Python正則運算式
目錄- Python正則運算式
- 快速參考
- 函式詳解
- match()
- search()
- 捕獲和分組
- Match物件
- sub()
- compile()
- findall()
- finditer()
- split()
- 參考博客與示例代碼
快速參考
常用函式:
re.match():從字串的起始位置匹配一個正則運算式,
re.search():掃描整個字串并回傳第一個成功的匹配,
re.sub():用于替換字串中的匹配項,
re.compile():用于編譯正則運算式,生成一個正則運算式(Pattern)物件,供match()和search()這兩個函式使用,
re.findAll():在字串中找到正則運算式所匹配的所有子串,并回傳一個串列,
re.finditer():在字串中找到正則運算式所匹配的所有子串,并回傳一個迭代器,
re.split():split 方法按照能夠匹配的子串將字串分割后回傳串列,
元字符:具有特殊含義的字符
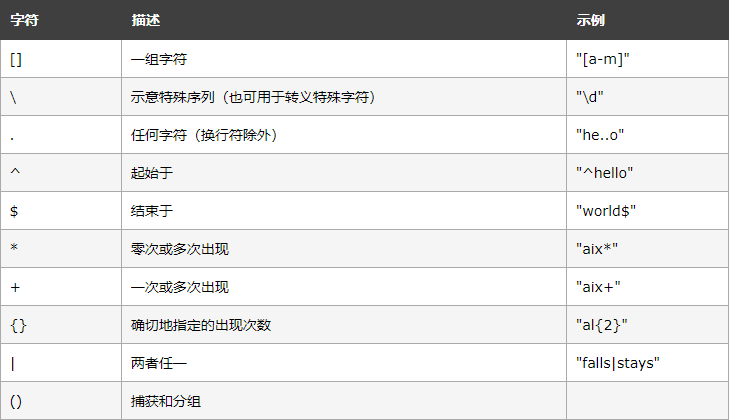
特殊序列:特殊序列指的是\后跟下表中的某個字符,擁有特殊含義,
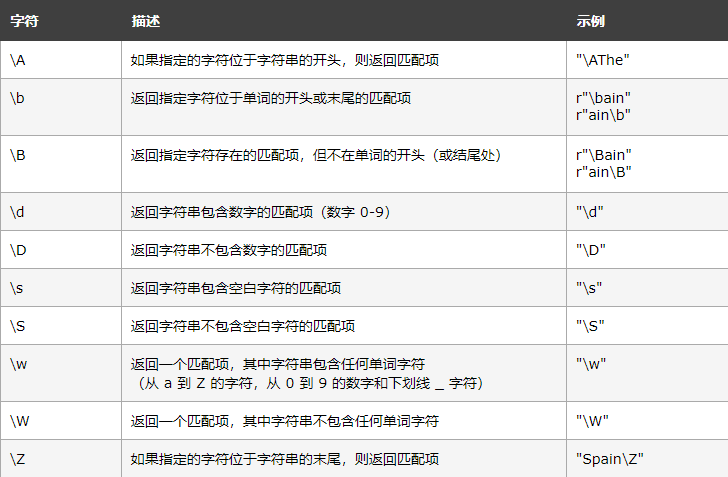
集合:集合(Set)是一對方括號 [] 內的一組字符,具有特殊含義
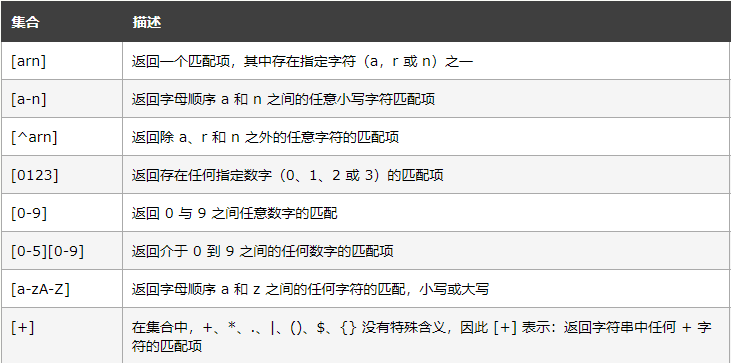
正則運算式修飾符

函式詳解
match()
re.match(): 從字串的起始位置(開頭)匹配一個正則運算式,匹配成功回傳一個Match物件,匹配失敗回傳None,
re.match(pattern, string, flags=0)
# pattern:正則運算式;string:字串;flags:正則運算式修飾符
示例:
_str = 'https://www.baidu.com/'
print(re.match('https', _str))
print(re.match('baidu', _str))
結果圖:
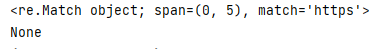
search()
re.search():掃描整個字串來匹配正則運算式,如果匹配成功,則回傳第一個匹配成功的Match物件,匹配失敗則回傳None,
re.search(pattern,string,flags=0)
# pattern:正則運算式;string:字串;flags:正則運算式修飾符
示例:
_str = 'https://www.baidu.com/'
print(re.search('baidu', _str))
print(re.search('goole', _str))
結果圖:
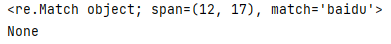
捕獲和分組
示例:
_str = 'Cats are smarter than dogs'
# r:字串為非轉義的原始字串 ():捕獲和分組 .:除了換行符的所有字符 *:零次或者多次出現
# (.*)是第一個分組,.*表示匹配除了換行符之外的所有字符;(.*?)是第二個分組,.*后面的?代表非貪婪模式,只匹配符合條件的最少的字符
# 最后一個.*不是分組,不會計入匹配結果;|表示兩者任一
# re.M:多行匹配,影響^和$;re.I:大小寫不敏感
# 匹配的正則運算式中的空格對結果影響很大
matchObject = re.match(r'(.*) are (.*?) .*', _str, re.M | re.I)
if matchObject:
print(matchObject.groups())
print(matchObject.group())
print(matchObject.group(1))
print(matchObject.group(2))
結果截圖:

groups是包含分組匹配項的元組;group()或者group(0)是整個正則運算式的匹配項;group(1)和group(2)分別是兩個分組的匹配項;當呼叫group(3)時會報錯,因為沒有第三個分組
Match物件
_str = 'https://www.baidu.com/'
_result = re.match('https', _str)
print(_result)
print(_result.span())
print(_result.start())
print(_result.end())
print(_result.group())

sub()
re.sub():用于替換字串中正則運算式的匹配項,
re.sub(pattern, repl, string, count=0, flags=0)
# pattern:正則運算式;repl:替換的字串或者函式;string:字串;
# count:最大替換次數,默認0代表替換所有匹配正則運算式;flags:正則運算式修飾符
示例:
_phone = '2004-959-559 # 這是一個國外電話號碼'
# 洗掉字串中的Python注釋
_phone = re.sub(r'#.*$', '', _phone)
print(_phone)
# 洗掉字串中的-
_num = re.sub(r'\D', '', _phone)
print(_num)
# 洗掉字串中的-
_num = re.sub(r'-', '', _phone)
print(_num)
# 洗掉字串中第一個-
_num = re.sub(r'-', '', _phone, 1)
print(_num)
結果圖:

示例(repl引數是一個函式):
# 將字串中的匹配的數字*2
def doubleNum(matched):
_value = https://www.cnblogs.com/wind-and-sky/archive/2022/10/24/int(matched.group('value'))
return str(_value * 2)
_str = 'cxk666cxk456cxk250'
# 分組匹配
_result = re.sub(r'(?P<value>\d+)', doubleNum, _str)
print(_result)
結果圖:
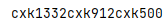
compile()
compile()函式用于編譯正則運算式,生成一個正則運算式物件(RegexObject) ,供match()和search()這兩個函式使用,
re.compile(pattern[, flags])
# pattern:正則運算式;flags:正則運算式修飾符
示例:
_str = 'cxk666cxk456cxk250'
# re.compile函式,compile函式用于編譯正則運算式,生成一個正則運算式物件
_pattern = re.compile(r'\d+') # 匹配至少一個數字
_result = _pattern.search(_str)
print(_result)
結果圖:

findall()
findall():在字串中找到正則運算式所匹配的所有子字串并回傳一個串列,如果有多個匹配模式,則回傳元祖串列;如果沒有找到匹配子串,則回傳空串列,
findall(string[, pos[, endpos]])
# string:字串;pos:可選引數,字串的起始位置,默認為0;endpos:可選引數,字串的結束位置,默認為字串長度,
示例:
_str = 'cxk666cxk456cxk250'
_pattern = re.compile(r'\d+') # 匹配至少一個數字
_result = _pattern.findall(_str)
print(_result)
結果圖:

多個匹配模式示例:
_str = 'cxk666cxk456cxk250'
_pattern = re.compile(r'([a-z]+)(\d+)') #按小寫字母和數字分開匹配
_result = _pattern.findall(_str)
print(_result)
結果圖:
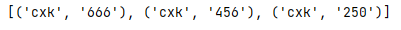
finditer()
finditer():在字串中找到正則運算式所匹配的所有子串,并將結果作為一個迭代器回傳,
re.finditer(pattern, string, flags=0)
# string:字串;pattern:正則運算式;flags:正則運算式修飾符
示例:
# finditer
_str = 'cxk666cxk456cxk250'
_iter = re.finditer(r'\d+', _str)
for _it in _iter:
print(_it.group())
結果圖:

split()
split() 方法按照能夠匹配的子串將字串分割后回傳串列,注意:是分割,而不是取某一部分,
re.split(pattern, string[, maxsplit=0, flags=0])
# pattern:正則運算式;string:字串;maxsplit:分隔次數,默認為 0,不限制次數;flags:正則運算式修飾符
示例:
_str = 'cxk sing jump rap basketball'
_result = re.split(r'(\S+ )', _str)
print(_result)
結果圖:

參考博客與示例代碼
示例代碼:https://gitee.com/mr-wildfire/PythonRegExDemo/
參考博客:
? 感謝:Python 正則運算式 | 菜鳥教程 (runoob.com)
? 感謝:Python RegEx (w3school.com.cn)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/519113.html
標籤:其他