JD-hotkey 是京東 APP 后臺熱資料探測框架,歷經多次高壓壓測和 2020 年京東 618 大促考驗,
在上線運行的這段時間內,每天探測的key數量數十億計,精準捕獲了大量爬蟲、刷子用戶,另準確探測大量熱門商品并毫秒級推送到各個服務端記憶體,大幅降低了熱資料對資料層的查詢壓力,提升了應用性能,
該框架歷經多次壓測,性能指標主要有兩個:
1 探測性能:8核單機worker端每秒可接收處理16萬個key探測任務,16核單機至少每秒平穩處理30萬以上,實際壓測達到37萬,CPU平穩支撐,框架無例外,
2 推送性能:在高并發寫入的同時,對外推送目前性能約平穩推送每秒10-12萬次,譬如有1千臺server,一臺worker上每秒產生了100個熱key,那么這1秒會平穩推送100 * 1000 = 10萬次,10萬次推送會明確在1s內全部送達,如果是寫入少,推送多,以純推送來計數的話,該框架每秒可穩定對外推送40-60萬次平穩,80萬次極限可撐幾秒,
每秒單機吞吐量(寫入+對外推送)目前在70萬左右穩定,
在真實業務場景中,可用1:1000的比例,即1臺worker支撐1000臺業務服務端的key探測任務,即可帶來極大的資料存盤資源節省(如對redis集群的擴充),
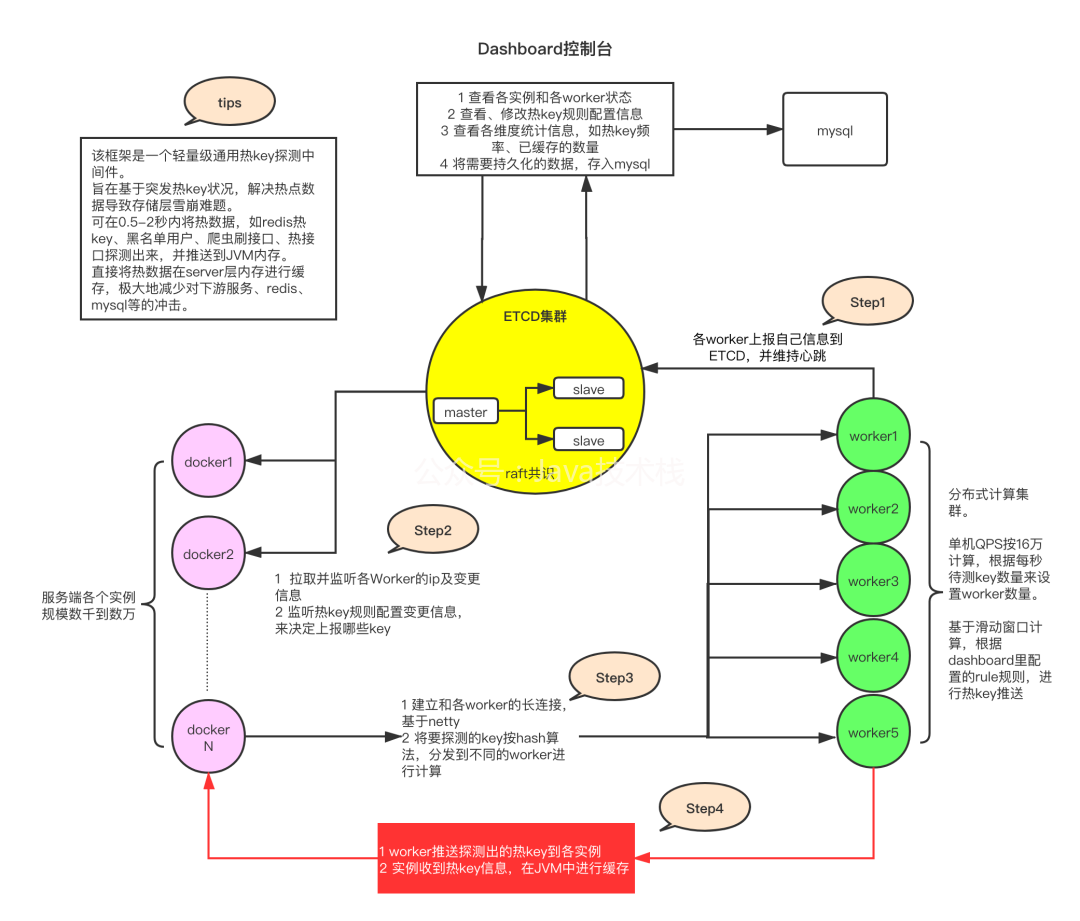
介紹
對任意突發性的無法預先感知的熱點請求,包括并不限于熱點資料(如突發大量請求同一個商品)、熱用戶(如爬蟲、刷子)、熱介面(突發海量請求同一個介面)等,進行毫秒級精準探測到,
然后對這些熱資料、熱用戶等,推送到該應用部署的所有機器JVM記憶體中,以大幅減輕對后端資料存盤層的沖擊,并可以由客戶端決定如何使用這些熱key(譬如對熱商品做本地快取、對熱用戶進行拒絕訪問、對熱介面進行熔斷或回傳默認值),這些熱key在整個應用集群內保持一致性,
核心功能:熱資料探測并推送至集群各個服務器,
適用場景:
- mysql熱資料本地快取
- redis熱資料本地快取
- 黑名單用戶本地快取
- 爬蟲用戶限流
- 介面、用戶維度限流
- 單機介面、用戶維度限流限流
- 集群用戶維度限流
- 集群介面維度限流
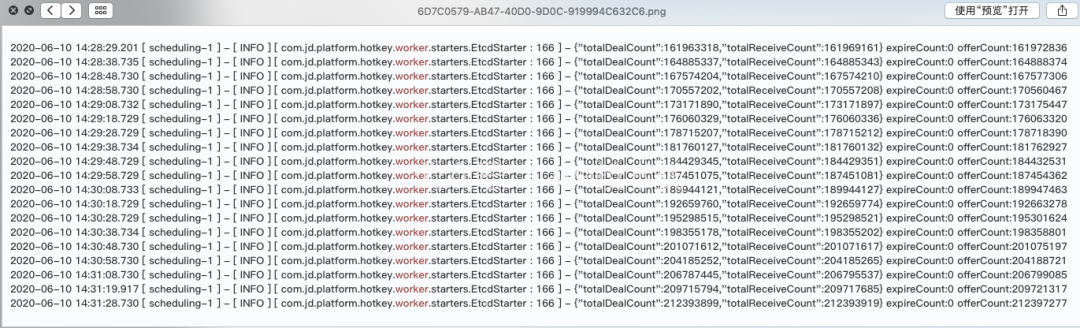
worker 端強悍的性能表現
每10秒列印一行,totalDealCount代表處理過的key總量,可以看到每10秒處理量在270萬-310萬之間,對應每秒30萬左右QPS,
僅需要很少的機器,即可完成海量key的實時探測計算推送任務,比擴容redis集群規模成本低太多,
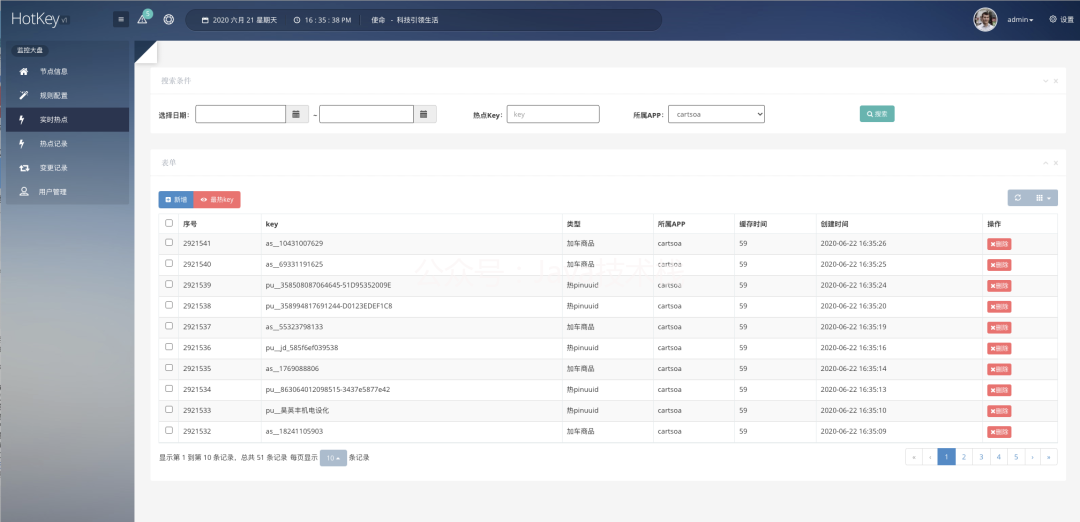
界面效果
來源:https://gitee.com/jd-platform-opensource/hotkey
近期熱文推薦:
1.1,000+ 道 Java面試題及答案整理(2022最新版)
2.勁爆!Java 協程要來了,,,
3.Spring Boot 2.x 教程,太全了!
4.別再寫滿屏的爆爆爆炸類了,試試裝飾器模式,這才是優雅的方式!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/521786.html
標籤:Java
上一篇:從阿里規約看Spring事務