pandas的下載
使用命令下載:
pip install pandas

或者自行下載whl檔案安裝
https://www.lfd.uci.edu/~gohlke/pythonlibs/
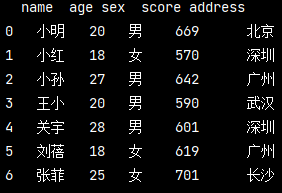
創建DataFrame資料
pd_data =https://www.cnblogs.com/liuyebai/p/ pd.DataFrame({ "name":["小明","小紅","小孫","王小","關宇","劉蓓","張菲"], "age":[20,18,27,20,28,18,25], "sex":["男","女","男","男","男","女","女"], "score":[669,570,642,590,601,619,701], "address":["北京","深圳","廣州","武漢","深圳","廣州","長沙"] }) print(pd_data)
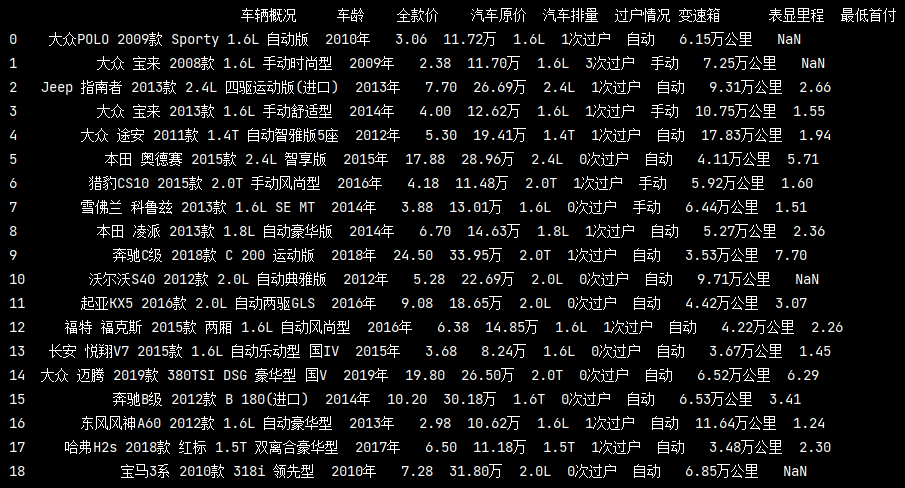
讀取本地檔案
pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./測驗.xlsx') pd.set_option('display.max_columns', None) # 顯示完整的列 pd.set_option('display.max_rows', None) # 顯示完整的行 pd.set_option('display.expand_frame_repr', False) # 設定不折疊資料 print(pd_data)
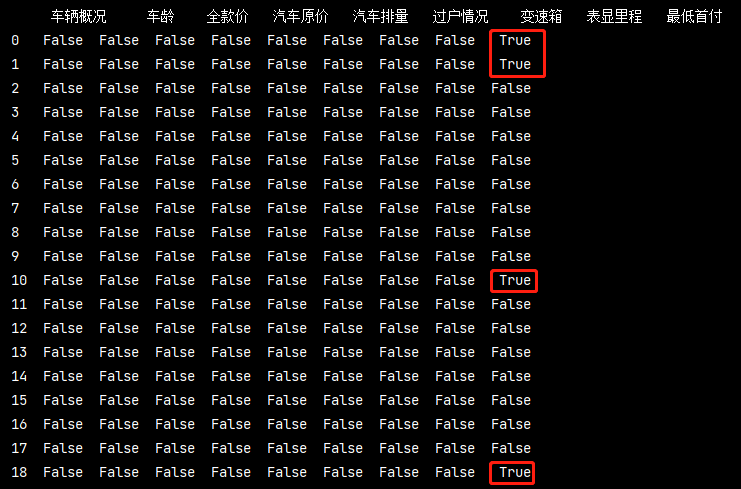
查看資料是否有缺失
# 如果缺失顯示為True,否則顯示False isnull = pd_data.isnull() print(isnull)
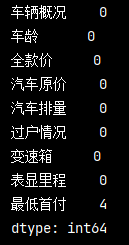
統計缺失值個數
# 統計缺失值個數 null_count = pd_data.isnull().sum() print(null_count)
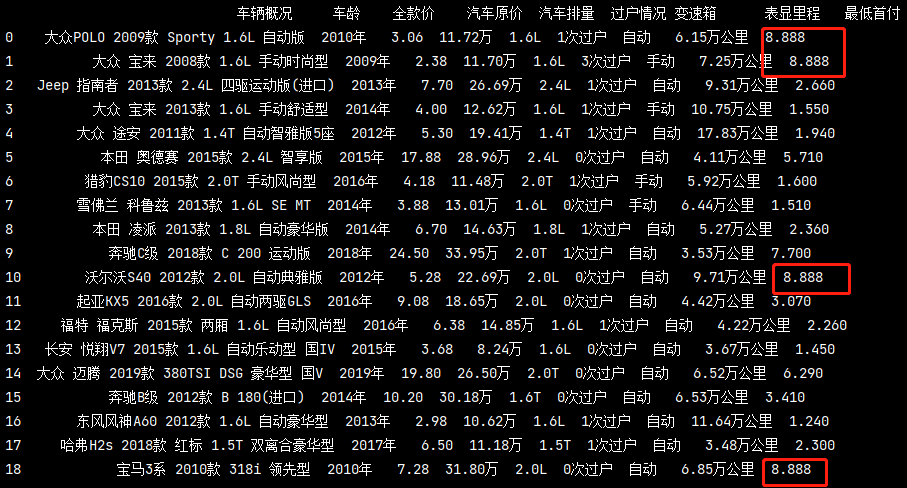
缺失值填充
# 填充資料 我選擇了8.888,你隨意 pd_data.fillna(8.888, inplace=True) print(pd_data)
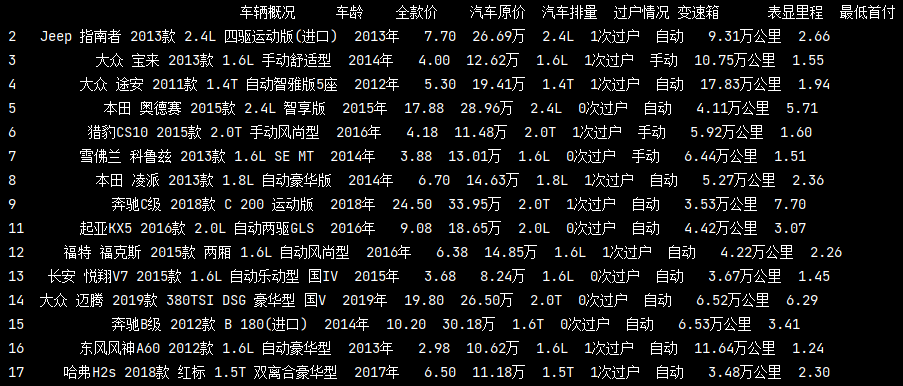
缺失值洗掉
# 如果有缺失值,洗掉此行 exist_col = pd_data.dropna() print(exist_col)
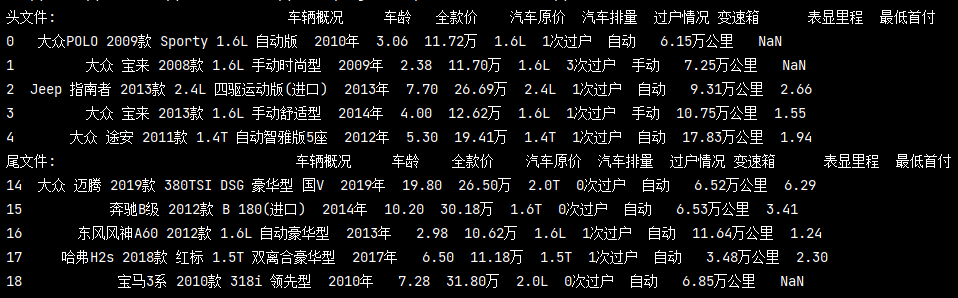
查看頭尾檔案
# 查看頭尾檔案 print('頭檔案:', pd_data.head()) print('尾檔案:', pd_data.tail())
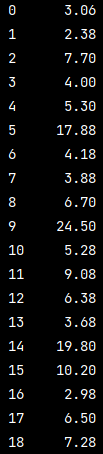
取單列值
# 單列值 pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./測驗.xlsx') print(pd_data['全款價'])
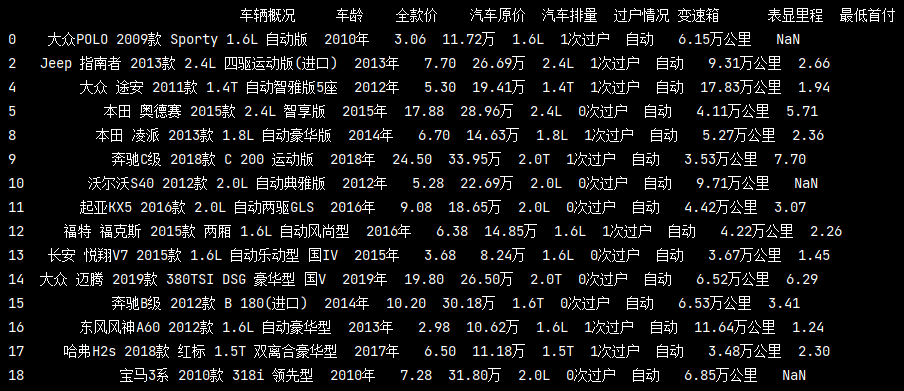
取多列值
# 多列值 pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./測驗.xlsx') print(pd_data[['車輛概況', '全款價']])

單條件取值
pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./測驗.xlsx') print(pd_data[pd_data['全款價'] == 4]) print('-'*100) print(pd_data[pd_data['汽車排量'] == '2.0T'])

多條件取值-與
# 多條件篩選資料 print(pd_data[(pd_data['車齡'] == '2018年') & (pd_data['變速箱'] == '自動')])

多條件取值-或
# 多條件篩選資料 print(pd_data[(pd_data['車齡'] == '2018年') | (pd_data['變速箱'] == '自動')])
字串的開始函式
# 找出在 車輛概況 中以'大眾'開頭的 cars = pd_data[pd_data['車輛概況'].str.startswith('大眾')] print(cars)

字串的結尾函式
# 找出在 車輛概況 中以'豪華型'結尾的 cars = pd_data[pd_data['車輛概況'].str.endswith('豪華型')] print(cars)

字串的包含函式???????????????
# 找出在 車輛概況 中包含'進口'的 cars = pd_data[pd_data['車輛概況'].str.contains('進口')] print(cars)

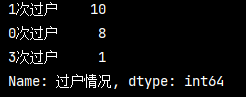
統計元素個數
# 統計 過戶分類 以及對應次數 trans_count = pd_data['過戶情況'].value_counts() print(trans_count)
為了便于進一步的資料分析,我希望將它們置于不同的陣列之中,可以采用如下方法:
# 統計 過戶分類 以及對應次數 trans_count = pd_data['過戶情況'].value_counts() # 針對于過戶情況的分類 x1_data =https://www.cnblogs.com/liuyebai/p/ trans_count.index.tolist() # 分類后各組資料的統計 x2_data =https://www.cnblogs.com/liuyebai/p/ trans_count.tolist() print(x1_data) print(x2_data)
這種格式的資料才是最適合做可視化分析的!
這里再多介紹兩種方法,條條大路通羅馬
都能輕松實作你的目標,
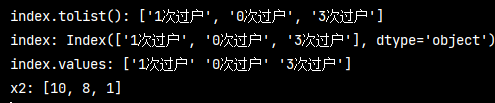
# 統計 過戶分類 以及對應次數 trans_count = pd_data['過戶情況'].value_counts() # 針對于過戶情況的分類 x1_data =https://www.cnblogs.com/liuyebai/p/ trans_count.index.tolist() x11_data = trans_count.index x12_data = trans_count.index.values # 類后各組資料的統計 x2_data =https://www.cnblogs.com/liuyebai/p/ trans_count.tolist() print('index.tolist():', x1_data) print('index:', x11_data) print('index.values:', x12_data) print('x2:', x2_data)
分割字串
這個功能也很實用,大家可以看看我的汽車名稱資料這一列,我的目標僅僅是車名而已,后面的車型、車齡、排列、變速箱資訊對我來說都是冗余資訊,
非常不利于我后續資料可視化
所以字串分割在這里就顯得尤為重要,
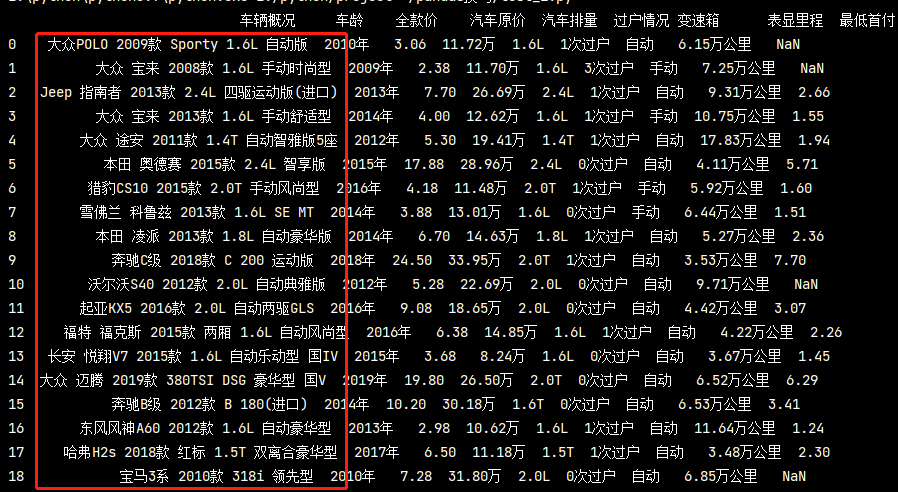
# 對 汽車名稱 這一列按照空格分割 并取第一個字符 pd_data['汽車名稱'] = pd_data['車輛概況'].map(lambda x: x.split(" ")[0]) name = pd_data['汽車名稱'].value_counts() # 汽車名稱分類 name1 = name.index.tolist() # 汽車名稱對應數量 name2 = name.tolist() print(name1) print(name2)

看到我取出來資料的樣子了嗎,要的就是這個!
清理資料
當我們相對汽車里程做進一步的分析時會發現資料后面都有一個’萬公里’,這種資料要做可視化必須先對資料進行處理,
就是先要去除數字后面的字符
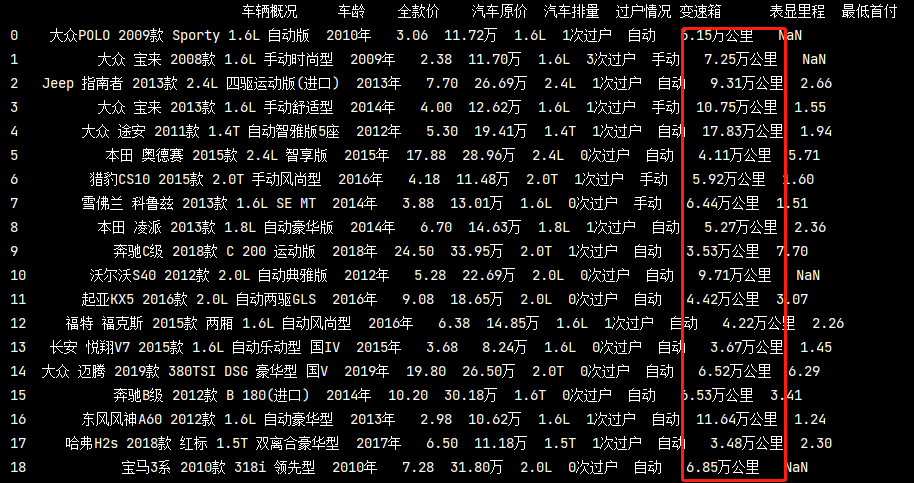
我們可以使用字串的replace()方法,使用空格替換字符
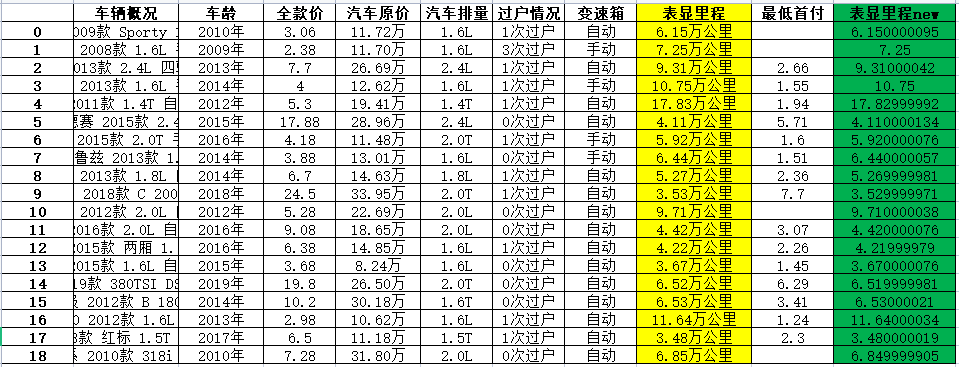
pd_data.loc[:, '表顯里程new'] = pd_data['表顯里程'].str.replace('萬公里', '').astype('float32') # 去除 30 ’萬公里‘ # 保存資料 pd_data.to_excel('測驗1.xlsx')
黃色一列是我們處理之前的資料
綠色一列是我們處理之后的資料
已經達到了我們想要的效果
劃磁區間
現在有這么一個需求,我想要按照汽車的行駛里程分類,基本上每個車的行駛里程都是不一樣的,如果將每個資料都反映在圖示上就會看起來很冗余,
也就失去了作圖的意義
所以我們可以按照區間來劃分,例如5w-10w公里、10w-15w公里這樣圖表展示展示出來的效果就會很好了,
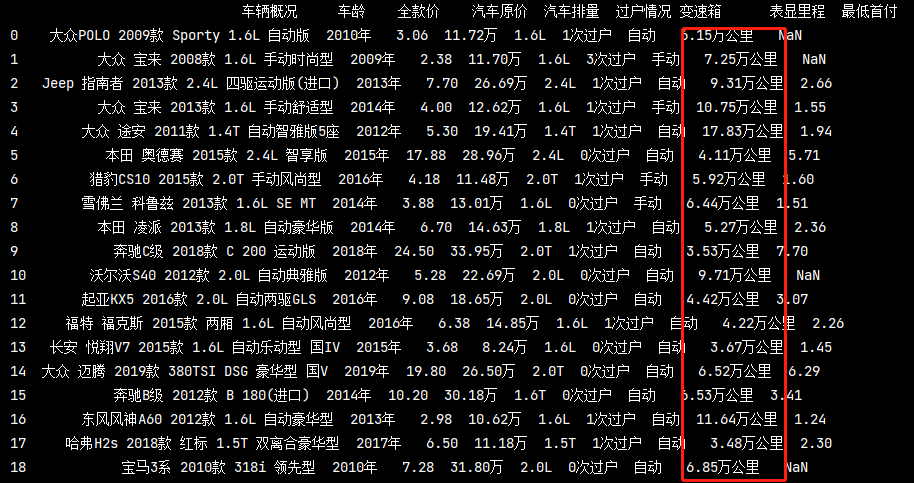
pd_data.loc[:, '表顯里程new'] = pd_data['表顯里程'].str.replace('萬公里', '').astype('float32') # 去除 30 ’萬公里‘ # 劃磁區間 pd_data['里程區間'] = pd.cut(pd_data['表顯里程new'], [0, 2, 4, 6, 8, 10, 20], labels=['0-2', '2-4', '4-6', '6-8', '8-10', '>10']) mile = pd_data['里程區間'].value_counts() mile1 = mile.index.tolist() # 里程區間分類 mile2 = mile.tolist() # 里程區間分類對應數量 print(mile1) print(mile2)

重置索引
其實我們在上面案例的演示中已經發現了,根據條件取出來的資料的索引都是處理資料之前的索引,
我們現在要重置索引的話要怎么辦呢?
我們可是使用_reset_index()_來索引重置
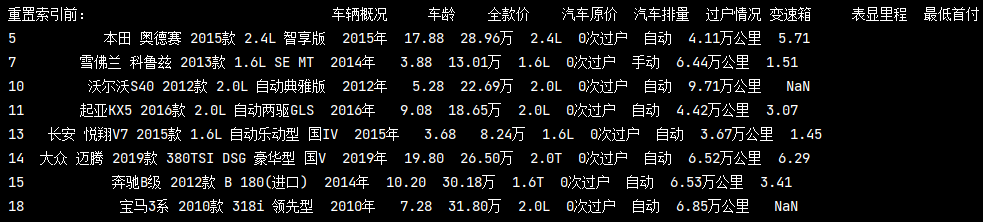
重置索引前:
# 找出在 過戶情況 中所有'0次'的汽車 cars = pd_data[pd_data['過戶情況'].str.contains('0次')] print(cars.reset_index())
重置索引后:
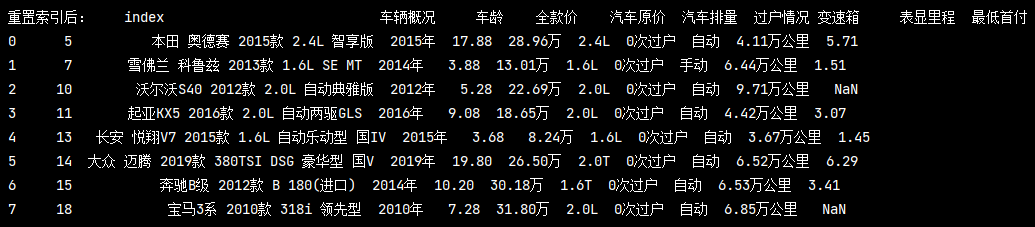
很好,但是不完美,多了一列colm name叫做 index的先前序列號,
不想看到它,有辦法嗎?
drop = True
# 找出在 過戶情況 中所有'0次'的汽車 cars = pd_data[pd_data['過戶情況'].str.contains('0次')] print(cars.reset_index(drop=True))
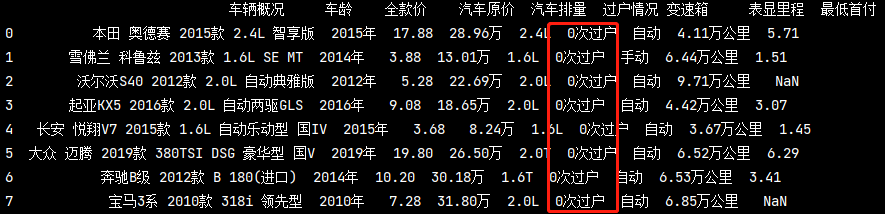
column重命名
# 重命名 pd_data = https://www.cnblogs.com/liuyebai/p/pd_data.rename(columns = {'車輛概況':'車輛詳情'}) print(pd_data)
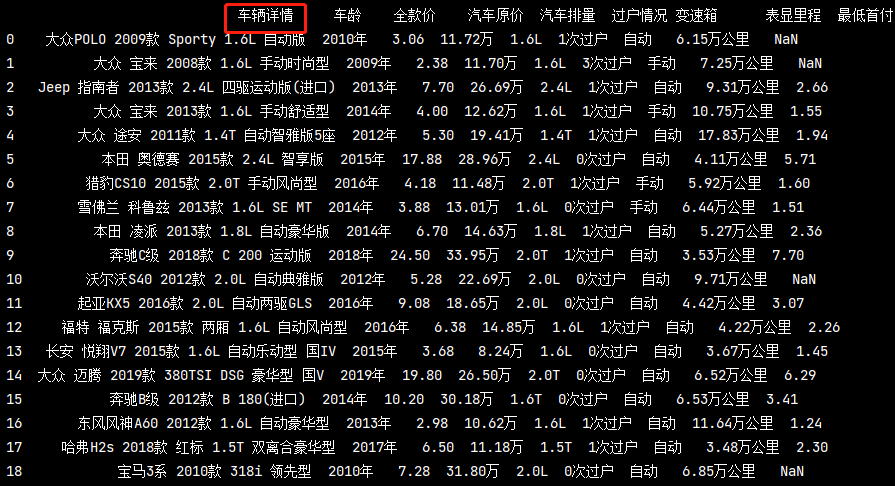
分組統計groupby-單條件
# 統計不同變速箱總里程 pd_data.loc[:, '表顯里程new'] = pd_data['表顯里程'].str.replace('萬公里', '').astype('float32') # 去除 30 ’萬公里‘ trans_mile = pd_data.groupby('變速箱')['表顯里程new'].sum() print(trans_mile)
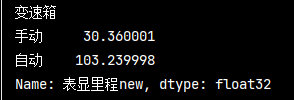
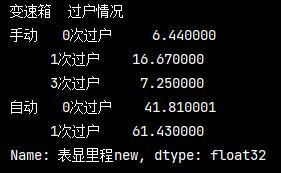
分組統計groupby-多條件
# 統計不同變速箱和過戶情況總里程 pd_data.loc[:, '表顯里程new'] = pd_data['表顯里程'].str.replace('萬公里', '').astype('float32') # 去除 30 ’萬公里‘ trans_mile = pd_data.groupby(['變速箱','過戶情況'])['表顯里程new'].sum() print(trans_mile)
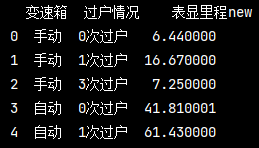
如果再加上一個重置索引 trans_mile.reset_index()
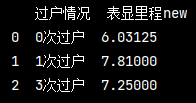
求平均
# 統計不同過戶次數車輛平均里程 pd_data.loc[:, '表顯里程new'] = pd_data['表顯里程'].str.replace('萬公里', '').astype('float32') # 去除 30 ’萬公里‘ trans_mile = pd_data.groupby('過戶情況')['表顯里程new'].mean() print(trans_mile.reset_index())
apply函式
還記得我們爬取大學的那個教程嗎?
我們爬出來的資料如果是985或者是211顯示為1,
如果非985或者211,顯示為2
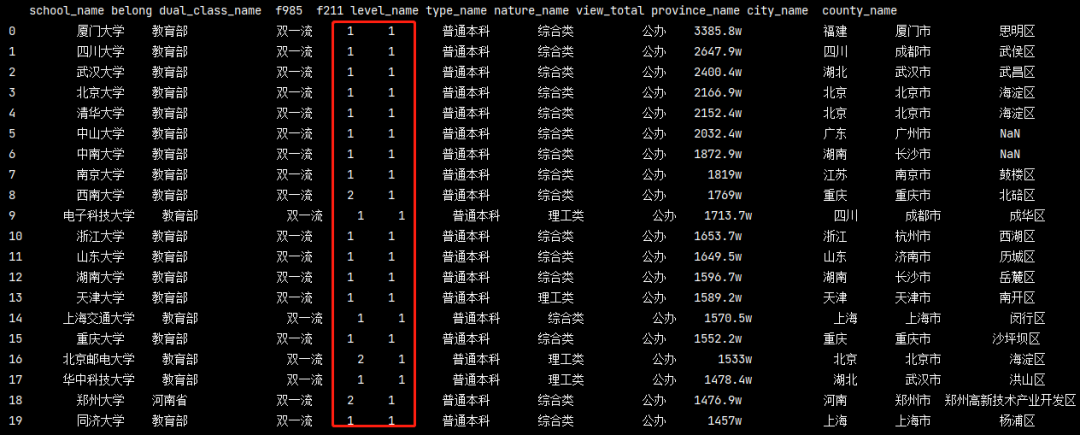
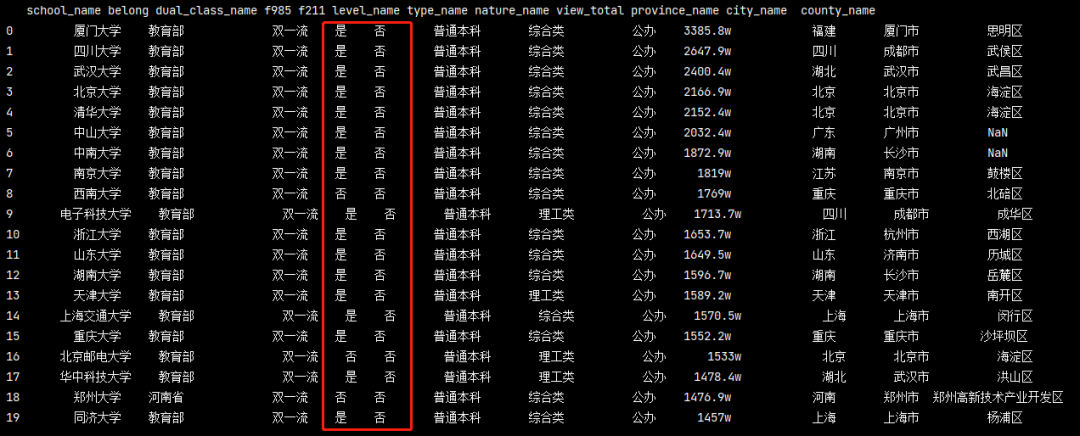
現在我不想要1和2了,因為我看不懂它是什么意思?如果是985或者211,就顯示是,如果不是,就顯示否!
pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./全國高校資料.xlsx') print(pd_data) pd_data1 = pd_data.copy() # 生成一個副本, 防止資料損壞 pd_data['f985'] = pd_data['f985'].apply(lambda x: '是' if x == 1 else '否') # 通過匿名函式解決 pd_data['f211'] = pd_data['f985'].apply(lambda x: '是' if x == 1 else '否') # 通過匿名函式解決 print(pd_data)
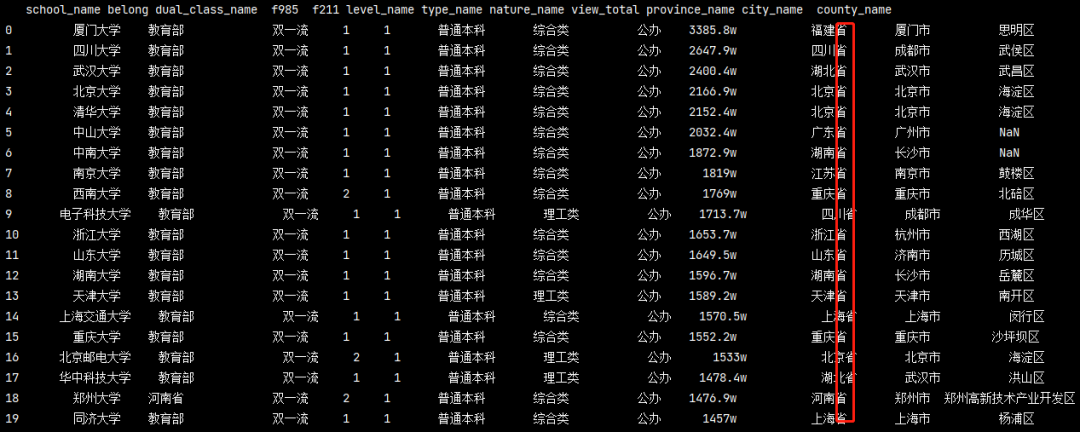
同理利用_lambda_函式我們還可以
給省份這一列后面加個’省’
pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./全國高校資料.xlsx') print(pd_data) pd_data1 = pd_data.copy() # 生成一個副本, 防止資料損壞 pd_data['province_name'] = pd_data['province_name'].apply(lambda x: x+'省') # 通過匿名函式解決 print(pd_data) '''
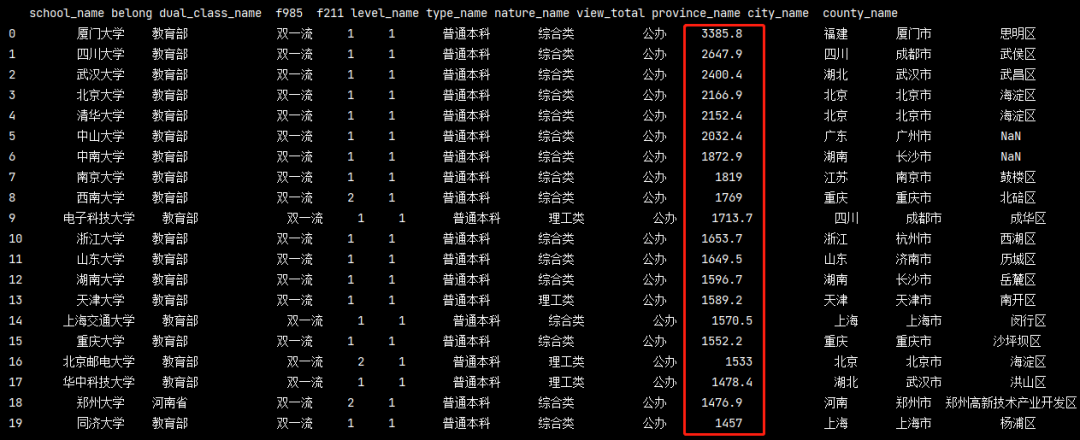
同理利用_lambda_函式我們還可以給
人氣值view_total這一列最后面的’w’
pd_data['view_total'] = pd_data['view_total'].apply(lambda x: x[:-1]) # 通過匿名函式解決 print(pd_data)
求最大最小值
max_view_total = pd_data[pd_data['view_total'] == pd_data['view_total'].max()] print(max_view_total)

min_view_total = pd_data[pd_data['view_total'] == pd_data['view_total'].min()] print(min_view_total)

時間提取
為了便于演示,我加上了一列 Date 選項,如下:
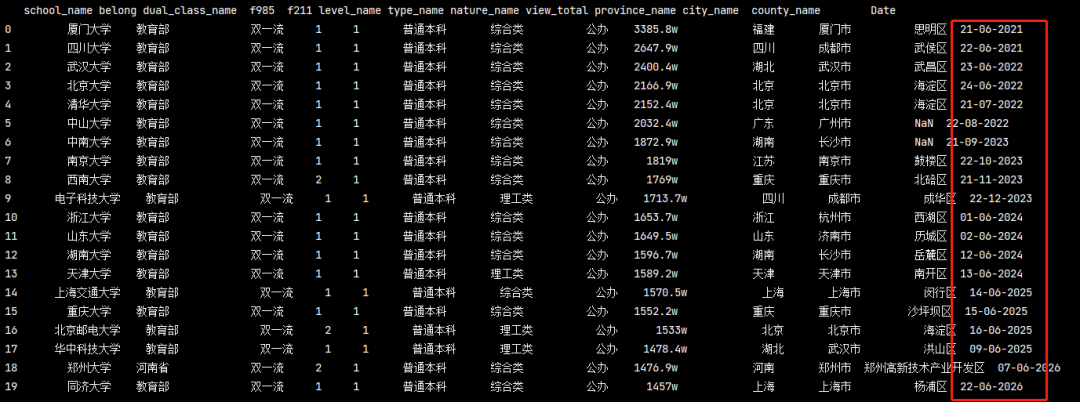
現在我們想提取其中的年份或者月份,我們可以使用 'DatetimeIndex’這個方法來實作,
pd_data = https://www.cnblogs.com/liuyebai/p/pd.read_excel('./全國高校資料.xlsx') pd_data['year'] = pd.DatetimeIndex(pd_data['Date']).year pd_data['month'] = pd.DatetimeIndex(pd_data['Date']).month pd_data['day'] = pd.DatetimeIndex(pd_data['Date']).day print(pd_data)
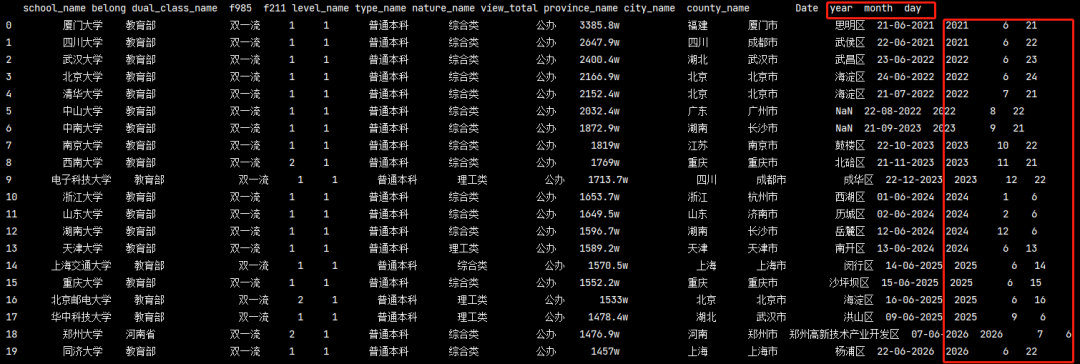
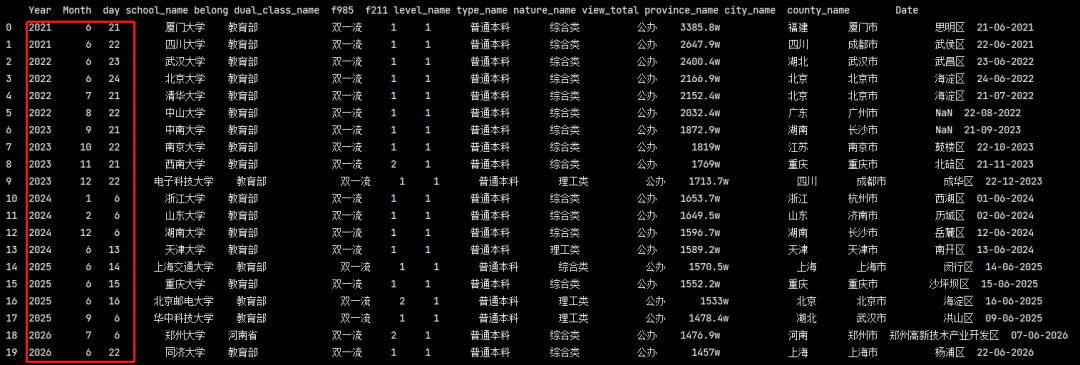
增加列
我想把剛才的生成的年+月+日方法到前三列,可以使用insert()方法來實作
Year = pd.DatetimeIndex(pd_data['Date']).year Month = pd.DatetimeIndex(pd_data['Date']).month day = pd.DatetimeIndex(pd_data['Date']).day pd_data.insert(0, 'Year', Year) pd_data.insert(1, 'Month', Month) pd_data.insert(2, 'day', day) print(pd_data)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/518931.html
標籤:Python