(value)
}
s := strings.TrimPrefix(sb.String(), operate)
return s
}
func main() {
a := []string{"hello", "world"}
s := implode(a, " ")
fmt.Println(s)
}
go run 7.go
hello world
6、位元組切片轉字串
需要明確的是,位元組切片轉換成字串,需要復制一份副本出來,可以通過下面的代碼做驗證:
b := []byte{'a', 'b', 'c'}
s := string(b)
b[1] = 'x'
fmt.Println(s)
事實上,上面將會輸出abc而不是axc,所以位元組切片到字串的轉換是有開銷的,
但是我們開發中經常用到的包iio.Read之類的,入參或者回傳經常是位元組切片型別,而我們呼叫這些函式時經常是以字串的形式,導致我們不得不做一些位元組切片刀字串的轉換,
所以結論是,當我們需要使用字串作為入參或者回傳時,我們首先要考慮的是能用位元組切片的就用位元組切片,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/518916.html
標籤:Go
上一篇:golang垃圾回收
下一篇:Redis常見問題