正則運算式03
5.6正則運算式三個常用類
java.util.regex 包主要包括以下三個類:Pattern類、Matcher類和PatternSyntaxException類
-
Pattern類
Pattern物件是一個正則運算式物件,Pattern類沒有公共構造方法,要創建一個Pattern物件,呼叫其公共靜態方法,它回傳一個Pattern物件,該方法接收一個正則運算式作為它的第一個引數,比如:
Pattern r = Pattern.compile(pattern); -
Matcher類
Matcher物件是對輸入字串進行解釋和匹配的引擎,與Pattern類一樣,Matcher類也沒有公共構造方法,需要呼叫Pattern物件的matcher方法來獲得一個Matcher物件
-
PatternSyntaxException類
PatternSyntaxException是一個非強制例外類,它表示一個正則運算式模式中的語法錯誤,
5.6.1Pattern類
JAVA正則運算式, matcher.find()和 matcher.matches()的區別
- find()方法是部分匹配,是查找輸入串中與模式匹配的子串,如果該匹配的串有組還可以使用group()函式
- matches()是全部匹配,是將整個輸入串與模式匹配,如果要驗證一個輸入的資料是否為數字型別或其他型別,一般要用matches()
package li.regexp;
import java.util.regex.Pattern;
//演示matcher方法,用于整體匹配(注意是整個文本的匹配),在驗證輸入的字串是否滿足條件使用
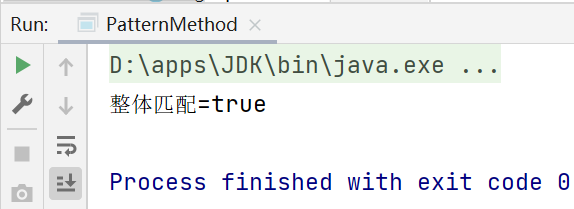
public class PatternMethod {
public static void main(String[] args) {
String content="hello abc hello,儂好";
//String regStr="hello";//false
String regStr="hello.*";//true
boolean matches = Pattern.matches(regStr, content);
System.out.println("整體匹配="+matches);
}
}
matches方法的底層原始碼:
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
return m.matches();
}
可以看到,底層還是創建了一個正則運算式物件,以及使用matcher方法,最后呼叫matcher類的matches方法(該方法才是真正用來匹配的)
5.6.2Matcher類


package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//Matcher類的常用方法
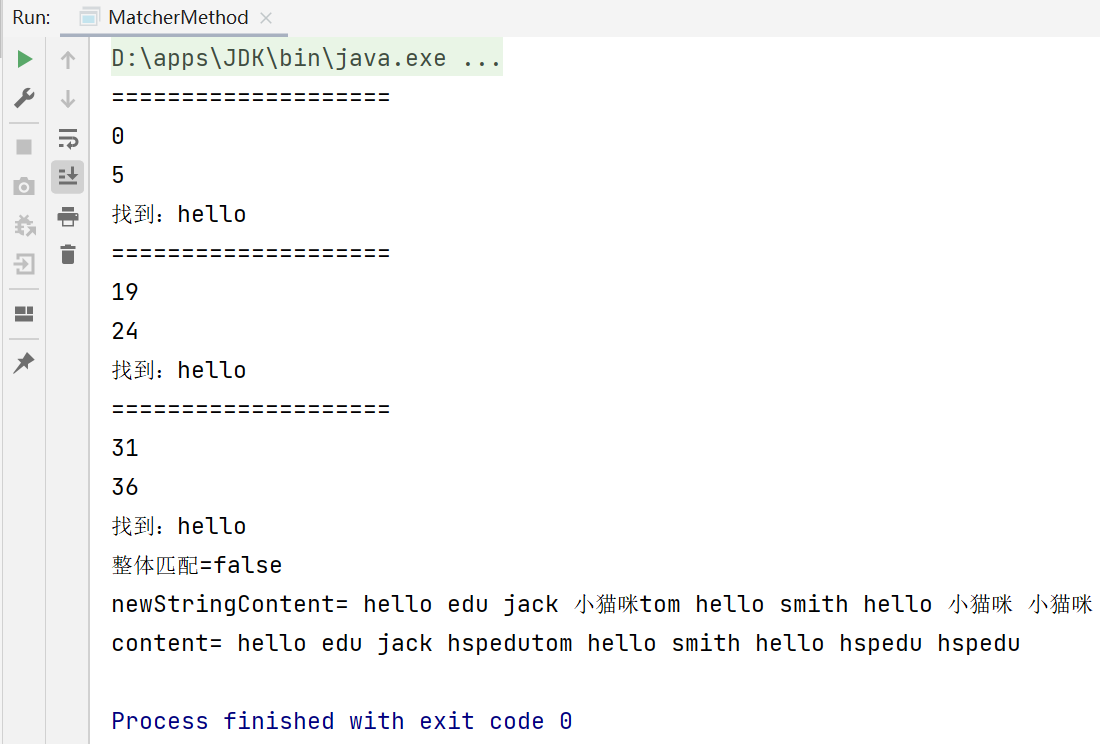
public class MatcherMethod {
public static void main(String[] args) {
String content = "hello edu jack tom hello smith hello";
String reStr = "hello";
Pattern pattern = Pattern.compile(reStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()) {
System.out.println("====================");
System.out.println(matcher.start());
System.out.println(matcher.end());
System.out.println("找到:" + content.substring(matcher.start(), matcher.end()));
}
//整體匹配方法,常用于校驗某個字串是否滿足某個規則
//Pattern的matches方法底層呼叫的就是Matcher類的matches方法
System.out.println("整體匹配=" + matcher.matches());//false
content = "hello edu jack hspedutom hello smith hello hspedu hspedu";
//如果content有字串 hspedu,就將其替換為 小貓咪
reStr = "hspedu";
pattern = Pattern.compile(reStr);
matcher = pattern.matcher(content);
//注意:回傳的字串newStringContent才是替換后的字符,原來的字串content是不變化的
String newStringContent = matcher.replaceAll("小貓咪");
System.out.println("newStringContent= " + newStringContent);
System.out.println("content= " + content);
}
}
5.7反向參考
請看下面的問題:
給定一段文本,請找出所有四個數字連在一起的子串,并且這四個數字要滿足:
- 第一位與第四位相同
- 第二位與第三位相同
在解決前面的問題之前,我們需要了解正則運算式的幾個概念:
-
分組
我們可以用圓括號組成一個比較復雜的匹配模式,那么一個圓括號的部分我們可以看作是一個子運算式/分組
-
捕獲
把正則運算式中的 子運算式/分組 匹配的內容,保存到記憶體中以數字編號或顯式命名的組里,方便后面參考,從左向右,以分組的左括號為標志,第一個出現的分組的組號為1,第二個為2,以此類推,組0代表的是整個正則式
-詳見5.4.6
-
反向參考
圓括號的內容被捕獲后,可以在這個括號后被使用,從而寫出一個比較實用的匹配模式,這個我們稱為反向參考,這種參考既可以是在正則運算式內部,也可以是在正則運算式外部,內部反向參考使用\\\分組號,外部反向參考使用$分組號
5.7.1反向參考的匹配原理
捕獲組(Expression)在匹配成功時,會將子運算式匹配到的內容,保存到記憶體中一個以數字編號的組里,可以簡單的認為是對一個區域變數進行了賦值,這時就可以通過反向參考方式,參考這個區域變數的值,一個捕獲組(Expression)在匹配成功之前,它的內容可以是不確定的,一旦匹配成功,它的內容就確定了,反向參考的內容也就是確定的了,
反向參考必然要與捕獲組一同使用的,如果沒有捕獲組,而使用了反向參考的語法,不同語言的處理方式不一致,有的語言會拋例外,有的語言會當作普通的轉義處理,
- 看幾個小案例
- 要匹配兩個連續的相同數字 (\\\d)\\\1
- 要匹配五個連續的相同數字 (\\\d)\\\1{4}
- 要匹配個位與千位相同,十位與百位相同的數 (\\\d) (\\\d)\\\2\\\1
- 在字串中檢索商品編號,形式如:12321-333999111這樣的號碼,要求滿足前面是一個五位數,然后一個-號,然后是一個九位數,連續的每三位要相同
例子:
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//反向參考
public class RegExp12 {
public static void main(String[] args) {
String content = "ke7887k5225e he12341551l12321-333999111lo ja11ck yy22y xx33333x";
//1. 要匹配兩個連續的相同數字 (\\d)\\1
//String regStr="(\\d)\\1";
//2. 要匹配五個連續的相同數字 (\\d)\\1{4}
//String regStr="(\\d)\\1{4}";
//3. 要匹配個位與千位相同,十位與百位相同的數 (\\d)(\\d)\\2\\1
//String regStr="(\\d)(\\d)\\2\\1";
//在字串中檢索商品編號,形式如:12321-333999111這樣的號碼,
// 要求滿足前面是一個五位數,然后一個-號,然后是一個九位數,連續的每三位要相同
String regStr="\\d{5}-(\\d)\\1{2}(\\d)\\2{2}(\\d)\\3{2}";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
while (matcher.find()){
System.out.println("找到:"+matcher.group(0));
}
}
}
5.7.2去重
經典的結巴程式
把類似 “我.....我我要......學學學學.......編程java!”
這樣一句話,通過正則運算式將其修改成“我要學編程java!”
package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
//去重
public class RegExp13 {
public static void main(String[] args) {
String content = "我.....我我要......學學學學.......編程java!";
//1.去掉所有的 .
Pattern pattern = Pattern.compile("\\.");
Matcher matcher = pattern.matcher(content);
content = matcher.replaceAll("");//用空串替換掉.
System.out.println("去掉所有的\".\"=" + content);
//2.去掉重復的字
//思路:
//2.1使用(.)\\1+去匹配連續重復的字
//2.2使用反向參考$1來替換匹配到的內容
//--注意:這里的正則運算式匹配的是多個重復的字,但是捕獲的內容是重復的字中的一個,即圓括號
pattern = Pattern.compile("(.)\\1+");//分組的捕獲內容記錄到$1中
matcher = pattern.matcher(content);//因為正則運算式改變了,需要重置 matcher
while (matcher.find()) {
System.out.println("找到=" + matcher.group(0));
}
//使用反向參考$1來替換匹配到的內容
//注意:雖然上面的正則運算式是匹配到的連續重復的字,但是捕獲的是圓括號里面的內容,所以捕獲的組里面的字只有一個,
//因此使用replaceAll("$1")的意思是:用捕獲到的單個字去替換匹配到的多個重復的字
content = matcher.replaceAll("$1");
System.out.println("去掉重復的字=" + content);
//2.相當于:
// content = Pattern.compile("(.)\\1+").matcher(content).replaceAll("$1");
// System.out.println(content);
}
}

5.8替換分割匹配
5.8.1替換
使用正則運算式替換字串可以直接呼叫 public String replaceAll(String regex,String replacement) ,它的第一個引數是正則運算式,第二個引數是要替換的字串,
給出一段文本:
/*
2000年5月,JDK1.3、JDK1.4和J2SE1.3相繼發布,幾周后其獲得了Apple公司Mac OS X的工業標準的支持,2001年9月24日,J2EE1.3發布,2002年2月26日,J2SE1.4發布,自此Java的計算能力有了大幅提升,
*/
將這段文字中的 JDK1.3 JDK1.4 統一替換成 JDK
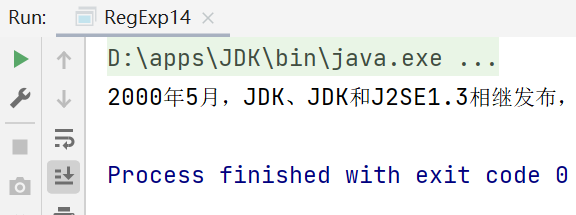
package li.regexp;
//替換
public class RegExp14 {
public static void main(String[] args) {
String content = "2000年5月,JDK1.3、JDK1.4和J2SE1.3相繼發布,幾周后其獲得了" +
"Apple公司Mac OS X的工業標準的支持,2001年9月24日,J2EE1.3發布,2002" +
"年2月26日,J2SE1.4發布,自此Java的計算能力有了大幅提升,";
//使用正則運算式,將JDK1.3/JDK1.4 統一替換成 JDK
content = content.replaceAll("JDK1.[34]", "JDK");
System.out.println(content);
}
}
5.8.3判斷
String類 public boolean matches(String regex)
驗證一個手機號碼,要求必須是以138、139開頭的
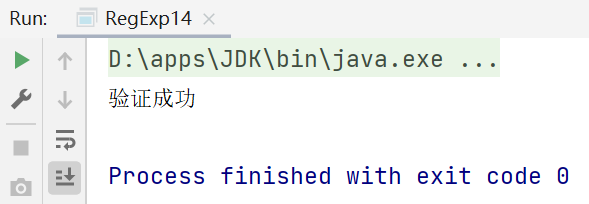
package li.regexp;
//匹配
public class RegExp14 {
public static void main(String[] args) {
//驗證一個手機號碼,要求必須是以138、139開頭的十一位數字
String content="13899988880";
if (content.matches("13[89]\\d{8}")) {//matches是整體匹配,不用加定位符
System.out.println("驗證成功");
}else {
System.out.println("驗證失敗");
}
}
}
5.8.3分割
String類 public String[] split(String regex)
例子
有如下字串,要求按照#或者-或者~或者數字來分割
“hello#abc-jack12smith~北京”
package li.regexp;
//分割
public class RegExp14 {
public static void main(String[] args) {
//要求按照# 或者- 或者~ 或者數字 來分割
String content = "hello#abc-jack12smith~北京";
String[] split = content.split("#|-|~|\\d+");
for (int i = 0; i < split.length; i++) {
System.out.println(split[i]);
}
}
}

5.9本章習題
5.9.1驗證電子郵件格式
規定電子郵件格式為:
- 只能有一個@
- @前面是用戶名,可以是
a-z A-Z 0-9_-字符 - @后面是域名,并且域名只能是英文字母,比如 shouhu.com 或者 tsinghua.org.cn
- 寫出對應的正則運算式,驗證輸入的字串是否滿足規則
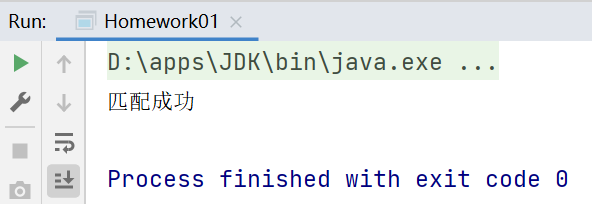
package li.regexp;
public class Homework01 {
public static void main(String[] args) {
String content = "[email protected]";
//因此,String 的 marches方法是整體匹配,不用加定位符,但是建議加上
if (content.matches("^[\\w-]+@([a-zA-z]+\\.)+[a-zA-z]+$")) {
System.out.println("匹配成功");
} else {
System.out.println("匹配失敗");
}
}
}
原始碼分析:
- 點擊matches方法,可以看到String的marches方法:
public boolean matches(String regex) {
return Pattern.matches(regex, this);
}
- 再點擊return的Pattern.matches方法:
public static boolean matches(String regex, CharSequence input) {
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(input);
return m.matches();
}
- m.matches()方法:
/**
* Attempts to match the entire region against the pattern.-嘗試將整個區域與模式匹配
*/
public boolean matches() {
return match(from, ENDANCHOR);
}
因此,String 的 marches方法是整體匹配,不用加定位符,但是建議加上
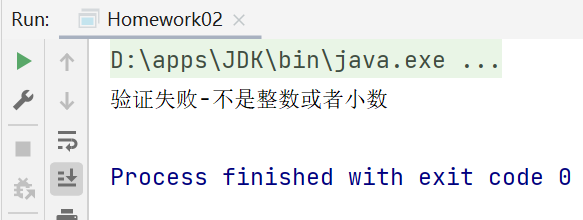
5.9.2驗證整數或者小數
要求驗證是不是整數或者小數
提示:這個題要考慮整數和負數
比如:123,-345,34.89,-87.0,-0.01,0.45等
package li.regexp;
public class Homework02 {
public static void main(String[] args) {
//要求驗證是不是整數或者小數
//提示:這個題要考慮整數和負數
//比如:123,-345,34.89,-87.0,-0.01,0.45等
/**
* 思路:
* 1.先寫出簡單的正則運算式
* 2.再根據各種情況逐步地完善
* 2.1 [-+]? 考慮的是符號
* 2.2 小數點以及小數點后面的數字可以用 (\\.\\d+)?
* 2.3 小數點前面的應該存在數字,且分為兩種情況:
* 2.3.1情況一:第一個應該以1-9開頭,剩下的可能有0到多個數字, ([1-9]\\d*)
* 2.3.2情況二:小數點前面只有一位數字 0
* 兩種情況整合起來就是 ([1-9]\\d*|0)
*/
String content = "-09.9";
//"^[-+]?([1-9]\\d*|0)(\\.\\d+)?$"
if (content.matches("^[-+]?([1-9]\\d*|0)(\\.\\d+)?$")) {
System.out.println("驗證成功-是整數或者小數");
} else {
System.out.println("驗證失敗-不是整數或者小數");
}
}
}
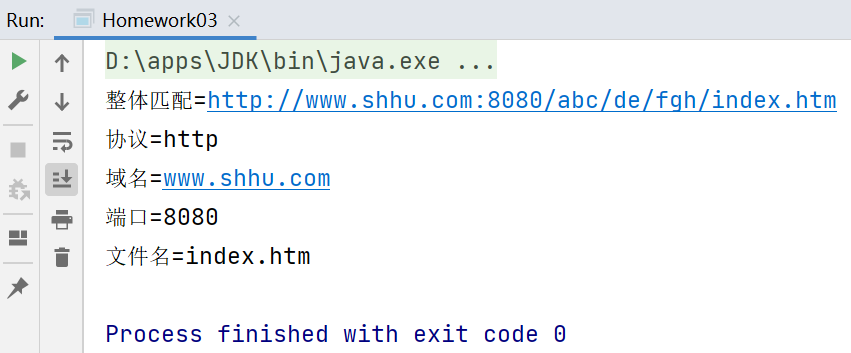
5.9.3決議URL
對一個url進行決議 http://www.shhu.com:8080/abc/index.htm
- 要求得到協議是什么 http
- 域名是什么 www.shhu.com
- 埠是什么 8080
- 檔案名是什么 index.htm
思路:分組,4組,分別獲取到對應的值

package li.regexp;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Homework03 {
public static void main(String[] args) {
String content = "http://www.shhu.com:8080/abc/de/fgh/index.htm";
//如果名稱中要求有特殊符號,就將特殊符號加入到中括號中
String regStr = "^([a-zA-Z]+)://([a-zA-Z.]+):(\\d+)[\\w-/]*/([\\w.]+)$";
Pattern pattern = Pattern.compile(regStr);
Matcher matcher = pattern.matcher(content);
if (matcher.matches()) {//整體匹配,如果匹配成功,可以通過group(x),獲取對應分組的內容
System.out.println("整體匹配=" + matcher.group(0));
System.out.println("協議=" + matcher.group(1));
System.out.println("域名=" + matcher.group(2));
System.out.println("埠=" + matcher.group(3));
System.out.println("檔案名=" + matcher.group(4));
} else {
System.out.println("沒有匹配成功");
}
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/519102.html
標籤:Java
上一篇:JVM中的行程和執行緒