
大家好,又見面了,
本文是筆者作為掘金技術社區簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面,如果感興趣,歡迎關注以獲取后續更新,
在上一篇檔案《聊一聊作為高并發系統基石之一的快取,會用很簡單,用好才是技識訓》中,我們對快取的龐大體系進行了個初步的探討,浮光掠影般的介紹了本地快取、集中快取、多級快取的不同形式,也走馬觀花似的初識了快取設計的關鍵原則與需要關注的典型問題,
作為《深入理解快取原理與實戰設計》系列專欄的第二篇內容,從本篇開始,我們將聚焦快取體系中的具體場景,分別進行深入的闡述與探討,本篇我們就一起具體地聊一聊快取使用中需要關注的典型問題與可靠性防護措施,
在分布式系統盛行的今天,尤其是在一些用戶體量比較大的互聯網業務系統里面,快取充當著扛壓屏障的作用,當前各互聯網系統可以扛住動輒數萬甚至數十萬的并發請求量,快取機制功不可沒,而一旦快取出現問題,對系統的影響往往也是致命的,所以在快取的使用時必須要考慮完備的兜底與災難應對策略,

熱點資料與淘汰策略
大部分服務端使用的抗壓型快取,為了保證快取執行速度,普遍都是將資料存盤在記憶體中,而受限于硬體與成本約束,記憶體的容量不太可能像磁盤一樣近乎無限的去隨意擴容使用,對于實際資料量極其龐大且無法將其全部存盤于快取中的時候,我們需要保證存盤在快取中的有限部分資料要盡可能的命中更多的請求,即要求快取中存盤的都是熱點資料,
說到這里,就會存在一個不得不面對的問題:當資料量超級大而快取的記憶體容量有限的情況下,如果容量滿了該怎么辦?
斷舍離!
快取實作的時候,必須要有一種機制,能夠保證記憶體中的資料不會無限制增加 —— 也即資料淘汰機制,資料淘汰機制,是一個成熟的快取體系所必備的基礎能力,這里有個概念需要厘清,即資料淘汰策略與資料過期是兩個不同的概念,
-
資料過期,是快取系統的一個正常邏輯,是符合業務預期的一種資料洗掉機制,即設定了有效期的快取資料,過期之后從快取中移除,
-
資料淘汰,是快取系統的一種“有損自保”的
降級策略,是業務預期之外的一種資料洗掉手段,指的是所存盤的資料沒達到過期時間,但快取空間滿了,對于新的資料想要加入快取中時,快取模塊需要執行的一種應對策略,
我們把快取當做一個容器,試想一下,一個容器已滿的情況下,繼續往里面放東西,可以有什么應對之法?無外乎兩種:
-
直接拒絕,因為滿了,放不下了,
-
從容器里面扔掉一些已有內容,然后騰挪出部分空間出來,將新的東西放進來,
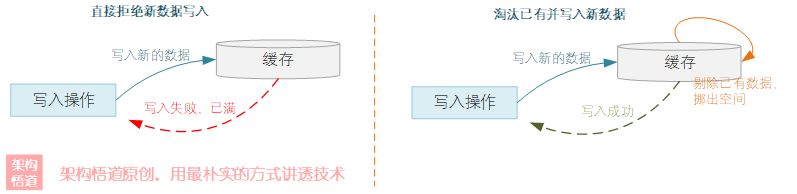
進一步地,當決定采用先從容器中扔掉一些已有內容的時候,又會面臨一個新的抉擇,應該扔掉哪些內容?實踐中常用的也有幾種方案:
-
一切隨緣,隨機決定,從容器中現有的內容中
隨機扔掉剔除一些, -
按需排序,保留常用,即基于
LRU策略,將最久沒有被使用過的資料給剔除掉, -
提前過期,淘汰出局,對于一些設定了過期時間的記錄,將其按照過期時間點進行排序,將最近即將過期的資料剔除(類似讓其
提前過期), -
其它策略,自行實作快取時,除了上述集中常見策略,也可以根據業務的場景構建業務自定義的淘汰策略,比如根據
創建日期、根據最后修改日期、根據優先級、根據訪問次數等等,
一些主流的快取中間件的淘汰機制大都也是遵循上述的方案來實作的,比如Redis提供了高達6種不同的資料淘汰機制,供使用方按需選擇,將有限的空間僅用來存盤熱點資料,實作快取的價值最大化,如下:
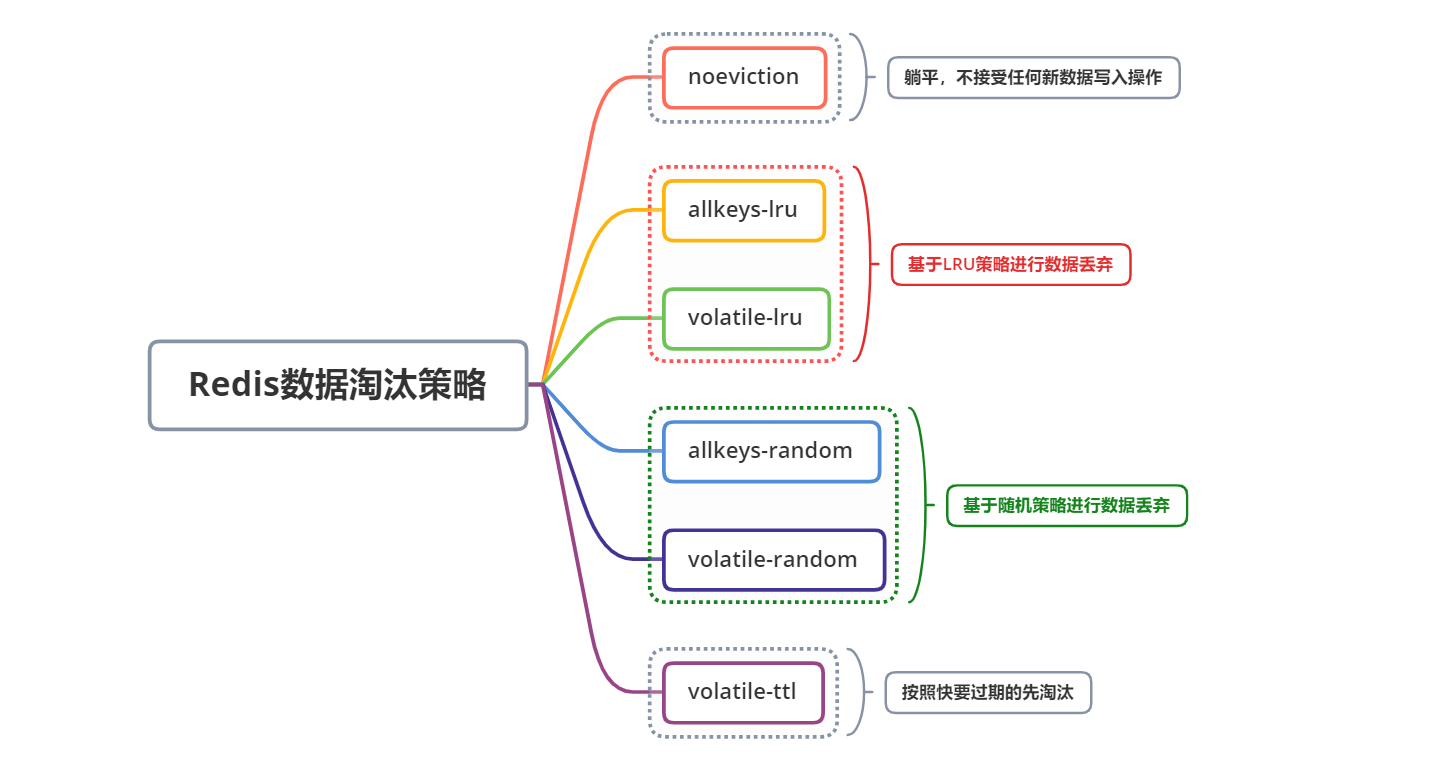
從上圖可以看出,Redis對隨機淘汰和LRU策略進行的更精細化的實作,支持將淘汰目標范圍細分為全部資料和設有過期時間的資料,這種策略相對更為合理一些,因為一般設定了過期時間的資料,本身就具備可洗掉性,將其直接淘汰對業務不會有邏輯上的影響;而沒有設定過期時間的資料,通常是要求常駐記憶體的,往往是一些配置資料或者是一些需要當做白名單含義使用的資料(比如用戶資訊,如果用戶資訊不在快取里,則說明用戶不存在),這種如果強行將其洗掉,可能會造成業務層面的一些邏輯例外,
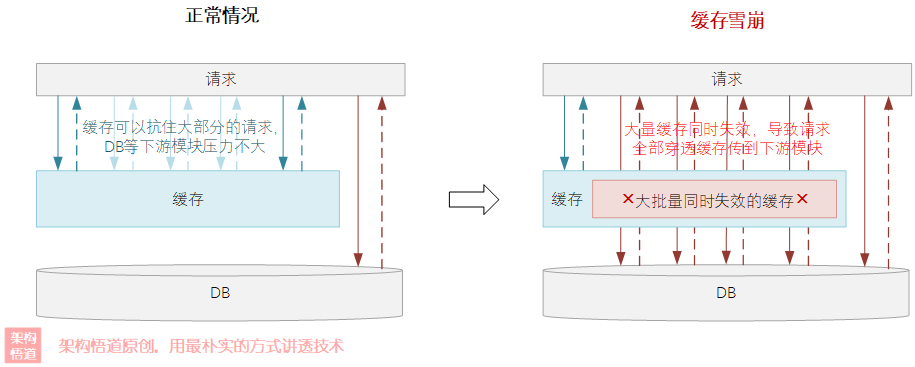
快取雪崩:避免快取的集中失效
為了限制快取的數量,很多的快取記錄都會設定一定的有效期,到期后自動失效,這種在一些批量快取構建或者全量快取重建時,因為設定了相同的失效時間,會導致大量甚至全部的快取資料在短時間內集體失效,這樣會導致大量的請求無法命中快取而直接流轉到了下游模塊,導致系統癱瘓,也即快取雪崩,
其實解決的思路也很簡單,避免出現集中失效就好咯,如何避免呢?
一種簡單的策略,就是批量加載的場景,將過期時間在一個固定時間段內以毫秒級別進行隨機打散,比如本來要設定每條記錄過期時間為5分鐘,則批量加載的時候可以設定過期時間為5~10分鐘之間的任意一個毫秒數,這樣就可以有效的避免資料集中失效,避免出現快取雪崩而影響業務穩定,
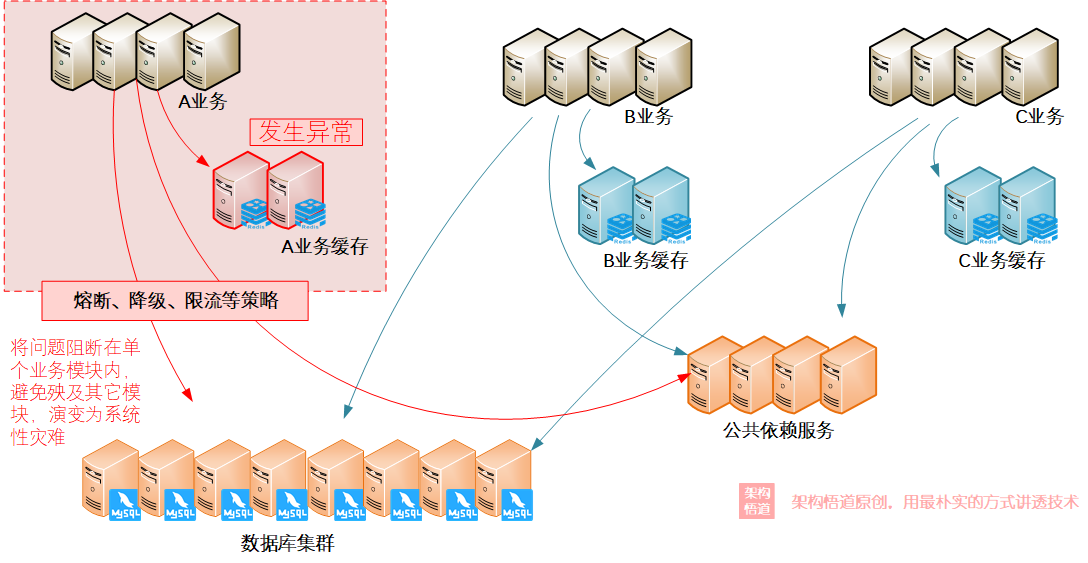
此外,在一些大型系統里面,尤其是一些分布式微服務化的系統中,很多情況下都會有多個獨立的快取服務,而最終持久化資料則集中存盤,如果某個獨立快取真的出現了快取雪崩,業務層面應該如何將受損范圍控制在僅自身模塊、避免殃及資料庫以及下游公共服務模塊,進而避免業務出現系統性癱瘓呢?這個就需要結合服務治理中的一些手段來綜合防范了,比如服務降級、服務熔斷、以及介面限流等策略,
快取擊穿:有效的冷資料預熱加載機制
正如前面所提到的,基于記憶體的快取,受記憶體容量限制,往往都會加載一些熱點資料,而這些熱點快取資料,可以命中大部分的業務請求,少部分沒有命中快取的資料,則直接轉由業務模塊進行處理(比如從MySQL里面進行查詢),
先來看一個例子:
互動論壇系統,使用Redis作為快取,快取最近1年的帖子資訊,如果用戶查看的帖子是最近1年的,則直接從Redis中查詢并回傳,如果用戶查看的帖子是1年前的,則從MySQL中進行撈取并回傳,
因為論壇系統中,大部分人會閱讀或者查看的都是最近新發的帖子,只有極少數的人可能會偶爾“挖墳”查看一年前的歷史帖子,系統上線前會根據冷熱請求的比例與總量情況,評估需要部署的硬體規模,以確保可以支撐住線上正常的訪問請求,但為了避免快取資料被無限撐滿,一般業務快取資料都會設定一個過期時間,來保證快取資料的定期清理與更新,
近段時間,娛樂圈的雷聲不斷,各種新鮮的大瓜也讓吃瓜群眾撐到打嗝,
有一天,娛樂圈當紅流量明星李某某突然被爆料與某網紅存在某些不正當的關系,甚至被爆有多次PC被捕的驚天大瓜,引起粉絲和路人的強烈關注,
吃瓜群眾們群情高漲、熱搜一波蓋過一波、帖子的瀏覽量光速攀升,論壇系統在快取模塊的加持下,雖然整體CPU和記憶體占用都飆升上去了,倒也相安無事,
但天有不測風云,恰好這個時候,這條帖子的記錄在快取中過期被洗掉了,然后狂濤巨浪般的請求涌向了后端的資料庫,讓資料庫原地癱瘓,進而陸陸續續殃及了整個論壇系統,這就是典型的一個快取擊穿的問題,
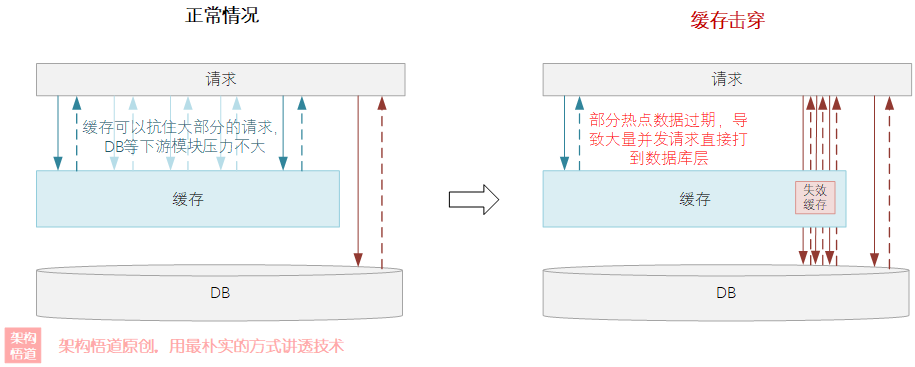
快取擊穿和前面提到的快取雪崩產生的原因其實很相似,區別點在于:
-
快取雪崩是大面積的快取失效導致大量請求涌入資料庫,
-
快取擊穿是少量快取失效的時候恰好失效的資料遭遇大并發量的請求,導致這些請求全部涌入資料庫中,
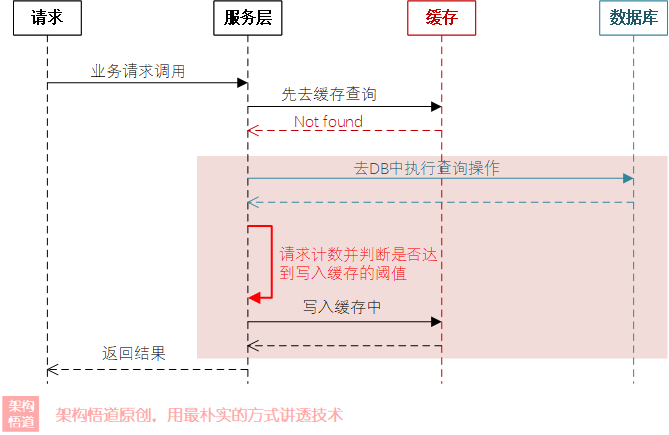
針對這種情況,我們可以為熱點資料設定一個過期時間續期的操作,比如每次請求的時候自動將過期時間續期一下,此外,也可以在資料庫記錄訪問的時候借助分布式鎖來防止快取擊穿問題的出現,當快取不可用時,僅持鎖的執行緒負責從資料庫中查詢資料并寫入快取中,其余請求重試時先嘗試從快取中獲取資料,避免所有的并發請求全部同時打到資料庫上,如下圖所示:
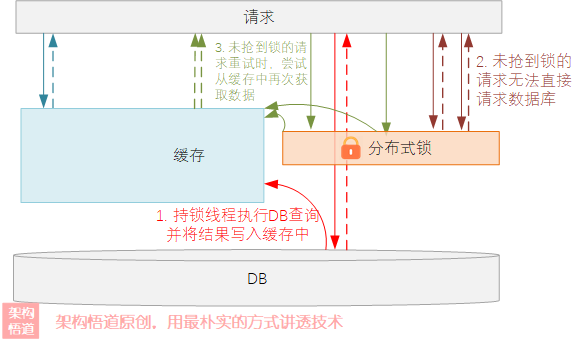
對上面的處理程序描述說明如下:
-
沒有命中快取的時候,先請求獲取分布式鎖,獲取到分布式鎖的執行緒,執行
DB查詢操作,然后將查詢結果寫入到快取中; -
沒有搶到分布式鎖的請求,原地
自旋等待一定時間后進行再次重試; -
未搶到鎖的執行緒,再次重試的時候,先嘗試去快取中獲取下是否能獲取到資料,如果可以獲取到資料,則
直接取快取已有的資料并回傳;否則重復上述1、2、3步驟,
按照上面的策略,經過一番通宵緊急上線操作后,系統終于恢復了正常,正當開發人員長舒了口氣準備下班回家睡覺的時候,系統警報再次響起,系統再次宕機了,
有人扒出了一個2年前的帖子,這個帖子在2年前就已經爆料李某某由于PC被警方拘捕,當時大家都不信,于是這個2年前的帖子得到了眾人狂熱的轉發與閱讀查看,
其實宕機的原因很明顯,因為系統只規劃快取了最近1年的所有帖子資訊,而對超過1年的帖子的操作,都會直接請求到資料庫上,這個2年前的帖子突然爆火導致大量的用戶來請求直接打到了下游,再次將資料庫壓垮 —— 也就是說又一次出現了快取擊穿,在同一塊石頭上摔倒了兩次!
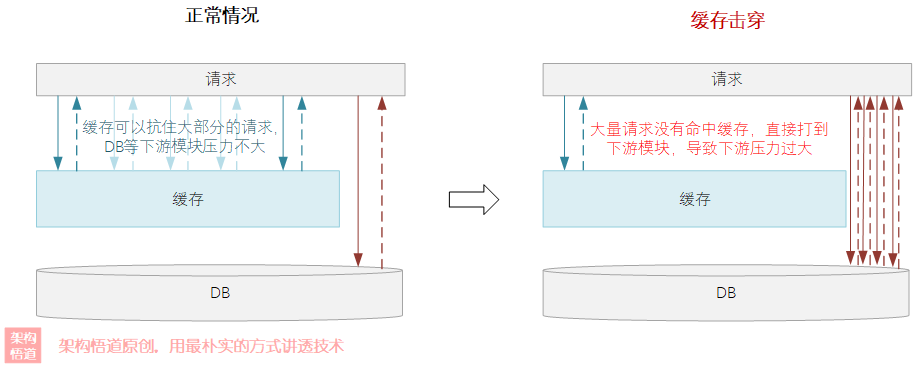
對于業務中最常使用的旁路型快取而言,通常會先讀取快取,如果不存在則去資料庫查詢,并將查詢到的資料添加到快取中,這樣就可以使得后面的請求繼續命中快取,
但是這種常規操作存在個“漏洞”,因為大部分快取容量有限制,且很多場景會基于LRU策略進行記憶體中熱點資料的淘汰,假如有個惡意程式(比如爬蟲)一直在刷歷史資料,容易將記憶體中的熱點資料變為歷史資料,導致真正的用戶請求被打到資料庫層,因而又出現了一些業務場景,會使用類似上面所舉的例子的策略,快取指定時間段內的資料(比如最近1年),且資料不存在時從DB獲取內容之后也不會回寫到快取中,針對這種場景,在快取的設計時,需要考慮到對這種冷資料的加熱機制進行一些額外處理,如設定一個門檻,如果指定時間段內對一個冷資料的訪問次數達到閾值,則將冷資料加熱,添加到熱點資料快取中,并設定一個獨立的過期時間,來解決此類問題,
比如上面的例子中,我們可以約定同一秒內對某條冷資料的請求超過10次,則將此條冷資料加熱作為臨時熱點資料存入快取,設定快取過期時間為30天(一般一個陳年八卦一個月足夠消停下去了),通過這樣的機制,來解決冷資料的突然竄熱對系統帶來的不穩定影響,如下圖所示:
又是一番緊急上線,終于,系統又恢復正常了,
快取穿透:合理的防身自保手段
我們的系統對外開放并運行的時候,面對的環境險象環生,你不知道請求是來自一個正常用戶還是某些別有用心的盜竊者、亦或是個純粹的破壞者,
還是上面的論壇的例子:
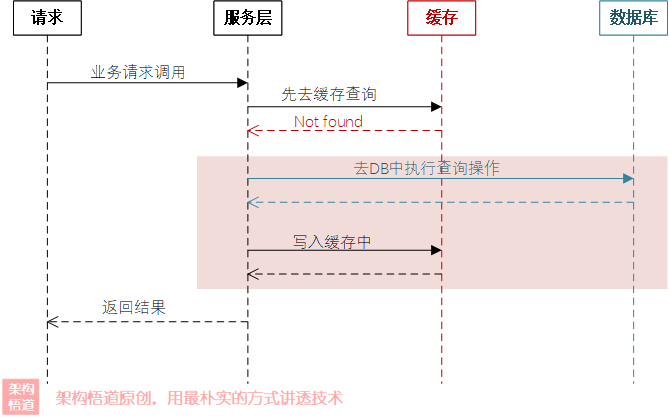
用戶在互動論壇上點擊帖子并查看內容的時候,界面呼叫查詢帖子詳情介面時會傳入帖子ID,然后后端基于帖子ID先去快取中查詢,如果快取中存在則直接回傳資料,否則會嘗試從MySQL中查詢資料并回傳,
有些人盯上了論壇的內容,便搞了個爬蟲程式,模擬帖子ID的生成規則,呼叫查詢詳情介面并傳入自己生成的ID去遍歷挖取系統內的帖子資料,這樣導致很多傳入的ID是無效的、系統內并不存在對應ID的帖子資料,
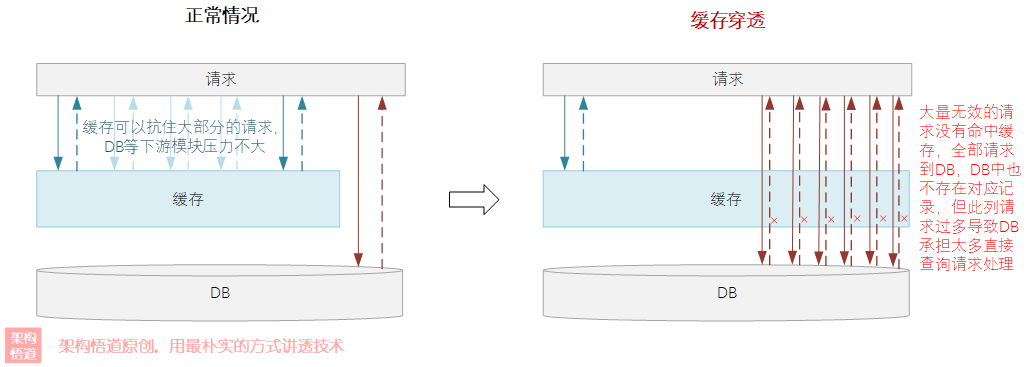
所以,上面大量無效的ID請求到系統內,因為無法命中快取而被轉到MySQL中查詢,而MySQL中其實也無法查詢到對應的資料(因為這些ID是惡意生成的、壓根不存在),大量此類請求頻繁的傳入,就會導致請求一直依賴MySQL進行處理,極易沖垮下游模塊,這個便是經典的快取穿透問題(快取穿透與快取擊穿非常相似,區別點在于快取穿透的實際請求資料在資料庫中也沒有,而快取擊穿是僅僅在快取中沒命中,但是在資料庫中其實是存在對應資料的),
快取穿透的情況往往出現在一些外部干擾或者攻擊情景中,比如外部爬蟲、比如黑客攻擊等等,為了解決快取穿透的問題,可以考慮基于一些類似白名單的機制(比如基于布隆過濾器的策略,后面系列文章中會詳細探討),當然,有條件的情況下,也可以構建一些反爬策略,比如添加請求簽名校驗機制、比如添加IP訪問限制策略等等,
快取的資料一致性
快取作為持久化存盤(如資料庫)的輔助存在,畢竟屬于兩套系統,理想情況下是快取資料與資料庫中資料完全一致,但是業務最常使用的旁路快取架構下,在一些分布式或者高并發的場景中,可能會出現快取不一致的情況,
資料庫更新+快取更新
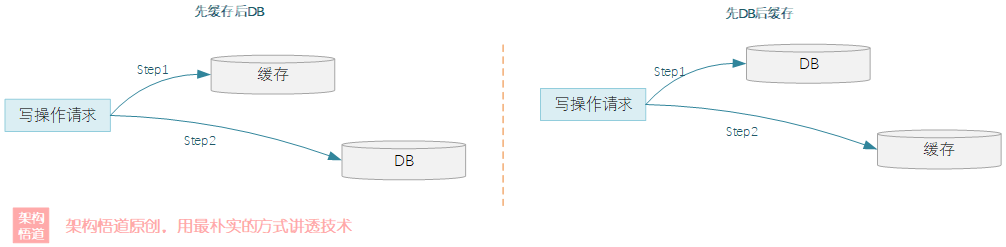
在資料有變更的時候,需要同時更新快取和資料庫兩個地方的資料,因為涉及到兩個模塊的資料更新,所以會有2種組合情況:
- 先更新快取,再更新資料庫
- 先更新資料庫, 再更新快取
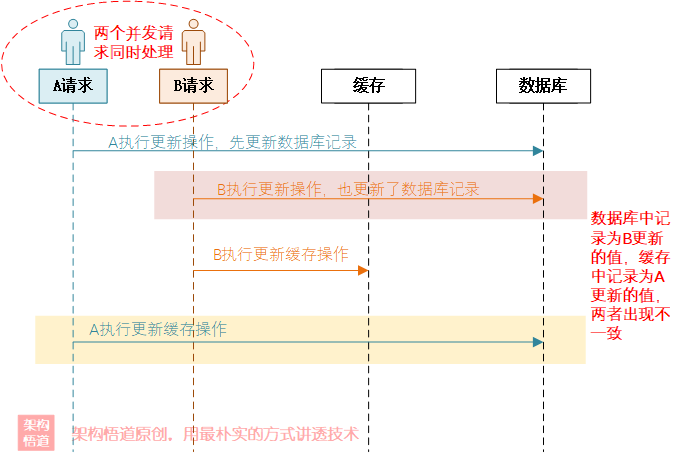
在單執行緒場景下,如果更新快取和更新資料庫操作都是成功的,則可以保證資料庫與快取資料是一致的,但是在多執行緒場景下,由于由于更新快取和更新資料庫是兩個操作,不具備原子性,就有可能出現多個并發請求交叉的情況,進而導致快取和資料庫中的記錄不一致的情況,比如下面這個場景:
這種情況下,有很多的人會選擇結合資料庫的事務來一起控制,因為資料庫有事務控制,而Redis等快取沒有事務性,所以會在一個DB事務中封裝多個操作,比如先執行資料庫操作,執行成功之后再進行快取更新操作,這樣如果快取更新失敗,則直接將當前資料庫的事務回滾,企圖用這種方式來保證快取資料與DB資料的一致,
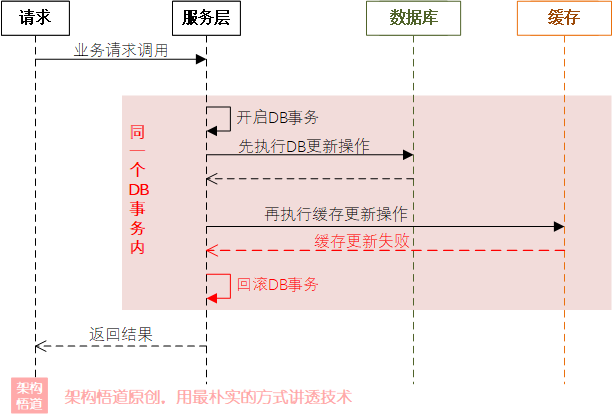
乍看似乎沒毛病,但是細想一下,其實是有前提條件的,我們知道資料庫事務的隔離級別有幾種不同的型別,需要保證使用的事務隔離級別為Serializable或者Repeatable Read級別,以此來保證并發更新的場景下不會出現資料不一致問題,但這也降低了并發效率,提高資料庫的CPU負載(隔離級別與并發性能存在一定的關聯關系,見下圖所示),
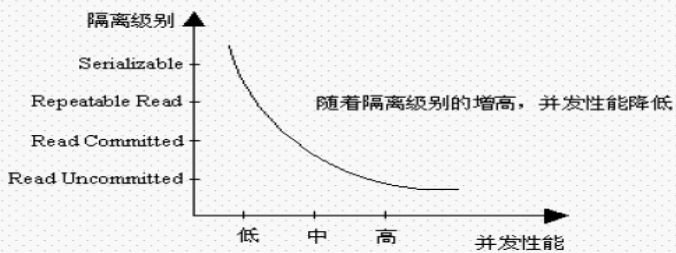
所以對于一些讀多寫少、寫操作并發競爭不是特別激烈且對一致性要求不是特別高的情況下,可以采用事務(高隔離級別) + 先更新資料庫再更新快取的方式來達到資料一致的訴求,
資料庫更新+快取洗掉
在旁路型快取的讀操作分支中,從快取中沒有讀取到資料而改為從DB中獲取到資料之后,通常都會選擇將記錄寫入到快取中,所以我們也可以在寫操作的時候選擇將快取直接洗掉,等待后續讀取的時候重新加載到快取中,
這樣也會有兩種組合情況:
- 先洗掉快取,再更新資料庫
- 先更新資料庫,再洗掉快取
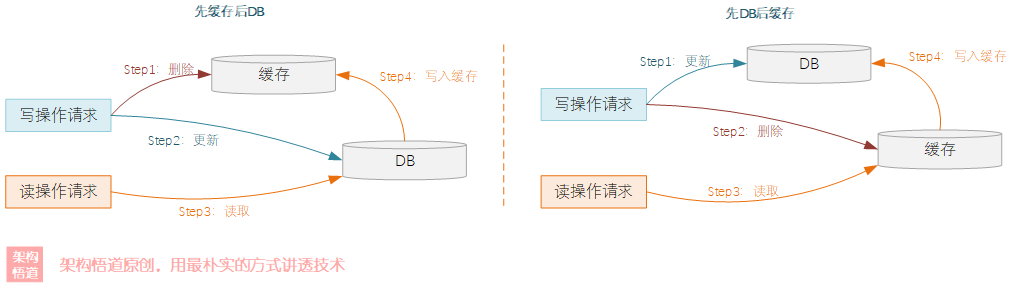
這種也會出現前面說的先操作成功,后操作失敗的問題,
我們先看下先洗掉快取再更新資料庫的操作策略,如果先洗掉快取成功,然后更新資料庫失敗,這種情況下,再次讀取的時候,會從DB里面將舊資料重新加載回快取中,資料是可以保持一致的,
雖然更新資料庫失敗這種場景下不會出現問題,但是在資料庫更新成功這種正常情況下,卻可能會在并發場景中出現問題,因為常見的快取(如Redis)是沒有事務的,所以可能會因為并發處理順序的問題導致最終資料不一致,如下圖所示:
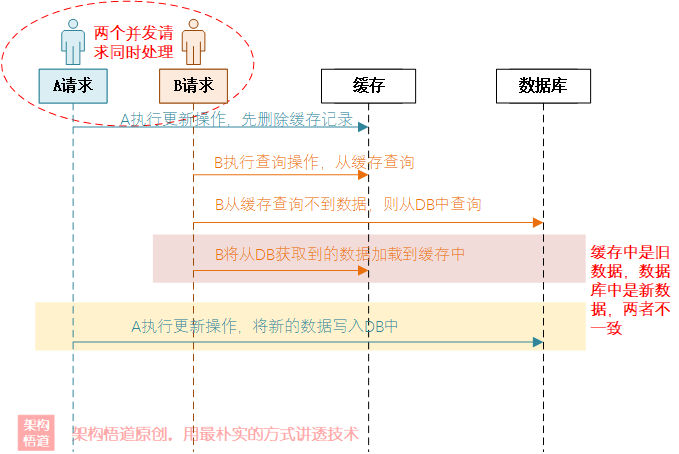
上圖中,因為洗掉快取和更新DB是非原子操作,所以在并發場景下可能的情況:
-
A請求執行更新資料操作,先洗掉了快取中的資料;
-
A這個時候還沒來及往DB中更新資料的時候,B查詢請求恰好進入;
-
B先查詢快取發現快取中沒有資料,又從資料庫中查詢記錄并將記錄寫入快取中(相當于A剛刪了快取,B又將原樣資料寫回快取了);
-
A執行完成更新邏輯,將變更后的資料寫入到DB中,
一番操作完成后,實際上快取中存盤的是A修改前的內容,而DB中存盤的是A修改后的資料,兩者因此出現了不一致的問題,這樣導致后面的查詢請求依舊是從快取中獲取到舊資料,而更新后的新資料無法生效,
那么,如果采用先更新資料庫,再洗掉快取的策略,又會有何種表現呢?假設資料庫更新成功,但是快取洗掉失敗,我們也可以通過資料庫事務回滾的方式將資料庫更新操作回滾掉,這樣在非并發狀態下,可以確保資料庫與快取中資料是一致的,
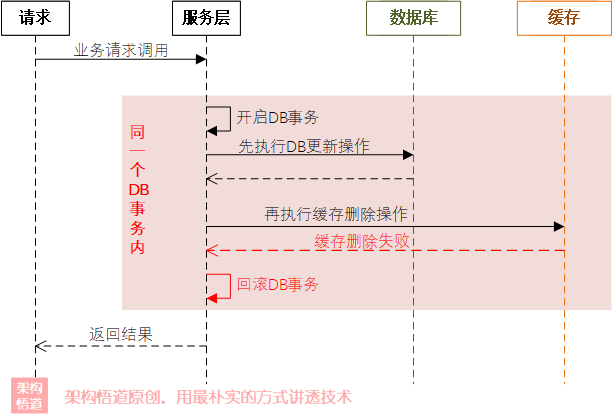
當然,因為基于資料庫事務機制來控制,需要注意下事務的粒度不能過大,避免事務成為阻塞系統性能的瓶頸,在對并發性能要求極高的情況下,可以考慮非事物類的其余方式來實作,如重試機制、或異步補償機制、或多者結合方式等,
比如下圖所示的這種策略:
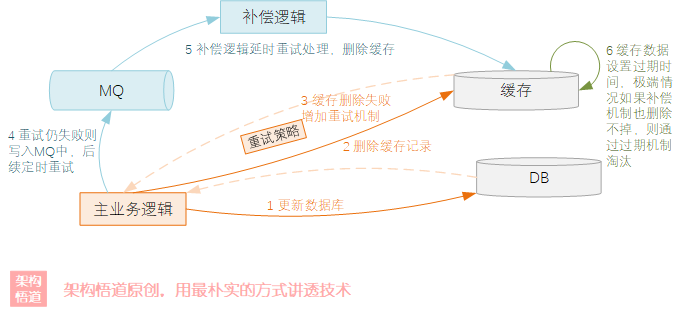
上圖的資料更新處理策略,可以有效的保證資料的最終一致性,降低極端情況可能出現資料不一致的概率,并兜底增加了資料不一致時的自恢復能力,
具體處理邏輯說明如下:
-
先執行資料庫的資料更新操作,
-
更新成功,再去執行快取記錄洗掉操作,
-
快取如果洗掉失敗,則按照預定的
重試策略(比如對于指定錯誤碼進行重試,最多重試3次,每次重試間隔100ms等)進行重試, -
如果快取洗掉失敗,且重試依舊失敗,則將此洗掉事件放入到MQ中,
-
獨立的
補償邏輯,會去消費MQ中的訊息事件請求,然后按照補償策略繼續嘗試洗掉, -
每個快取記錄設定過期事件,極端情況下,重試洗掉、補償洗掉等策略全部失敗時,等到資料記錄過期自動從快取中淘汰,作為
兜底策略,
這種處理方式,雖然依舊無法百分百保證資料一致,但是整體出現資料不一致情況的概率與可能性非常的小,
實際使用場景中,對于一致性要求不是特別高、且并發量不是特別大的場景,可以選擇基于資料庫事務保證的先更新資料庫再更新/洗掉快取,而對于并發要求較高、且資料一致性要求較好的時候,推薦選擇先更新資料庫,再洗掉快取,并結合洗掉重試 + 補償邏輯 + 快取過期TTL等綜合手段,
小結回顧
本篇內容中,我們主要探討了下快取的使用程序中的一些典型例外的觸發場景與防護策略,并一起聊了下保持快取與資料庫資料一致性的一些保障手段,
關于這些內容,我們本篇就聊到這里,
那么,你是否在使用快取的時候遇到過類似的問題呢?你是如何解決這些問題的呢?你關于這些問題你是否有更好的理解與應對策略呢?歡迎評論區一起交流下,期待和各位小伙伴們一起切磋、共同成長,
?? 補充說明 :
本文屬于《深入理解快取原理與實戰設計》系列專欄的內容之一,該專欄圍繞快取這個宏大命題進行展開闡述,全方位、系統性地深度剖析各種快取實作策略與原理、以及快取的各種用法、各種問題應對策略,并一起探討下快取設計的哲學,
如果有興趣,也歡迎關注此專欄,
我是悟道,聊技術、又不僅僅聊技術~
如果覺得有用,請點贊 + 關注讓我感受到您的支持,也可以關注下我的公眾號【架構悟道】,獲取更及時的更新,
期待與你一起探討,一起成長為更好的自己,

本文來自博客園,作者:架構悟道,歡迎關注公眾號[架構悟道]持續獲取更多干貨,轉載請注明原文鏈接:https://www.cnblogs.com/softwarearch/p/16834547.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/524867.html
標籤:Java
上一篇:java Stream流練習
下一篇:自從用了灰度發布,睡覺真香!